


On paper, the Facebook Graph API looks like the natural choice for extracting Facebook data. In practice, it’s riddled with limitations that make it frustrating for anyone who wants structured access to public Page content. First, it’s permission-gated: you can’t retrieve most fields without submitting your app for Facebook’s review, which can take weeks and often ends in rejection due to complex Meta policies. Even after approval, the API enforces strict rate limits, caps on historical data retrieval, and returns data in rigid formats that aren’t always complete or up to date. To make matters worse, changes to API endpoints are frequent, meaning your integration can break without warning.
With Apify’s Facebook Pages Scraper, there’s no need for API keys, coding, OAuth tokens, or app review. You can extract page names, URLs, number of followers, contact details, categories, likes, and more from any Facebook Page, in real time. Here’s how.
Step-by-step guide to scraping Facebook Pages
Step 1. Go to Facebook Pages Scraper
Click the Try for free button to sign up for a free Apify account and start using Facebook Pages Scraper.
If you don’t have an Apify account yet, it’s easy to sign up with your GitHub or email account from any provider. You’ll enter Apify Console, a workspace to run or build web scraping tools.
Step 2. Choose one or several Facebook pages
Now that you’re on the scraper page in Console, it’s time to enter the URL of the Facebook page from which you want to extract posts. To do that, open facebook.com, find the page (or pages) of your interest, and copy the URL(s).

Copy the URLs and paste them into the Facebook URLs fields. For our example, we’ll use three Facebook pages - Starbucks, Coca-Cola, and McDonald’s. You can add as many URLs as you wish.
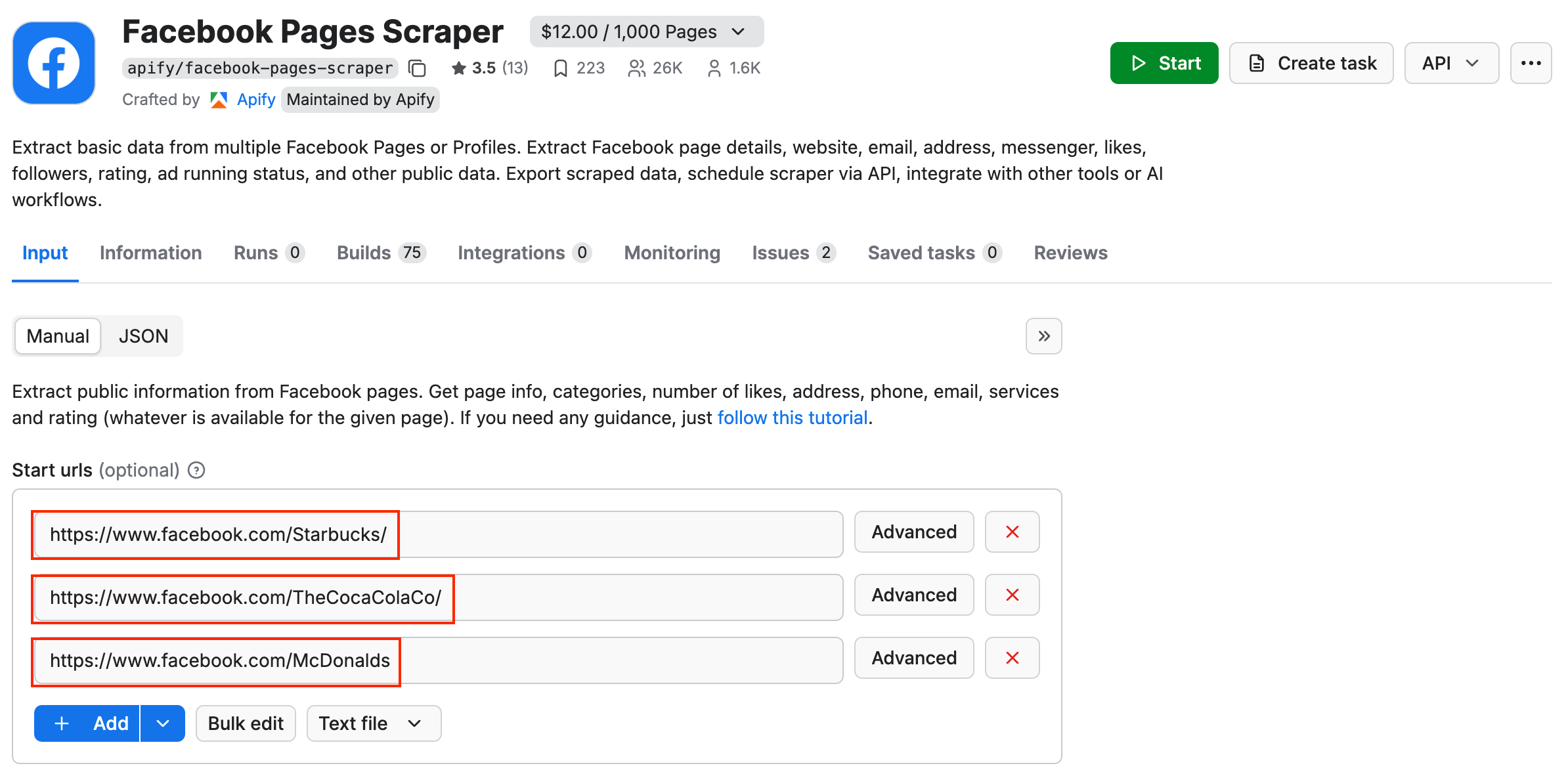
You can leave the additional options as they are, or limit the number of results. That way, you can also control the credit spent on this particular run.
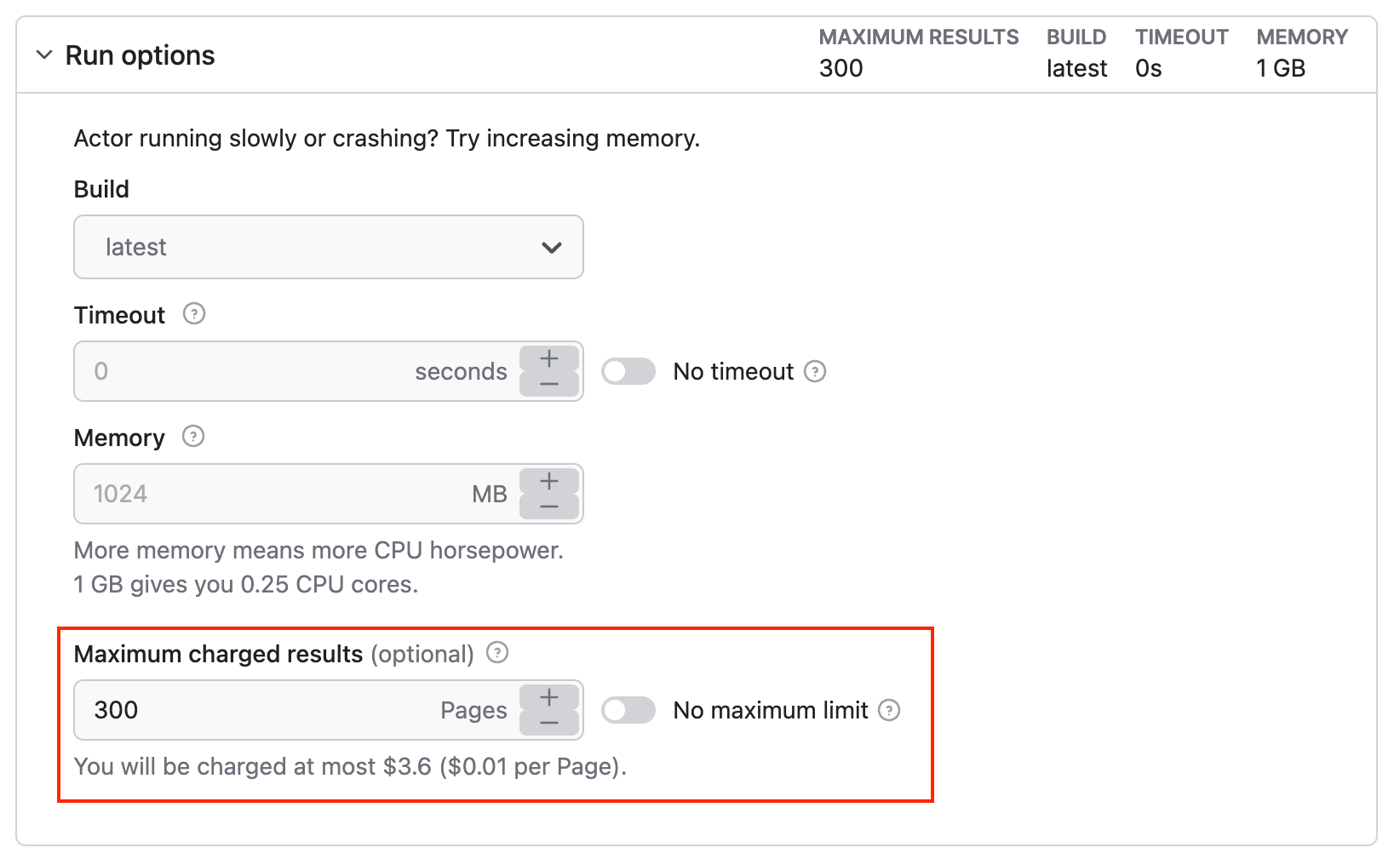
Step 3. Click Start
Once you’re all set with the URLs, hit the Start button. The scraper will begin data extraction from Facebook pages. The status will change to Running, and you’ll need to wait until the process is complete. It shouldn’t take long for the status to change to Succeeded.
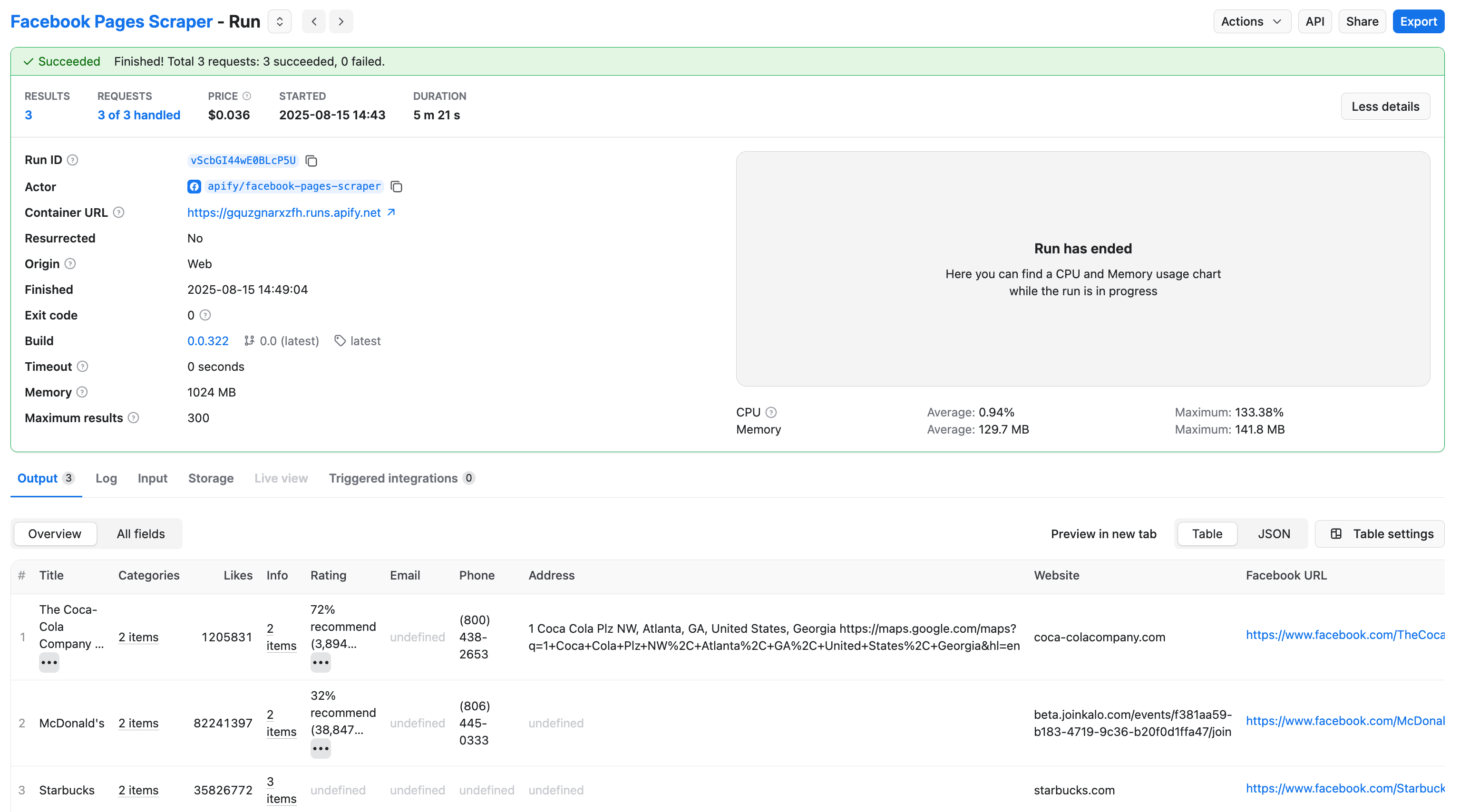
Step 4. Preview and download your data
Click on the Export button to download your data. The scraper has extracted information from all three pages, and the preview displays the page name, categories, number of likes, rating, contact information, and an official website URL. Choose your preferred preview format.
You can download Facebook data in several formats, including JSON, CSV, and Excel. You can customize your export and exclude fields you’re not interested in, reducing the information noise.
Now you can easily extract data from Facebook posts and save them in a format of your choosing. In this example, we chose JSON as our export output format.
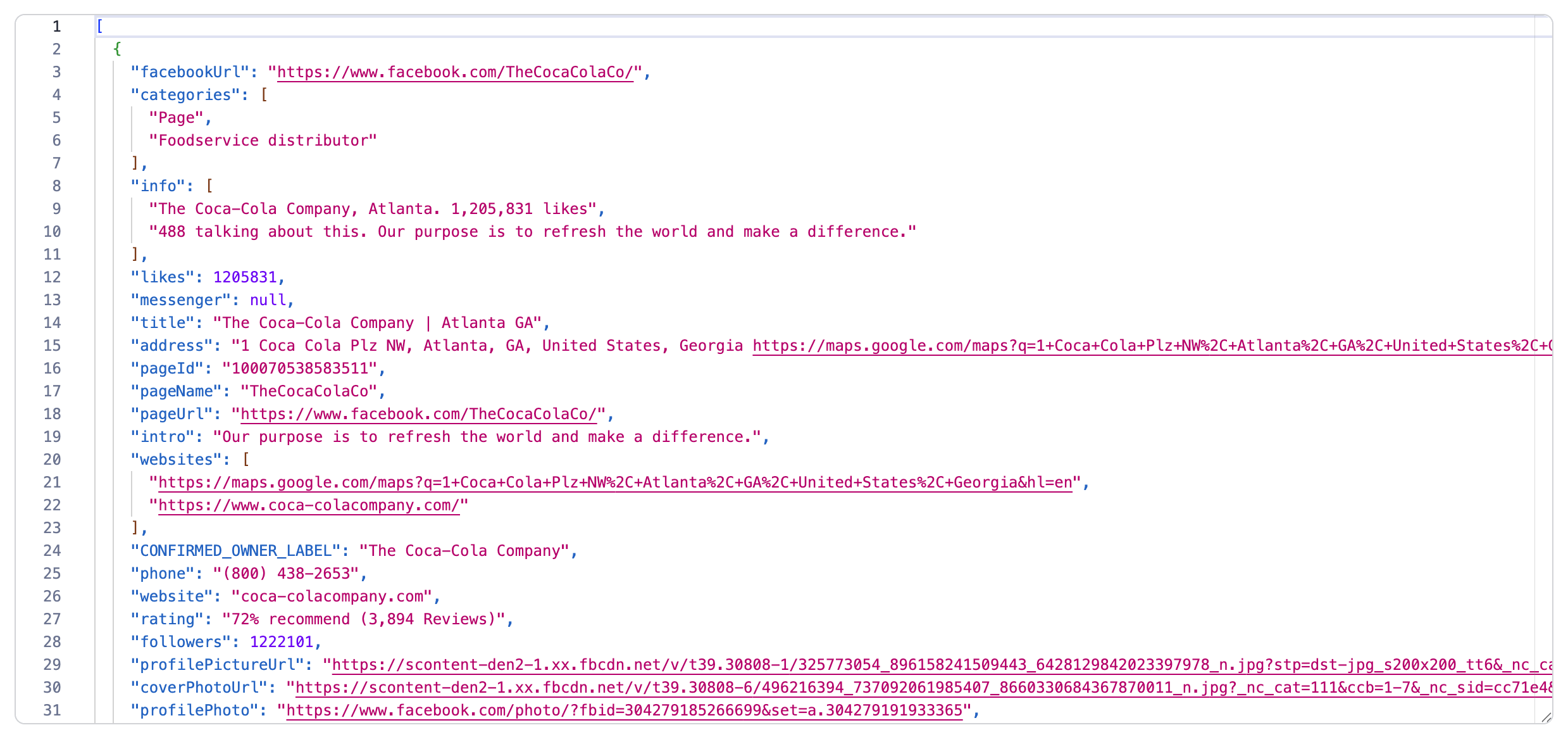
That’s it, you’re done. Now that you know how it works, you can give it a go yourself - choose your Facebook pages, copy the URLs, and run the Facebook Pages Scraper.
Need more Facebook scraping tools?
Check out these scrapers below, made for posts, reviews, comments, and image scraping. Each one's made for a specific task, so find a specific use case that matches your needs.
- 📝 Facebook Posts Scraper: extract data from the posts.
- 💬 Facebook Comments Scraper: extracts comments from the posts.
- 🌟 Facebook Reviews Scraper: extracts Facebook reviews data from the page (text and reviewer).
- 🗓 Facebook Events Scraper: extracts Facebook events data.
- 👍 Facebook Likes Scraper: extracts Facebook reactions and likes.
- 👥 Facebook Groups Scraper: extracts Facebook data posts in public groups.
- 🛍 Facebook Ads Scraper: extracts data from Facebook ads.
- 🏞 Facebook Photos Scraper: extracts Facebook images and their data.
- 🕵️♀️ Facebook Search Scraper: scrapes Facebook search by keyword.
- 🎮 Facebook Games Scraper: extracts info about Facebook games and live streams.
FAQs
Is it legal to scrape Facebook pages?
In principle, yes, scraping is legal. To keep it that way, legal rules must be followed, such as GDPR and CCPA regulations. Basically, you should make sure only to scrape publicly available content on the website and not scrape copyrighted content or accumulate personal data without having a legal basis for doing so. You can read up on the legality of web scraping in our blog post on the subject.
What about getting data with the Facebook API?
Scraping some of the Facebook data is available through their official API, but Facebook’s rules and rate limits are strictly enforced. You won’t be able to extract a lot of information in a short period of time, and you can easily get your API key blocked. These restrictions have given rise to a lot of Facebook API alternatives, including our Facebook scrapers.
Can I use AI to scrape Facebook?
AI is currently unable to scrape websites directly, but it can help generate code for scraping Facebook if you prompt it with the target elements you want to scrape. Note that the code may not be functional, and website structure and design changes may impact the targeted elements and attributes.
Can I build a Facebook scraper of my own?
Yes, you can, and we can host it in the cloud for you. You can create your own Facebook crawler directly on the platform and keep production there, or develop it locally on your computer and only push it to the Apify cloud during deployment.
Can you scrape Facebook Page Reviews?
Yes, you can. Check out Facebook Reviews Scraper. It's specifically designed to extract Facebook reviews data from pages, including review text, timestamp, and basic reviewer info.
Do you need proxies to scrape Facebook pages?
Yes. You will usually need some sort of proxy to be able to scrape Facebook successfully. Although you can still get some results (such as reviews, about, and some other content) with just datacenter proxies, our best bet is on residential proxies for all Facebook scraping. Luckily, our free plan includes a free trial of residential proxies so you can fully test the scraper.
What’s a Facebook page and a Facebook profile?
Facebook Pages are used by brands, companies, and organizations to provide information about their product or service. They're all about posting public content and usually are associated with a particular category (Politics, Music, Non-profit, etc.). This scraper tool is not intended to extract info from Facebook profiles.
Can I use cookies to scrape Facebook data behind login?
In general, you can use cookies to scrape Facebook, but not with our Facebook scrapers. We don’t provide the option to scrape Facebook pages that are visible only after login.




