



We're Apify, and we've been scraping the web for 8 years. You can build, deploy, share, and monitor fast, reliable web scrapers on the Apify platform. Check us out.
How much can change over the span of one year? Well, 2022 has shown us that not that much and everything at the same time. Let's dive into what web scraping was like in 2022 and how it might develop in 2023.
🤖 Anti-scraping protections in 2023
With web scraping becoming a more common tool for companies across many industries, security providers are efficiently keeping up and constantly improving their antibot products. The trend of 40% of web traffic being bots is going nowhere in 2023. The antibot products focus on a much broader area than preventing web scraping. Most of these solutions protect websites against attacks on the website or its users. These malicious bots make up 15% of all web traffic. Unfortunately, web scraping is affected by these countermeasures as well. It is a must for modern web scraping programs to know their way around them. So what does the antibot situation look like in 2023?
#1 AI and browser fingerprinting becoming an industry standard
Security providers have been improving their solutions significantly. In past years, only the top players leveraged browser fingerprints (browser checks). Nowadays, it is becoming an industry standard. We have seen a big boom in AI in recent years, and this is now also being adopted in the bot detection industry. AI plays a significant role in analyzing the validity of browser fingerprints, request features, and finding suspicious visitor patterns in website traffic. With this being said, modern web scraping is carried out by automating browsers. Of course, there are sites you can scrape without a browser. However, these sites are becoming less common.
#2 Datacenter proxies don't cut it anymore
Another trend we have spotted in recent years is tied into proxies. Proxies are an essential part of web scraping. There are traditionally two types of proxies—residential and data center. Datacenter proxies are hosted in a data center, and residential proxies are hosted on an actual personal device, such as a smartphone, router, or laptop. Historically, only a few providers could flag datacenter proxies through passive checks with bots databases or active checks with latency measurements or portscans. Nowadays, it is more common for datacenter proxies to get blocked right away.
#3 Bot protections affecting UX
Bot protections are not only affecting bots – they also affect website users. They can make the user experience an absolute nightmare. You probably find captchas annoying too. Apple recently introduced a feature for its operating systems called Private Access Token, which might finally put those annoying captchas out of their misery. So far, it is being used by Cloudflare, but once more OS vendors will provide this feature, captchas could, in theory, disappear. This will present a non-trivial challenge for web scraping developers to dig around and try to generate these tokens for bots to access the websites protected by this new shiny tech. But let's keep our hopes up. This will probably not happen any time soon, and until then, CAPTCHA bypass is still not a significant complication for bots.
#4 Mobile apps putting up anti-scraping measures
When speaking about web scraping protections, we can't leave out scraping data from mobile applications. In the past, mobile applications were only sometimes protected against web scraping. Usually, there were unprotected endpoints that required specific headers shared across all of the app installations. Nowadays, mobile apps are also adopting countermeasures to prevent scraping. The most common feature is generating unique device fingerprints based on accelerometers and other sensors, which makes the scraping complicated but possible.
#5 Data behind login where possible
Antiscraping mitigation tools are evolving, often implementing the same sophisticated tech as the antibot protections. This makes websites hide part or all of the content behind a login. Scraping behind a login is not impossible, but it presents legal challenges and is best avoided.

📚 Languages and libraries
#1 What's the most popular language for web scraping in 2023?
With its variety of libraries, such as Beautiful Soup and Python Requests, in 2023 Python remains the most popular language choice for web scraping. Paired with data scientist's favorite, Jupyter Notebook, Python dwarfs all the other languages used on GitHub in publicly open web scraping projects as of January 2023.
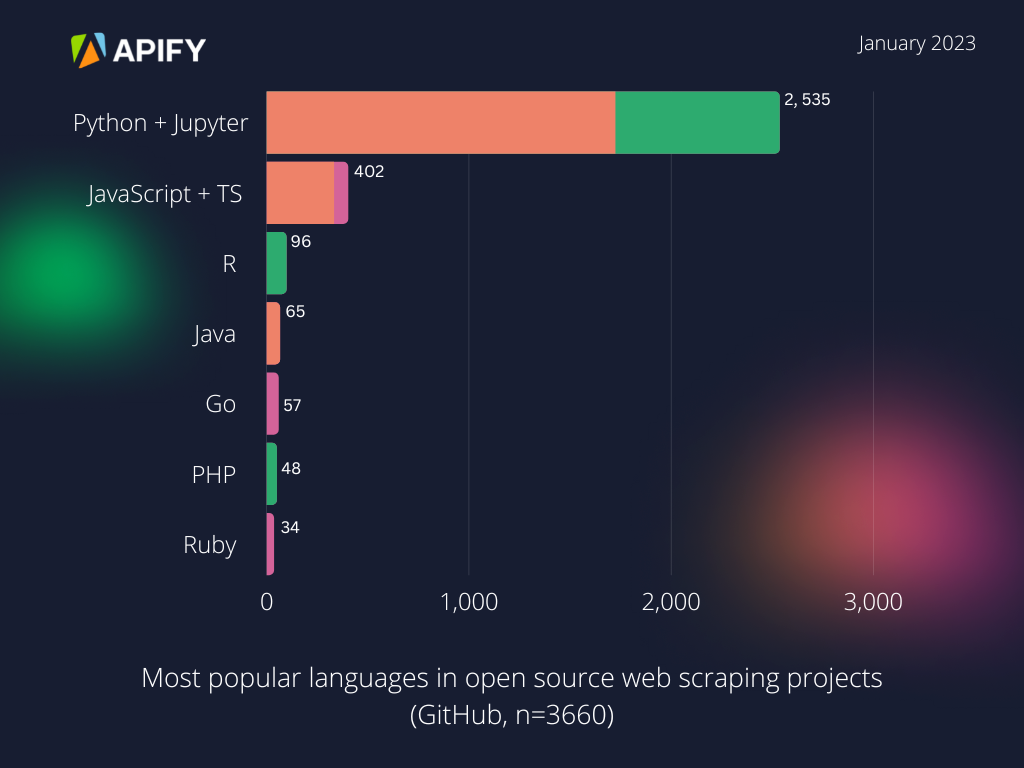
This is largely thanks to Python's syntax, which is generally easy to read and understand, making it an easy language for beginners in web scraping. When used together, Beautiful Soup and Python Requests library make it manageable to download and parse web pages, making them a popular choice for many Python web scraping developers. Scrapy is also a well-known open-source Python web scraping framework. Web automation devs use it to handle the most common use cases when doing web scraping at scale, such as multithreading, web crawling, data extraction, validation, and saving to different formats and databases.
Python also leads significantly in Google, which leads us to assume Python is the number one choice in discovery and web scraping beginner search queries.
#2 What's the most popular library for web scraping in 2023?
That depends on the language you use. Scrapy remains the most popular web-scraping library for Python and overall in 2023. With over 45,000 stars on GitHub, no other library comes close.
But, if you're a JavaScript fan, there's some good news for you. In 2022 Crawlee launched and finally brought a full-featured web scraping library to Node.js developers. It's open source, has full support for TypeScript, and it's built on top of other popular Node.js libraries, such as Got Scraping, Cheerio, Puppeteer, and Playwright. It boosts them with web scraping specific features like smart proxy and fingerprint rotation, URL queues, autoscaling, data storage and more.
We do admit that we might be terribly biased about Crawlee, so check it out for yourself; it is the no.1 repo on GitHub for the web-scraping category. Don't forget to add one to its 7.5K+ stars on GitHub if you end up falling in love with it, as we did.

#3 Browser automation in 2023: headless browsers still rule
In 2023, as it becomes increasingly difficult to scrape without using a browser, the best browser automation tools for web scraping remain the same: Selenium, Puppeteer, and Playwright. These tools allow for the rendering of JavaScript on dynamic websites, controlling browsers in headless mode, and creating workflow automation.
- Selenium is particularly popular in the Python community, but it also supports various other languages, including JavaScript (Node.js), Ruby, Java, Kotlin, and C#.
- Puppeteer is a Node.js library developed by Google and provides a high-level API for manipulating Chrome.
- Playwright is a newer library that has gained popularity for its modern features, cross-browser support, and ease of use in multiple languages.
It's getting increasingly harder to do web automation and data extraction in 2023 without these tools, especially on modern websites that utilize JavaScript to load content dynamically.

🧑⚖ Legal developments
There have been quite a few interesting legal developments in 2022 that influenced data scraping legal practices. Web scraping case law got enriched with a new resolution to one infamous dispute in particular.
#1 Final word in hiQ vs. LinkedIn case?
The five-year-long data scraping dispute between hiQ and LinkedIn seems to have gotten closure, actually a few of them. But was it in favor of the web scraping community?
LinkedIn has had a problem with web scraping for quite some time, even if it's done for business, such as in the case of hiQ. This brought LinkedIn and hiQ to a dispute in 2017, with LinkedIn claiming hiQ's systematic scraping violated its Terms of Service and the Computer Fraud and Abuse Act, and HiQ rejected the wrongdoings as the scraped data was open and public. So after six years, it's finally settled.
But not without some rollercoaster rides, both of which happened in 2022. First, impacted by the US Supreme Court's Van Buren ruling of the year before, the Ninth Circuit applied the "Gate up/Gate down" analogy to the LinkedIn data case and ruled in favor of hiQ. Van Buren's gate concept applied to public websites assumes there's no gate (authorization) to lift in the first place, since being open to anyone is the defining feature of public websites. Based on this logic, in April 2022 the Ninth Circuit Court found that the authorization-related clause of the Computer Fraud and Abuse Act can't apply to public websites such as LinkedIn, meaning hiQ wasn't breaching any anti-hacking acts and is now allowed to access LinkedIn user data.
 Lucie Růžičková
Lucie Růžičková
However, later that same year, in October, the court issued another decision, this time siding with LinkedIn. First, in August 2022, hiQ notified the court it was no longer in business (very much as a result of being forbidden from scraping LinkedIn this whole time), which eliminated the need for accessing LinkedIn user data (as well as the court's permission for it). And just a few months later (and a few weeks after another batch of scraped LinkedIn user data showed up on the dark web), the court determined that hiQ violated LinkedIn's Terms of Service. This means that while hiQ did not breach the criminal law (CFAA), it breached a contract (created by the acceptance of LinkedIn's Terms of Service). The settlement required $500,000 in payment to LinkedIn and the destruction of scraped data.
Doesn't look much like a win for the web scraping community, does it? More like 50/50. Win in the first part (CFAA) and loss in the second (ToS).
The wind is changing. Because of Van Buren 2021 and the hiQ April 2022 ruling built on it, CFAA lost a lot of allure of being the go-to claim for when websites want to sue web scraping companies. The heart of web scraping case law now lies with proving the violation of the website's Terms of Use.
The judgments in the hiQ case were important, but they were only summary judgments, which means the court is not finished with this whole story yet. The settlement in October 2022 was significant, but even more so was the ruling of April 2022. No matter how the legal developments proceed in the year 2023, the important thing for the web scraping community is that the landmark ruling of April 2022 dispelling the fear of criminal law consequences of web scraping public data remains valid.
#2 Meta keeps lawyering up
Meanwhile, some things never change: tech giants keep sending C&D letters, suing smaller web scraping companies, and winning. In summer 2022, Meta filed two Terms of Service-based lawsuits against web scraping companies: Octopus for offering scraping services for hire and Mystalk for creating clone sites using scraped data. Later in the autumn this year, Meta won two lawsuits from back in 2020 against BrandTotal and Unimania, both of which offered marketing intelligence solutions based on scraped social media data.
All of Meta's lawsuits have similar requirements expecting the web scraping companies or individuals to be banned from scraping Facebook and Instagram data, stop profiting from collected data, and, of course, pay up. Most likely, Meta will continue with its devotion to anti-scraping measures in the coming year (both technically and legally). The company has already taken 300+ enforcement actions against people and entities that scrape at scale, and started the new year with a new lawsuit against Voyager Labs.
Lucie Růžičková
#3 EU doesn't play around with data privacy
The European Union doesn't play around when it comes to data privacy. In total, in 2022, Meta received a total of €747M in publicly disclosed fines from the GDPR's main regulatory body, DPC, including the €265M penalty for a data-scraping breach that impacted 530M users 2021. Meta isn't alone in this. AI + web scraping face recognition company Clearview AI was also fined on a GDPR basis. This year we will likely see more fines and discussions around social media data.

🌐 Overview of the market
Over the past ten years, the search frequency of web scraping grew 3x on Google. And according to the only publically available report on web data extraction spending (done by Opimas in 2018), overall spending on web scraping should have reached $7B by 2020. However, their recent prediction figures, published in 2022, start from $3B for 2020. Did the $4B just vanish?
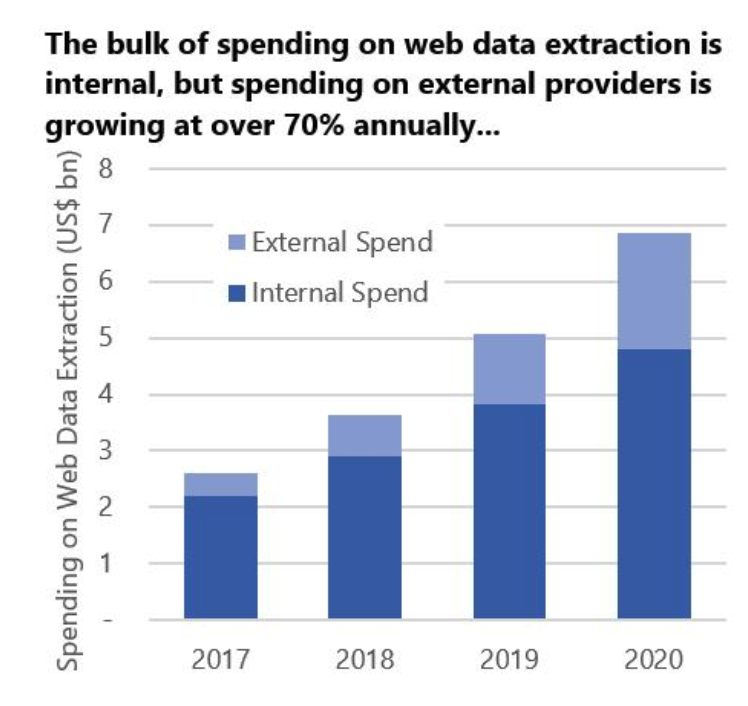
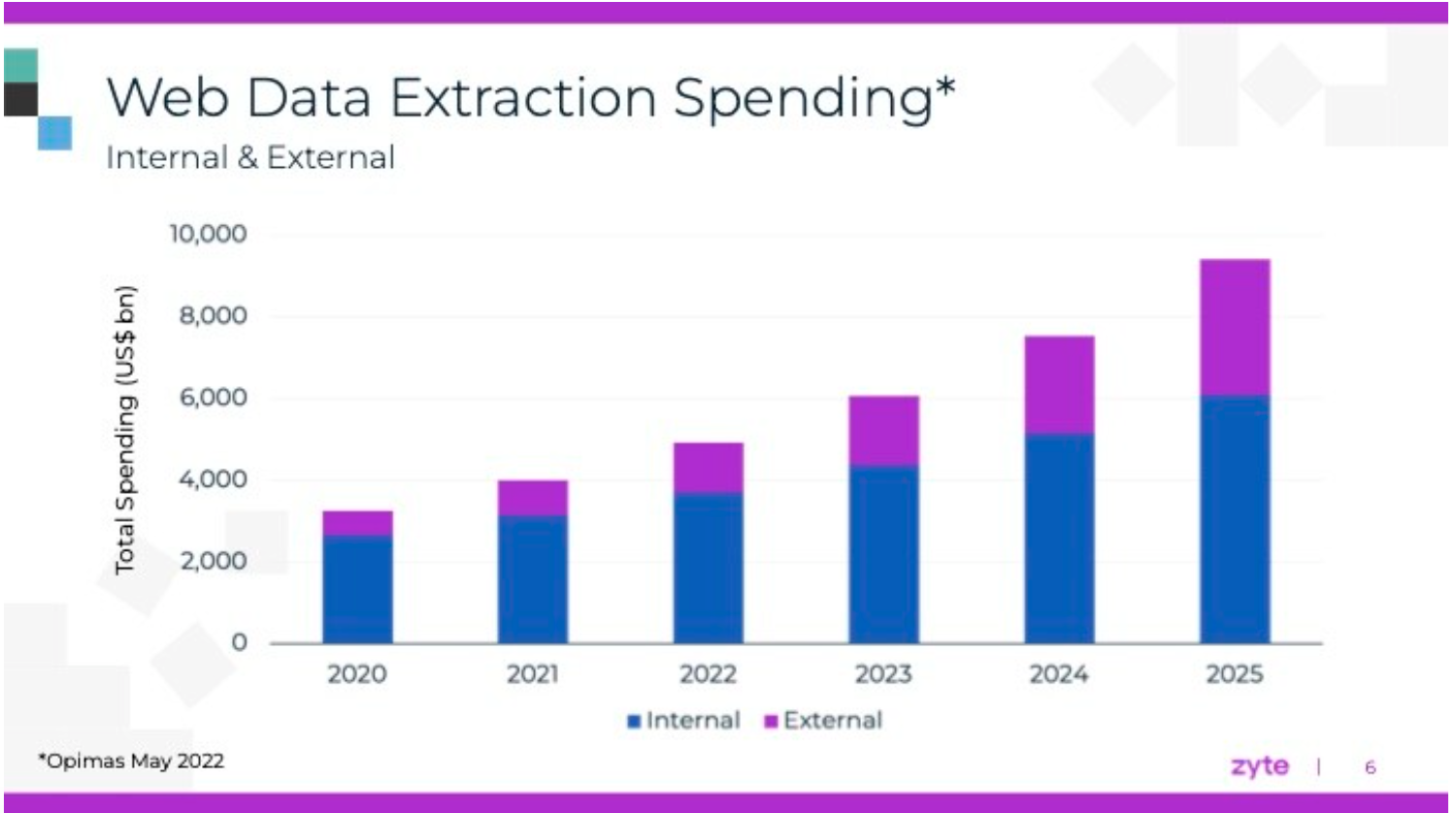
Predictions on web data extraction spending by Opimas in 2018 vs. 2022
The moral of this story is that perhaps Opimas analytics have become more accurate and therefore realistic in 2022 compared to 2018. Or perhaps that you shouldn't trust market predictions that much. Web scraping trends, on the other hand, might be a bit more reliable. Among them in 2022:
#1 Data extraction is the bare minimum
With terms such as data-as-a-service, web data suppliers, data feeds, and data providers being bounced around the web scraping community both online and offline, it becomes quickly obvious that 1. The rebranding of web scraping into more general data extraction has been both successful and 2. ubiquitous. Data extraction has become the baseline for the market.
Providing high-quality scraped data is the new normal. A prime example of this might be Bright Data's launch of pre-made datasets. The question now is: what else can you offer besides scraped data? This brings us to trend no.2.
#2 Covering the full lifecycle
Most key players on the market are now striving to cover the full web data lifecycle. This explains the numerous mergers and acquisitions occurring over the year aimed at building and maintaining a well-rounded web scraping ecosystem. Some companies, such as Oxylabs, have been expanding their proxy services even more, entering 2023 with the introduction of Web Unblocker. Others, such as Bright Data, launched market intelligence tools by acquiring Market Beyond. Zyte went for a full all-in-one API solution instead at the tip of the new year. All these moves are unified by the motivation for web scraping companies to become something more than web data providers.
#3 New players on the market
Besides the usual well-known names, there have been some new introductions to the market. There have been many new launches (ZenRows, The Codery API, ScrapeIN', Windmill, Browse AI), rebrandings (CrawlBase), and even unexpected players entering the game (web automation from Cloudflare, the arch-nemesis of all scraper bots).
🗞️ Web scraping - less niche, more mainstream
While it is true that web scraping usually makes it into news feeds because of legal battles, in 2022, there were quite a few different reasons the term made it into mainstream media.
#1 Instagram + live camera art project
Merging scraped Instagram data with videos from open surveillance cameras, artist Dries Depoorter turned scraping Instagram into an art project and made web scraping into a Saturday brunch conversation topic. In The Follower, the artist matched influencers' posted Insta pics with online video footage from the same place and moment. The comparison revealed that behind the scenes of perfect Instagram grids are often uninteresting and trivial. After posting about it on social media, he was quickly banned based on copyright claims. Some influencers felt like matching those media was an invasion of their privacy.
#2 Scraping Twitter for defamation proofs (Depp vs. Heard)
Web scraping also played a part in the defamation trial of Johnny Depp v. Amber Heard as a method of investigation. The director at Berkeley Research Group, Ron Schnell, elaborated on how he used an API to scrape Twitter hashtags to show a spike in negative sentiment towards Heard right after Johnny Depp's then-attorney Adam Waldman called the abuse allegations a hoax. The goal of Twitter scraping was to provide proof to Heard's allegations that Waldman's comments have damaged her acting career.
#3 Google robot trained with web scraping
Last but not least, an impressive machine learning stride in language comprehension has been spotted in Google by Wired. A Google robot learned how to take simple orders in natural language form, not formalized hey-Siri style. How? By learning the language through millions of web pages. Machine learning scientists have decided to swap enormous datasets for scraped web text and get themselves a robot whose speech comprehension is surprisingly effortless.
🌿 More common non-commercial use of web scraping
If you thought that web scraping is only good for business cases, think again. In 2022, the EU used data extraction across European e-commerce to support a new Directive, researchers continued using web scraping for COVID-19 data, and NGOs and journalists collected digital evidence of the aftermath of air strikes as the Russo-Ukrainian war escalated in 2022.
#1 State: Web scraping spreads to the government level
State organizations have also started publicly recognizing the value of automated web data collection. In 2022, the EU did its first sweep of e-commerce websites to determine which ones were inflating prices before offering "discounts". In line with the EU Directive on Consumer Protection, over the span of a few months, the EU Commission monitored the prices of 16,000 products from 176 websites. This scope of work would have been impossible without web scraping technology. Apify's cooperation with the EU Commission is another example of how web scraping can be used as a force for good.
Theo Vasilis
#2 NGOs: Web scraping and the war in Ukraine
War in the 21st century is very much digital, which means a lot of its impact is recorded on the web. Investigative journalist organizations such as Bellingcat have been the first ones to embrace that change and analyze the events in Ukraine using aggregated data from the web. In this particular case, Bellingcat scraped TikTok for footage of missile strikes and their aftermath. NGOs like Mnemonic also collected digital evidence of suspected war crimes in Ukraine from various social media platforms for further use in research, journalism, and international law.
#3 Web scraping and COVID in 2022
While the pandemic is not over, in 2022, we felt less of its impact on our daily lives and the livelihoods of those around us. And while most of the kudos go to the tireless work of medical professionals and other essential workers, what this pandemic was a lot about is timely data. This means a lot of web scraping companies provided their pandemic data scraping services for free – as one should in times of crisis.

The future of web scraping: trends and predictions
It is difficult to predict with any certainty what the main trends in web scraping will be in 2023, as the field is constantly evolving. However, here are a few potential trends that may shape the future of web scraping:
🤳 Scraping social media and e-commerce remains on top
Web scraping of social media and e-commerce websites is expected to remain popular in 2023. According to our own research with data from Apify Store, despite the partial introduction of more logins and antibot protections on these websites, web scraping of Instagram, Facebook, and other social media is still in high demand for market research, brand monitoring, and sentiment analysis. Analyzing the data can also help marketers determine the best time to post on social media, ensuring that their content reaches the maximum number of people. Similarly, e-commerce scraping is also expected to remain popular as businesses are still interested in gathering data on competitors, prices, and product information.
However, scraping these websites is becoming increasingly difficult, as many social media websites are now requiring logins to access their data, making it harder for scrapers to gather the desired information. E-commerce websites are instead leading with more sophisticated anti-scraping measures.
Despite these challenges, web scraping of social media and e-commerce will remain a popular trend in 2023. The benefits of web scraping these websites outweigh the challenges, and businesses continue to find new and innovative ways to gather the data they need.
🛡️Increased focus on data privacy and security
As fines and concerns about data privacy continue to rise, and the legal battles of 2022-2021 continue to drive data scraping case law forward, ethical web scraping remains a big trend well in 2023. It is a hot topic of web scraping conferences, it is a matter of interest for every well-meaning web scraping company, and it is a concern of potential customers ("is web scraping legal?" is one of the most frequent web scraping queries on Google).
The web scraping industry is one of those rare businesses whose legality gets constantly questioned. With growing emphasis on the websites' responsibility to "keep the gates up" and discourse around who social media data belongs to – users or companies, in 2023 we will see many more web scraping businesses claim or reaffirm their commitment towards ethical web scraping.
As the issue of data privacy becomes increasingly pressing, websites, on the other hand, will continue implementing stricter measures to protect against web scraping. This could include the use of browser fingerprinting, IP blocking, putting data behind logins, and more robust security measures to prevent unauthorized access to their data.
❌ Power-ups continued with anti-scraping protections
Theoretical concepts are now becoming real solutions (such as advanced browser fingerprints). It is increasingly necessary to use a browser for scraping. More mobile apps are using anti-scraping protections and more public data is moving behind login. In a general trend, datacenter proxies are becoming more detectable as proxies. The only new and revolutionary last year tech was probably Apple Private Access Tokens. Captchas are generally still easily solvable by third-party services.
🚀 ChatGPT, AI, and web scraping on our minds
Our attitudes towards AI have changed dramatically over 2022. We went from feeling concerned over Google firing an engineer after claims of AI's sentience to being astonished by DALLE's imagery, to ChatGPT and speculating on the topic of job security. So what about web scraping and AI? Is web scraping going to be automated? We wish. But don't listen to us, here's what AI has to say about it:
As you see, it's a lot about efficiency. Some assume that ChatGPT will soon replace Google (which Google, by the way, is also officially concerned about). However, many are too quick to overestimate the current capabilities of AI, which results in them spreading the misleading information or code it sometimes generates. One example of that is StackOverflow's ban on ChatGPT after a flood of wrong answers.
In terms of web scraping and AI, creating generic AI data extractors is an extremely challenging task, which is why there are still very few public AI data extractors out there. There were a few attempts at AI-powered web automation by data scraping providers, including, in our particular case, fingerprint and header generators, generic models for e-commerce, and automated product detail extraction. But it's a slow and complicated battle, because reliable web scraping at scale is still a challenge with too many variables for AI to handle.
David Barton
However, one difference the recent progress in AI made was a different baseline for the upcoming web scraping startups . New web scraping businesses no longer have to start from ground zero and can kick off their solutions with AI in mind (such as Dev Tools AI). Of course, after this year, you can also expect a lot of misuse of the term, so stay SEO-vigilant on the web.
Web scraping in 2023: recap of key points
🌐 Market
The web scraping industry has seen significant growth in recent years. However, the market is still competitive and ripe for innovation. One trend in the industry is the rebranding of web scraping as data extraction and the normalization of high-quality scraped data. Another trend is companies striving to provide a full web data lifecycle, including mergers and acquisitions to build a well-rounded ecosystem.
📚 Languages and libraries
In 2023, Python is widely considered the top choice for web scraping. One of the most popular libraries for Node.js scraping is Crawlee, with its advanced anti-blocking capabilities. For browser automation, Selenium and Playwright are the go-to tools, as they enable JavaScript rendering on dynamic websites, headless browser control, and automation of workflows.
❌ Anti-scraping
In 2023, it is expected that AI and browser fingerprinting will become an industry standard, datacenter proxies will be less effective, bot protections will affect user experience, mobile apps will have anti-scraping measures, and more data will be hidden behind login pages.
👨⚖️ Legal
The legal implications of web scraping have undergone significant changes due to the Van Buren and hiQ rulings in 2021 and 2022 respectively. As a result of these rulings, the Computer Fraud and Abuse Act (CFAA) is no longer seen as the primary legal claim for websites looking to sue web scraping companies. Instead, the focus has shifted to proving violations of a website's terms of use agreement (ToU). Meta gets a record amount of data privacy fines and keeps doubling down on C&D letters/lawsuits with web scraping companies.
🤖 Web scraping trends for 2023
- continued popularity of scraping social media and e-commerce sites
- increasing mentions in mainstream media, growing government and NGO use of web scraping
- increased focus on data privacy and security
- implementation of stricter anti-scraping measures by websites, including the AI-based ones
- discussion around AI and ChatGPT improving the accuracy and efficiency of web scraping
Read other reports about web scraping:



