


You must have already faced this issue. You want to collect data from a website to use it for in-depth analysis but are stuck because you don’t have an idea how to actually get the data. Let me tell you directly that copy-pasting is not a clever way. But no worries! Fortunately, there is data scraping, also known as web scraping, the automated process of web data extraction.
In this comprehensive guide, you’ll learn step-by-step how to collect data from a website with web scraping using both your own code and no-code scrapers.
Side note: For more than 2,000 user-friendly and easy-to-deploy web scrapers of different sites such as Facebook, Amazon, or Google Maps, visit Apify Store.
12 reasons to collect data from websites
| Use case | How it works |
|---|---|
| 📉 Market research | Collect vast amounts of data from social media, Google, and more, to better understand competitor strategies, customer reviews, and market trends. |
| 💯 Sentiment analysis | Find out what your customers think of you by collecting reviews, comments, and opinions from social media, review sites, and forums |
| 💸Price monitoring | Track price movements of your competitors’ goods and services and be able to change your pricing strategy accordingly. |
| 📇Lead generation | Muster contact information and details about your potential business leads from LinkedIn and other social media sites. With that, you're prepared to skyrocket your sales strategy. |
| 🧠 Data for AI | Scrape data from whatever sites you need to feed it to LLMs such as ChatGPT and create your own AI. |
| 🚀Product development | Obtain data from e-commerce websites, your competitors' sites, and reviews from all over the web. You'll gain insights into the customers' minds and can build market-fitting products easily. |
| 🏢Job market analysis | Monitor job postings on job sites such as Indeed, Glassdoor, or LinkedIn. Find your next job or colleague with ease. |
| 🏘️ Real estate scraping | Want to buy or rent a house? Scrape real estate sites and gain information about new listings and price changes. You can react immediately and increase your chances of a successful deal. |
| 💹Stock market analysis | Monitor stock prices and financial reports, always have up-to-date data on the market, and automate your investments. |
| 🎓 Academic research | Speed up your search for scientific studies, analysis, and statistical data with scraping sites like Google Scholar. |
| 🤖 Robotic process automation (RPA) | Scrape any data you need to automate your software robots doing payroll processing, onboarding, order processing, and much more. |
Yes, scraping data that is publicly available on the internet is legal, but there are rules you need to follow. Read our full guide about web scraping legislation.
2 ways how to collect data from a website
See? You can use data collection aka web scraping for various use cases. These 12 were only a little sneak peak.
That’s why you should try web scraping. Now, to answer your question about how to collect data from websites.
There are 2 possible ways. You can either write your own code, for which you need high-level programming skills and experience with Python or JavaScript, or you can try a ready-made scraper. That’s pretty easy, all you need is an Apify account and decide which website you want to scrape. You’ll learn exactly how to do it in a moment.
Which way should you choose? There is no right or wrong answer. It depends purely on you and the nature of your projects. Take a look at the table below to find out more.
| Using code | No-code solutions | |
|---|---|---|
| ➕ Pros | Can be tailored directly to your project. | There is a scraper for almost every website you can think of. It’s easy to use and fairly priced. |
| ➖ Cons | More skill-intensive and expensive. | Dependency on a third-party provider. |
| Suitable for | Scraping niche sites. | Projects that require daily scraping of big websites. |
1) Use your own code for data collection
You've decided to create your own web scraper. To build data-driven products like leading web development companies, you need to equip yourself with the right tools and follow the steps below.
5 steps for building your own web scraper
- Select the page you want to scrape (= URL)
First of all, make sure you know from which sites you want to collect data. It can be one URL or multiple ones. - Define which data you want to scrape.
- Inspect the page
A URL is not enough. To make your scraper work properly, you’ll need to explain thoroughly where it’ll find the data. Start inspecting the page by right-clicking and selecting Inspect. You’ll find yourself looking at DevTools. - Select the data
You only need some types of data. Search for it in DevTools to determine the specific selectors that contain your data. For example, if you want to get all H2 titles from the web, search for<H2>tags. Afterwards, tell your web scraper it needs to find all<H2>on the page.
- Inspect the page
- Code it till you make it!
Now, choose the tools with which you want to write the code (stay tuned - more on that comes in a few scrolls), and start working! You’ll need to tell your scraper to crawl the web, scrape, and parse the data you want. - Make the scraper work
Ready? Make an HTTP request to the server and wait for the magic to happen! - Store your data carefully
Congrats! You've successfully finished your first web scraping run. Make sure to store the data in a format of your choice - Excel, HTML, or anything else.
10 best web scraping tools for data collection
Theoretically, you now know the steps when writing your own scraper. However, you’ll not manage it on your own. You’ll need at least a couple of the following web scraping tools at hand. Take a look, decide which one you want to try, and learn more about them.
HTTP clients
HTTP clients help with data extraction by sending your request to the page. Which one you can consider?
| Name | What it is | Learn more |
|---|---|---|
| Requests (Python) | HTTP library that becomes your bread and butter when doing simple data scraping. | ❗Learn web scraping with Python Requests |
| HTTPX (Python) | Request on steroids - adds async and HTTP/2 support to your toolbox. | ❗Discover the best Python web scraping libraries |
| Axios (Node.js) | Your basic need if you want to do HTTP requests from Node.js. | ❗How to do web scraping with Axios |
HTML and XML parsers
Tools that you’ll use to parse the data you get, i.e., get them sorted and ready to be interpreted. The most popular ones are Beautiful Soup and Cheerio.
| Name | What it is | Learn more |
|---|---|---|
| Beautiful Soup (Python) | Essential Python data parsing library for simple and quick task with HTML or XML documents. | ❗Web scraping basics in Beautiful Soup |
| Cheerio (Node.js) | Equivalent for Node.js, effective and adaptable parser for most of web scraping tasks. | ❗Ultimate guide to web scraping with Cheerio |
Browser automation libraries
To make your scraping a repetitive process, you’ll need to automate it. For that, you’ll use one of the browser automation libraries. These include:
| Name | What it is | Learn more |
|---|---|---|
| Selenium | Primarily a Python library that is compatible with multiple languages, popular for basic data extraction. | ❗Everything you need to know about web scraping with Selenium |
| Playwright | Similar to Selenium but was built originally for Node.js. Has auto-await and more functions on top. | ❗How to scrape the web with Playwright step-by-step |
| Puppeteer (Node.js) | The older brother of Playwright, Puppeteer is suited only for Node.js. Crucial when you need to collect data from dynamically-loaded content. | ❗Alpha and omega of web scraping with Puppeteer |
Web scraping libraries
If you could choose just one tool of all we have listed, you should reach for a comprehensive web scraping library that includes elements of multiple instruments you’ve read about. Let me introduce you to Crawlee and Scrapy.
| Name | What it is | Learn more |
|---|---|---|
| Crawlee (Node.js.) | Integrates features from libraries that were already mentioned, such as Cheerio or Puppeteer, and comes with additional tools designed specifically for web scraping developers. | ❗Comprehensive guide on how to scrape web with Crawlee |
| Scrapy (Python) | The biggest Python web scraping library that will help you to succeed even in the most complex web scraping challenges. You can combine it effortlessly with other Python libraries to get the best result. | ❗Web scraping with Scrapy 101 |
To scrape specific data, you need to tell your scraper how it should distinguish them. You can do it by telling it the specific tag the data is enclosed by - such as <H2>. When using ready-made scrapers, just write down what you need before running the scraper.
2) Collect data for free with no-code web scrapers
Have you decided you want to scrape the web easier? Let’s meet Apify Actors, the ready-made web scrapers for all kinds of websites you can think of. Here’s a step-by-step guide on how to deploy them.
How to do web scraping with Apify Actors
1) Have a look at Apify Store
First, open Apify Store and have a look around. You can search for the scraper you need directly with the search bar, filter them by categories or view them all.
2) Choose the Actor and try it for free
Once you’ve selected the Actor you want to use, click on it to see its description and additional information. In this case, I’ve chosen YouTube Scraper.
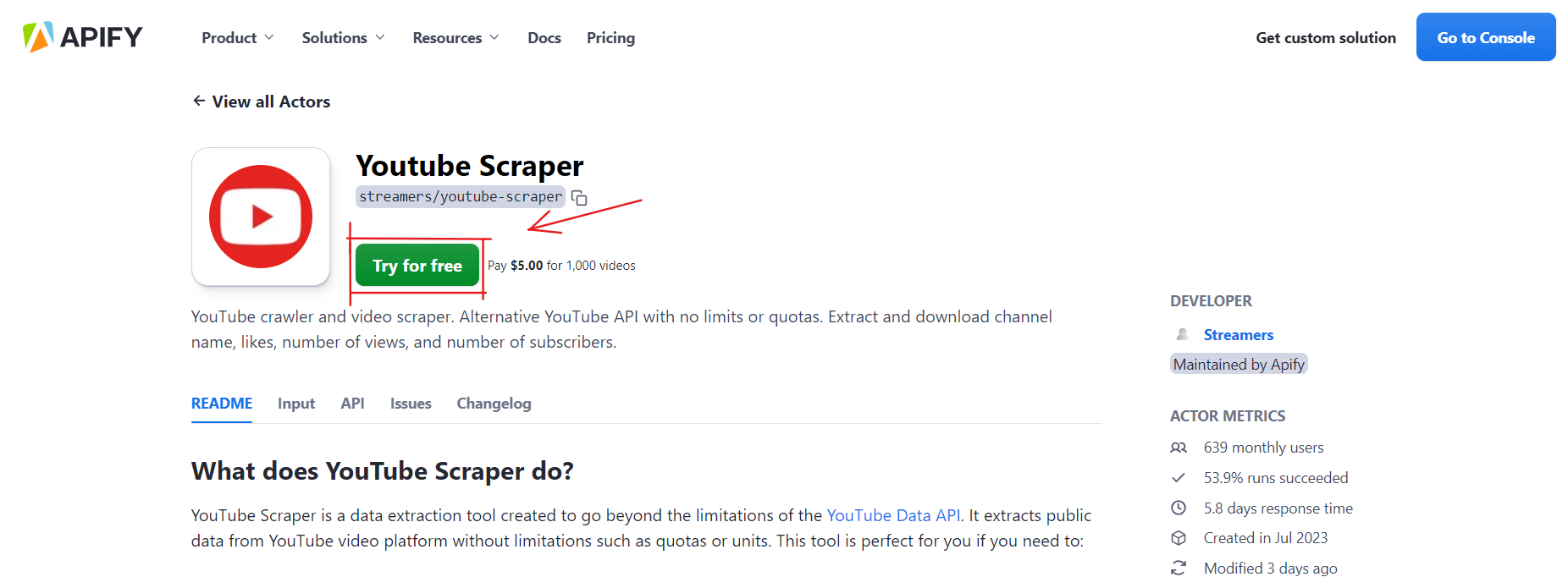
Don’t forget to hit the Try for free button.
3) Run the Actor
You’ll be redirected to the Actor on Apify Console. (In case you already have an Apify account, if not, register here.) After that, just fill in detailed information about what you want to scrape and tap on the button Save and Start.

And that’s all! After the Actor finishes scraping YouTube for the search term (in this case, “How to collect data from a website”) it’ll return the results in a simple table. You can export it in Excel, JSON, or other formats.
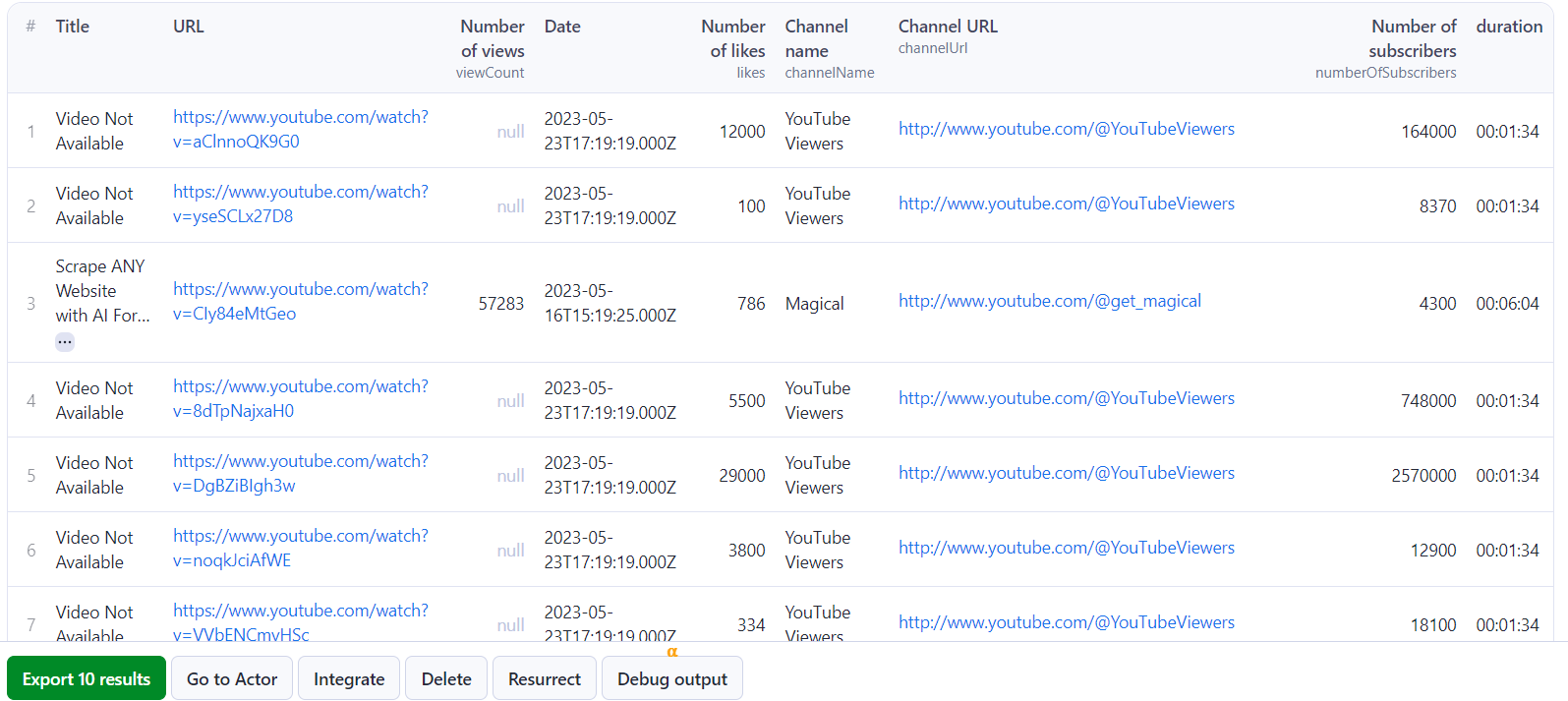
Congratulations! Now you know how to collect data from any website with Apify Actors. It’s time to turn knowledge into practice.
FAQ
You’ve learned 2 ways to collect data from a website. You now have basic know-how for building your own scraper and can start scraping the web with Apify Actors immediately. Any questions? If so, you can look for them in the FAQ below.
How can I extract data from a website for free?
For free data extraction, try out the Apify free plan. You get $5 worth of monthly credit every month, but there are limitations. However, there's no time limit on the free plan.
How to collect data from a website using Python?
Python is very popular among web scraping developers. If you want to write your own scraper in Python, you can try BeautifulSoup for simple tasks or Scrapy, the most complete Python web scraping library, for complex tasks. Read our tutorial on Python web scraping so you don’t have to start from scratch.
How can I collect data from a website online?
If you’re not up to building your own scraper, you can try ready-made solutions, such as the scrapers from Apify Store. These are scrapers that other developers have already built for you, so the heavy lifting has been done for you, and you can configure them for your use case.





