
Content
Searching for contact information on the web can be painful. If you’re lucky, finding the right email address may be a matter of a few clicks. But what if you also want to find phone numbers, LinkedIn profiles, and Twitter handles? And what if you need to find hundreds of them?
Today, everyone has different habits when it comes to their online presence, so getting in touch with someone often entails finding all possible ways of contacting them. Doing this job manually is a nightmare, especially if multiple web pages or websites need to be inspected. Luckily, you can automate this job using a technique called web scraping, which lets you automatically extract meaningful data from websites, find people on Messenger, TikTok, etc., and gather additional information from various online sources.
Apify's Contact Details Scraper will do the job of scraping contact information for you. In general, scrapers are a great tool for web scraping, automation, and data extraction tasks, including but not limited to scraping emails and other contact details.
The scrapers we make are called Actors, cloud programs running on the Apify platform, and you can find lots of them in our Apify Store. The job of these Actors is to automatically crawl the web pages of your choice, scrape the contact information from them, and then save it so that you can download it in Excel, CSV, JSON, or HTML formats.
What can you do with all that contact details data?
So why would you scrape contact details data? Here are just some compelling reasons to use web scraping to collect contact information:
Data collection made simple, cost-effective, and time-efficient
Scraping contact details is a much-requested solution from many marketing teams in every line of business. Why? Because web scraping emails, names, and phone numbers mean no more manual work to get the data. This way, web scraping tools save the resources of the marketing and sales teams for tasks that truly matter and have the potential to make an impact on the success of their business. Additionally, employing tools that effectively manage your emails can further streamline your communication processes, ensuring a more organized and efficient approach to email outreach.
Contact Details Scraper can harvest contact data in minutes compared to what it would take a human. This results in lead generation being a much less complicated, but more affordable and time-efficient process than it would’ve been if data gathering was done otherwise.
Make data the cornerstone of sales and marketing work
You might be surprised, but good sales work is always about data first. An automated approach to harvesting contact details can easily be considered a first big step in organizing the whole workflow of building targeted lead lists. And if not a first big step, then at least a very important element of that workflow of filling up and maintaining a working database of contacts, leads, and prospective customers.
Moreover, if the data that the scraper collects is of universal format and therefore can be integrated with other data processing and data classification tools, the lead generation process is on a solid path to getting automated. Lastly, implement a DMARC policy to ensure secure communication channels, protect sensitive information, and maintain trust with customers and partners.
Streamline your sales funnel with leads generation
Last but not least, contact scrapers to connect all lead generation channels into one: that can include anything from the company website and landing pages to event-specific content and social media. As the team gets comfortable with automated processes that are already in place, you can add more or adjust them to the new business challenges.
And if that isn't enough to get you thinking about what you can do with the data, you can check out our industry pages for use cases and more inspiration.
You can also find Email & Phone Extractor on Apify Store. This scraper works in a similar way to Contact Details Scraper but provides an extra input field. The Pseudo URLs input field allows you to set an order for the websites to scrape (using regex). That means that the email extractor won't waste time crawling pages you might not be interested in. This can be handy when scraping large websites. For all the other input fields, the same tutorial below will work fine. 👍
Disclaimer: privacy of personal data on the web is of our highest priority and we are fully committed to adhering to the personal data protection legislation. Luckily, there are many ways to collect data ethically, legitimately, and for a good cause. For instance, we’ve cooperated with NGOs and law enforcement institutions on investigations of juvenile sex trafficking. You can find much more information concerning data privacy on the web and how to create ethical scrapers in our recent post: Is web scraping legal.
Step-by-step guide to scraping emails
Our Contact Details Scraper enables you to automatically scrape emails, phone numbers, as well as Facebook, Twitter, LinkedIn and Instagram profiles from web pages. In this short tutorial, we'll show you how to do that by scraping our very own website, apify.com, for contact details. Let's get started!
Sidenote: tech-savvy users will find the technical terms used for extraction at the end of the article.
1. Go to the scraper's page, and click the Try for free button.
2. If you are not signed in, you’ll find yourself on the sign-up page (if you are already signed in, skip to Step 3.) Sign up using your email account, Google, or GitHub.
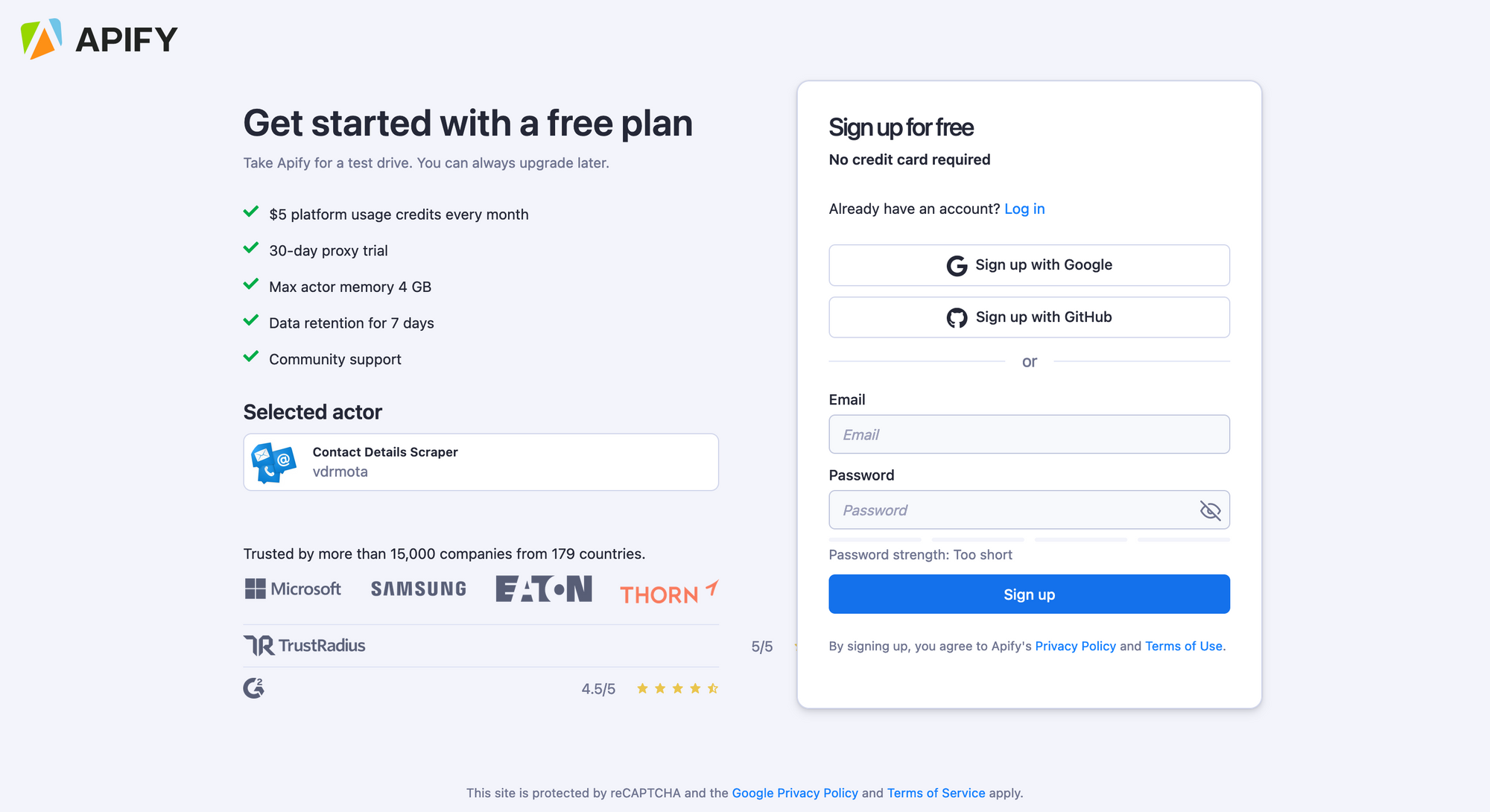
3. You will be redirected to the scraper’s page on your Apify Console. Apify Console is your workspace to run tasks for your scrapers. You can now fill in all the required fields on the Input display. The Actor won’t run until you click the Run button at the bottom of the page.
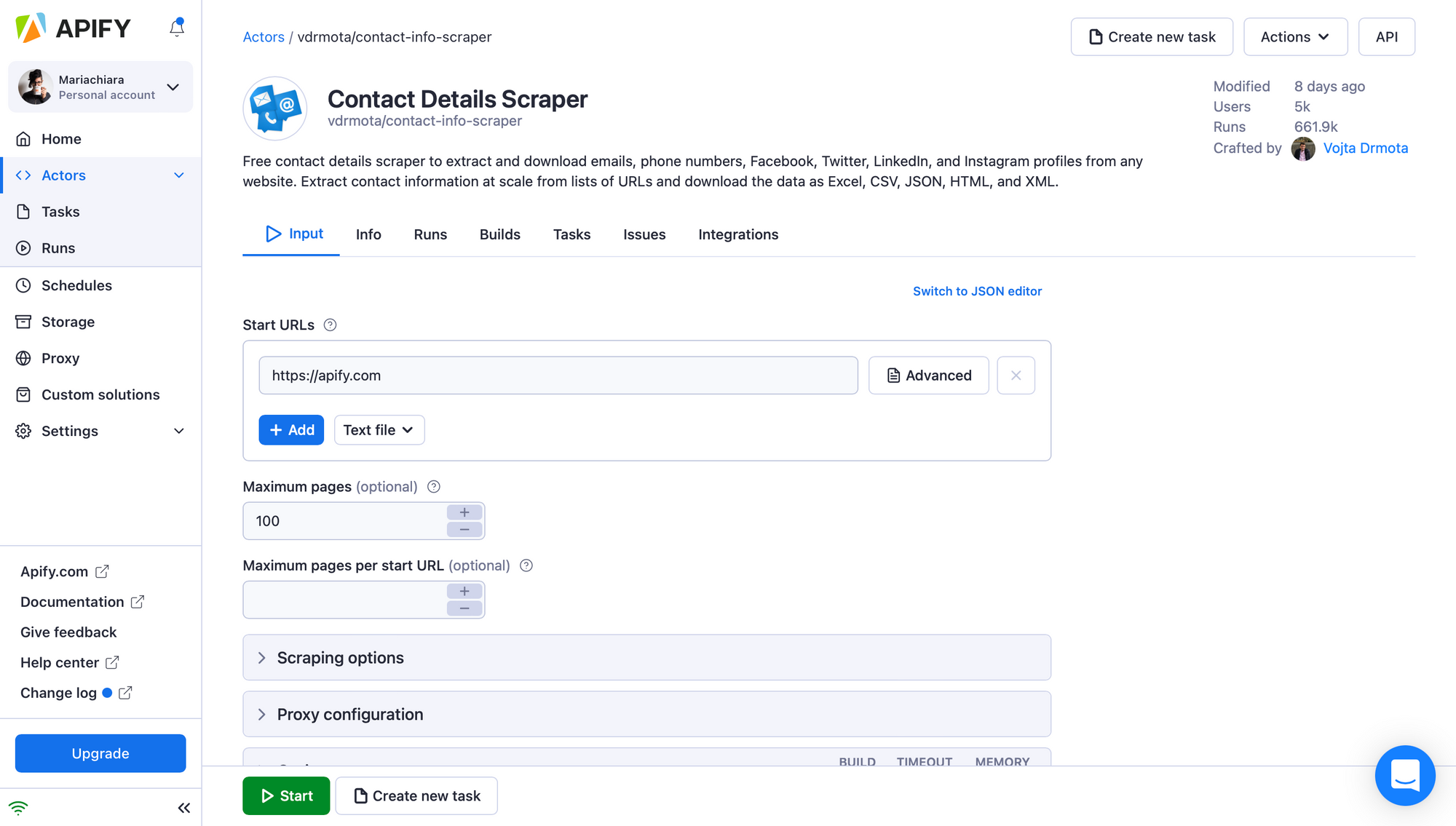
4. Under input, the Actor has several input options that let you specify which pages shall be crawled. Let's scrape the Apify website for all the emails and phone numbers that the website contains:
- Start URLs — A list of URLs of web pages where the crawler should start. You can enter multiple URLs, a text file with URLs, or even a Google Sheets document.
- Maximum link depth — Specifies how many links away from the web pages specified in Start URLs shall the crawler visit. If zero, the Actor ignores the links and only crawls the Start URLs.
- Stay within the domain — If enabled, the Actor will only follow links that are on the same domain as the referring page. For example, if this setting is enabled and the Actor finds on a page www.example.com/some-page a link to www.another-domain.com/, it will not crawl the second page, since www.example.com is not the same as www.another-domain.com
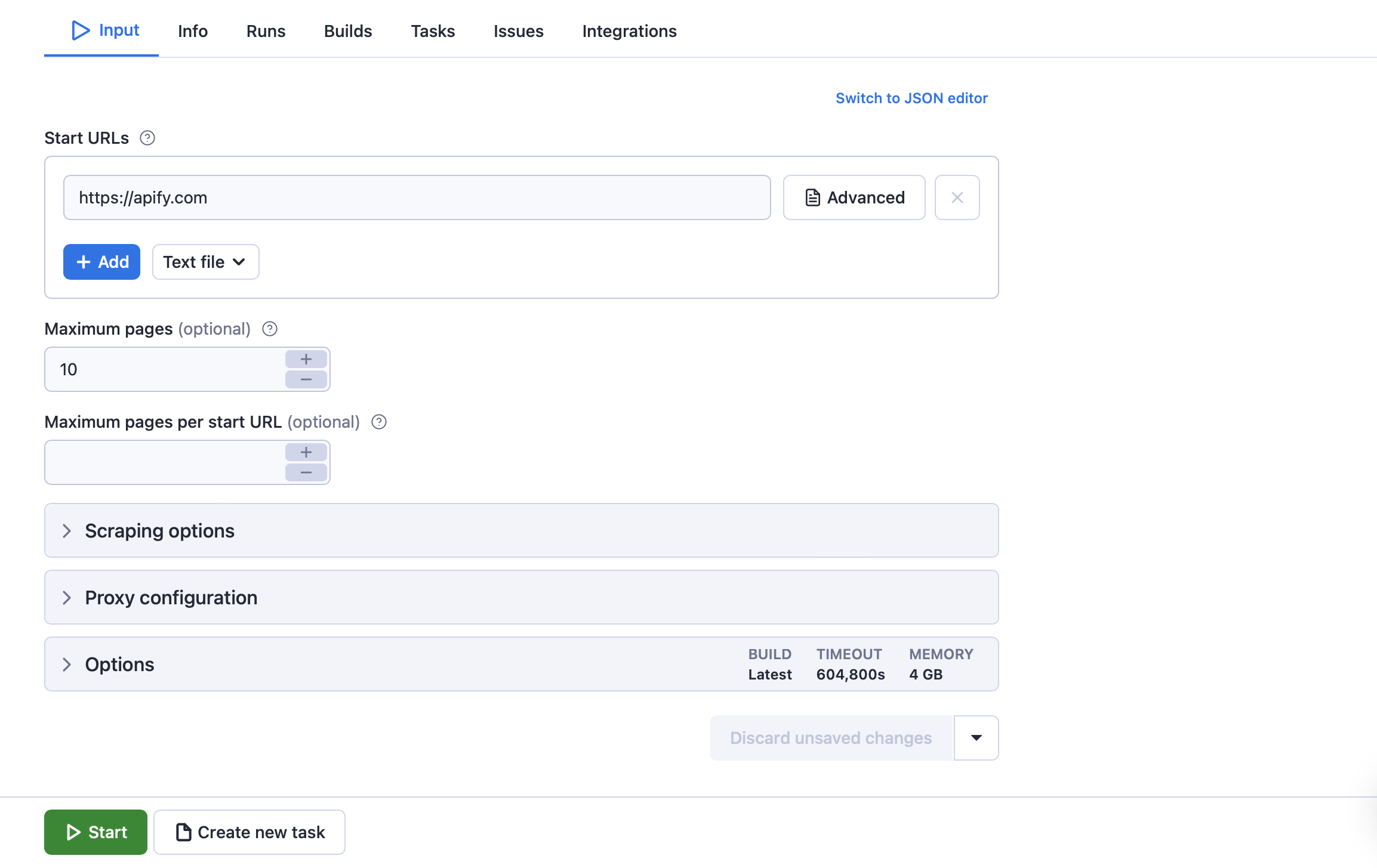
Note that the Actor accepts additional input options to specify proxy servers, limit the number of pages, etc. See Actor input for details. Once you’re all set with the input settings, click the Run button.
5. Once you are all set, click the Run button. Notice that your task will change its status to Running, so wait for the scraper's run to finish. It will be just a minute before you see the status switch to Succeeded.
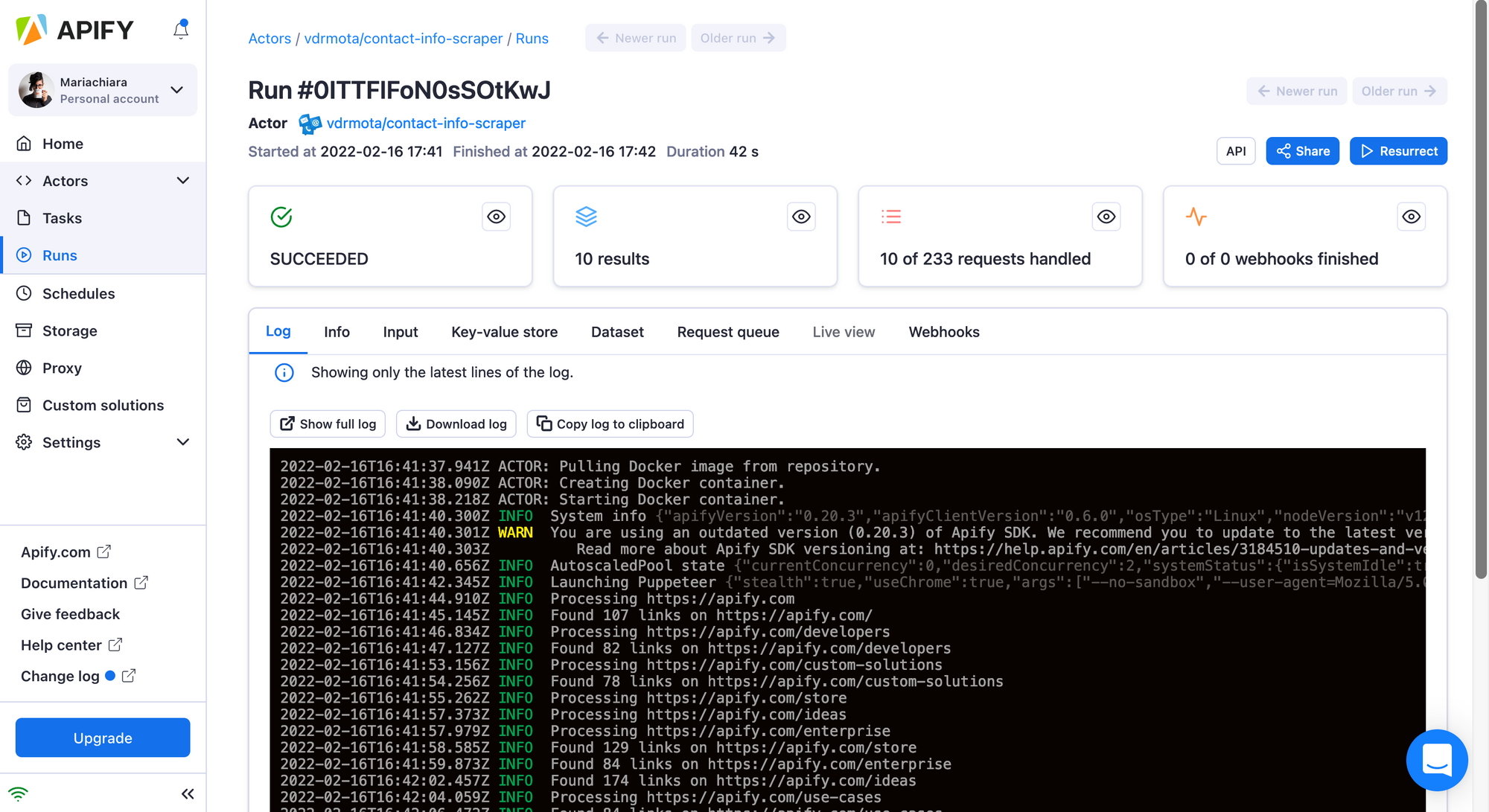
6. After the Actor finishes the run, you can preview your contact scraping results by clicking on the Dataset tab.
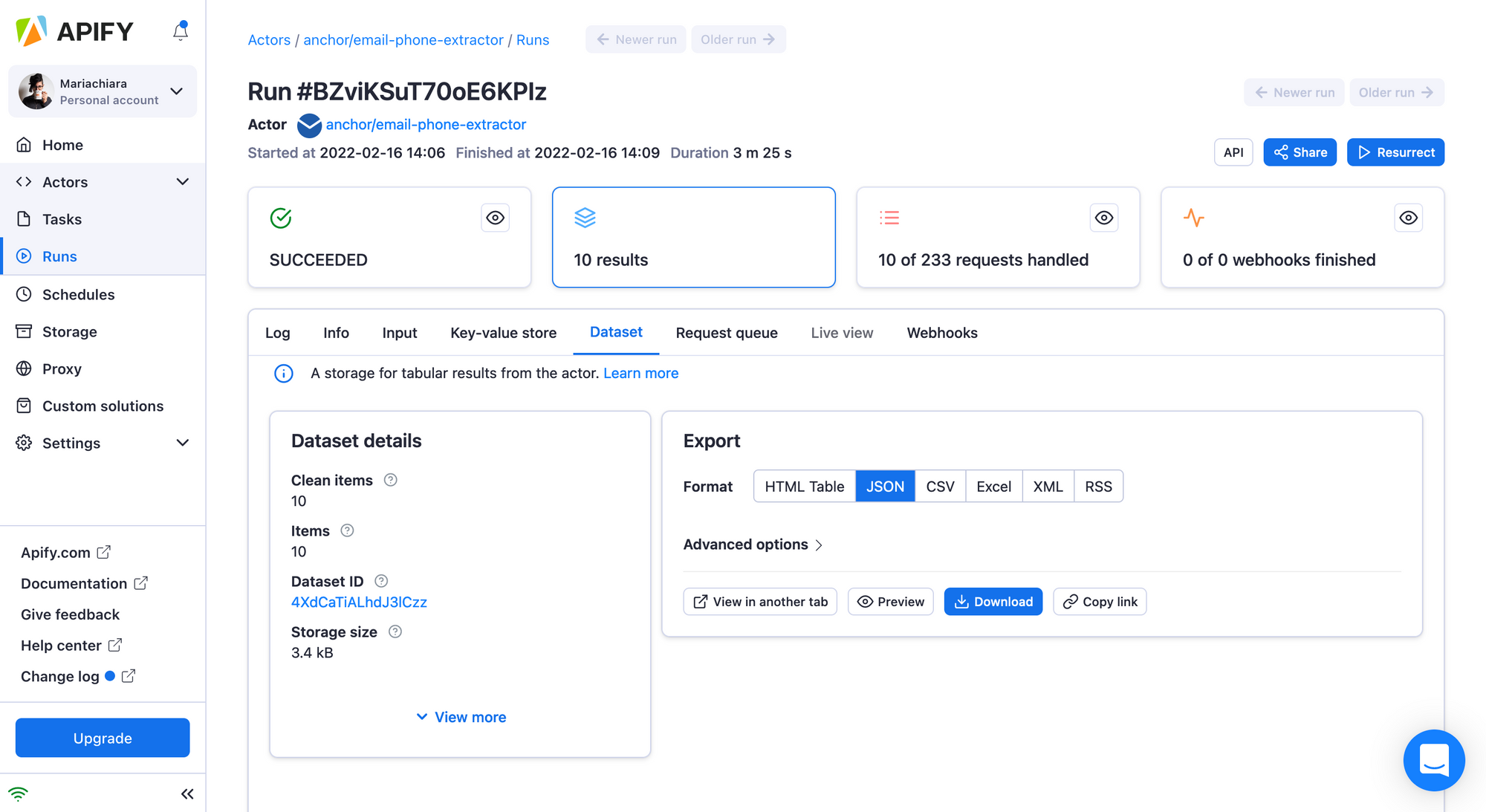
7. You can download the results in various formats such as Excel, CSV, XML, HTML or JSON and then upload them into a database.
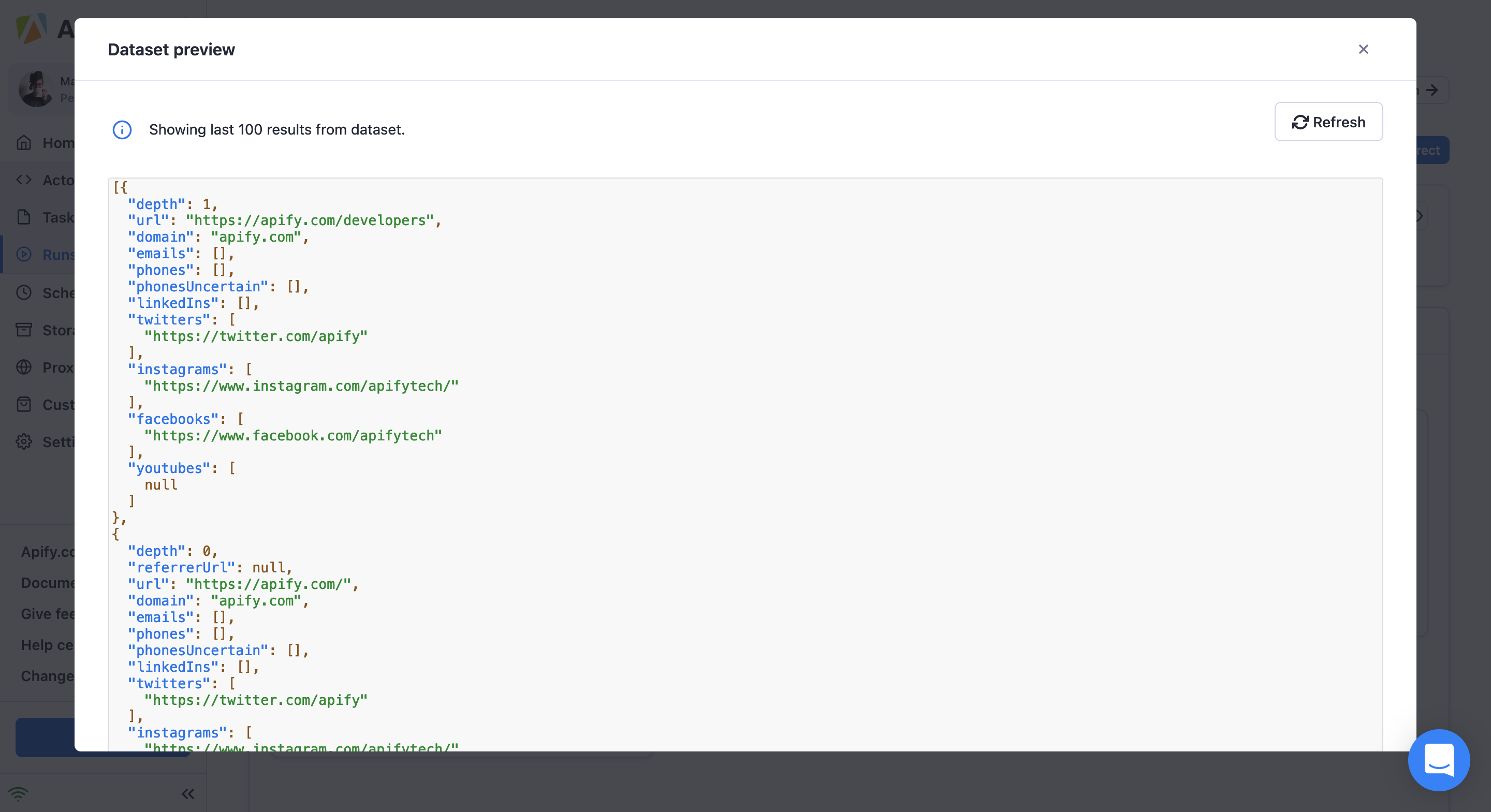
The technology behind the Actor
The Actor is built in Node.js and uses Apify SDK — an open-source web scraping and automation library. The full source code of the Actor is available on GitHub.
When started, the Actor loads the web pages provided in Start URLs. It does so using Google’s headless Chrome browser, with the help of the Puppeteer library. Through Puppeteer, the Actor is able to simulate user inputs on the web page, such as clicks and scrolling. The Actor looks for any links to other pages on the website and crawls them recursively, easily using the PuppeteerCrawler class provided by Apify SDK.
Once the web page has loaded, the Actor downloads the web page’s HTML source code. By using headless Chrome, the downloaded HTML represents the actual content of the web page that the user would see, including dynamic content loaded using AJAX. This allows the Actor to extract all contact details as they are presented on the pages.
To extract contact details from the HTML, the Actor harnesses the power of regular expressions. Below are a few of the regular expressions used to extract contact information from HTML (ECMAScript / JavaScript format). You can test them on regex101.com. Note that all the expressions are provided by the Social Utils in Apify SDK (see source code).
 Ayodele Aransiola
Ayodele Aransiola
Final points
If you need to have more control over the crawling and data extraction process, you can fork the Actor on GitHub and build your own version, or go for a customized version from us. For more details on building your own scraper, see our Actors documentation and our Apify SDK library.
Just to reiterate - it's important to stay informed and vigilant about how we share our personal data on the web, including but not limited to scraping contact details data. Personal data on the internet is a very sensitive and progressive subject that should be discussed more in the IT and legal communities, which is why we’ve done our research as well and are fully committed to the goal of ethical web scraping.
And that’s everything you need to know to get started using this Actor. Be sure to check out other Actors, such as Email & Phone Extractor, in Apify Store – they're just as great. And if you come up with anything fascinating on how to use that scraped data, we’ll be happy to hear about that from you on Twitter :)



