


Need Instagram data the official APIs won't give you? Instagram Scraper handles profiles, reels, posts, comments, mentions, hashtags, and location tags without a Facebook app, an auth token, or a single line of code. Use it to track competitors, brief AI agents, or build lead lists. It's one of the original Actors on Apify, the marketplace of tools for AI.
Here's how it works.

Why not use the official Instagram API for scraping?
Instagram does provide two free public APIs that can be used for various purposes, including web scraping and data extraction. But would those APIs be enough for scraping Instagram?
Not really. The official public Instagram API comes in two forms:
- Instagram Basic Display API
- Instagram Graph API
Both allow you to programmatically access Instagram posts. However, the extent and scope vary depending on the API type.
Instagram API with Business Login for Instagram
You can't use the Instagram Graph API to get regular Instagram user data; it's created specifically for Instagram business accounts and creators.
Besides, accessing this API requires an Instagram Business or Creator account, a Facebook page connected to this account, a Facebook Developer account, and a registered Facebook App with basic settings.
You don't have to jump through any of these hoops if you're using Instagram Scraper. And you don't have to apply any technical skills unless you want to.
How does this Instagram web scraper work?
It's built to take a list of Instagram URLs or search queries and then search for and scrape profile details, posts, or comments from those URLs. Using similar logic, it can scrape the Instagram feed guided by one or multiple search queries.
All of the resulting data is stored in a structured form as a dataset. You can download it in formats such as JSON, XML, Excel, and CSV. You can also extract it using API Endpoints or a Client (Node.js or Python), which turns this scraper into a full-fledged Instagram API of its own.
What data can I extract from Instagram?
Instagram Scraper lets you download public data from the platform, namely:
- Profile info
- Posts and reels
- Hashtagged content (Posts and Reels)
- Mentions or tagged posts, pinned content, and new posts
- Comments and replies
- Hashtags, their connections, and volume
- Search results (users and tagged places via Google Search)
- Various metrics (likes, comment count, share count, followers and follows count, play count, and video duration)
- Media (audio, video, images, video transcripts)
Not everything is possible to scrape from Instagram. See the ❓FAQ section below for exceptions. Here's a more detailed list of what your regular Instagram dataset could look like:
| Profile ID, username, full name, and URL | Bio and external URLs | Profile picture URLs |
| Followers and follows count | Verified status | |
| Post ID, caption, and hashtags | Post URL and shortcode | Comments and likes count |
| Timestamp | Mentions in the post | Image URL |
| Business account and category | Private account | Post likes count |
| Joined recently status | Has channel status | Related profiles |
How to scrape Instagram 101
Let's learn how to use Instagram Scraper to extract data from Instagram profiles and their posts. This step-by-step guide will get you started in just a few minutes.
Step 1. Go to Instagram Scraper
Click the Try for free button to sign up for a free Apify account and start using Instagram Scraper. You'll get $5 of monthly platform usage, which you can use with this or any tool on Apify Store.

You can sign up for free using your Gmail account, other email provider, or GitHub. After this, you'll be redirected to Apify Console, which is your workspace to run tasks for your scrapers, such as scraping profiles, posts, hashtags, and so on.

Step 2. Add Instagram URLs or usernames to start with
Head over to the Instagram website and pick the profiles you want to scrape. Copy and paste each profile URL into the input. You can add as many profiles as you want using the + Add button, or upload a whole list of them at once using the Bulk edit button nearby.
What kind of URLs can Instagram Scraper use?
- Profile URLs, IDs, usernames: https://www.instagram.com/natgeo/ or natgeo → to get profile details
- Post URLs: https://www.instagram.com/p/DUYkP6ijMY6/ → to get post details
- Reel URLs: https://www.instagram.com/reel/DUWTKLFDMe8/ → to get reel details
- Hashtag URLs: https://www.instagram.com/explore/tags/crossfit → to get hashtagged reels or posts
- Location tag URLs: https://www.instagram.com/explore/locations/7538318/copenhagen/ → to get location details
Step 3. Set your scrape type and max items
Then choose Details from the drop-down list of what you want to scrape: posts, reels, mentions, profiles/hashtags, or comments. The content type you want to scrape has to correlate with the chosen URL. For example, if you're scraping comments, you should provide the post URL to get them from; if you're scraping profile details, then it has to be a profile URL. Now insert the maximum number of items you want to scrape in the Max items field. We're going to put 200.
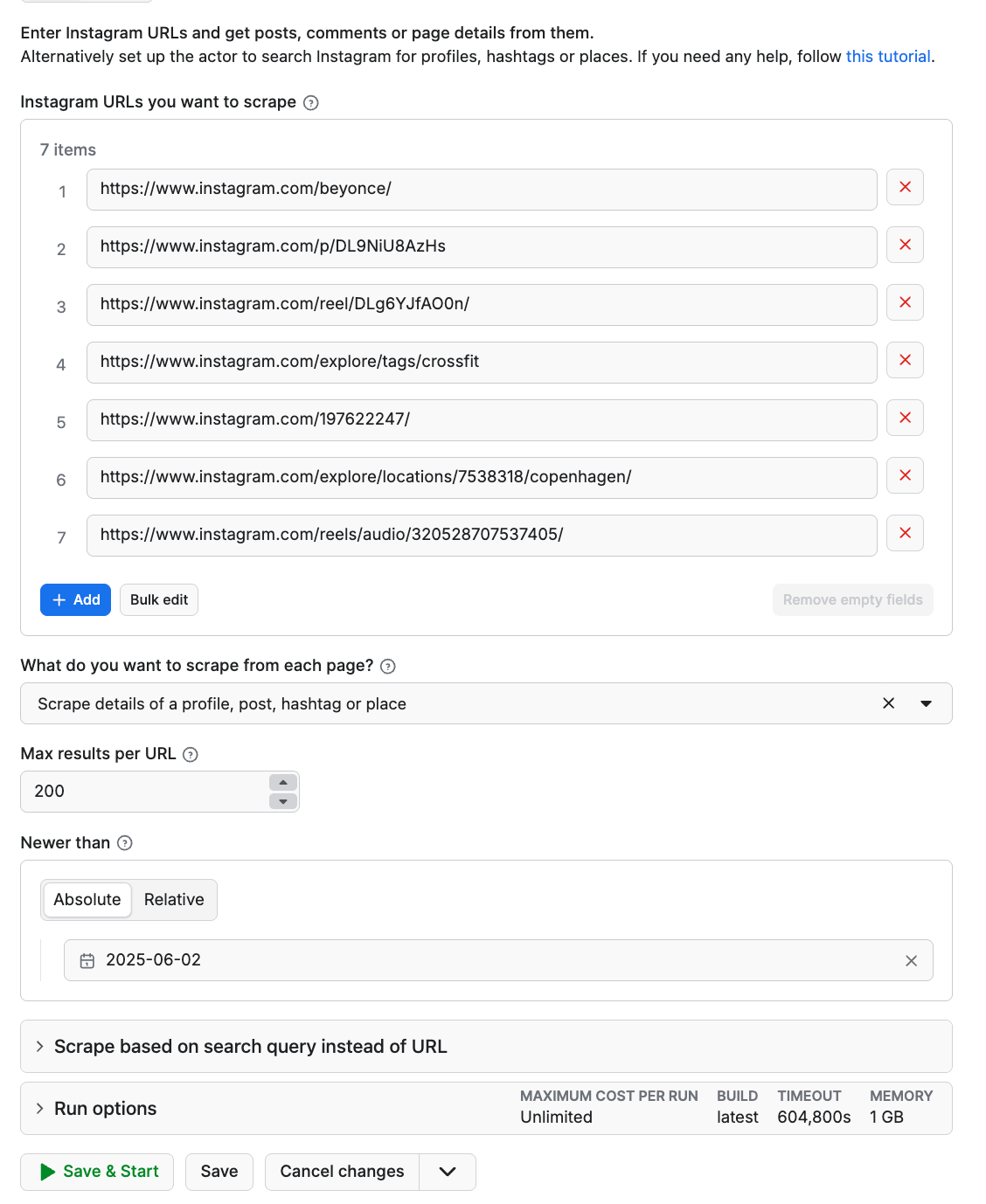
You can also choose an extra time filter for this scraper, Newer than, to scrape only the posts that fit a certain time period. You can set this filter up to scrape comments and posts, or scrape the Instagram feed using search queries (see next step).
Step 4. Add search queries
Alternatively to URLs, you can also scrape Instagram search results. This section is especially useful when you're only starting Instagram research or discovery.
- Search queries: winterolympics → to get tagged places, discover users, or find hashtags associated with this keyword
Warning: do not combine inputs from the top section (URLs) and the bottom section (search queries). URLs will always override the search queries. Make sure to delete all URLs if you want to scrape search results.
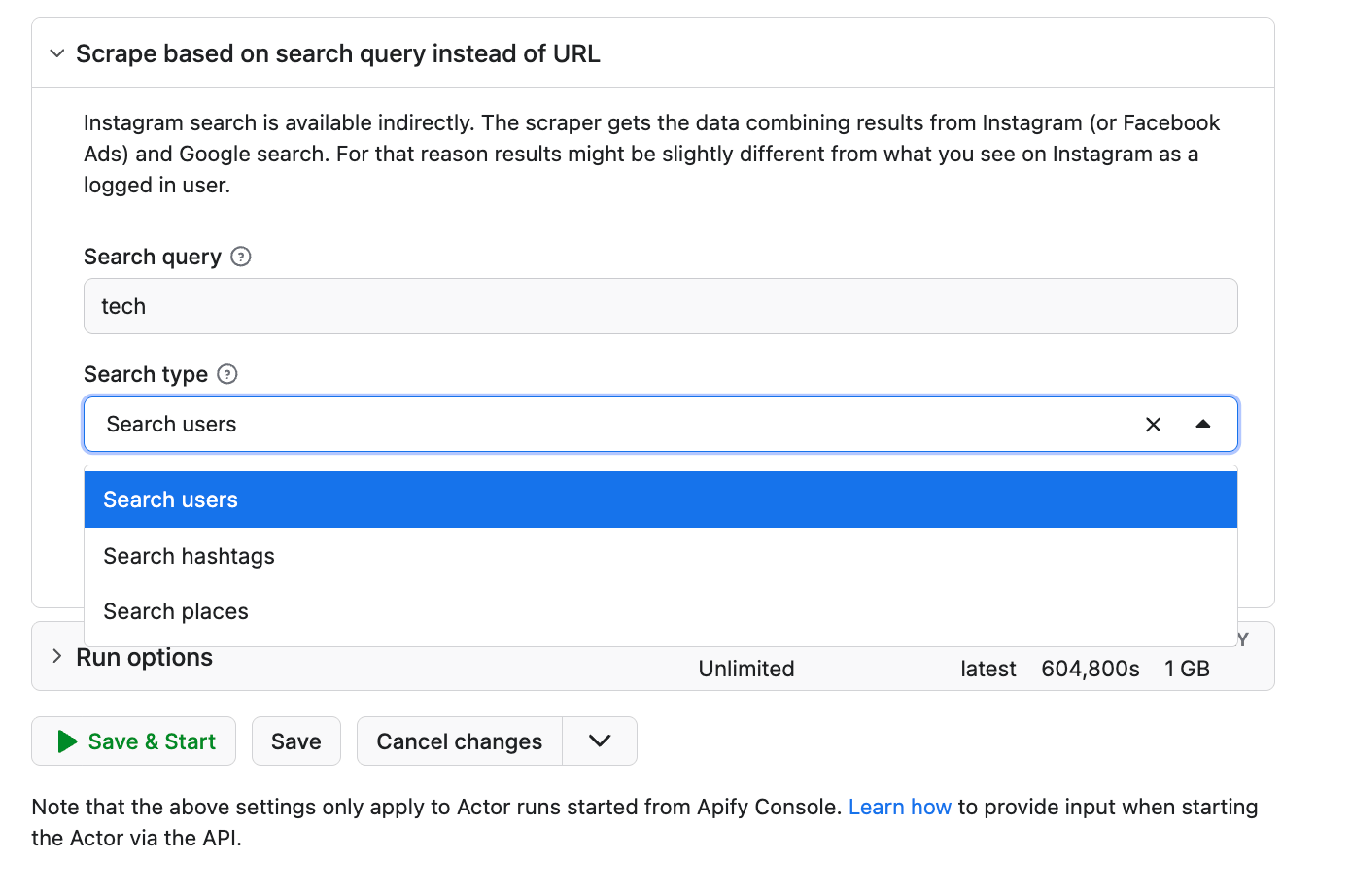
Step 5. Click Start ▶️ to run the web scraper
Once you are all set, click the Start button. Your task will change its status to Running 🏃🏻♀️, so just wait for the scraper's run to finish. It will be a minute before you see the status switch to Succeeded ✅ - 10 seconds in this case.
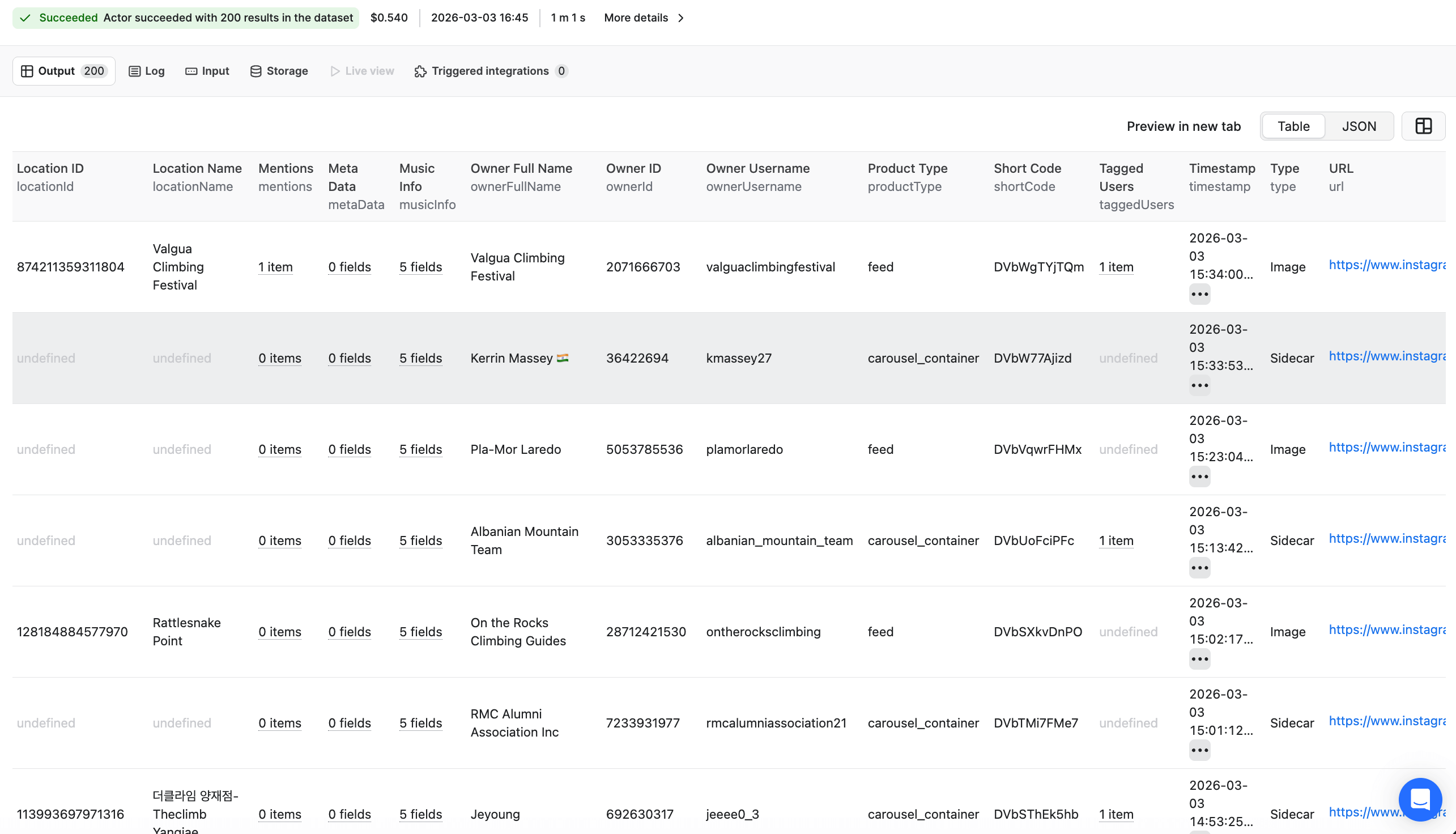
Each username we scraped will come up as a separate result, which is why our output says 3 results. At the end of the run, you will see a preview table with Output results.
Step 6. Export your Instagram data
Now you can move to the Storage tab to view all the results of your scraping. This tab contains your data in lots of versatile formats: HTML table, JSON, CSV, Excel, XML, and RSS feed.
You can open them by clicking on View in another tab, Preview, or Download. You can then share the data or upload it anywhere you like. You can also clean and preprocess the scraped data before downloading it by removing any irrelevant information.
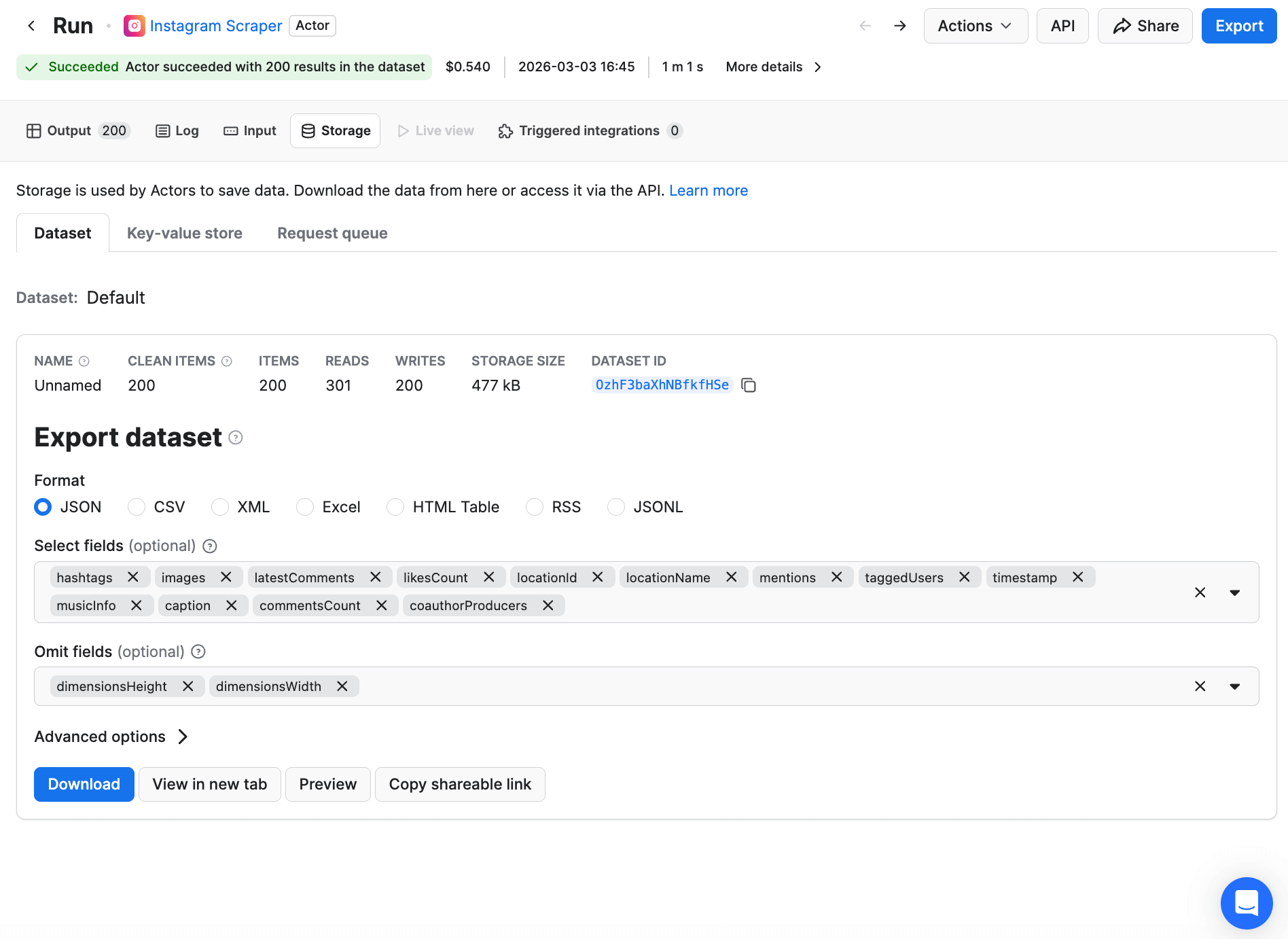
Here, in our example, we only want username, latest posts, follows count, related profiles, and some other details such as bio, profile pic, and URL in the dataset. In order to export only that data, we'll choose the relevant tags from the list of Selected fields before downloading them.
Step 7. Bonus: Use the data, automate the pipeline
What you do with the data is the fun part, and there are plenty of ways to use it. Spot trends in hashtags before they peak, find influencers and track their engagement, pull sentiment from comments, or run market research that goes deeper than surveys.
Any of those can run on autopilot. Schedule the scraper to refresh nightly, pipe results into integration platforms like Zapier, n8n, or Make, or pull them through the API. Same Actor, hands off.
Prefer video? Watch this tutorial on how to scrape Instagram data
Just want to extract Instagram reels, comments, or ads?
You can use the Instagram data scraper from this tutorial to scrape data from Instagram in multiple ways. However, if you want to scrape specific Instagram data, let's say comments only, you might like our dedicated Instagram web scrapers more.
Compared to the original IG Scraper, there are fewer settings to change, and you'll get fast, precise results. As a rule, all you have to do is paste one or more Instagram URLs (or usernames) and click to scrape.
These dedicated scrapers are a better fit for incorporating into agent workflows. Because, unlike Instagram Scraper, which has a dozen possible outputs due to its versatility, these scrapers have specific, invariable outputs, e.g. Comment Scraper → only comments, Reels Scraper → only reels.
Explore all Instagram tools:
❓ FAQ
What about Instagram Ads? Can this scraper extract ads from Instagram?
No, this scraper cannot scrape ads. You can scrape ads from Instagram (both static and video, from different brands and locations) using Facebook Ad Library Scraper.
However, you can use Instagram Scraper to extract brand collaborations on creators' grids. These are not technically ads but content that a brand created together with a creator.
What Instagram data is available without login?
There isn't much Instagram data that's publicly available without a login.
Search. Instagram search is no longer available without a login. Results scraped via workarounds (like Google Search) may differ in order from native Instagram search.
Profiles, hashtags, and locations. Public Instagram pages (profile, hashtag, or location) only preload a handful of posts without login. You can't scroll further, and even the See more posts button on profiles has limits.
Comments. Comments and infinite scroll were once public. That data is no longer available without a login.
Our scrapers do not support logging into Instagram, so there are some limits on what you can and cannot scrape. Our scraper is capable of getting around those limitations (such as using proxies or Google Search results), but only to an extent.
Can I get the behind-login data from Instagram?
In theory, yes. But this is not what the scraper can do. If you check the Instagram website in an incognito browser window, you'll quickly find that there's very little data that you can view and access freely without logging in.
Although it would be possible to log in to Instagram to access this data automatically, this approach is risky since it can lead to the banning of your account by Instagram. Sure, you could create a fake Instagram account and use that instead, but that's beyond the scope of this article and against Instagram's terms and conditions. We don't recommend that you do this, and none of Apify's tools support it.
Over time, Instagram has been increasingly limiting the data you can access without login, so you'll need to test to see what you can scrape without logging in.
Can I scrape Instagram stories or follower names without a login?
No. And we can't provide that either. Use community scrapers from Apify Store instead.
Can I scrape Instagram data through MCP?
Yes, here's the step-by-step guide.
Is this data compatible with Claude?
Yes, everything is compatible through our API. We even have these scrapers as Claude Skills to ease the transition.
Can I scrape both posts and comments in one go?
Yes, there's a dedicated scraper for that. You only need to provide a profile username to get both posts and comments: Export Instagram Comments and Posts.
With Instagram Scraper, you either scrape posts (by providing profile URLs/usernames) or comments (by providing post or reel URLs). Export Instagram Comments and Posts unites those two steps into one.
Can I enrich Instagram data with data from Google Maps?
No, but you can do the reverse. Scrape places from Google Maps and then enrich them with social media data using Google Maps Scraper.
Can I download reels or images from Instagram?
You can download reels using Instagram Reel Scraper. Instagram Scraper doesn't support reel downloads, but it does extract image URLs. To download them to your local folder, pair your scraped results with the Images Download Upload Actor via Actor-to-Actor integration.
Do you need proxies to scrape Instagram?
These days, you generally need proxies to have a successful and generally reliable scraping process. Social media websites often use blocking technologies to prevent scraping. We recommend using residential proxies as the most reliable way to go about scraping anything from Meta in 2026. Fortunately, Apify's free plan offers a free trial of residential proxies, so you can fully test this scraper tool on getting data from Instagram, Facebook, or Threads. And you don't have to set the proxies up; they are already built in and set up for your scraping success.
Can I use this scraper with API?
This Instagram Scraper is one of many Actors available in Apify Store. As with the other Actors, you can use this scraper directly on the platform with a few clicks, or using an API or scheduler. So basically, you can consider it your own personal Instagram API. You can call this Instagram web scraper using an API Client in Python, JavaScript, and curl. You can also use available API Endpoints to get the scraped Instagram data to where you need it.
Is it legal to scrape data from Instagram?
Scraping publicly available data is legal, but you need to be careful not to extract content that is protected by copyright or contains personal information. So, after scraping Instagram, double-check your output for data that would go against GDPR, CCPA, or could be considered intellectual property. Read more about the legality of web scraping,
Can I scrape both Instagram users and Threads users?
Since Instagram and Threads share userbase, you can scrape both Threads users and Instagram users since they share the same usernames and profiles. By using scraping techniques, you can extract data from both platforms simultaneously and get insights into user profiles and their activities on both Meta platforms. You may want to check out Threads Profile Scraper as well.





