


Accessing Twitter data via the official API might seem like the go-to solution, but when you take a closer look, you’ll find that:
- The official Twitter API requires applying for a developer account, waiting for approval, and building an app before you can even begin collecting data.
- When you apply for API access, you have to provide the core use case and intent, but X doesn’t offer a clean list of “allowed” vs. “disallowed” API use cases. Enforcement and interpretation of the intent are vague.
- Once you’re in and start fetching data, you’ll find fragmented reply threads, missing engagement metrics, and limited historical coverage.
As a result, developers are turning to scraping tools as an alternative, looking for solutions that can deliver real-time and historical data, easily integrate with third-party apps, and provide structured formats that can be fed directly into LLM pipelines. To make data collection efficient, a Twitter/X scraper should ideally search by keyword or handle (to monitor topics and trends), collect user and profile information, as well as extract large volumes of data to build targeted datasets.
How to scrape data from Twitter via Python API
In this tutorial, you’ll learn how to scrape Twitter programmatically without the official Twitter API - using an Apify scraper instead. That way, you’ll be able to extract the data you need at scale while handling anti-bot measures automatically. We’ll walk through how to run the scraper via the API, configure the input, and retrieve structured results.
What you need to get started
To follow along with this tutorial, make sure you have:
- An Apify account
- A basic understanding of how Apify Actors work when called via API
- Python 3.10+ installed locally
- An IDE (e.g., Visual Studio Code with the Python extension or PyCharm)
- Familiarity with Python syntax and the HTTP request mechanism
Set up your Twitter scraping project
Make sure you’re already in the directory where you want the scraper project to live. Once you’re there, create the project folder and step into it.
mkdir nasa-tweets
cd nasa-tweets
Next, let’s set up a virtual environment inside of it:
python -m venv .venv
To activate the virtual environment on Windows, execute this command in the IDE's terminal:
.venv\Scripts\activate
Equivalently, on Linux/macOS, run:
source .venv/bin/activate
Access the Apify Actor
Start by logging into your Apify account. If you don’t have one, you can easily create one for free. You’ll enter Apify Console - your dashboard for running Apify scrapers.
Create a free account or sign up with your Google or GitHub account.
Then, navigate to Apify Store - a marketplace of 10,000+ scrapers and automation tools, called Actors.

- Built-in proxy management
- Anti-bot evasion support
- Integrated storage with structured exports in CSV/Excel/JSON
- Input configuration schema with standardized parameters (URLs, keywords, limits, etc.)
- REST API endpoint for start, stop, and data retrieval
- Easy integration with third-party apps or other Actors
Every Apify Actor can be triggered programmatically via the Apify API, opening up lots of ways to integrate it into your workflows.
On Apify Store, search for Tweet Scraper V2 - X / Twitter Scraper and select it from the list:
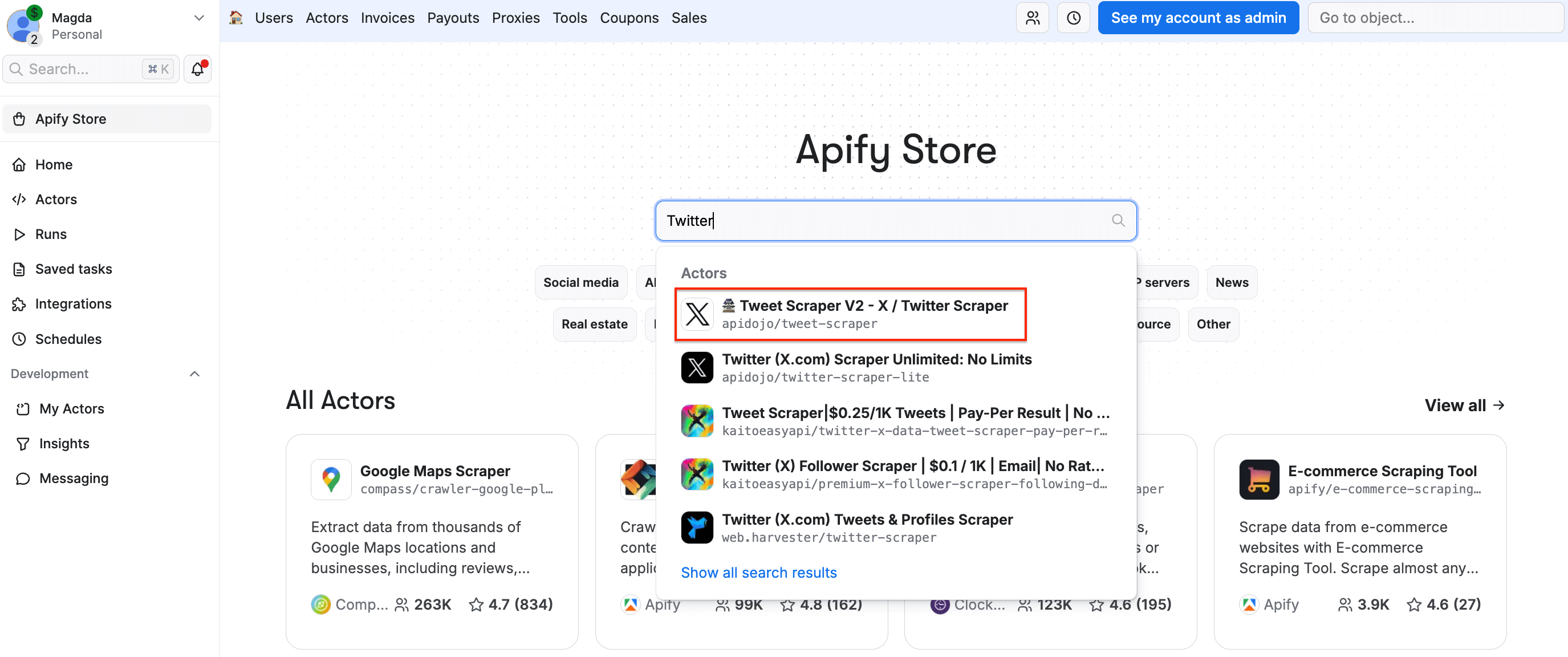
You’ll be redirected to the Actor page.
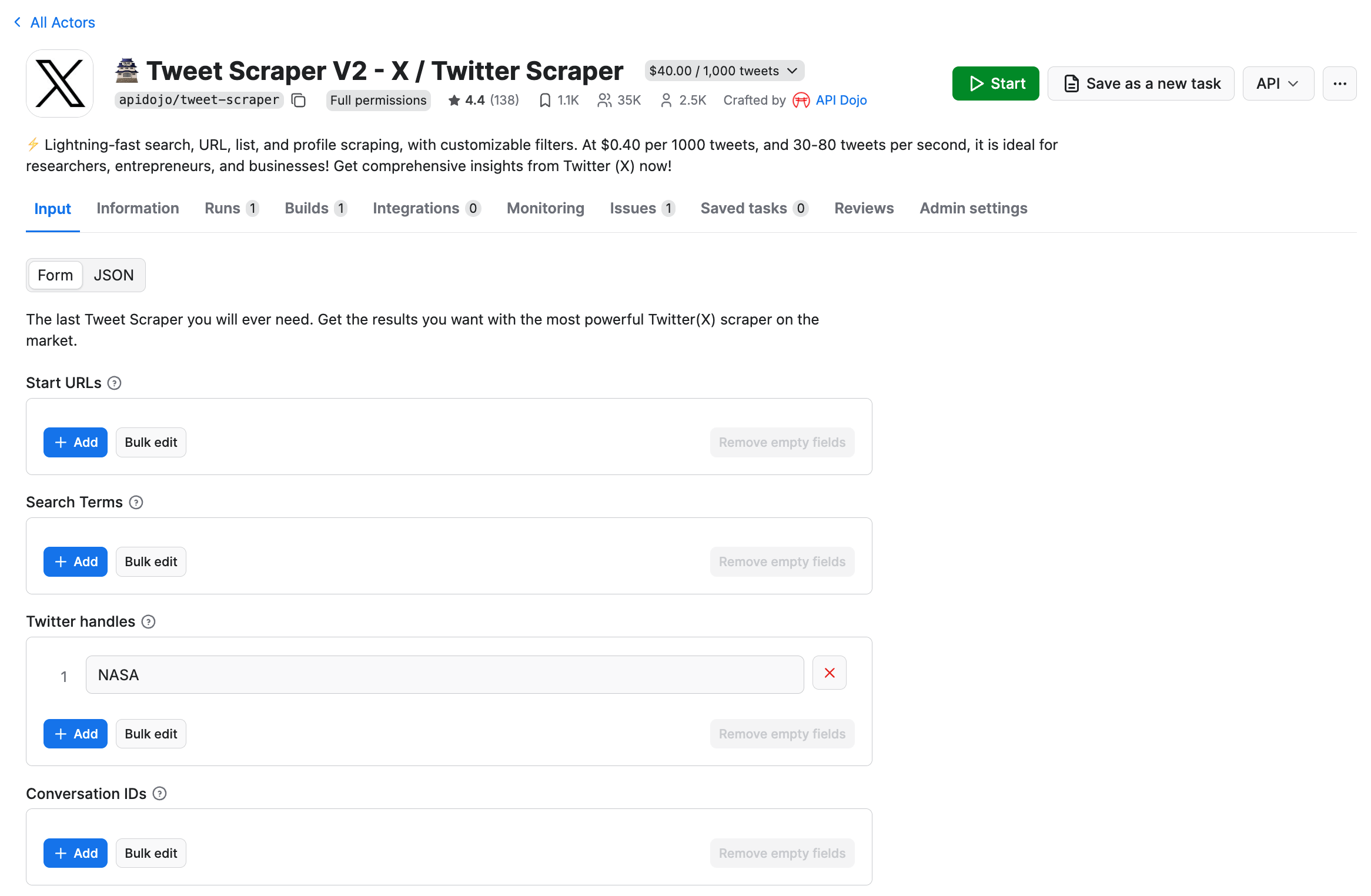
- Minimum requirement: Each query must return at least 50 tweets
- Free users: Limited to 10 items with higher pricing
- Single tweet fetching and conversation scraping are not allowed
Get started with the API integration setup
It’s time to set up Tweet Scraper V2 - X / Twitter Scraper for API usage. Begin by locating the API dropdown in the top-right corner. Then, select API clients:
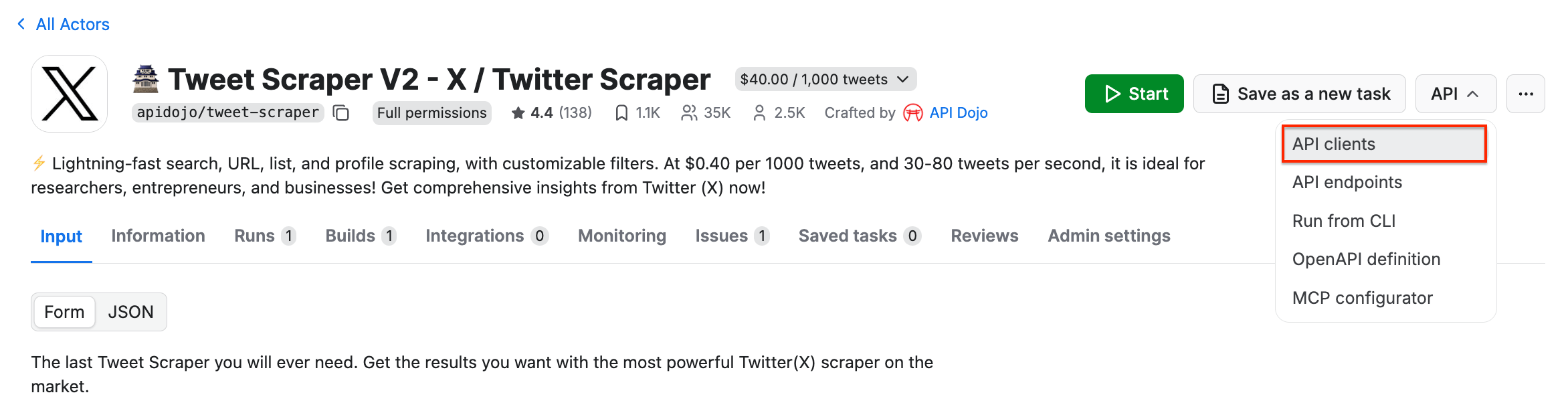
This will bring up a modal with ready-to-use code snippets for interacting with the Actor via the Apify API client. By default, it displays a Node.js snippet, so switch to the Python tab:
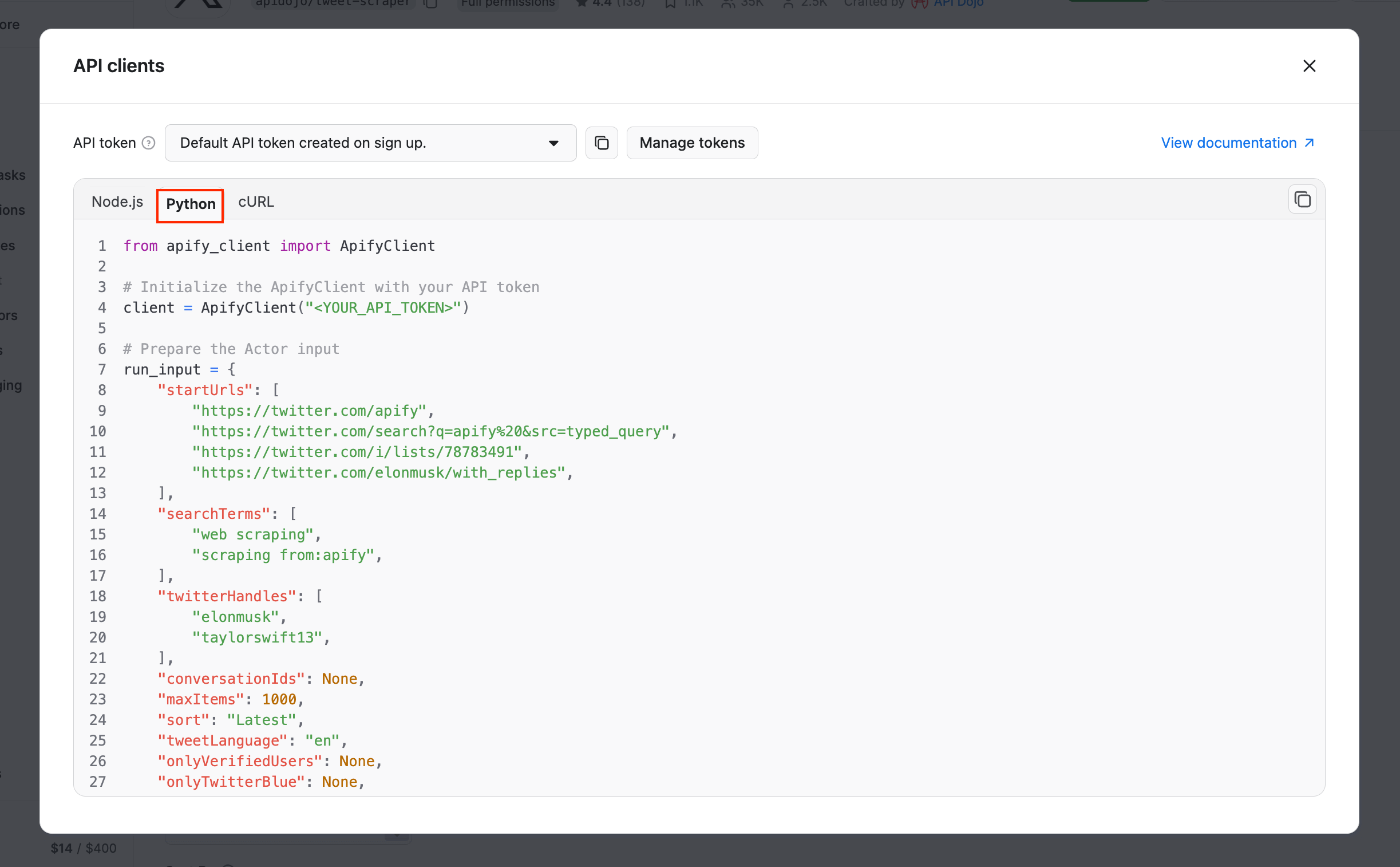
Copy the Python snippet from the modal and paste it into your Python file. Keep the modal open, as we’ll refer back to it in the next step.
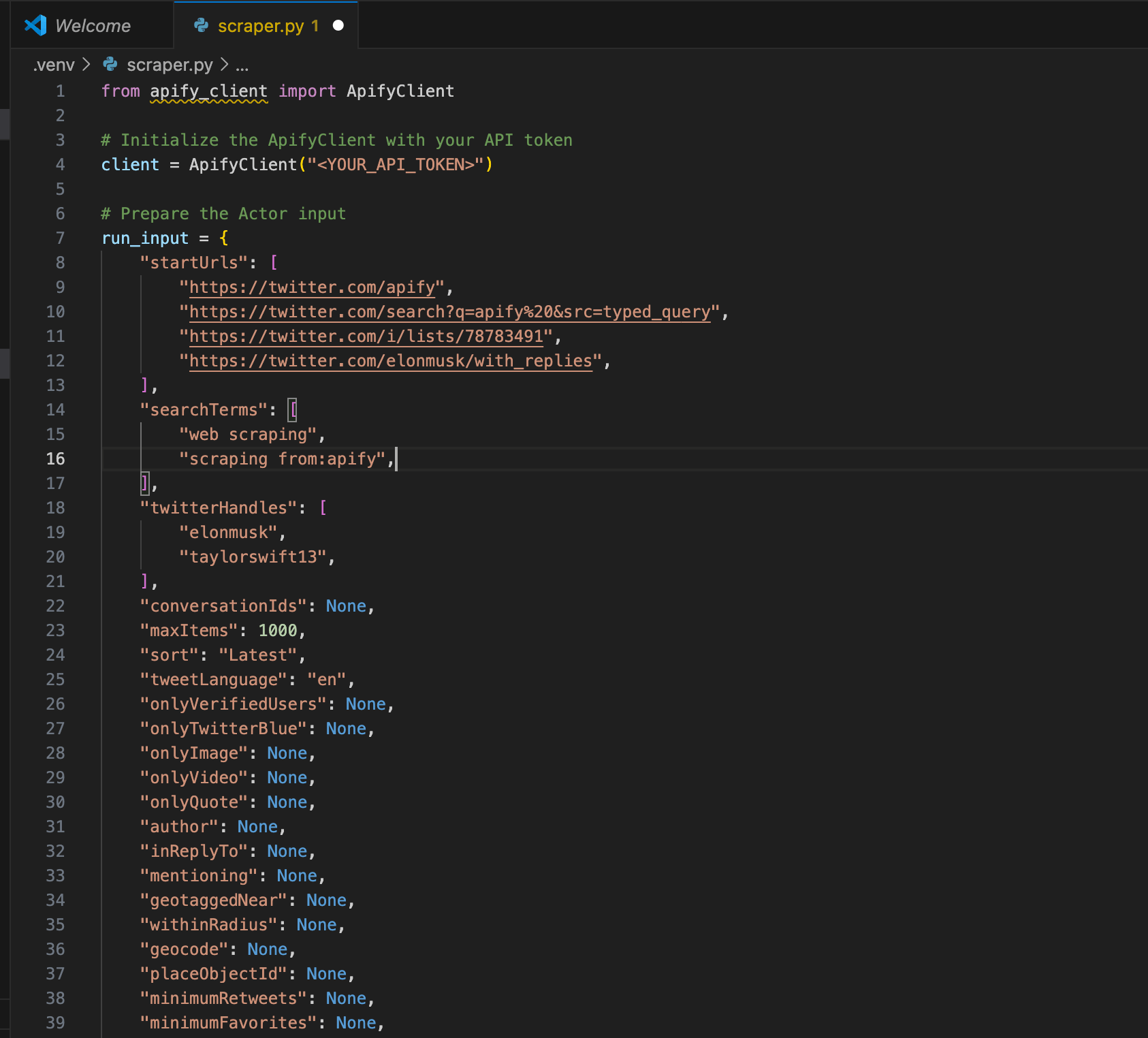
<YOUR_API_TOKEN> placeholder in the code. To keep things simple for this tutorial, just replace it with your actual token so you can run and test the script right away. That’s totally fine as long as the code stays on your machine.Once you move beyond testing, though, don’t hard-code your token anymore. Before publishing the project, pushing it to GitHub, sharing it with someone, or deploying it anywhere, remember to move your token to a
.env file instead, so it isn’t exposed in the code.After pasting the code into your file, you’ll likely see a warning that says Import apify_client could not be resolved . That simply means the package isn’t installed yet. To fix it, just run the command below inside the activated virtual environment.
pip install apify_client
Get and set your Apify API token
The next step is to retrieve your Apify API token and replace the placeholder <YOUR_API_TOKEN> in the file with your actual token. That is the final step required for scraping Twitter (X) via API integration with the Tweet Scraper V2 - X / Twitter Scraper.
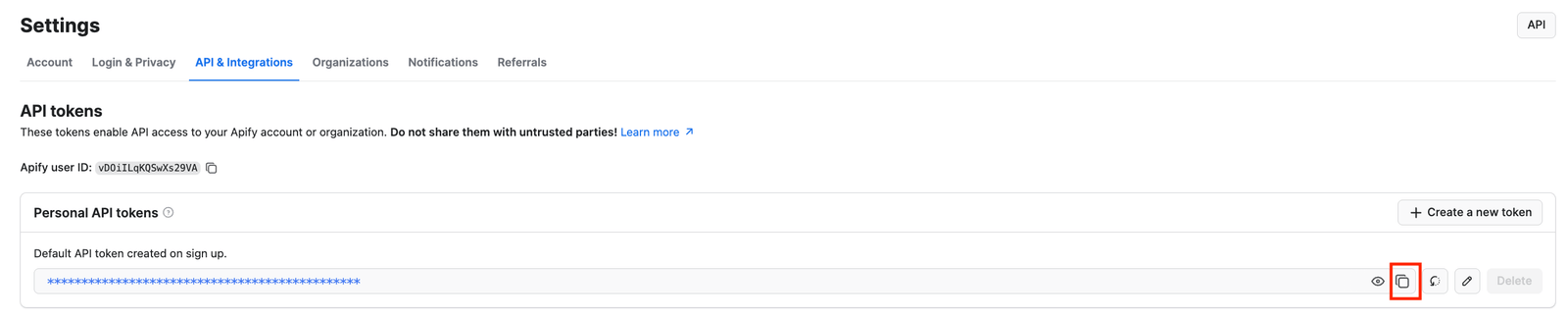
Go back to the Console, and in the API clients modal, click the Manage tokens button:

You’ll reach the API & Integrations section of the Settings page of your Apify account. To access your Apify API token, press the Copy to clipboard icon next to the Default API token created on sign-up entry:
Finally, replace the placeholder with the API token you just copied from your account:
# Replace the <YOUR_API_TOKEN> placeholder with your actual API token
client = ApifyClient("<YOUR_API_TOKEN>")
Configure the Actor
Like any other Actor, Tweet Scraper V2 - X / Twitter Scraper requires the correct input parameters to retrieve the desired data. When using the ApifyClient, these parameters specify which pages the Actor should scrape via API.
This particular Actor can scrape data using:
- Twitter (X) URLs
- Search terms
- Twitter handles
- Conversation IDs
In this example, we want to scrape recent tweets from the NASA Twitter account. To simplify the input configuration process, open the Input section on the Actor’s page, and paste the profile name into the Twitter handle field.
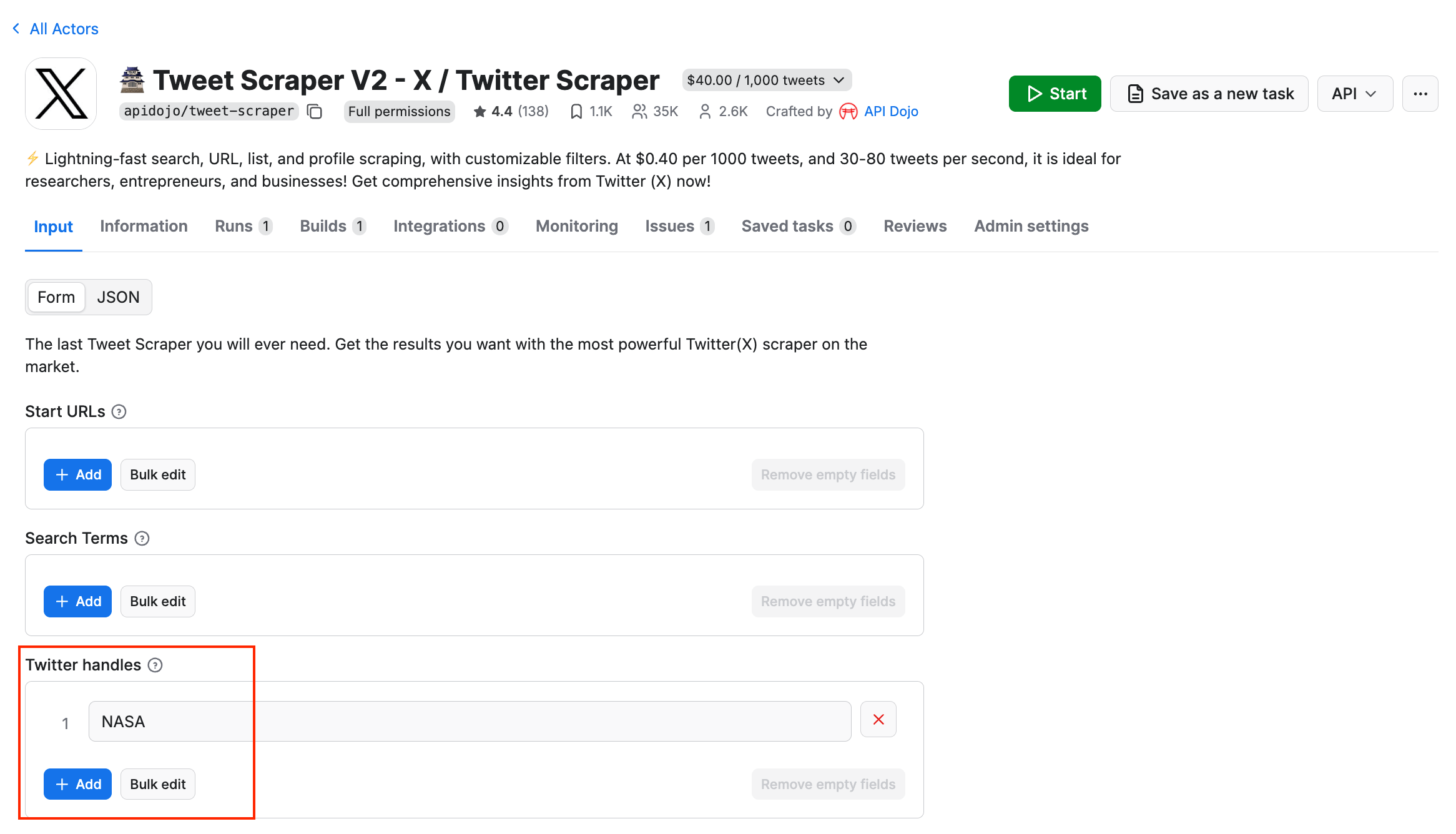
Then, switch to the JSON view, which looks like this:
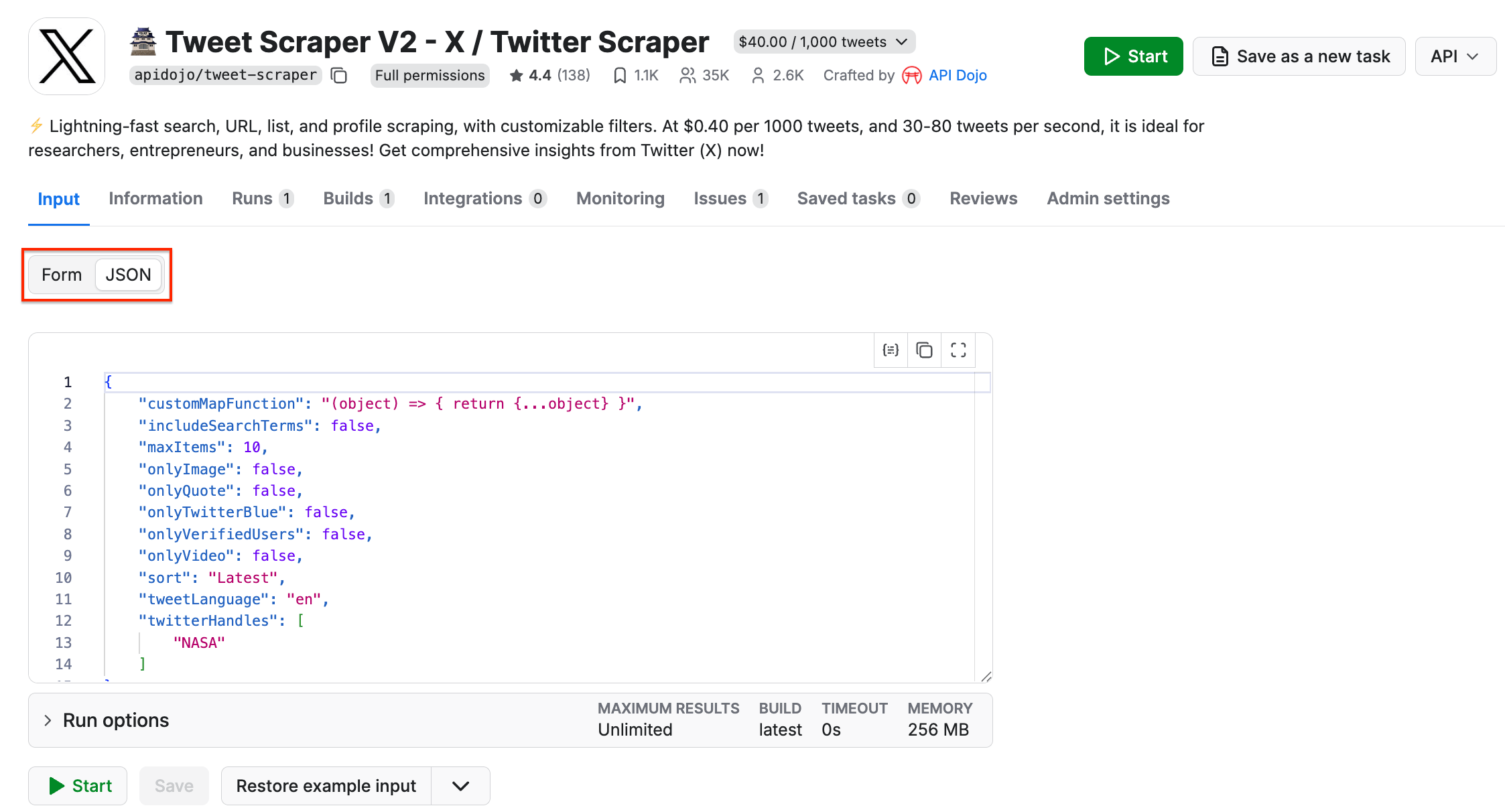
As you can see, the NASA profile name appears in the twitterHandles field. Now, follow this structure and populate the input dictionary in Python, and call Tweet Scraper V2 - X / Twitter Scraper as shown below:
run_input = {
"customMapFunction": "(object) => { return {...object} }",
"includeSearchTerms": False,
"maxItems": 10,
"onlyImage": False,
"onlyQuote": False,
"onlyTwitterBlue": False,
"onlyVerifiedUsers": False,
"onlyVideo": False,
"sort": "Latest",
"tweetLanguage": "en",
"twitterHandles": [
"NASA"
]
}
# Run the Actor and wait for it to finish
run = client.actor("61RPP7dywgiy0JPD0").call(run_input=run_input)
Now that the code is set up to scrape data from a specific Twitter handle, we can run it to trigger the API call.
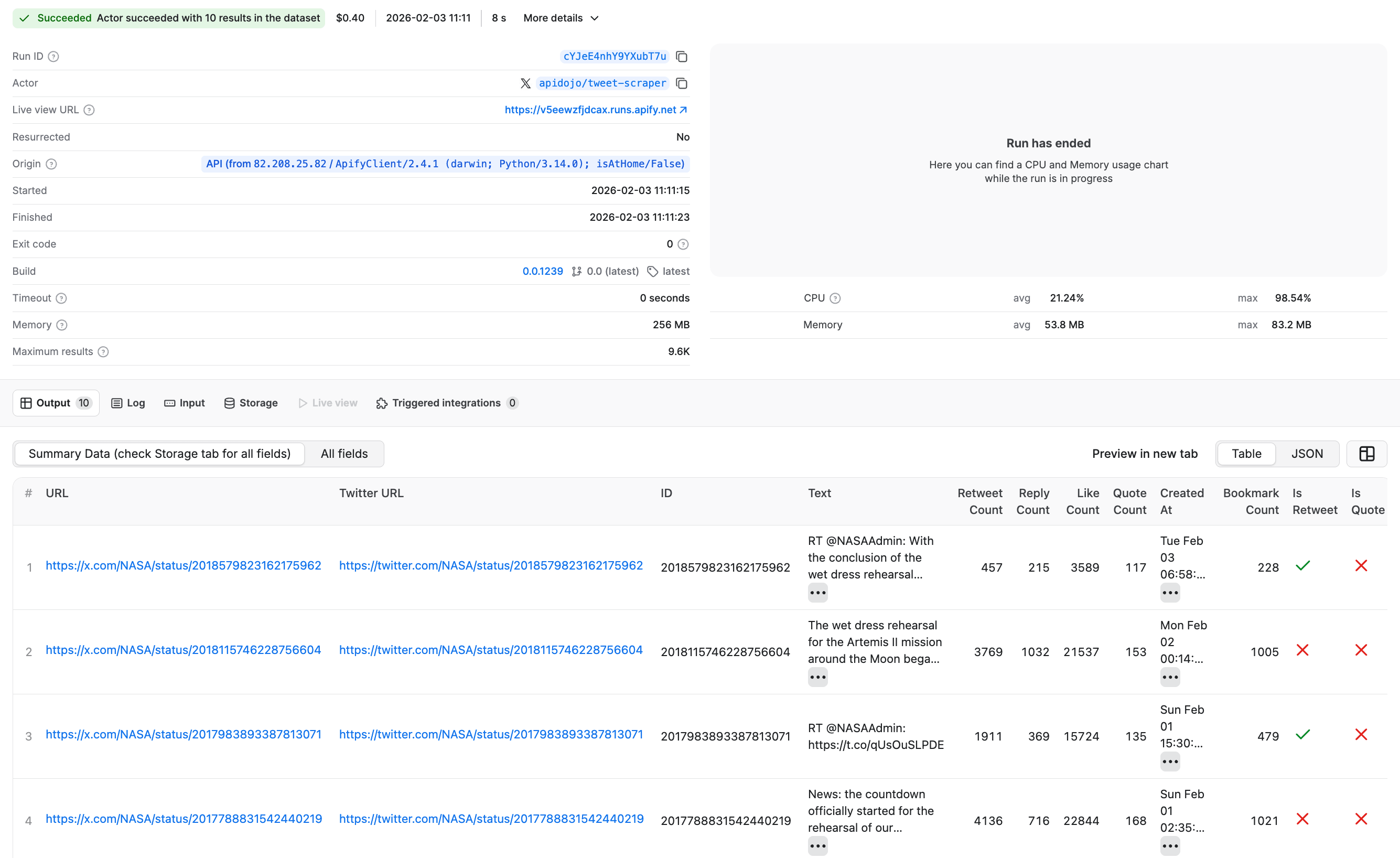
After it finishes, go back to Apify Console and open the Runs tab. You’ll see the latest Tweet Scraper V2 - X / Twitter Scraper run, with its origin marked as API, which confirms the code worked.
By clicking on the run, we can find the extracted results just like we would if we had started this run from the platform UI instead.
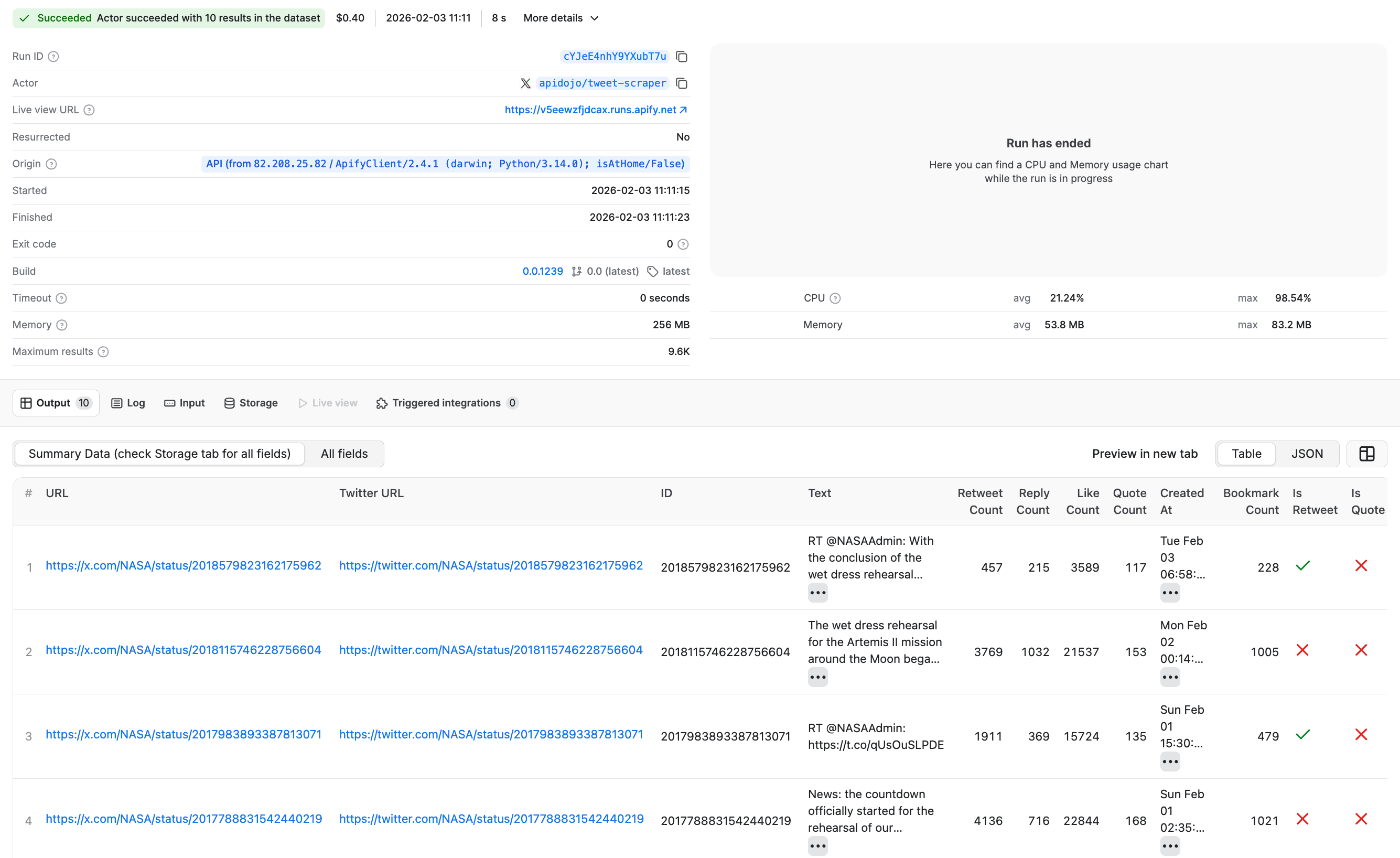
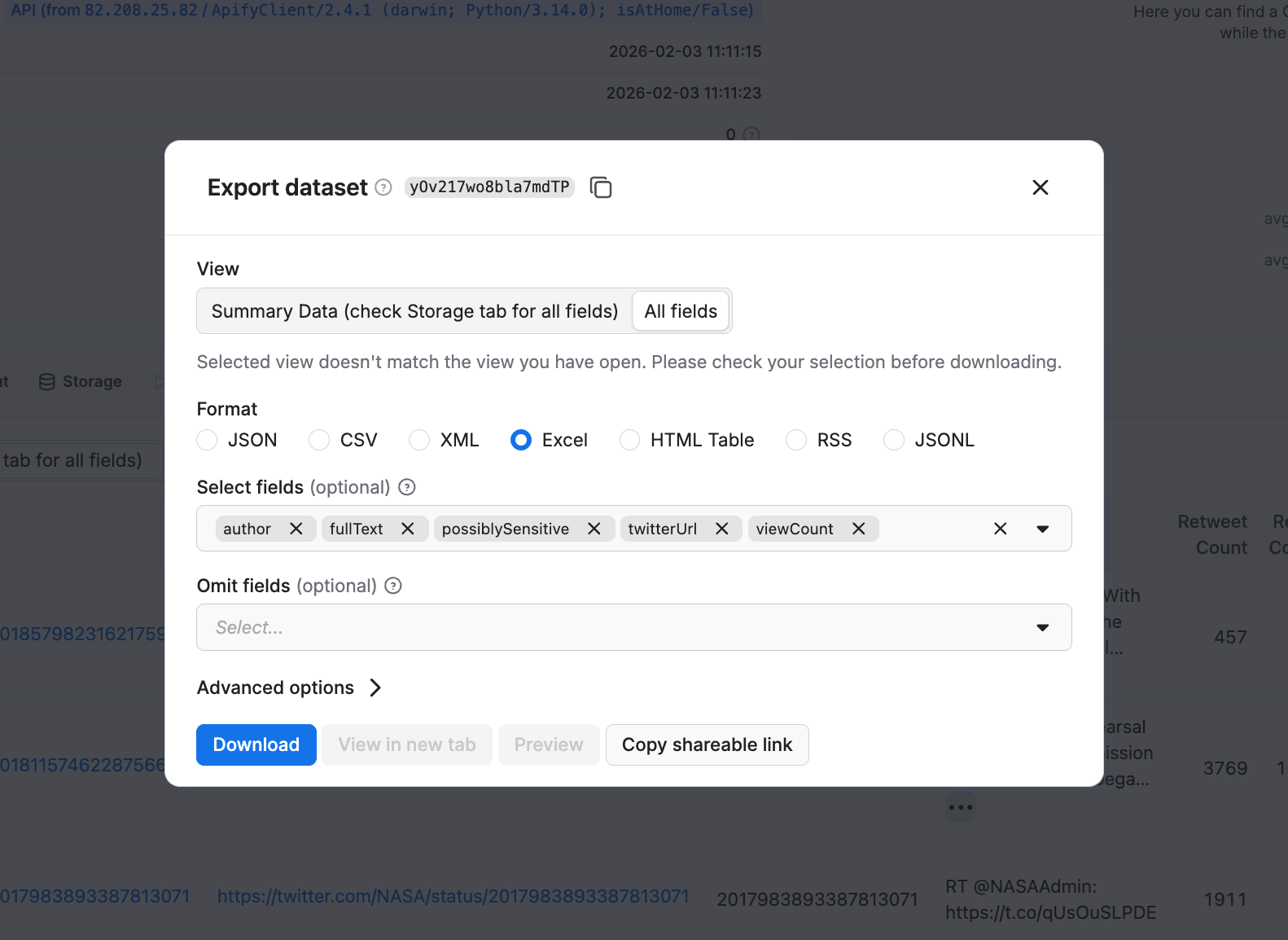
From here, you can also export your data in a preferred format, selecting fields you’re interested in.

What else can Tweet Scraper V2 - X / Twitter Scraper do?
This scraper was designed by an independent creator on the Apify platform for scaling and speed, delivering over 1,000 tweets per minute. Thanks to the advanced search and filtering options, the output can be narrowed down to hashtags, time range, or locations, and results are delivered in clean JSON, CSV, or Excel formats.
You can filter your results by verified users, Twitter Blue, images, videos, and quotes. There’s also a Query Wizard feature if you want to collect tweets from a specific geo radius or posts mentioning another Twitter user:

Start scraping Twitter (X)
Apify lets you collect Twitter data at scale with clean, structured outputs without the constraints of the official API. With the right setup, you can move faster and spend your time analyzing insights instead of fighting infrastructure.
Try it yourself: Run the Actor on Apify, plug it into your Python code, and start collecting tweets in minutes.

FAQ
Do I need a developer account to scrape Twitter?
No, you don’t need a developer account to scrape. You need a developer account if you want to use the official API, which requires an application and an approval process.
What’s the difference between scraping and using the official API?
Scraping pulls raw data from the public web interface (HTML pages, internal requests), while the official API gives structured data (JSON) through documented endpoints. Scraping is quicker to start and can bypass application requirements.





