


Getting a 403 error shouldn't stop you from extracting publicly available data from any website. But if you're getting blocked by a 403 error, here are a few things you can do.
What does error 403 mean?
Error 403 (or 403 Forbidden error) is a client error response HTTP status codes from the server side. Another example is the infamous 404 Not Found error, which shows up when a web page can't be found.
403 Forbidden means that the server has received your request but refuses to approve it. For a regular user, it is usually a sign they don't have sufficient rights to access a particular web page. A typical example is a request to view the website as an admin if you're not one.
However, a 403 error may be a sign of something different when web scraping.
Why am I getting a 403 error when web scraping?
There are several reasons for getting an HTTP 403 error. So like everything in programming, you will need to do some detective work to figure out exactly why 403 Forbidden showed up in your particular case. But if you’re trying not just to visit but also extract the data from a website, the reasons why a 403 Forbidden Error is glaring at you from the screen narrow down to just two:
- You need special rights to access this particular web resource - and you don’t have that authorization.
- The website recognized your actions as scraping and is politely banning you.
In a way, the second cause is good news: you’ve made a successful request for scraping. The bad news is that these days, websites are equipped with powerful anti-bot protections able to deduce the intentions of their visitors and block them. If the webpage you’re trying to scrape opens normally in a browser but gives you the 403 Forbidden HTTP status code when trying to request access via scraper – you’ve been busted!
But before we start with solutions, we need to know the challenge we’re up against: how was the website able to detect our scraper and apply anti-scraping protections to it? The short answer is digital fingerprints. ⏩ Skip to the longer answer if you already know enough about browser or user fingerprints.
These days, every respectable website with high stable traffic has a few tracking methods in place to distinguish real users and bots like our scraper. Those tracking methods boil down to the information the website gets about the user’s machine sending an access request to the server, namely the user’s device type, browser, and location. The list usually goes on to include the operating system, browser version, screen resolution, timezone, language settings, extensions like an ad blocker, and many more parameters, small and big.
Every user has a unique combination of that data. Once individual browsing sessions become associated with the visitor, that visitor gets assigned an online fingerprint. Unlike cookies, this fingerprint is almost impossible to shake off - even if you decide to clear browser data, use a VPN, or switch to incognito mode.
Next step: the website has a browser fingerprinting script in place to bounce visitors with unwelcome fingerprints. Some scripts are more elaborate and accurate than others as they factor in more fingerprint signals, but the end goal is the same: filter out flagged visitors. So if your fingerprint gets flagged as belonging to a bot (for example, after repeatedly trying to access the same web page within a short amount of time), it’s the script’s duty to cut your access from the website and show you some sort of error message, in our case, error 403.
There’s a reason why these techniques are employed in the first place: not all website visitors have good intentions. It is important to keep the spammers, hackers, DDoS attackers, and fraudsters at bay and allow the real users to return as many times as they want. It is also important to let search engine or site monitoring bots do their job without banning them.
But what if we’re just trying to automate a few actions on the website? There’s no harm in extracting publicly available data such as prices or articles. Unfortunately, abuse of web scraping bots led many websites to set strict measures in place to prevent bots from overloading their servers. And while websites have to be careful with singling out human visitors, there’s no incentive for them to develop elaborate techniques (besides robot.txt) to distinguish good and bad bots. It’s easier to ban them all except for search engines. So if we want to do web scraping or web automation, we’re left with no other option but to try and bypass the restrictions. Here’s how you can do it.
How to fix 403 errors when web scraping
Encountering a 403 error when web scraping typically means that the website is denying access due to the nature of the request. If the block is coming from Cloudflare specifically, you'll often see a Cloudflare error 1020 instead. To overcome this issue, you can try alternating the following solutions:
- Change user agents (to imitate different devices): modify the user agent to make your requests appear as if they come from different devices or browsers.
- Modify request headers (to imitate other browsers): adjust other HTTP headers to mimic a real browser more closely.
- Use rotating proxies (to imitate other locations): employ various proxies to periodically change your IP address.
Change user agents
The most common telltale sign that can make the website throw you a 403 error is your user agent. User-agent is a boring bit of information that describes your device to the server when you’re trying to connect to the server and access the website. In other words, the website uses your user agent info as a token to identify who’s sending an HTTP request to access it. It typically includes the application, operating system, vendor, and/or version. Here’s an example of a user agent token; as you see, it contains the parameters mentioned above.
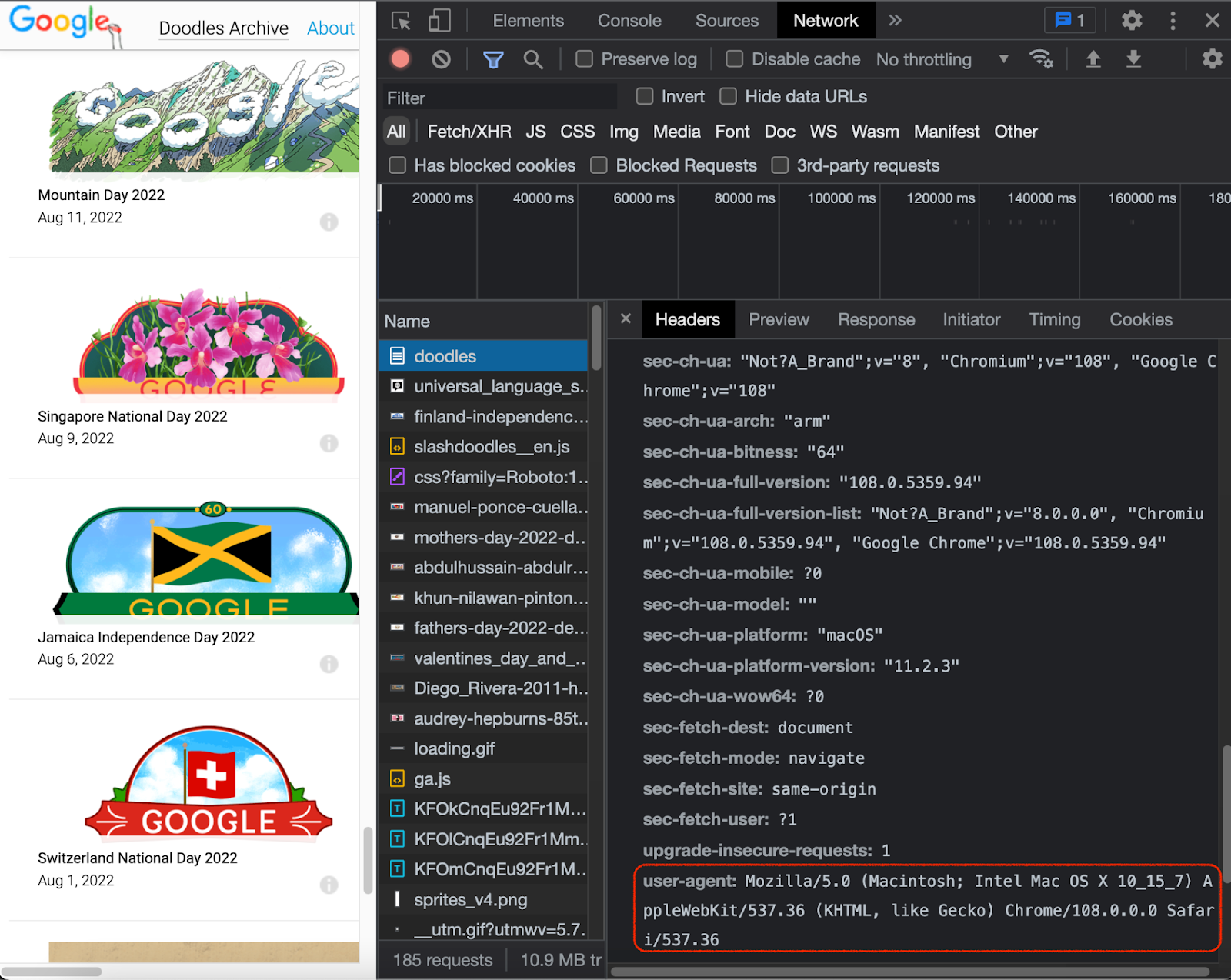
The good news is there are many ways to tinker with and change these parameters manually and try to come off as a different, let’s say, Mozilla+Windows user. But there are rules to it if you want to succeed.
Devices
A small warning before we start: sometimes the user agent term gets closely associated with the type of device: laptop, tablet, mobile, etc., so you might think if you replace the device type, it will be enough to pass as a different user. That’s not enough. The device type info is not standalone; it’s usually paired with a certain OS and/or browser.
You wouldn’t normally see an Android mobile device with an iOS using Opera or an iPad with a Windows OS and Microsoft Edge (unless you’re feeling adventurous). These unlikely combinations can unnecessarily attract website’s attention (because they are that - unlikely), and that’s what we’re trying to avoid here.
So even if you try to change the device type, it will require you to rewrite the whole user agent to come off as an authentic, real user instead of a bot. That’s why you need to know how to combine all those bits of info. There are some user agent combos that are more common than others and many free resources that share that information. Here’s one of them, for instance - you can find your own user agent there, too, and how common it is for the web these days.
Libraries
There are also HTTP libraries that offer many user agent examples. The problem with the libraries usually is that they can be either outdated or created for website testing specifically. While the issue with the former is clear, the latter needs a bit of explanation. The user agents from a testing library usually indicate directly that they are sampled from a library. This serves a purpose when you’re testing your website (clear labeling is important for identifying bugs) but not when you’re trying to come off as a real user.
{
"headers": {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"Host": "www.google.com",
"User-Agent": "got-scraping/1.3.9",
}
}
In the end, your best chance at web scraping is to come off as different users for the website by randomizing and rotating several sure-proof user agents. Here’s what that could look like:
import request from 'request';
const userAgentsList = [
'Mozilla/5.0 (X11; Linux x86_64; rv:107.0) Gecko/20100101 Firefox/107.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
];
let options = { url: 'https://google.com/doodles', headers: { 'User-Agent': userAgentsList[Math.floor(Math.random() * 3)] } };
Or, if you step up your game, you can use a library for randomizing user agents, such as modern-random-ua. Here’s an example of how to randomize user-agents from this library:
import request from 'request';
const userAgentsList = [
'Mozilla/5.0 (X11; Linux x86_64; rv:107.0) Gecko/20100101 Firefox/107.0',
'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36',
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36'
];
let options = { url: 'https://google.com/doodles', headers: { 'User-Agent': userAgentsList[Math.floor(Math.random() * 3)] } };
All this can help you to tinker with your user agent, come up with a list of the most successful cases, and use them in rotation. In many cases, diversifying your HTTP requests with different user agents should beat the 403 Forbidden error. But again, it all highly depends on how defensive the website you’re trying to access is. So if the error persists, here is a level-two modification you can apply.
More complex HTTP headers for browsers
Simple bot identification scripts filter out unwanted website visitors by user agent. But more refined scripts include checking users against HTTP headers – k namely, their availability and consistency.
Humans don’t usually visit a website without using some sort of browser as a middleman. These days modern browsers include tons of extra HTTP headers sent with every request to deliver the best user experience (screen size, language, dark mode, etc.)
Since your task is to make it harder for the website to tell whether your HTTP requests are coming from a scraper or a real user, at some point, you will have to change not only the user agent but also other browser headers.
Complexity
A basic HTTP header section, besides User-Agent, usually includes Referer, Accept, Accept-Language, and Accept-Encoding. A lot of HTTP clients send just basic HTTP header with a simple structure like this:
{
"Accept": "text/html, application/xhtml+xml, application/xml;q=0.9, image/webp, */*;q=0.8",
"Accept-Language": "en",
"User-Agent": "got-scraping/1.3.9",
}
Compare this with an example of a real-life, complex browser header:
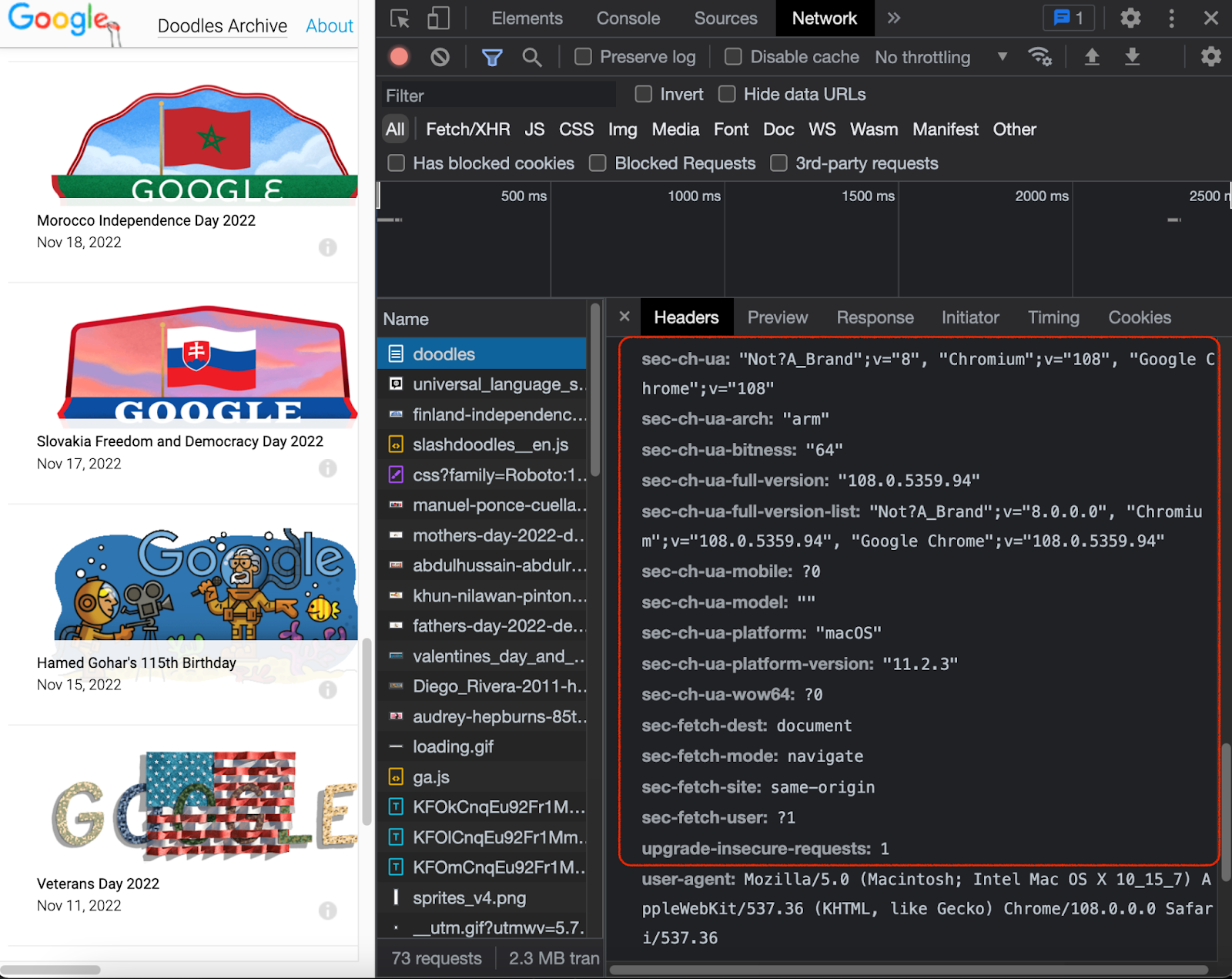
Note that it is not only about the browser name (that one is indicated in the user-agent) but rather the sidekick section that goes with it.
Consistency
Some HTTP headers are shorter, some are longer. But the important thing is that they also have to be consistent with user-agent. There has to be a correct match between the user-agent and the rest of the header section.
If the website is expecting a user visiting from an iPhone via Chrome browser (user-agent info) to be accompanied by a long header that includes a bunch of parameters (header info), it’ll be checking your request for that section and that match. It will look suspicious if that section is absent or shorter than it should be, and you can be banned.
For instance, here’s the browser compatibility table for including the Sec-CH-UA-Mobile parameter into the header.

As you can see, not every browser sends this header. But it does go with Chromium browsers, which means you’ll have to include it in your request if you want to come off as a real Chrome user. Usually, the more elaborate the browser header is, the better your chance is for flying under the radar – if you know how to put it together correctly. Our real Chrome header from the previous screenshot does include that parameter, by the way:
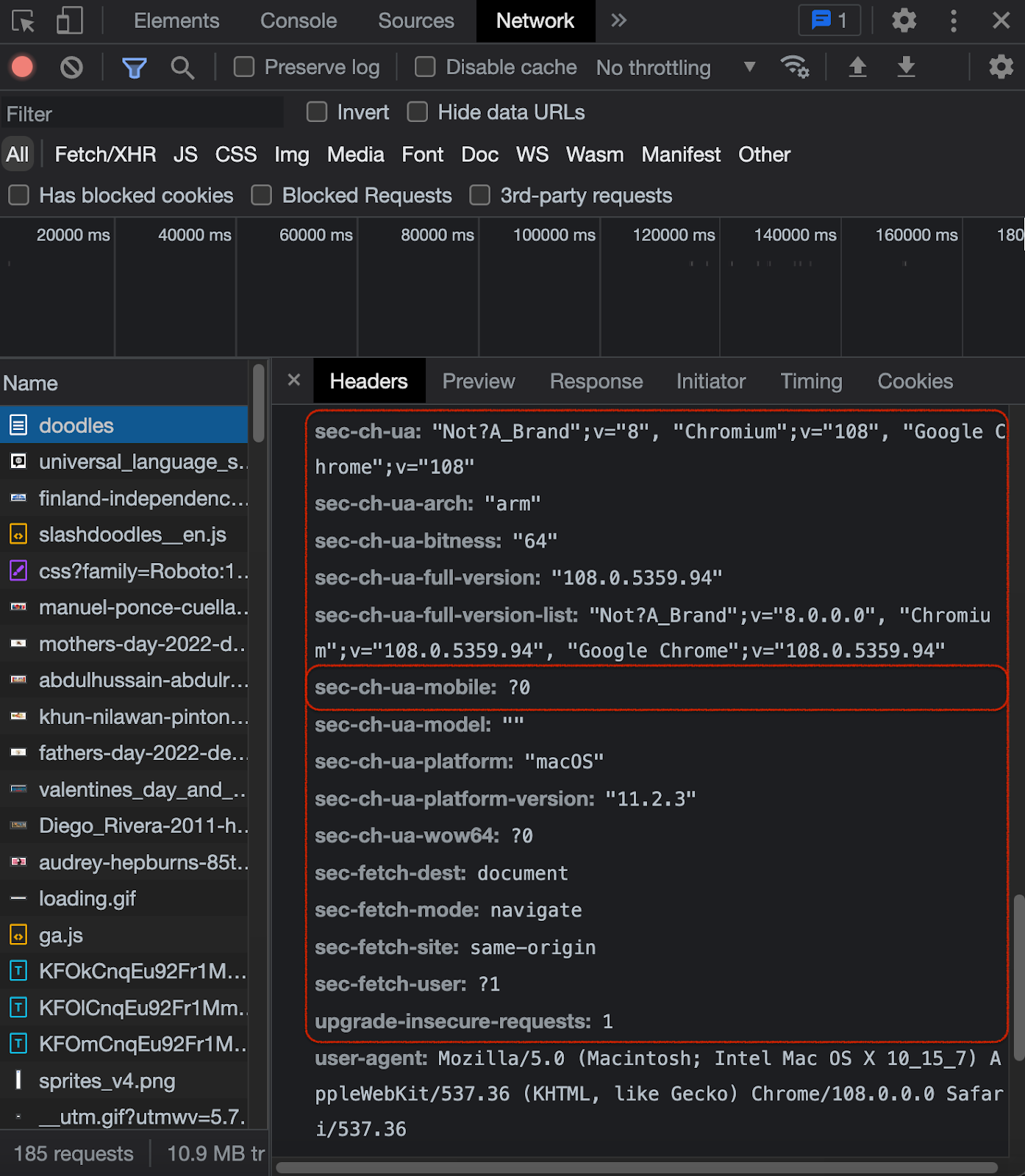
You can create your own collection of working header combos or turn to libraries. For instance, this is how you can send a request with a predefined header from the Puppeteer library:
await page.setExtraHTTPHeaders({
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/74.0.3729.131 Safari/537.36', 'upgrade-insecure-requests': '1',
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'en-US,en;q=0.9,en;q=0.8' })
await page.goto('...')
By adding an appropriate, expected request header, we’ve reduced the chances of being blocked by the website and getting the dreaded 403. Our request now comes off as from a real user using a real browser, and since most websites are quite careful about keeping human traffic, it gets a pass from the bot-blocking measures.
However, if the 403 error keeps showing up, we have to move on to level 3 issues: IP-rate limiting. Maybe you’ve overdone it with the number of requests to the website, and it flagged your IP address as one belonging to a bot. What now?
Rotating proxies
If the two options above have stopped working for your case, and the 403 error keeps showing up, it’s time to consider the last scenario: your IP address might be getting blocked.
This scenario is quite reasonable if you see it from the website’s point of view: it just got a large number of requests coming from the same IP address within an unnaturally short amount of time. Now it could be the case of many people sharing the same IP address by using the same WiFi, but they wouldn’t normally all go on the same website at the same time, right?
The most logical way to approach it is to use a proxy. There are many proxy providers out there, some paid, some free, and varying in type. There are even tools, such as our free Proxy Scraper, that can find free working public proxies for you. But the main point is proxies secure your request with a different IP address every time you access the website you’re trying to scrape. That way, the website will perceive it as coming from different users. This is the fix for rate-limit blocks specifically, like Cloudflare error 1015, which a site returns when it sees too many requests from a single IP in a short window.
You can use an existing proxy pool or create one of your own, like in the example below.
const { gotScraping } = require('got-scraping');
const proxyUrls = [
'http://usernamed:password@myproxy1.com:1234',
'http://usernamed:password@myproxy2.com:1234',
'http://usernamed:password@myproxy4.com:1234',
'http://usernamed:password@myproxy5.com:1234',
'http://usernamed:password@myproxy6.com:1234',
];
proxyUrls.forEach(proxyUrl => {
gotScraping
.get({
url: 'https://apify.com',
proxyUrl,
})
.then(({ body }) => console.log(body))
});
Don’t forget to combine the proxy method with the previous ones you’ve learned: user-agents and HTTP headers. That way, you can secure the chances for successful large-scale scraping without breaching any of the website’s bot-blocking rules.
Using ready-made solutions
You’re probably not the first one and not the last one to deal with the website throwing you errors when scraping. Tinkering with your request from various angles can take a lot of time and trial-and-error. Luckily, there are open-source libraries such as Crawlee 🔗 built specifically to tackle those issues.
This library has a smart proxy pool that rotates IP addresses for you intelligently by picking an unused address from the existing number of reliable proxy addresses. In addition, it pairs this proxy with the best user agents and HTTP header for your case. There’s no risk of using expired proxies or even the need to save cookies and auth tokens. Crawlee makes sure they are connected with your IP address, which diminishes the chances of getting blocked, including but not limited to the 403 Forbidden error. Conveniently, there’s no need for you to create three separate workarounds for picking proxies, headers, and user agents.
This is how you can set it up:
import { BasicCrawler, ProxyConfiguration } from 'crawlee';
import { gotScraping } from 'got-scraping';
const proxyConfiguration = new ProxyConfiguration({ /* opts */ });
const crawler = new BasicCrawler({
useSessionPool: true,
sessionPoolOptions: { maxPoolSize: 100 },
async requestHandler({ request, session }) {
const { url } = request;
const requestOptions = {
url,
proxyUrl: await proxyConfiguration.newUrl(session.id),
throwHttpErrors: false,
headers: {
Cookie: session.getCookieString(url),
},
};
let response;
try {
response = await gotScraping(requestOptions);
} catch (e) {
if (e === 'SomeNetworkError') {
session.markBad();
}
throw e;
}
session.retireOnBlockedStatusCodes(response.statusCode);
if (response.body.blocked) {
session.retire();
}
session.setCookiesFromResponse(response);
},
});
SessionPool in the Crawlee docs You also have complete control over how you want to configure your working combination of user agents, devices, OS, browser versions, and all the browser fingerprint details.
import { PlaywrightCrawler } from 'crawlee';
const crawler = new PlaywrightCrawler({
browserPoolOptions: {
useFingerprints: true, // this is the default
fingerprintOptions: {
fingerprintGeneratorOptions: {
browsers: [{
name: 'edge',
minVersion: 96,
}],
devices: [
'desktop',
],
operatingSystems: [
'windows',
],
},
},
},
// ...
});
Facing errors is the reality of web scraping. If, after trying all these various ways (rotating user agents, headers, and proxies), and even trying Crawlee, the 403 error still doesn’t leave you alone, you can always turn to the community for guidance and some pretty accurate advice. Share your issue with us on Discord and see what our community of like-minded automation and web scraping enthusiasts has to say.
Another frequent issue is, while being focused on something very complex, you could've missed something very obvious. Which is why you're invited to refresh your memory or maybe even learn something new on anti-scraping protections in Apify Academy. For CAPTCHA-specific challenges, see how to bypass CAPTCHA. Best of luck!





