In this tutorial, we’re going to build a custom AI chatbot. Our chatbot is going to work on top of data that will be fed to a large language model (LLM). In other words, we’ll be developing a retrieval-augmented chatbot. The main tools we’ll use are Streamlit and LangChain.
- Streamlit is a tool for the quick creation of web apps. We’ll use it to implement the chat interface.
- LangChain is a framework that simplifies the building of LLM apps. It mostly acts as the “glue” between vector databases, LLMs, and your custom code.
We’ll split this tutorial into 3 steps:
- First, we’ll get some data that can be used as context for the LLM.
- Second, we’ll use Streamlit to create the chat interface.
- Lastly, we’ll connect everything together using LangChain.
The code is available at https://github.com/apify/chat-with-a-website.
Obtaining the data and saving it in a vector database
First, we want to collect some data. We'll later use this as the context provided to the LLM when chatting. Our example code will use Apify’s Website Content Crawler to scrape the selected website and store it in a local vector database.
First, let’s create an .env file that will contain the website we want to chat with and API tokens for Apify and OpenAI:
OPENAI_API_KEY=your_api_key
APIFY_API_TOKEN=your_api_key
WEBSITE_URL="<https://docs.apify.com/platform>"
Next, let’s install all the required packages:
pip install apify-client chromadb langchain openai python-dotenv streamlit tiktoken
Our environment’s all set, so let’s write some Python code!
Let’s create a new file called scrape.py. First, we want to import the necessary packages and load our .env file:
import os
from apify_client import ApifyClient
from dotenv import load_dotenv
from langchain.document_loaders import ApifyDatasetLoader
from langchain.document_loaders.base import Document
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
# Load environment variables from a .env file
load_dotenv()
Next, we’ll write the main function:
if __name__ == '__main__':
apify_client = ApifyClient(os.environ.get('APIFY_API_TOKEN'))
website_url = os.environ.get('WEBSITE_URL')
print(f'Extracting data from "{website_url}". Please wait...')
actor_run_info = apify_client.actor('apify/website-content-crawler').call(
run_input={'startUrls': [{'url': website_url}]}
)
print('Saving data into the vector database. Please wait...')
loader = ApifyDatasetLoader(
dataset_id=actor_run_info['defaultDatasetId'],
dataset_mapping_function=lambda item: Document(
page_content=item['text'] or '', metadata={'source': item['url']}
),
)
documents = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=1500, chunk_overlap=100)
docs = text_splitter.split_documents(documents)
embedding = OpenAIEmbeddings()
vectordb = Chroma.from_documents(
documents=docs,
embedding=embedding,
persist_directory='db2',
)
vectordb.persist()
print('All done!')
We'll run the Website Content Crawler Actor on Apify to scrape the target website, then use the ApifyDatasetLoader that is integrated into LangChain to load the scraped documents.
Then, we use the RecursiveCharacterTextSplitter to chunk the documents, and finally, we use OpenAI’s embeddings to convert our documents into vectors that get stored in the db directory.
Creating the chat interface
We're gonna use Streamlit to create the interface. We’ll base it on examples provided at https://github.com/langchain-ai/streamlit-agent.
Let’s start with the imports and some settings:
import os
import streamlit as st
from dotenv import load_dotenv
from langchain.callbacks.base import BaseCallbackHandler
from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI
from langchain.embeddings import OpenAIEmbeddings
from langchain.memory import ConversationBufferMemory
from langchain.memory.chat_message_histories import StreamlitChatMessageHistory
from langchain.vectorstores import Chroma
load_dotenv()
website_url = os.environ.get('WEBSITE_URL', 'a website')
st.set_page_config(page_title=f'Chat with {website_url}')
st.title('Chat with a website')
Next, we'll implement some helpers. The get_retriever function will create a retriever based on data we extracted in the previous step using scrape.py. The StreamHandler class will be used for streaming the responses from ChatGPT to our application.
@st.cache_resource(ttl='1h')
def get_retriever():
embeddings = OpenAIEmbeddings()
vectordb = Chroma(persist_directory='db', embedding_function=embeddings)
retriever = vectordb.as_retriever(search_type='mmr')
return retriever
class StreamHandler(BaseCallbackHandler):
def __init__(self, container: st.delta_generator.DeltaGenerator, initial_text: str = ''):
self.container = container
self.text = initial_text
def on_llm_new_token(self, token: str, **kwargs) -> None:
self.text += token
self.container.markdown(self.text)
Finally, let’s add the main code. We use the ConversationalRetrievalChain utility provided by LangChain along with OpenAI’s gpt-3.5-turbo. The rest of the code sets up the Streamlit chat interface.
retriever = get_retriever()
msgs = StreamlitChatMessageHistory()
memory = ConversationBufferMemory(memory_key='chat_history', chat_memory=msgs, return_messages=True)
llm = ChatOpenAI(model_name='gpt-3.5-turbo', temperature=0, streaming=True)
qa_chain = ConversationalRetrievalChain.from_llm(
llm, retriever=retriever, memory=memory, verbose=False
)
if st.sidebar.button('Clear message history') or len(msgs.messages) == 0:
msgs.clear()
msgs.add_ai_message(f'Ask me anything about {website_url}!')
avatars = {'human': 'user', 'ai': 'assistant'}
for msg in msgs.messages:
st.chat_message(avatars[msg.type]).write(msg.content)
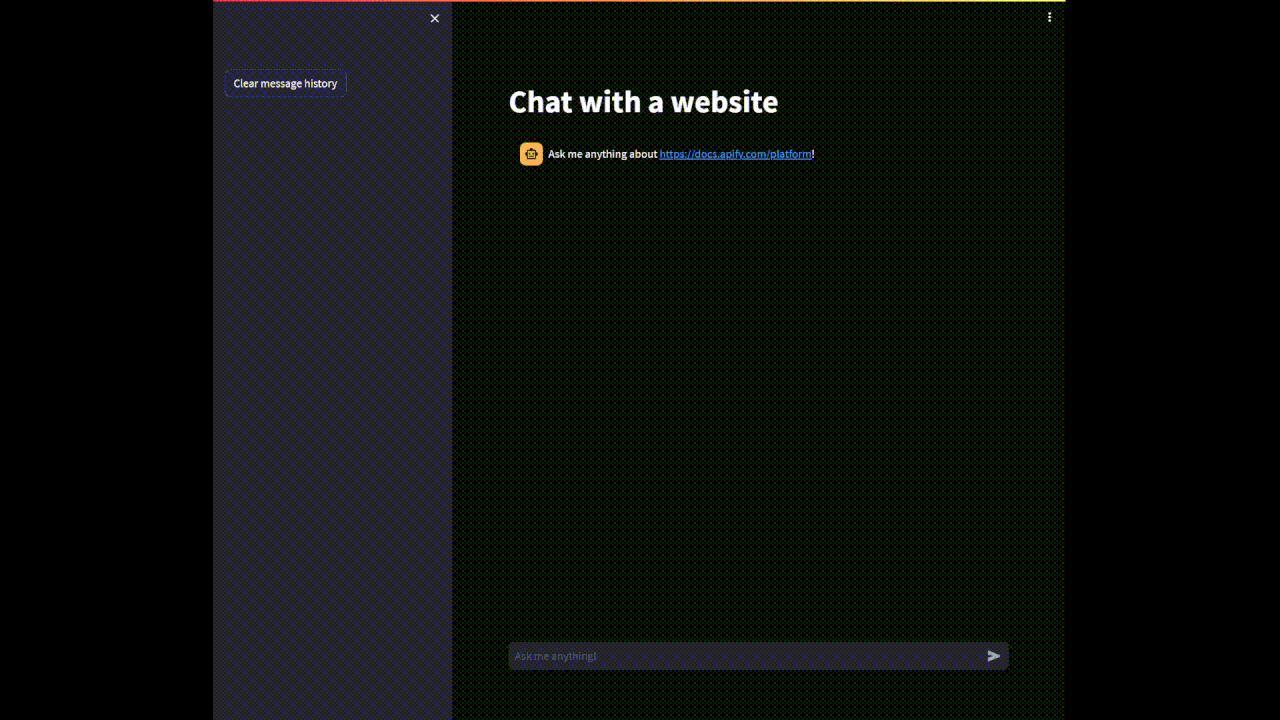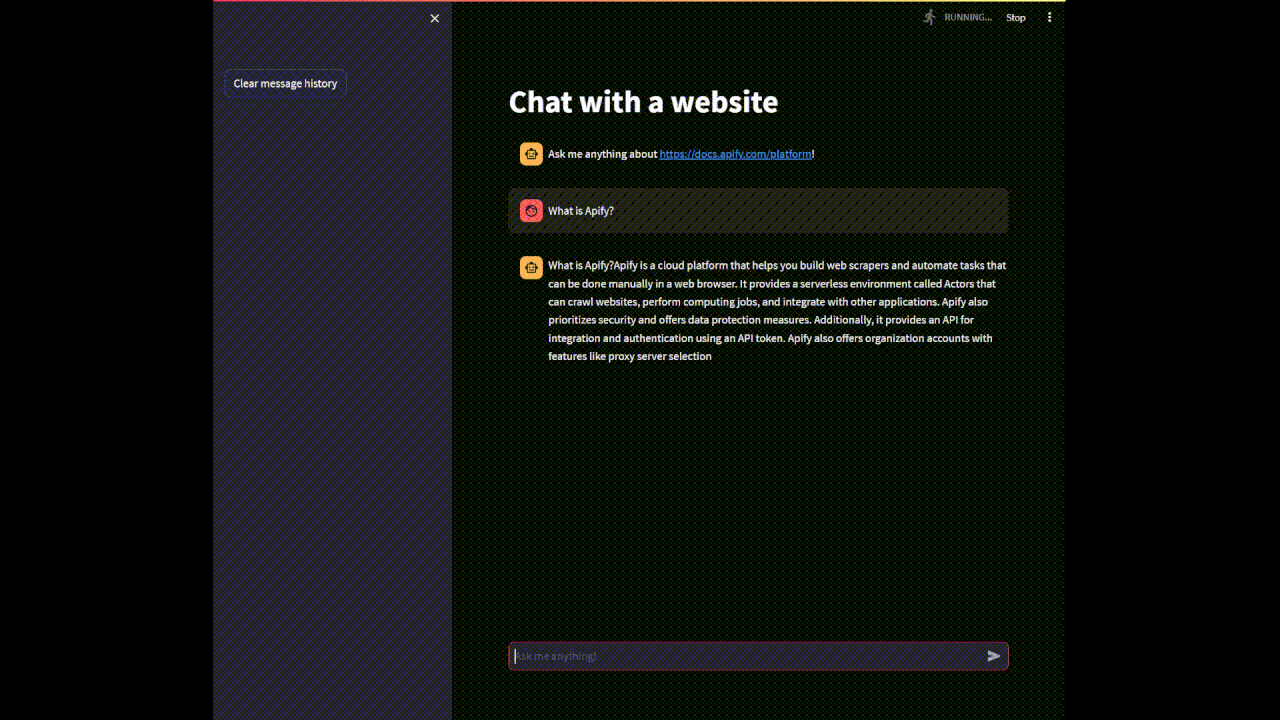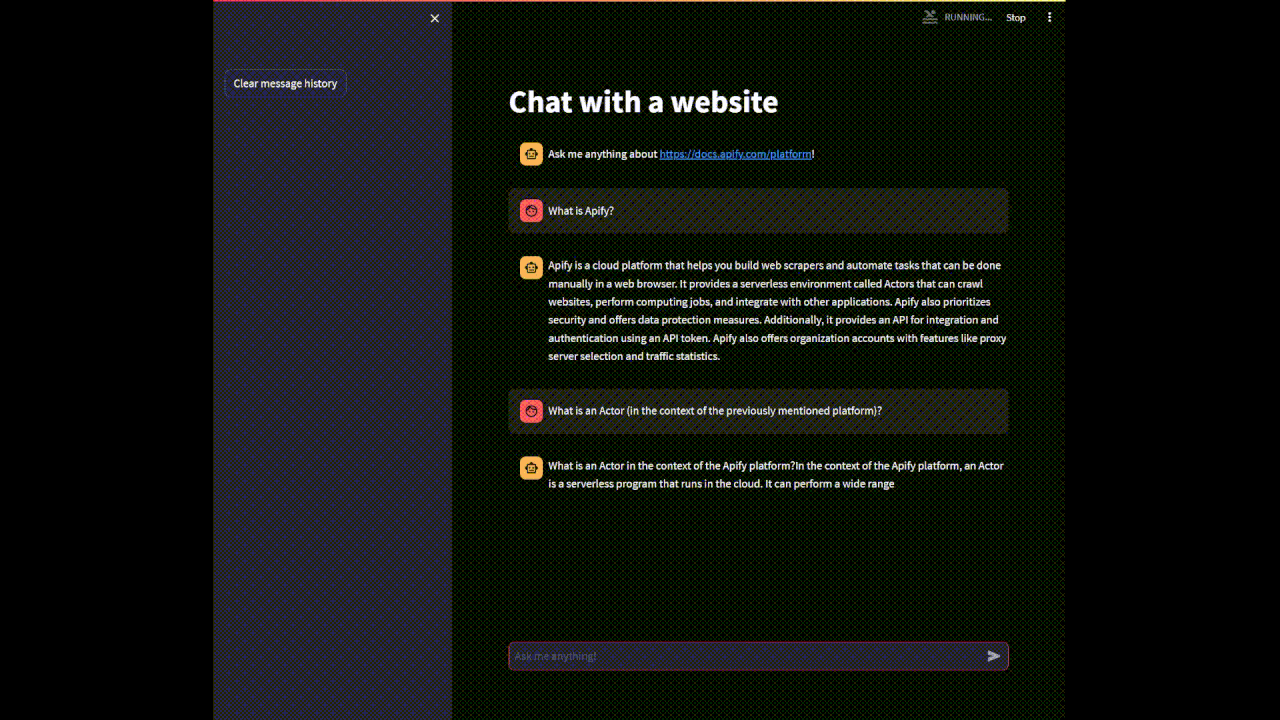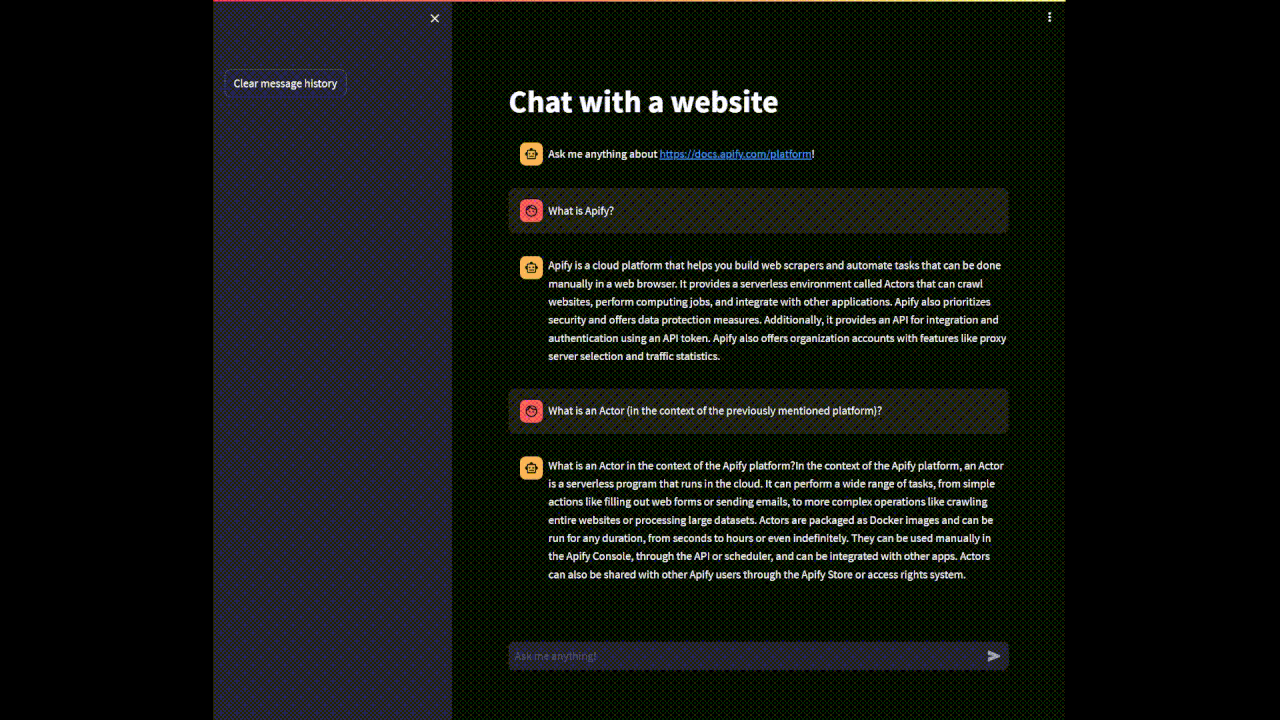
if user_query := st.chat_input(placeholder='Ask me anything!'):
st.chat_message('user').write(user_query)
with st.chat_message('assistant'):
stream_handler = StreamHandler(st.empty())
response = qa_chain.run(user_query, callbacks=[stream_handler])
Connecting everything together
If you’ve followed along with this tutorial, then by now, you should have three files: .env, [scrape.py](<http://scrape.py>) and chat.py. Let’s take what we’ve created and use it to chat with a website!
First, run python scrape.py to extract the relevant data from the target website. Note that this step may take a while since the website might be pretty big. You can check the progress at https://console.apify.com/actors/runs.
After the data extraction is done, you can start chatting with the website by running streamlit run chat.py!