


We’ve all encountered them – CAPTCHAs. Is it a bird, is it a plane, is it a bike, or is it a bus, or is it just a badly pixelated image of a CAPTCHA? This common feature, designed to verify human visitors, can be a huge obstacle in the user experience. We're going to look at why they're bad UX, how they can easily get bypassed, and what alternatives exist.
CAPTCHAs (or captchas, for when we feel less like screaming in all caps in this post) are one sure-fire way to ruin your enjoyment of any website, as you struggle and squint to decipher those blurry, weirdly-angled images.

Apify is a web scraping and automation platform, and anyone who is involved in web scraping at even the most superficial level will know that captchas are often one of the first puzzles a budding web scraper will need to deal with (although usually, they aren’t much of an obstacle, as you’ll find out below).
But how much do you really know about captchas? Why do we need them, are there alternatives, and do they even still work on the modern web? Read on for a quick exploration of the CAPTCHA and how it fails on multiple fronts, and might even be the cause for some exploitative practices across the world.
What is CAPTCHA?
The CAPTCHA, or Completely Automated Public Turing test to tell Computers and Humans Apart, was introduced to prevent bots and spammers from interacting with websites.
Captchas take advantage of the fact that humans are exceptionally good at doing some things that computers find very difficult. The earliest text-based captchas made use of the human ability to recognize letters that are malformed and distorted. Over time, as computers have become more powerful and algorithms more complex, captchas have evolved to use image recognition and other alternative approaches.
History of CAPTCHA
Captchas have been in use since the early 2000s, when they mostly looked like this:
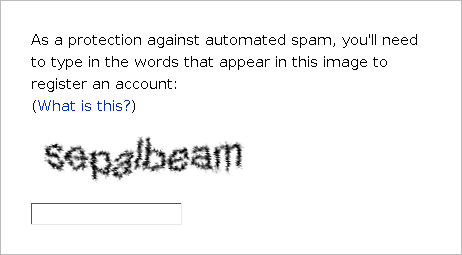
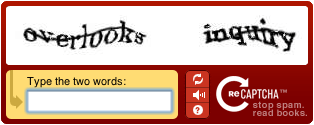
Originally developed at Carnegie Mellon University by Luis von Ahn, reCAPTCHA was based on mass collaboration to digitize books, with a pair of words presented to the user. One was used for control, the second deciphered an uncertain word using the power of crowdsourcing.
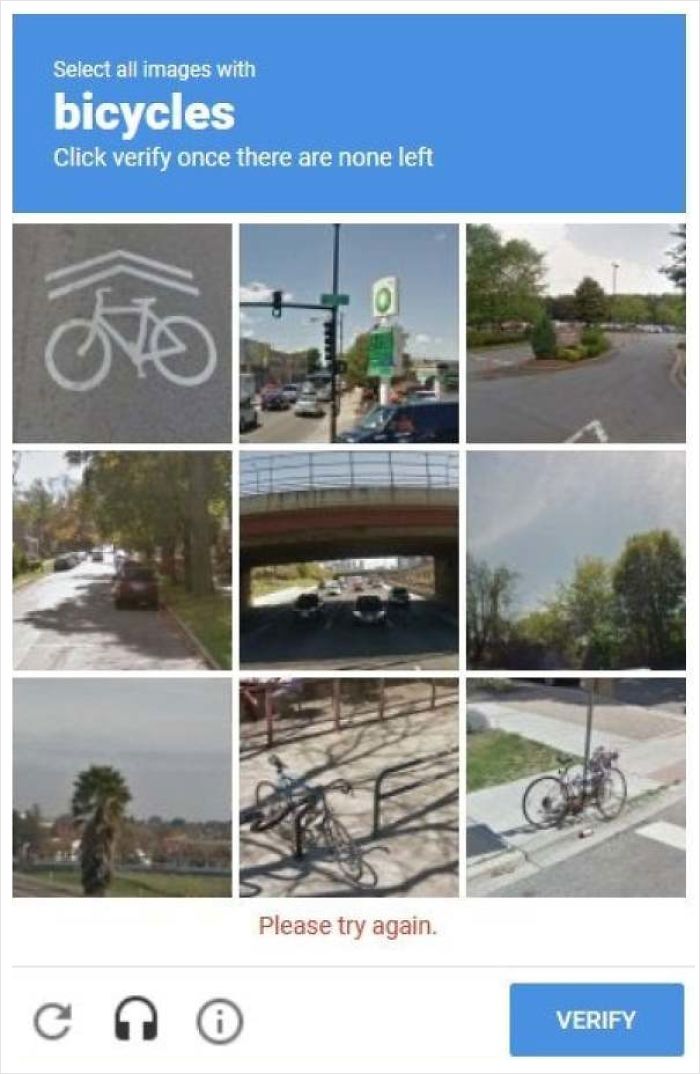
After reCAPTCHA was bought by Google in 2009, it was used to help digitize Google Books and displayed over 100 million captchas per day at its peak. Google introduced Google Street View images to reCAPTCHA in 2012 and it changed the way reCAPTCHA worked in 2014, switching to additional behavioral analysis of user activity to detect bots, and also introducing something closer to the kind of image captchas that we're all familiar with today, like this confusing cat captcha below:

Even though Google has tried to make its captcha service fade into the background with each release and it calls the current version a "frictionless fraud detection service", captchas are still as much of an annoyance to many users as cookie consent banners.
Advantages of CAPTCHA
In defense of captcha, it solved a very real problem in the early days of the internet and continues to play a small role in a comprehensive fraud management system by slowing down casual fraudsters or make it too expensive for them to bother causing too much mischief. Even just a quick roundup of what captchas do shows that they are helping to:
- Slow down brute force attacks to hack passwords
- Make it harder for hackers to sign up for multiple accounts on a website
- Limit fraudsters generating fake leads from filling out forms
- Help prevent ticket touts from buying up tickets in bulk
- Add an extra layer of security versus spammers for online activities such as polls, shopping, and forums
But note that each of these roles is really just about slowing down the enemy, or preventing those who do not have a financial, or other, incentive to get around the captcha. They aren’t really a solid brick wall for the determined, so do the pros outweigh the cons?
Disadvantages of CAPTCHA
Bad user experience
Captchas are designed to solve a real problem, but they're a bad design choice. Good user experience (UX) should make life easier for users, not harder, and we've all come across captchas that defeat our best attempts to solve them. Everyone on the internet has been at that crucial point where they sit wondering whether a bike sign is considered a bike.
Inaccessibility
And the problem is even worse for users with disabilities, with captchas acknowledged by W3C to effectively act as a "denial of service to these users". This kind of disenfranchisement can affect all levels of society, with one of the worst examples being a White House petition to help the blind in 2013 being rendered inaccessible to the blind.
The same is true of captchas that assume knowledge of the English language or Western Latin characters. Thousands of people around the world are either forced to struggle with unfamiliar letters, unfamiliar cultural imagery, or left unable to access sometimes essential information about other countries.

There are alternatives to captcha and any website designer who wants to be as inclusive as possible should explore them. A honeypot, for example, is a captcha visible to bots but not humans. The bot will attempt to solve the captcha, thereby proving that it is not human, while the human never even has to see the captcha. Other options are to rely on third parties such as Google to verify your visitors, or Cloudflare Bot Management to identify bots based on their behavior.
Captchas are disruptive to users because they are literally there to disrupt or impede access to websites. And, as bots get smarter thanks to machine learning, the problem just gets worse.
Speed and conversions
As if the UX problems weren’t enough, CAPTCHAs also affect how quickly pages load in browsers. Some studies estimate that even Google’s NoCaptcha reCaptcha was estimated to add 350 to 550 milliseconds globally to a website. Any kind of similar speed hit these days is likely to make your visitors just leave and go somewhere else.
Then there’s the problem of conversions. Getting traffic and visitors is hard enough, and costly enough, these days, without then requiring them to solve problems designed to slow them down and puzzle over distorted text or vague images. Although based on CAPTCHAs from a few years ago, a study of online and e-commerce sites found that up to 12 percent of potential customers will just leave a site rather than deal with a difficult captcha. Hey, there’s always somewhere else with better UX 🤷
Just plain wasteful
And at the end of the day, captchas are annoying and a great big waste of our collective time. Some recent back-of-the-envelope calculations from Cloudflare worked out that humanity as a whole wastes about 500 years per day on solving CAPTCHAS. Can’t humans do something more useful with our time in the twenty-first century?

Easily bypassed
The ultimate black mark against CAPTCHAs is that they can be so easily bypassed. If someone needs to access a website protected by a CAPTCHA, they can resort to a number of ways to get around it. Read on to find out how almost any captcha can be bypassed, and the hidden human story behind captcha solvers.
CAPTCHA killers
Several websites, such as 2Captcha, Anti Captcha, or Best Captcha Solver, exist to bypass CAPTCHA. Apify even uses one of them, Anti Captcha, to power one of our popular ready-made Actors, Anti Captcha Recaptcha.
This brings us to a much darker side of CAPTCHAs. While captchas can be defeated with sophisticated machine learning, often the method used is to take advantage of a difference in salary expectations between the first and third world and use real people to solve them. We might have designed CAPTCHAs to distinguish humans from bots, but what happens when an army of humans can solve them as quickly and cheaply as bots?
India is one of the few countries around the world where it makes sense for businesses to set themselves up as on-demand CAPTCHA solvers. The Philippines is another. If a person can be paid two dollars to solve a thousand captchas, that can be enough to give them a real advantage over their fellow citizens, even if they might only earn about $1.20 per day after working 11 hours non-stop. It makes CAPTCHAs seem like a bad joke, with the automation of solving CAPTCHAs really being fueled by human labor. But for people in those countries, the financial equation works and they make a living.
Is it legal to bypass CAPTCHAs?
Like any legal question regarding the internet, this is still a murky, gray area. In a recent court case in the United States, an article by Professor Orin Kerr of Berkeley Law was cited. Kerr argues:
The interesting question is whether use of an automated program to bypass the CAPTCHA by guessing or reading the words is an unauthorized access. The question is difficult because the technology shares some characteristics of a traditional authentication gate but not others. Like a password gate, it requires a code to be entered; but unlike a password gate, it presents the code to the user. Although it’s a close case, I think the better answer is that automated bypassing of a CAPTCHA is not itself an unauthorized access. Although the CAPTCHA looks like a password gate, it does not operate like one. The site tells everyone the password. It invites all to enter.
It is tempting to think that a CAPTCHA authenticates users as people instead of bots. But a “bot” request is still ultimately a request from a person. It is merely an automated request, with the person who used the software still responsible. That person could gain access and bypass the CAPTCHA manually by visiting the page and typing in the string of numbers that appear. As a result, a CAPTCHA is best understood as a way to slow a user’s access rather than as a way to deny authorization to access. The CAPTCHA is a speed bump instead of a real barrier to access. Courts should hold that automated access is not a trespass merely because it bypasses a CAPTCHA.
The case, regarding access to LinkedIn by a company called hiQ, ultimately determined that circumventing a CAPTCHA was not considered unacceptable use of a public website.
 Natasha Lekh
Natasha Lekh
Is there any way to solve CAPTCHAs automatically?
However, some relatively recent US anti-bot legislation is already being used to crack down on automated ticket purchasing for the purposes of resale. The Better Online Ticket Sales (BOTS) Act specifically “prohibits the circumvention of a security measure, access control system, or other technological control measure used online by a ticket issuer” and CAPTCHAs are mentioned in some of the cases in progress. That said, Zachary Sturman, in Vanderbilt Journal of Entertainment & Technology Law has some interesting comments on the unforeseen effects of such legislation:
The BOTS Act says that scalpers cannot circumvent online security measures or technological controls in order to violate ticket-purchasing rules or quantity limits. This makes it illegal for scalpers to pay for technological services that automatically solve CAPTCHA prompts. But if a scalper pays a friend to sit in front of a computer on his behalf to solve a CAPTCHA, then nobody has circumvented an online security measure. Instead, the scalper and his friend have contracted among themselves to abide by the security measures.
Because scalpers can, in light of the BOTS ACT, move away from automated CAPTCHA-solving services and into human-based CAPTCHA-solving services, this substitution renders the BOTS Act largely ineffective. The BOTS Act does not cover human-based CAPTCHA-solving services because these services do not circumvent or dupe security measures. To think otherwise would mean that nobody can purchase tickets - for example, as a gift-on behalf of another person. Human-based CAPTCHA-solving services are popular, cheap, and make it difficult for ordinary consumers without this service to acquire tickets on the primary market in the same way that automated services do. Therefore, the BOTS Act likely causes scalper substitution from automated services to human-based ones without reducing the price of tickets for end consumers.
There is one additional sense in which the BOTS Act's encouragement of human-based CAPTCHA-solving services is not merely consummate with but instead worse than the non-BOTS Act world. Incentivizing human-based services means that regions with low labor costs are the most likely to host these services. Accordingly, low-income individuals in impoverished areas are, thanks to the BOTS Act, probably now more likely to sit all day in front of computer screens solving CAPTCHA prompts that cost users two dollars for each thousand CAPTCHAs solved. Our laws should not push people into this sort of socially wasteful work. Individuals who solve CAPTCHAs all day do not produce new value for the world; instead, they engage in this type of work because the BOTS Act artificially induces it.
This is probably not the end of the arms race between websites that use CAPTCHA and companies that find ways around them to get the data they want, so the best advice is always to be aware of the terms and conditions of the website you’re accessing and try to do no harm by not overloading its servers and not scraping personal data. We all have to share the internet, so let’s try to make it a great place to work and live together, while also pushing the limits of what we can do with all this amazing technology we have to work with 🦾
As part of Apify’s ongoing research into ways to automate everything on the web, we’re working on a new CAPTCHA solving tool based on some rather interesting technology. Subscribe to the blog to get a look at it as soon as it’s ready!





