



This article was first published on December 15, 2023, and updated on January 29, 2024, to reflect recent updates in the legal landscape of web scraping.
How did 2023 treat the web scraping industry? Let's take a short walk through the bad, the good, and the different of yesteryear. Welcome to a summary of the key events and trends that emerged in 2023, setting the stage for the landscape of 2024.
🧑⚖️ Irony of the year
The year started off funny. In 2022, Meta was very keen on suing individuals and companies for web scraping; in 2023, it continued to zero in even on its recent allies. The culprit in question, Bright Data, got sued by Facebook for scraping Facebook data. The trick is that Facebook was using Bright Data's services previously for… scraping data (just from other websites). Essentially, Meta inadvertently revealed its practice of collecting data from other websites through its lawsuit against a firm it employed for this very purpose. Quite some web scraping uroboros there. This situation once more highlighted the two aspects of an age-old industry question: who really owns publicly accessible data, and is it okay to gather it?
In a cruel twist of fate, later last year, Meta got another billion-sized fine (as big as the previous 6 combined, apparently) from the Irish DPC for not protecting the data of EU citizens from surveillance. The Irish Data Protection Commission and EU are not playing when it comes to data privacy. The penalty relates to an inquiry that was opened by the DPC back in 2020. And it seems like in 2024 Meta will be facing several other lawsuits regarding ad space and its pay-or-consent policy, this time from Spanish media and Austrian data protection authority.
The pack of plaintiffs claiming the violation of terms and conditions was extended by a new member, with Air Canada filing suit against travel search site seats.aero in a similar case, alleging unlawful scraping of its website and thus violating its terms of conditions. Interestingly however, Air Canada also claims breach of criminal law under the Computer Fraud and Abuse Act (CFAA). This move could signal that, although claims on these grounds have been in the past dismissed by courts in Van Buren 2021 and the hiQ April 2022 ruling built on it, the CFAA has still not lost its allure for all of the websites wanting to sue web scraping companies.
👀 The non-event of the year
There are always a few things in life to be grateful for because they did not happen: the extinction of the bees, the eruption of Yellowstone Volcano, and the Google WEI Proposal. The Web Environment Integrity (WEI) proposal, which was pushed by Google, was eventually abandoned this year (not in the least due to the protest of the defenders of the free web — see screenshot from explainers-by-googlers issues).
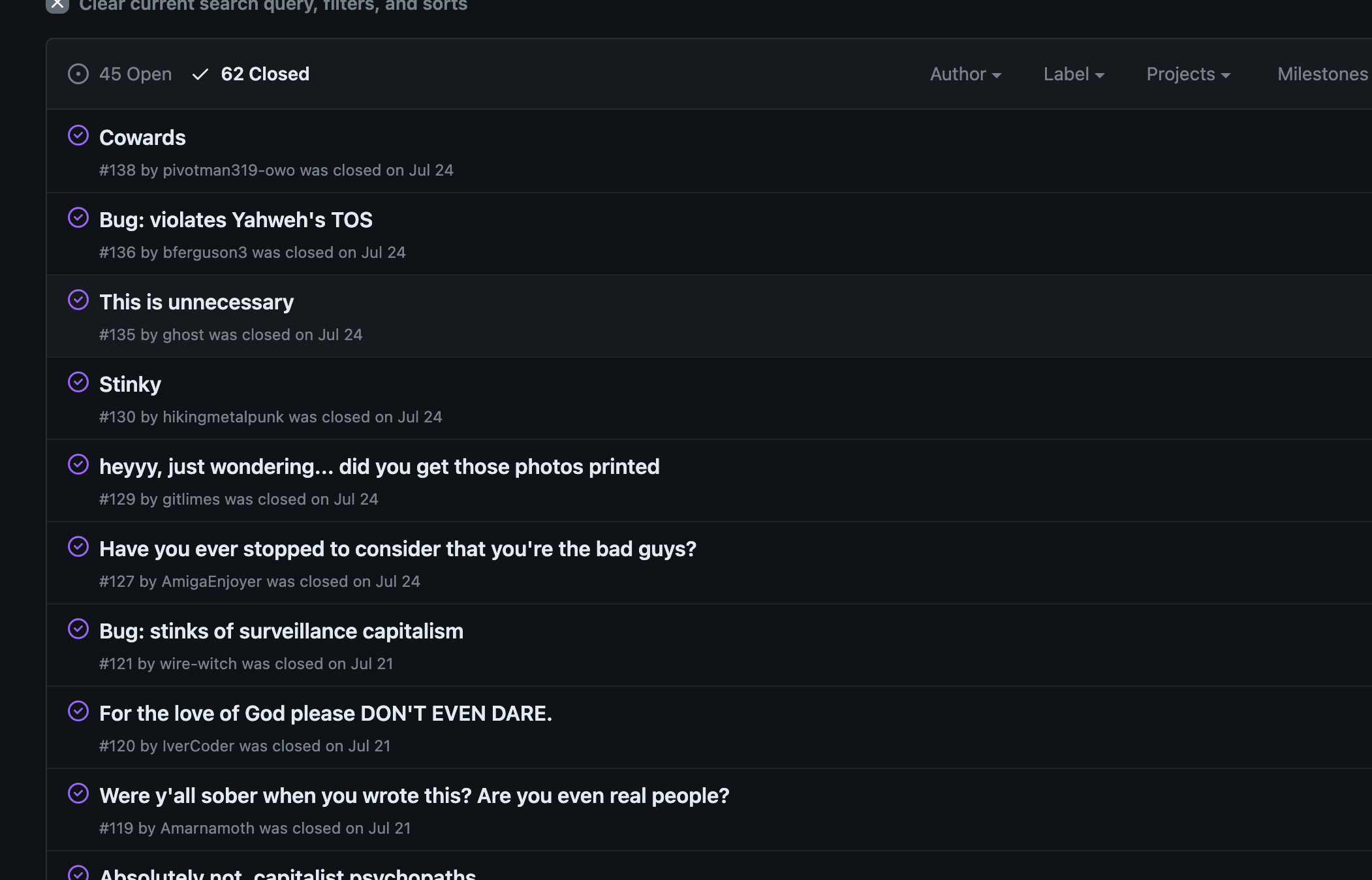
Google was trying to follow the likes of Apple to replace Captchas with a digitally signed token, an API containing a digitally signed token, to be precise. The reason seemed innocuous: to help separate real users from bot users, and real traffic from bot traffic, and limit online fraud and abuse — all this without enabling privacy issues like cross-site tracking or browser fingerprinting. Sounds like a dream, right?
However, while it might aid in reducing ad fraud, Google's proposed method of authentication also carries the risk of curtailing web freedom by allowing websites or third parties to directly influence the choice of browsers and software used by visitors. It could also potentially lead to misuses, such as rejecting visitors using certain tools like ad blockers or download managers.
Besides, Google intended to implement the Web Environment Integrity API in Chromium, the open-source base for Chrome and several other browsers, excluding Firefox and Safari. This, in comparison, makes Apple's Private Access Token seem way less dangerous, not in the least part because Safari has a much smaller browser market share than Chrome.
The drawbacks were quickly noticed by the open web proponents in the tech community. Critics quickly recognized the potential for this to evolve into a kind of digital rights/restriction management for the web. They also highlighted that this change would wildly benefit the ad companies but create high risks of disadvantaging the users. It would also make scraping and web automation activities significantly harder. Well, for everyone except for Google, of course.
The rejection of WEI by the tech community again highlights the importance of maintaining an open and accessible web.
🁫 First domino of the year
Scraping social media is the most common web scraping use case. In the old internet days, websites kept their APIs free and accessible, and even if they backed down from that, they often left a free version for the developers. The year started with X (Twitter)'s move to a paid API model, which meant discontinuing free access even for developers. A few months later, Reddit followed suit with its API transition to a paid model — which caused significant uproar and protests.
X's API policy changes might have contributed to the more frequent occurrences of Twitter scraping. With many projects forced to shut down due to the three price tiers, it's very likely that some developers had to turn to web scraping and browser automation as an alternative. We tried to keep up with these changes ourselves as providers of a more affordable Twitter API and Reddit API. But it's becoming increasingly difficult or inconvenient to scrape these websites without a reliable infrastructure.
👺 Troublemaker of the year
Last year the web scraping case law made strides with the hiQ vs. LinkedIn case. 2023 had been rather calm on the legal side of things, if not for one particular persona. If, in 2022, Meta was the one suing individuals and companies for harvesting data, this year was a debut for X (Twitter). To be fair, the year 2023 was a debut for a lot of things for Twitter, but let's focus on the thing in question.
Elon Musk, the tech mogul, made headlines with public promises to take legal action against web scraping companies. This move was followed by X adding and then silently removing the login requirement for viewing posts (tweets) and following through with the promise by initiating lawsuits against 4 unknown individuals. And before all that, Musk has made Twitter API paid. But let's follow step-by-step here.
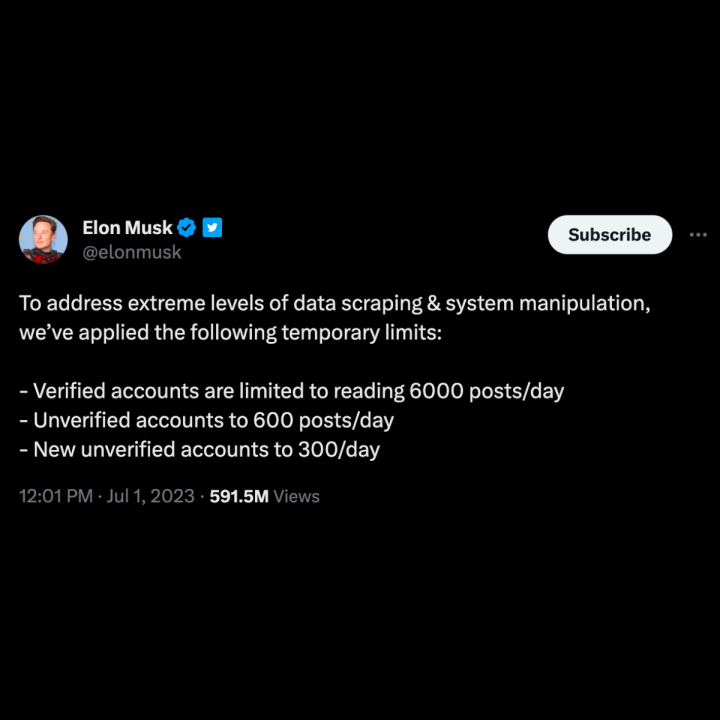
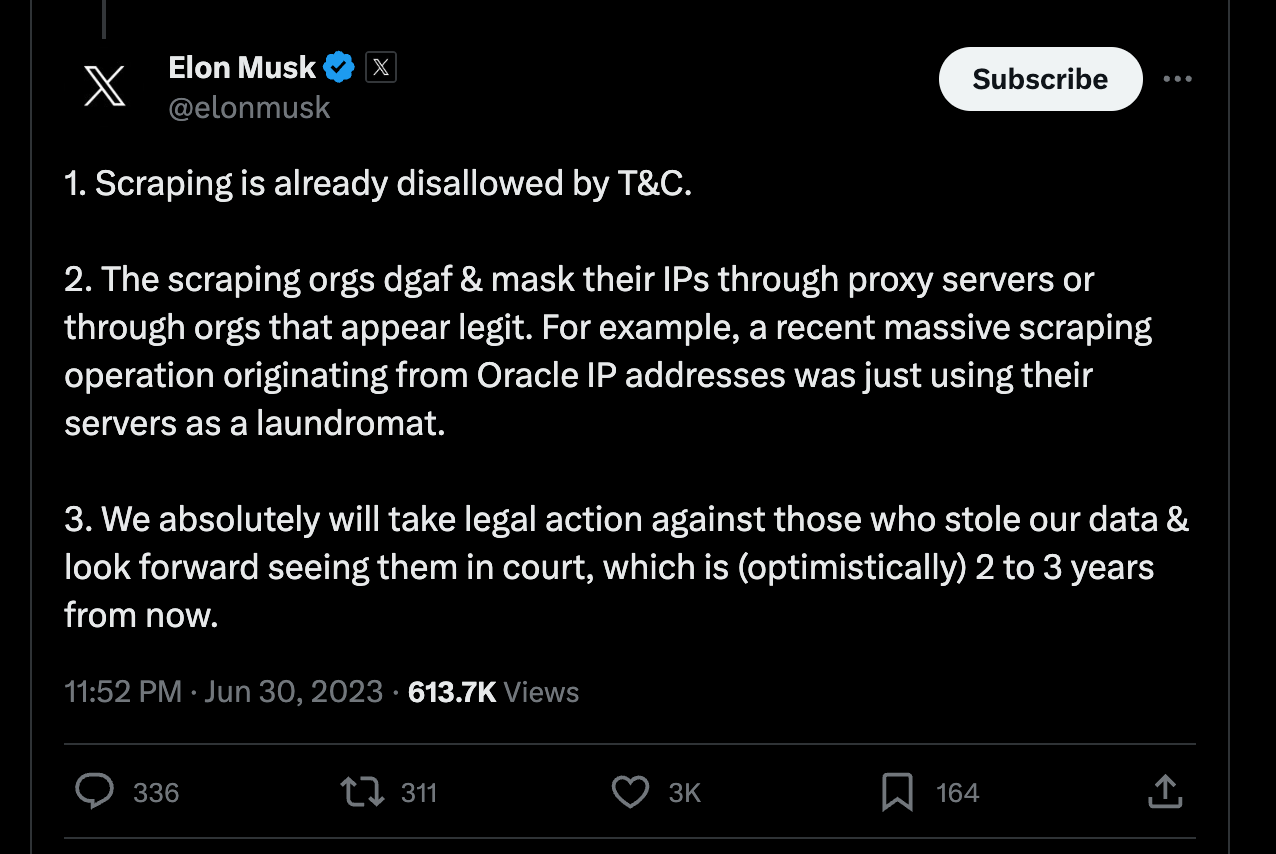
In July 2023, Elon Musk (well, X Corp, if we're being precise) gave us all some heat by initiating legal action against four anonymous entities who were scraping Twitter. Apparently, the four defendants overwhelmed Twitter's registration page with automated requests to such an extent that it caused a significant server strain and disruption of service for users. The culprits are accused of overburdening Twitter's servers, diminishing user experience, and profiting unjustly at the company's expense.
And as a regular cherry on top, the lawsuit further accuses them of scraping Twitter user data in breach of the platform's user agreement. These days, breach of Terms of Service has become companies’ favorite reference when instigating lawsuits against web scraping. Seconded only by scraping data for large language models training — which is a concern raised by Elon Musk as well. Despite these latter allegations, he did confirm that his recently launched firm, xAI, will use X posts for training purposes. So go figure.
The lawsuit suggests that the intensive data scraping led to such severe performance issues that X had to enforce a login requirement for access for everyone. Users are now required to have an account to view tweets and must subscribe to Twitter Blue's "verified" service to see over 600 posts per day.
Now, we don't know for sure whether the AI data scraping was so intense that it could have impacted the website as much. However, this lawsuit and the argumentation behind it raise concerns about the potential for misrepresenting ethical data scraping practices, especially companies that adhere to legal and ethical standards in data collection.
Resources:
- What is ethical web scraping and how do you do it? ⚖️ 5 principles of web scraping ethics
- Are website terms of use enforced?
- Ethical data, Explained. Responsible web scraping: challenges and approaches.
📈 Trend of the year
AI brings a new way to easily process large amounts of data – something that required developing complex and special machine learning models before. These days anybody can do, for instance, sentiment analysis with LLMs.
– Marek Trunkat, CTO of Apify
Web scraping really became the household term after the waves caused by ChatGPT and OpenAI this year. Why? Because web scraping was heavily involved in the training process. In Google Trends, among the regular adjacent topics such as point-and-click or proxy, we see AI. And this trend is here to stay.
We were happy to observe that making a one-off regular web scraper using AI is so easy these days. The AI hype makes it seem simple and accessible even without coding knowledge. It's the reliability and continuity of scraping that the AI cannot guarantee, especially with websites employing their own blocking measures based on AI.
🦾 AI and the hunt for data
The AI revolution of 2023 only underscored the already growing need for data from the web. All large language models (LLMs) like GPT-4 and LLaMA-2 were trained on data scraped from the web. As demand for AI and LLM applications will continue to grow, so will grow the demand for web scraping and data extraction.
– Jan Curn, Apify Founder & CEO
The large language models that power ChatGPT and other AI chatbots get their mastery of language from essentially two things: massive amounts of training data scraped from the web and massive amounts of compute power to learn from that data. That second ingredient is very expensive, but the first ingredient, so far, has been completely free.
However, creators, publishers, and businesses increasingly see the data they put on the web as their property. If some tech company wants to use it to train its LLMs, they want to be paid. Just ask the Associated Press, which struck a training data licensing deal with OpenAI. Meanwhile, X (née Twitter) has taken steps to block AI companies from scraping content on the platform.
Web data and RAG
The knowledge of LLMs is limited to the public data they were trained on. Building AI applications that can retrieve proprietary data or public data introduced after a model’s cutoff date and generate content based on it requires augmenting the knowledge of the model with specific information. That process is known as retrieval-augmented generation (RAG), and it has revolutionized search and information retrieval.
While the likes of LangChain and LlamaIndex swiftly took center stage in this field, web scraping (being the most efficient way to collect web data) has remained a significant part of RAG solutions.
To work around the training data cutoff date problem to provide models with up-to-date knowledge, LLM applications often need to extract data from the web. This so-called retrieval-augmented generation (RAG) is what gives the LLMs the superpowers and arguably this is the strongest use case of LLMs.
– Jan Curn, Apify Founder & CEO
Adding data to custom GPTs
OpenAI launched GPTs (custom versions of ChatGPT) in November 2023. This was a really big deal, as suddenly, everyone had the means to build their own AI models. These GPTs can be customized not only with instructions but also with extra knowledge (by uploading files) and a combination of skills (with API specifications). In other words, you can give such GPTs web scraping capabilities with the right specs or scrape websites to upload knowledge to a GPT so it can base generated content on that information.
The hype around GPTs was quickly replaced by a huge furore around the firing and return of OpenAI’s CEO. As a result, the debut of GPT Store, which lets users monetize their GPTs, was postponed and finally launched in early 2024.
EU AI Act represents break-through legislation for AI and web scraping
After the global shake-up in the world of personal data protection represented by GDPR, the EU reached a provisional agreement on the EU AI Act, which has similar ambitions for the world of artificial intelligence as GDPR had for personal data. Hailed by EU officials as “global first” and “historic”, the Act positions the EU as a frontrunner in the field of AI regulation.
The EU adopted a risk-based approach, defining four different classes of AI systems. The AI systems are divided into four categories: (1) unacceptable risk, (2) high risk, (3) limited risk, and (4) minimal/no risk.
Firstly, in the unacceptable risk category will belong to those AI systems which contravene EU values and are considered to be a threat to fundamental rights. These systems will be banned entirely. Among others, this category will include:
- biometric categorization systems that use sensitive characteristics (e.g., political, religious, philosophical beliefs, sexual orientation, race, etc.);
- untargeted scraping of facial images from the Internet or CCTV footage to create facial recognition databases;
- emotion recognition, social scoring, AI systems manipulating human behavior, or exploiting vulnerabilities of people (due to their age, disability, social or economic situation, etc.).
However, the EU regulators incorporated several exceptions to using AI systems in this category, such as the use of biometric identification systems for law enforcement purposes, which will be subject to prior judicial authorization and only for a strictly defined list of crimes.
Secondly, the Act will include some AI systems in the high-risk category due to their significant potential harm to health, safety, fundamental rights, the environment, democracy, and the rule of law. Among others, this category will include AI systems in the field of medical devices, certain critical infrastructure, systems used to influence the outcome of elections or voter behavior, and more. These systems will be subject to comprehensive mandatory compliance obligations, such as fundamental rights impact assessment, conducting model evaluations and testing, reporting serious incidents, etc.
Thirdly, the AI systems classified as limited risk, such as chatbots, will be subject to minimal obligations, such as the requirement to inform users that they are interacting with an AI system and the obligation to mark the image, audio, or video content generated by AI.
Lastly, all AI systems not classified in one of the other three categories will be classified as minimal/no risk. The Act allows for the free use of minimal and no-risk AI systems, with voluntary codes of conduct encouraged.
Violations of the Act will be subject to fines, depending on the type of AI system, the size of the company, and the severity of the infringement.
Resources:
- How to use LangChain
- What is retrieval-augmented generation?
- How to create a custom AI chatbot
- LlamaIndex vs. LangChain
- How to add custom actions to GPTs
- AI and web scraping in 2024: trends and predictions
- How to do question answering from a PDF
- How to collect data for LLMs
- How Intercom uses Apify to feed web data to its AI chatbot
🌟 Apify's contributions
Of course, we could not pass up an opportunity to contribute to the party. For the 8 years that Apify has been on the market — from the early days in Y Combinator to the transition from Apifier to now, it's been our goal to develop the cloud computing platform for automation and web scraping tools. So here's what we did this year to come a little bit closer to that goal.
Support for Python users: SDK, code templates, and Scrapy spiders
We've started the year off pretty strong by taking a significant — and probably unexpected — step forward. In March 2023 (on Pi Day, to be precise), we launched Python SDK to expand our toolset for Python developers. Now, if you know anything about Apify, you know that we have traditionally been on Node.js/JavaScript side of things. But things change, and so does the market and requests from our users. Being a start-up means venturing into different directions and trying different things when the situation calls for it. And since we consistently work on becoming the platform for web scraping and automation, launching a library for Python developers, giving them something to start from, just made sense.
As a follow-up step, we've rolled out web scraping templates aimed to simplify and improve the developer experience on our platform. We've realized not everyone wants to use ready-made tools in the Store or have complete control over every single aspect when building a scraper like with Crawlee. Web scraping templates seemed like a great third option, so here they are: in JavaScript, TypeScript, and Python. We've also launched the $1/month Creator Plan to support our most avid and enthusiastic users who are interested in building Actors.
Last but not least, we've made it possible to deploy Scrapy spiders to our cloud platform. All you have to do is use a Scrapy wrapper. The platform provides proxies and API and allows our Python users to run, schedule, monitor, and monetize their spiders.
Store and community growth
This year we've had to deal with unprecedented interest and growth of our Actors published in Store. The number of users engaging with Public Actors in Store has doubled, soaring from 8,971 to 17,070. In terms of new contributions, we've seen a significant influx, with 657 new Actors being published this year, a substantial increase compared to the 290 in 2022. Moreover, our community has been enriched by the addition of 96 new community developers, who have joined us with their Public Actors, doubling the number from the 48 who joined in 2022. This growth not only reflects the rising popularity of our platform but also underscores the expanding ecosystem for web scraping and automation we're building together.
New integrations and AI ventures
We've launched integrations with LlamaIndex and LangChain, marking a notable expansion in its collaboration network. These integrations mean you can load scraped datasets directly into LangChain or LlamaIndex vector indexes and build AI chatbots such as Intercom's Fin or other apps that query text data crawled from websites.
We've also introduced 3 AI tools in our Store to help fuel large language models and the likes: GPT Scraper and Extended GPT Scraper, Website Content Crawler, and AI Web Agent. Last but not least, we've launched a not LLM-related but nevertheless web scraping solution with AI at its core, AI Product Matcher.
Blog and YouTube
Regarding content, you can notice that our blog switched to a more technical approach, as well as our YouTube tutorials. We've also recorded our first podcast about the legality of web scraping. We've held three webinars on pretty extensive topics and experimented with posting Shorts. Our internal user engagement is as strong as ever — with our newsletter reaching over 68K people every month, with around a 65% open rate. You can now subscribe to an online version of it on LinkedIn if you don't like your inbox crowded.
Apify platform
Our crown jewel, the Apify platform, is evolving day by day, not only design and UX-wise but also functionality-wise. We are currently working on a video of a new tour of Apify that will showcase all the new features and changes made this past year. But for now, here's something to look back on and appreciate the progress:
See you in the new year!
Read other reports about web scraping:





