


YouTube is a treasure trove of data just waiting to be discovered. Better yet: all that YouTube data is now scrapable, including video content. Here's how to do it.
Here’s a short step-by-step tutorial on how YouTube Scraper can extract data from YouTube. It will get data from channels, streams, Shorts, playlists, and searches easily by cherry-picking data from selected YouTube video pages. It will enable you to scrape channels, all their videos, and their details, as well as fine-tune your search. Finally, you'll learn how to scrape both auto-generated and added captions in various languages.
Quick YouTube tutorial on scraping YouTube.
How to scrape YouTube
- Go to the YouTube Scraper page on Apify Store.
- Choose a keyword to scrape YouTube search results.
- Choose URLs to scrape YouTube channels or scrape YouTube videos.
- Choose whether to scrape YouTube subtitles.
- Collect your YouTube data.
- Preview and export your listings.
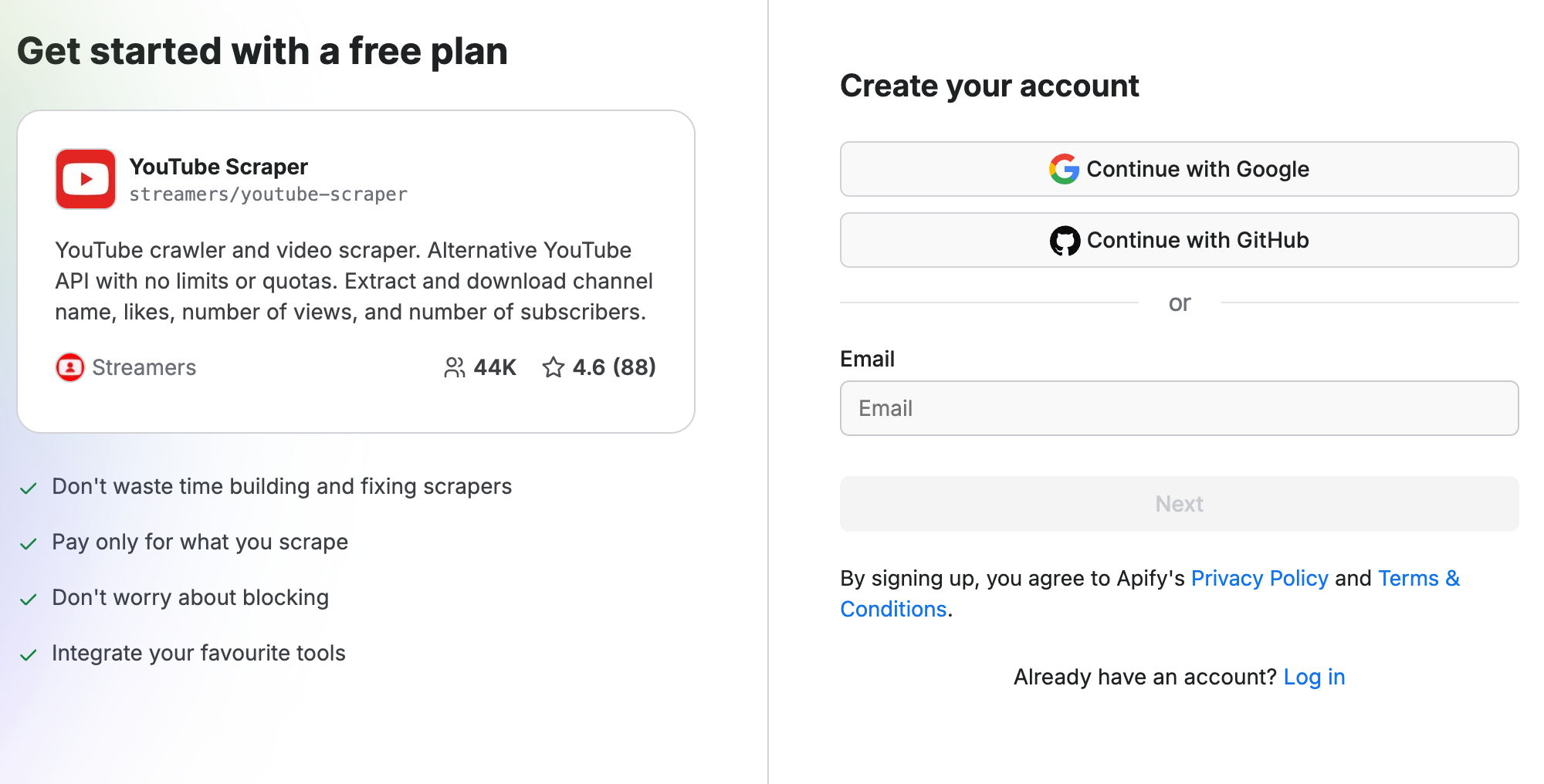
Step 1. Go to the YouTube Scraper page on Apify Store
Go to YouTube Scraper and click the Try for free button. You’ll then need to sign up for a free plan or sign in to Apify Console, which can also be done via your GitHub or Google account to speed up the process.
Step 2. Choose a keyword to scrape YouTube search results
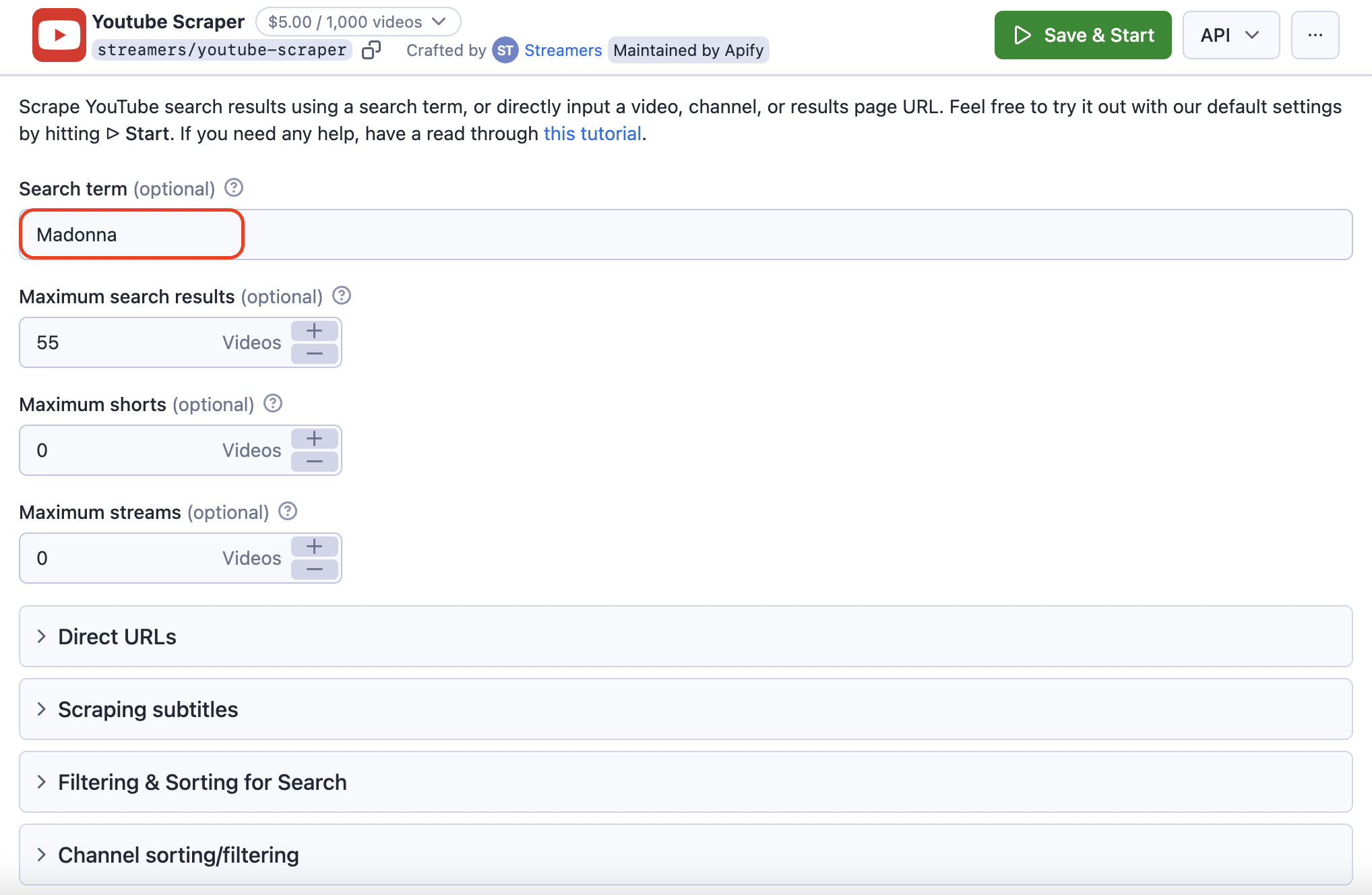
After you’re signed in, it's time to set up your YouTube Scraper. Here, you first decide whether you want to scrape YouTube data by a Search term 🔍 or a specific URL 🔗. Let's try the Search term first and see if we can scrape all the videos from YouTube's search page that match it. You can only add one Search term per run.
Choose the number of videos to scrape
If you're scraping YouTube videos by Search term, it's useful to limit the number of videos you expect to scrape. In the next section, pick the number of videos and/or Shorts, streams you expect in your YouTube dataset.
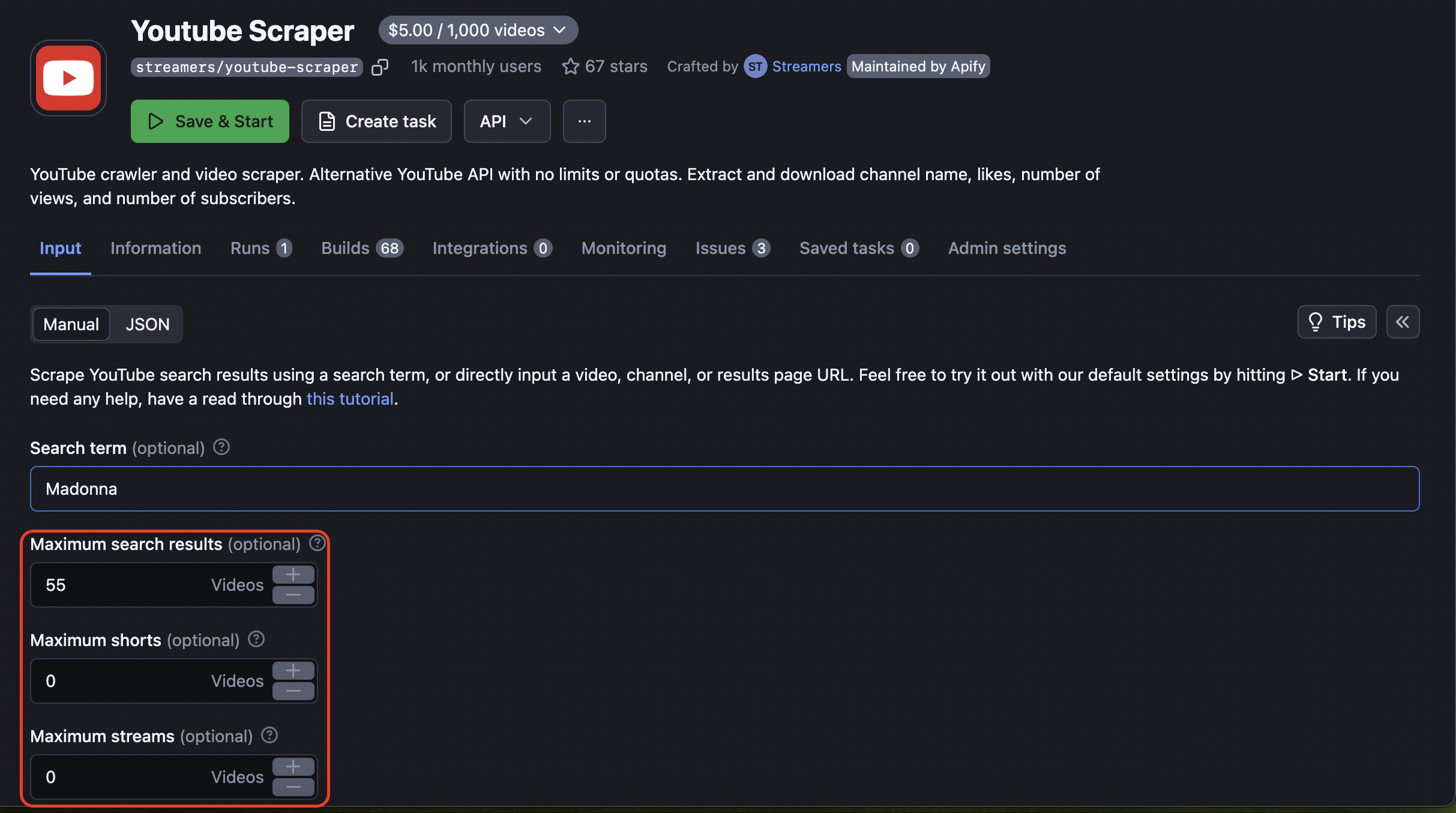
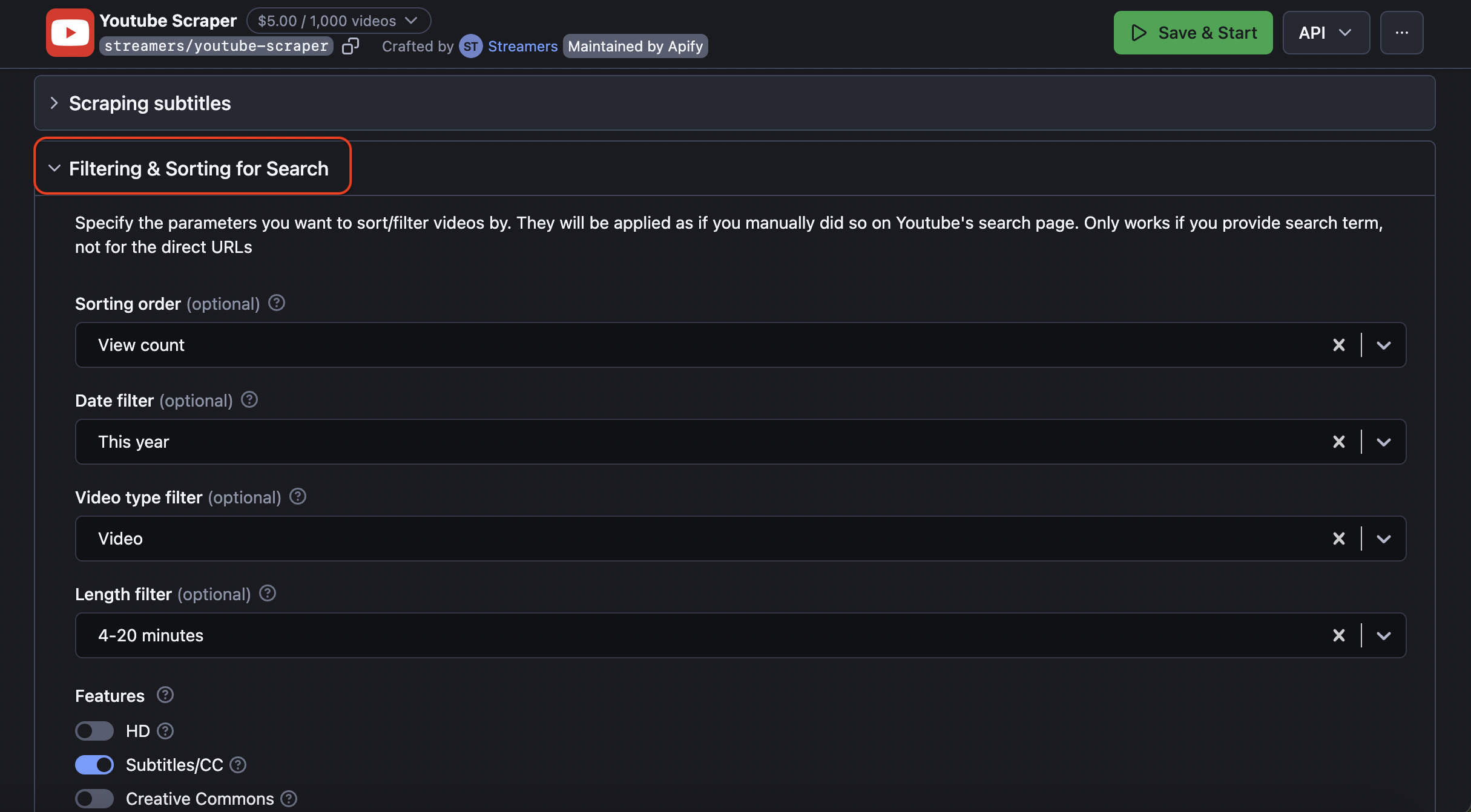
Set up filters and video sorting parameters
Additionally, to narrow down your scraped results even more, you can use Filtering & Sorting for Search and Channel sorting/filtering. There you can choose video groups by popularity, newness, video type, video length, quality, and more.
Step 3. Choose URLs to scrape YouTube channels or scrape YouTube videos
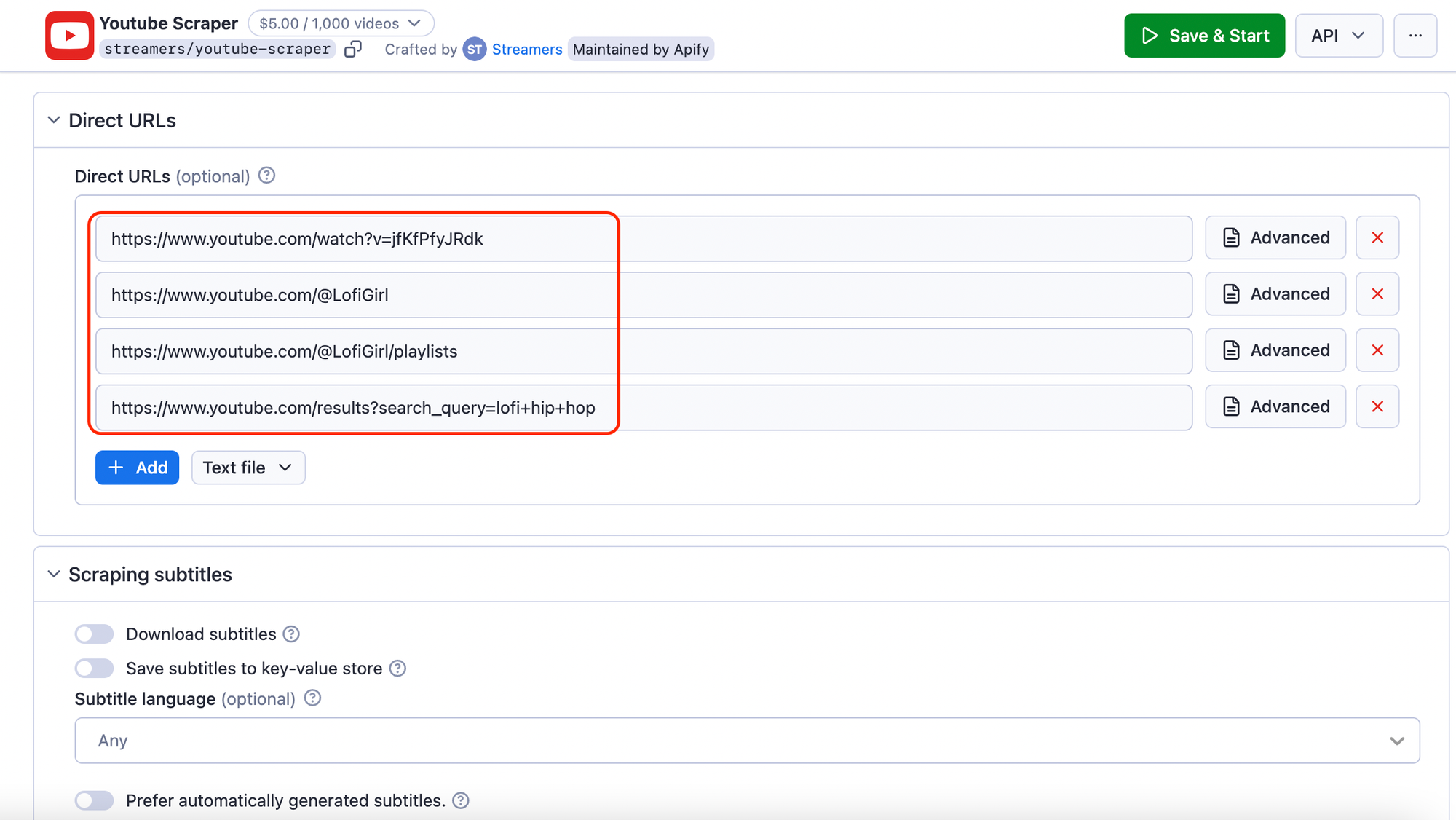
Alternatively to Search term scraping, you can scrape YouTube by URLs 🔗. Just head over to the YouTube site and copy any URL you want to scrape content from: channel URL, video URL, playlist URL, or search URL. Then paste it into the Direct URLs part. An advantage of the Direct URLs section is that you can add many URLs at once.
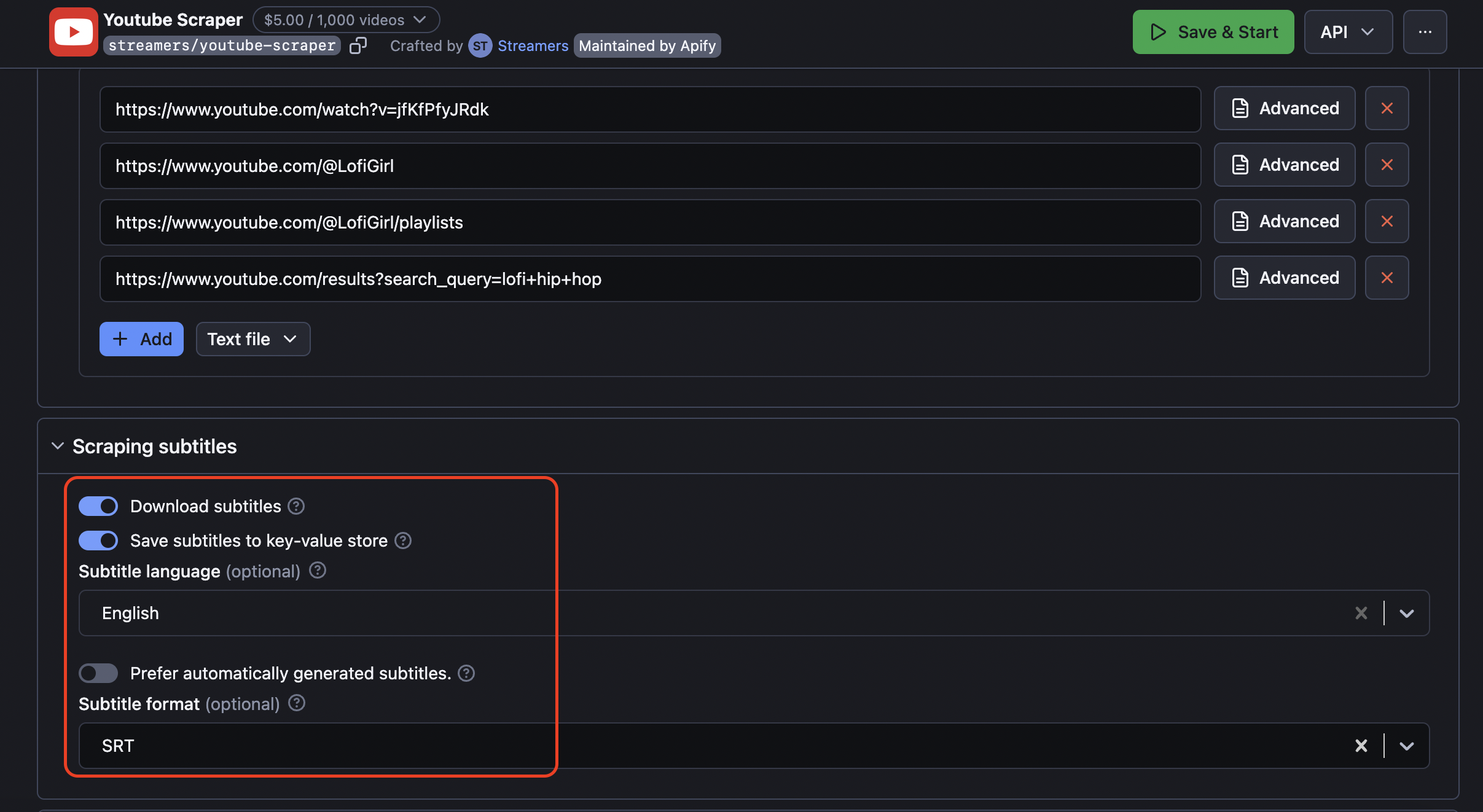
Step 4. Choose whether to scrape YouTube subtitles
Additionally, you can set up subtitles extraction in Scraping subtitles section. You can pick the subtitles format, language, as well as storage. This is also a place where you set up scraping auto-generated subtitles or those added by humans.
Step 5. Collect your YouTube data
Regardless of which method you choose to scrape YouTube videos - by Search term or by URLs, the next step is to click Start and wait for your data to load. The time it will take to extract the data depends on your predefined number of results, and whether you selected video details when scraping a YouTube channel.
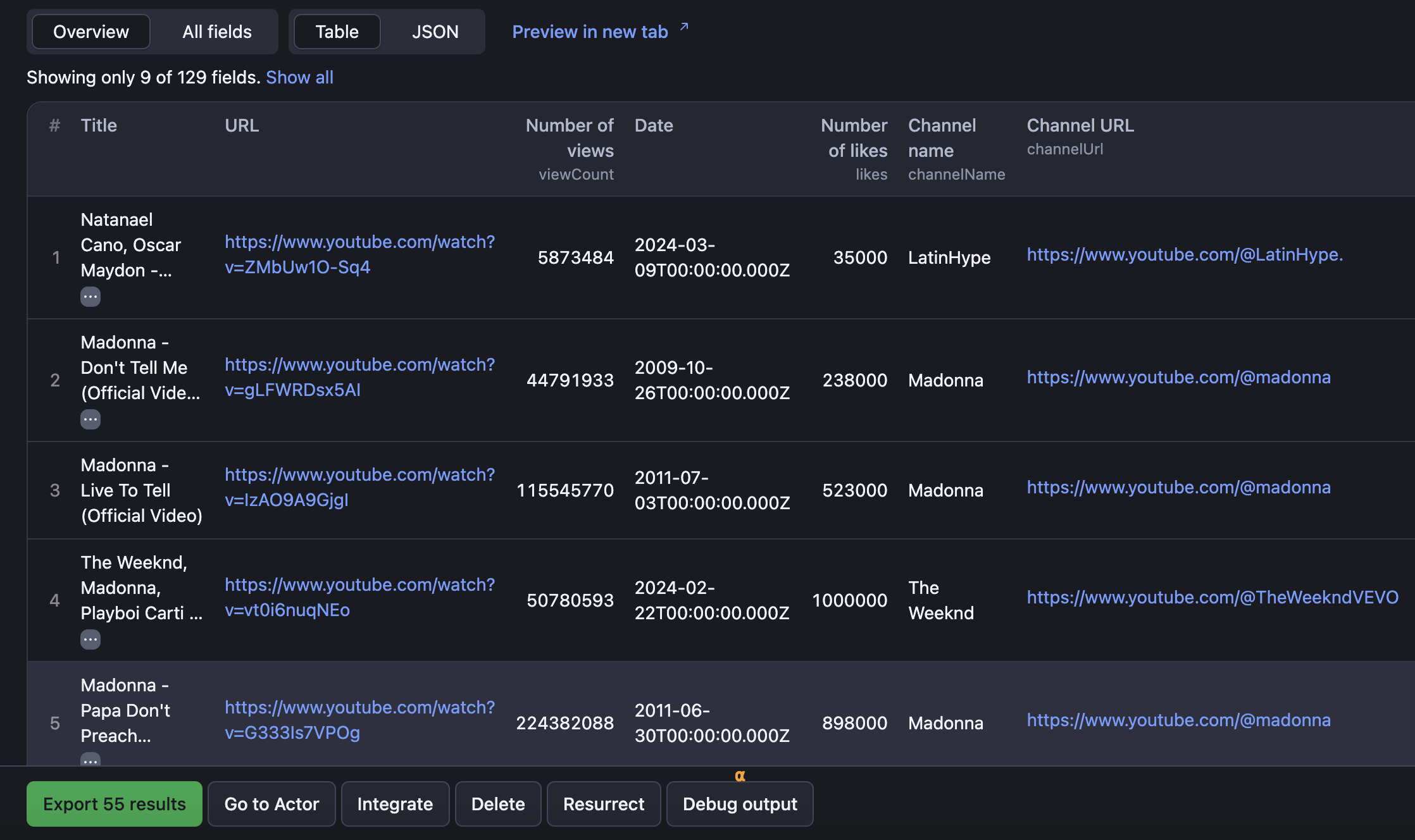
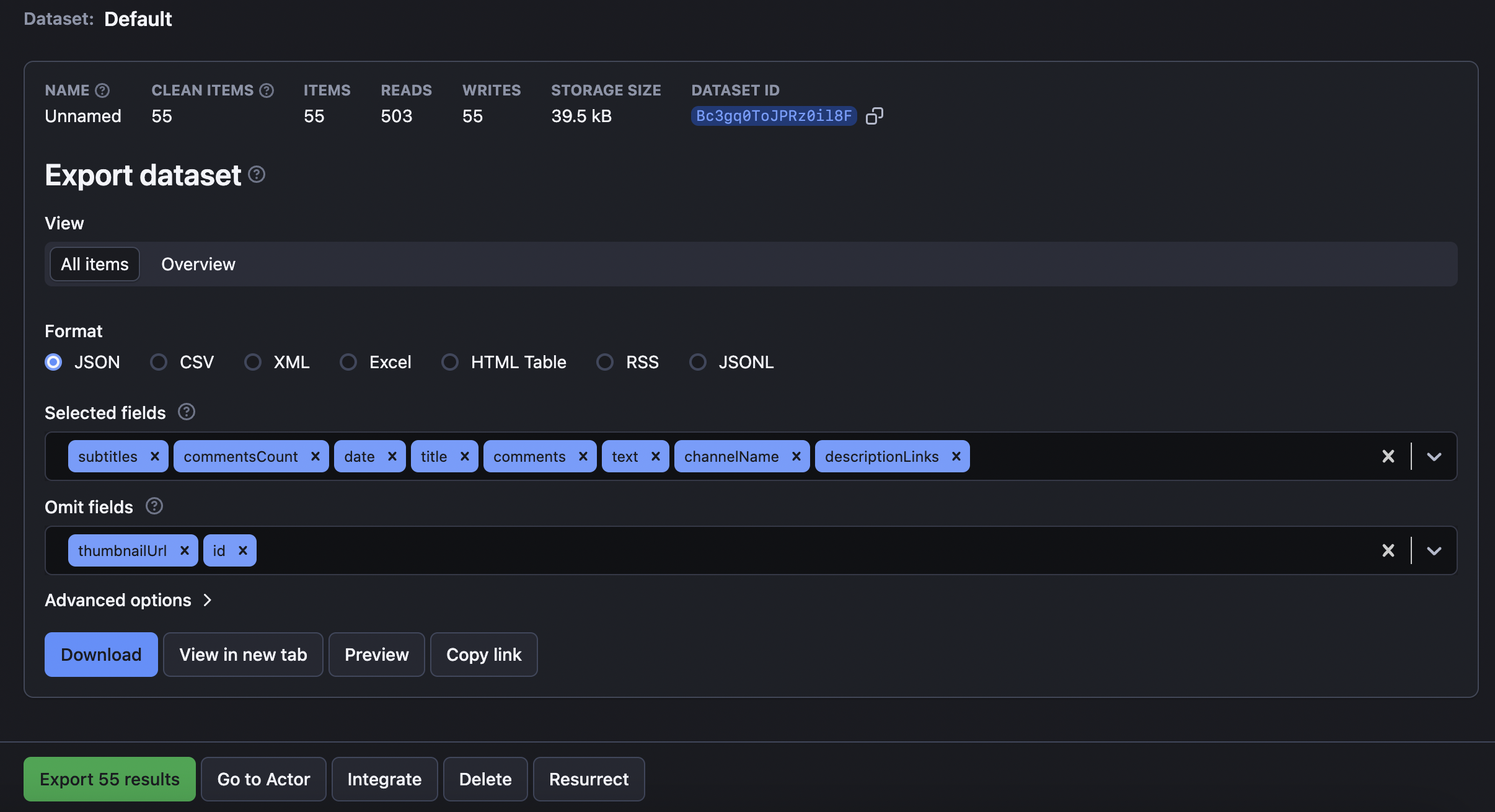
Step 6. Preview and export your listings
To see the complete results after the extraction is over, head on to the Storage tab. Here, you can download YouTube data in different formats, such as Excel, JSON, CSV, XML, HTML, or RSS. You can also prefilter the fields you want to extract or omit. Just proceed to the Export button and choose your parameters in the pop-up window.
Now that you know how to scrape YouTube, you can take it a step further and dig deeper into its input options, connect it to other web apps with Apify Integrations or maybe even try building your own scraper and monetizing your code.
YouTube API vs. YouTube scraping
YouTube does have its own API enabling you to do some basic content search and collect data from each video. However, the YouTube API has significant limitations: YouTube scraping is limited to video data, subscriptions, recommendations, ranking, and ads. In addition, YouTube API has a strong anti-scraping system in place, and it requires you to log in and imposes quota limits.
It seems like what you need is some kind of scraper that is flexible enough for various parameters, simple enough to use, but also strong enough to withstand the anti-bot blocking. Sure, you can try your hand at coding your own scraper. But why reinvent the wheel when you can try our ready-made tools, like our YouTube Scraper.
Does YouTube allow web scraping?
Most data found on YouTube is accessible to the general public, making it legal to scrape. But it’s still important to comply with regulations that deal with personal data and copyright protection. To learn more about the legal context of web scraping, check out this blog article on the subject.
More YouTube scraping tools
How do I scrape YouTube Shorts?
To scrape YouTube Shorts, you can use either the YouTube Scraper (by both Search term 🔍 and Direct URLs 🔗 sections) or the YouTube Shorts Scraper. Both are good fits for this scraping case; YouTube Shorts Scraper is simply more focused scraping tool.
How do I scrape YouTube emails?
To scrape emails from YouTube channels by search word, use the YouTube Email Scraper. However, please note that scraping emails is close to scraping personal data and requires you to log into YouTube.
How to scrape YouTube channels?
To scrape YouTube channel details, you can use either the YouTube Scraper (in the Direct URLs section) or the YouTube Channel Scraper. Both are good fits for this scraping case; YouTube Channel Scraper is simply a more focused scraping tool.
How to scrape YouTube comments?
YouTube Scraper doesn't scrape comment text or commentator details; it only scrapes the total comment count under each video. To scrape comments from YouTube, use the YouTube Comments Scraper. This tool will extract comment text, author name, date posted, vote count, reply count, and more.
All in all, YouTube offers a vast array of content, from DIYs to live streams. Now, you can scrape this data, and we’ll show you how. You can use YouTube data to:
- Calculate brand mentions and audience reach.
- Assess ROI for ads or referrals.
- Improve YouTube SEO.
- Monitor brand awareness.
- Analyze the success of your marketing campaigns by assessing activity during live streams.
- Feed video editors and AI video generators to make creating videos easy.
- and more!





