When people run into the topic of web scraping, the amount of information on it can be overwhelming. Even if you are a dedicated web data enthusiast, navigating through web automation tools can often be confusing and misleading. We’re here to provide you with the answers you need so that you start your web scraping journey with a very good chance of successfully finishing it.
What is web scraping?
Web scraping, web data extraction, web harvesting, data scraping are all synonyms for extracting data from websites. To put it simply, web scraping is a fully automated process that replaces the manual work of opening web pages, copy-pasting publicly available information from there, and saving it into a spreadsheet for later use.
Is it legal to scrape the web?
Like many other forms of automatization, scraping merely gathers information the way a human would, but in a faster and more efficient way. So as long as you scrape public, copyright-free content and don’t accumulate personal data, scraping is legal. Check out our legality article to learn more about the laws and regulations connected to web scraping.
What is the difference between web scraping tools and web scraping techniques?
Web scraping is a rather new and dynamically evolving area, so when just starting to explore this subject, very often people find answers on the internet that might be quite confusing. That’s why it is important to use the right terms when talking about web scraping. For example, users sometimes confuse web scraping technologies or techniques with web scraping tools, services and platforms. Sometimes you may even find a web scraping company listed as a tool or service. So let’s clear the air here.
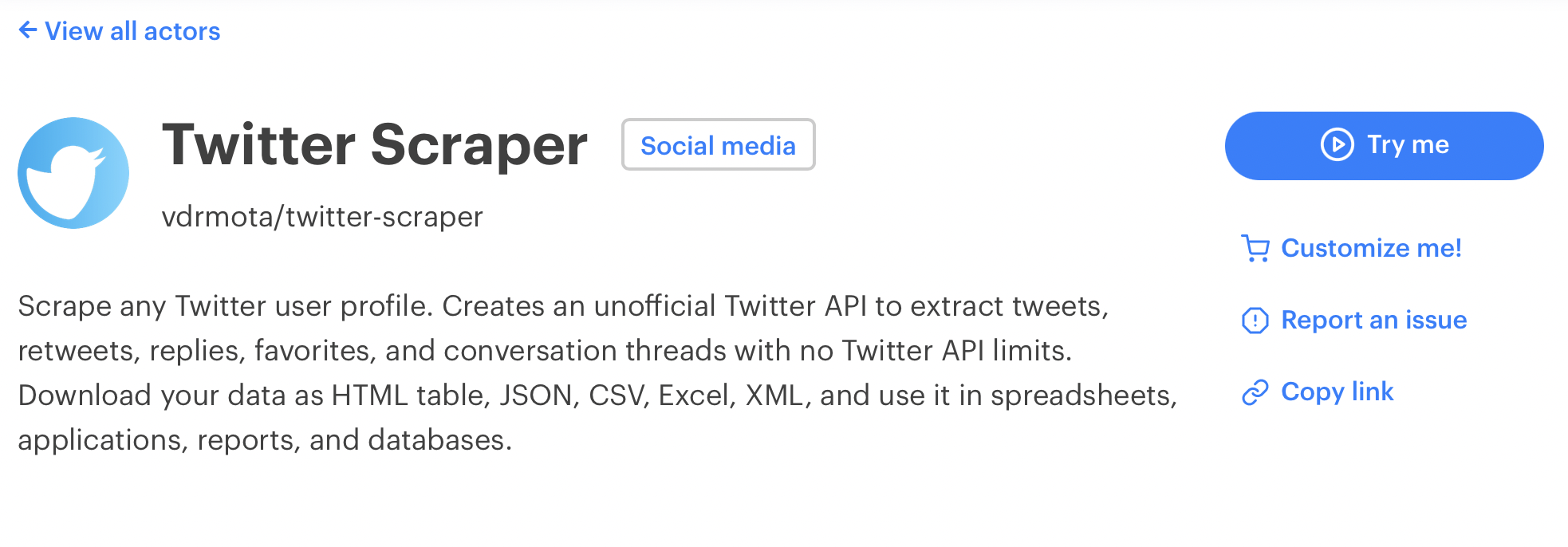
A web scraping tool is a piece of software that does the job of collecting and delivering data for you; it can also be called a web scraper, or web scraping API. Don’t let the abbreviation intimidate you, an API, or application programming interface, is simply a way for the web scraper to communicate with the website it’s collecting data from. That’s why you can often find the word API standing right next to the names of some of the biggest websites: e.g. Google Maps API, Aliexpress API, Instagram API, and so on. In a way, “Amazon API” and “Amazon Scraper” mean the same thing. Here’s an example of a web scraping tool. This Twitter Scraper effectively acts as an unofficial Twitter API.
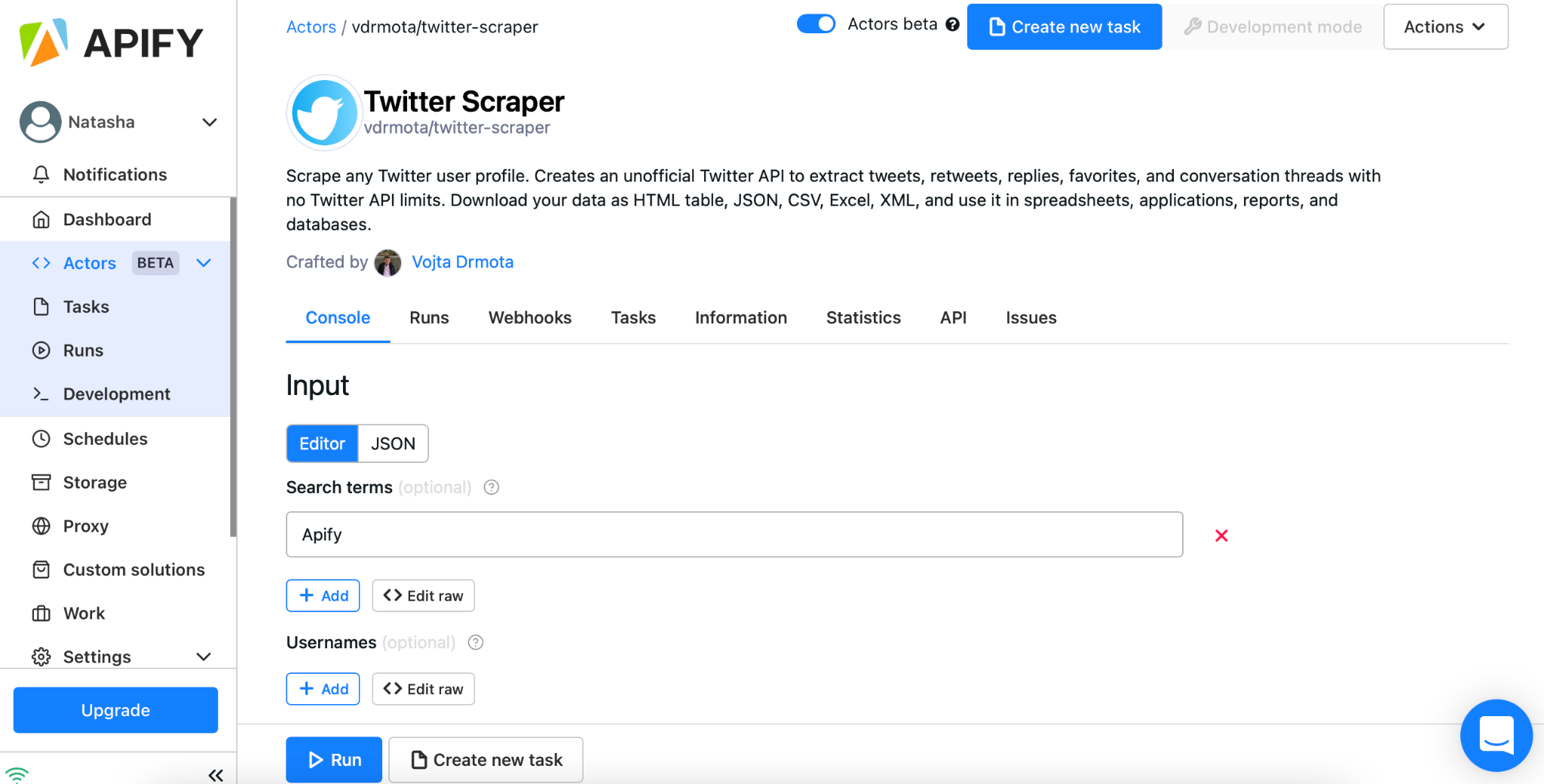
A web scraping platform is a unifying cloud-based structure where all these scraping tools are maintained and where a user can tune them according to their needs. The platform - if it’s a good one - also serves as a channel of communication between the company and the users, where registered users can leave their feedback and report issues so the company can improve on their scraping services. An example of this could be our Apify platform, including the Twitter scraping tool. There you can search through all the scrapers as well as organize and schedule the way they work according to your needs.
A web scraping technique is the way a scraper executes its job; an approach or a method for the scraper to get the data from the webpage.
Top web scraping techniques are:
- using CSS selectors
- Schema.org microdata
- JSON-LD
- Internal JavaScript variables
- XHRs
Those are the methods or technical approaches of how to scrape data. You can read more about these in our documentation. As you can see, there are many of them, but the good news is that, in these days of the super-developed web, a regular user doesn’t have to know any of them well. Nor do you have to know how to use web scraping tools that are built with those techniques. This is the convenience that is provided by our library of mostly free customized scrapers called Apify Store. In Apify Store, you can find dozens of such ready-made solutions along with their descriptions. We call them Actors; they are mostly web scrapers that scan the web page for the data it displays and collects that data. If you look at the gif below, you can see that each website listed has a corresponding scraper to it, an API that interacts with the website and knows how to read it and extract data from it.

A web scraping company is an enterprise that has the capacity to provide those tools, APIs, and services around them, usually on some sort of platform. You see how it all comes together into one united web scraping ecosystem. Some web scraping companies focus more on user-friendly solutions, some are more oriented towards tech-savvy people, some even incorporate AI algorithms into their software products.
Top web scraping companies are:
All of them either produce simple tools on the platform that other users can use for a subscription, or they can scrape the data for them thus providing web scraping services. They can also make custom-made scraping tools, encourage external developers to help them work on their scrapers or empower other programmers to receive passive income by developing their own scrapers. This is what web scraping business looks like in simplified form.
What does a typical web scraping workflow look like?
Now that you have the bases covered, you can start planning out the hows and whys of your scraping. Before you try out scraping with any of our free web scraping tools, you have to ask yourself three questions:
- What type of information am I looking for? (pictures, text)
- Where can I find it? (which webpage, provide a specific link)
- What will I do with it? (business, research, analysis, and decision-making)
If you’re using our YouTube Scraper, for example, your web scraping workflow will look a little bit like this:
- I want to scrape the YouTube video subtitles for mentions of Tyrannosaurus Rex
- I can find that info at YouTube.com, but my search will be even more precise if I use the URL that contains my search for Tyrannosaurus Rex on YouTube
- I want to collect that data for my research about the popularity of this topic in mass culture.
Since we’re at it already, you can try your hand at scraping Youtube subtitles, comments or profiles by following our step-by-step tutorial.
Combining all of those terms and factors together, we can share with you the list of the most popular and user-friendly scraping tools on our platform, in no particular order.

Our top user-friendly web scraping tools are:
1. Google SERPs Scraper
Google Search does not provide a public API that you can use to see how your search query ranks in mysterious google algorithms. That’s why our users like our free Google scraper tool which allows you to scrape SERPs independently (SERPs stands for Google Search Result Pages). Typical use cases of data scraped from Google Search Results include: search engine optimization, analyzing the ads that Google displays for a given set of keywords, monitoring competition in both organic and paid search, and lots of other fascinating use cases.
Being able to quickly access and collect a huge amount of data from the web, lots of important and well-meaning projects can be realized. Read about how we collaborate with companies and NGOs for a better web of the future.
You can also try scraping Google yourself by following the simple steps in our how to scrape Google Search blog post.
2. Google Maps Scraper
This independent Google Maps API will allow you to scrape anything from reviews, photos, contacts and popular times to addresses, location data, plus code and opening hours and people also search area. Our Google Maps scraper also enforces no rate limits or quotas.
Scraped data from Google Maps can be used in as many ways as you can imagine, but if you want to see real life examples of applying it, check out our use cases on how web scraping can enhance your travel business. You can also try scraping Google Maps by following the simple steps in our how to scrape Google Maps blog post.
3. Instagram Scraper
With this web scraping tool, you can scrape and download Instagram posts, likes, profiles, locations, hashtags, photos, and even comments (if a link to a specific Instagram post is provided). This unofficial Instagram API is designed to enable limitless scraping and extraction of publicly available data.
You can extract data from social media websites for research or for business. With our social media scrapers, you can also scrape nearly every major social media website: Instagram, Reddit, Facebook, Twitter. All you need is to just follow the step-by-step instructions included in the links above.
4. Facebook Pages Scraper
This Facebook scraping tool downloads posts, likes, comments, reviews, contact details, social media profiles, addresses, and all publicly available information from Facebook Pages, without running up against Facebook’s limits. You can also fine-tune your scraping runs to filter the results by minimum and maximum dates, set the max number of results you want to receive, set your preferred language, and get your data in a matter of minutes. In our guide, we’ll show you how to scrape Facebook Pages.
5. Contact Details Scraper
This scraper will extract publicly available contact information for you: from any websites that contain those, including email addresses, phone numbers, and Facebook, Twitter, LinkedIn, and Instagram profiles. You can collect contact details to automate the search for competitors’ and potential partners’ contact details, find new leads and support marketing campaigns with actual data. Read more about how to get and use that contact information data in our tutorial or take a look at our use cases for inspiration.
6. Amazon Scraper
This Actor will scan the Amazon website items for specific keywords and will automatically extract all available pages with those keywords for you. It will enable you to scrape even a large e-commerce website like Amazon in an efficient and timely manner. You can find reasons why scraping e-commerce websites is the future, and ideas how you can capitalize on that data on our E-commerce and Retail page. This video will tell you everything you need to know about how to scrape Amazon with our Actor. But if that isn’t enough, here are two sets of step-by-step instructions.
7. Apartments.com Scraper
This tool is a popular scraper for extracting data about homes from apartments.com. It allows you to search homes in any location and extract detailed information about each one. Web scraping is used heavily not only for apartments.com specifically, but in the real estate industry in general - to predict trends, make better investment decisions, automate real estate marketing, and create new products. You can read about how one talented student used our real estate scraper to analyze the tax rates in the American real estate market.
8. SEO Audit Tool
This Search Engine Optimization tool is created to carry out an automatic SEO audit on any website: it will find broken links, missing images, and will provide information about possible page improvements. You can’t create a good website or even good content these days without being backed up by data like this. Discover how one company has adjusted the concept of our SEO Audit scraper to their needs and enhanced their workflow with keyword-powered research. Check out our set of scrapers created specifically to perform SEO checks.
9. Google Trends API
Google Trends API to scrape data from Google Trends can extract data for multiple search terms listed in a Google Sheet, define time ranges to get results at a higher frequency, select categories, and specify geographical locations.
Trending Searches gives you the chance to track interest, sentiment, gain demographic insights, and understand what topics are rising and falling in popularity. Imagine what unique insights collecting data like that can give you. Following the trending searches also can help greatly in researching topics for journalism or academic papers but also in business ventures.
10. Content Checker
This Actor is amazing at monitoring a website or web page for content changes. When you schedule it, the Actor will automatically run through pages, save before and after screenshots and deliver those to you in an email or as a Slack notification when content changes are detected. Some people use it as a watchdog for prices, availability of appointments, tickets, product updates, sales, competitors, or to track changes in any content that they want to keep an eye on.
You can also explore how to tailor your Content Checker to your needs in our blog post. Or you can see a use case on how we’ve built up on that idea and made it into a proper watchdog for monitoring price changes on Black Friday.
Is web scraping easy to do?
Now that you’re well-armed with an understanding of the terminology and tools, you might be wondering whether web scraping is an easy task. It really depends on what data you want to scrape and what type of website you have in mind for this. Some websites are so complicated and huge that it can take hours even with the best tools, while scraping others will be time-equivalent to drinking a cup of coffee. Usually, web scraping requires a certain level of programming knowledge and experience. But the beauty of the web is that there are also many free ready-made tools available that don’t require a programming background and therefore can be easily used by data advocates or web scraping beginners.
Is there a web scraper that can scrape any web page?
There are millions of web pages on the internet, and logically, each one would need a separate type of scraper. But after looking at all these variations of scrapers for every single website you may start wondering: wouldn’t it be more efficient if there was some sort of a universal scraper that you can adjust to fit any website? And we’ll say - yes, it can sometimes be more efficient, and there are tools like that. You can find a Puppeteer Scraper, Playwright Scraper, Cheerio Scraper, and a Universal Web Scraper. All three of them use different technological strategies, programming languages and libraries to execute web scraping.
Universal Web Scraper stands out from this list because it is a bit more approachable technologically. It is - for an obvious reason - our most popular tool on the platform, but you’ll still need to have some knowledge of JavaScript to be able to steer it in your direction. Our web scraping guide for beginners includes a short tutorial on how to tune that all-in-one scraper as well.
Cheerio Scraper has some advantages over Web Scraper in some cases. Find out more in this guide to using it to scrape any website.
We’re constantly evolving with our ready-made scraping solutions, but if you can’t find a solution for your specific website, you can always order a custom-made scraper from us. We’ll make sure it accurately corresponds to your web scraping needs. Happy scraping!