Why everyone in AI is talking about MCP
Over the past year, Model Context Protocol (MCP) has gone from a curiosity on GitHub to the de facto way serious teams wire LLM agents into real-world data and tools. At the 2025 MCP Developers Summit in San Francisco, speakers from Anthropic, OpenAI, Bloomberg, GitHub, AWS, PayPal, Elastic, and others all echoed the same refrain:
We're shifting away from early experimentation and simple tool calling to building trustworthy, scalable and modular AI systems using MCP as the foundation.
That claim matters because integration, not model quality, is now the bottleneck. Organizations already have valuable data in GitHub, Snowflake, Elasticsearch, or Salesforce; what they lack is a safe, repeatable way for an agent to see, search, and act on that data. MCP’s answer is a single, open, bidirectional interface - much like USB-C replaced drawers full of proprietary cables.
What exactly is MCP (Model Context Protocol)?
Model Context Protocol (MCP) is an open standard designed by Anthropic to bridge the gap between AI assistants and external data sources and make AI applications more relevant and context-aware.
Traditionally, AI models have struggled with integrating external data efficiently. The result has been fragmented implementations for each new data source.
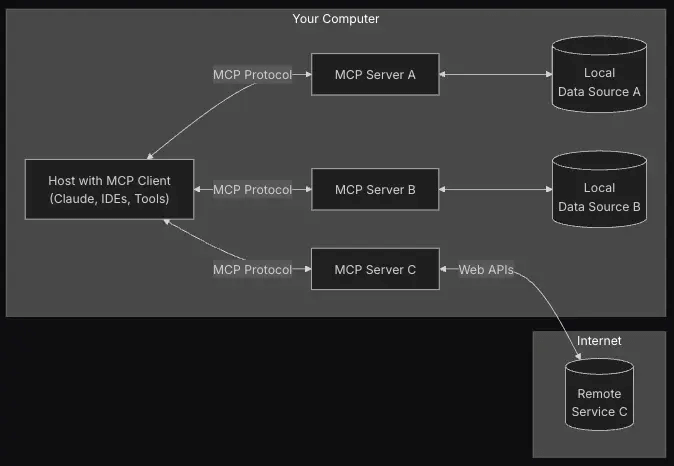
MCP addresses this problem by providing a standardized framework for secure and scalable connections between AI tools and various systems. It supports secure two-way connections through MCP servers and clients:
- MCP servers expose data from external sources such as Google Drive, Slack, GitHub, Postgres, and Puppeteer.
- MCP clients (AI applications) connect to these servers to access structured information and enhance responses with relevant context.
Because the protocol is model-agnostic and server-agnostic, any Claude, GPT, Llama, or Mistral-based agent can talk to any compliant server. The result: the first real chance at plug-and-play interoperability across the AI stack.
A short history - and why MCP rose above competing specs
- The pain point. Early agent builders hard-coded REST calls for each data source, then rewrote everything when they switched clouds - or worse, when security asked for audit trails.
- The breakthrough. Anthropic’s early MCP prototype (late 2023) added typed messages and a lightweight stream transport so agents could pull just the context they needed.
- Network effects. By mid-2025, the spec had thousands of GitHub stars, dozens of SDKs, and backing from enterprise vendors who saw it as a neutral standard (unlike vendor-locked “agent frameworks”).
Competing proposals fall into two buckets:
- Inter-agent protocols (Google A2A, Cisco/IBM ACP, Agora) focus on agents negotiating with each other.
- Context-oriented protocols (MCP, to some extent LangGraph) focus on agents acquiring structured context - a more immediate production need.
MCP’s decision to “own context first, coordination later” gave it a pragmatic edge and the community momentum that React enjoyed over more academically pure rivals.
How MCP works today
MCP’s appeal is that it feels simple for the agent creator, yet hides a surprising amount of protocol engineering under the hood. Below is a plain-language tour of four features that were demoed at the San Francisco MCP Developers Summit, and why they matter when you move from “hello world” to production.
1. Streamable HTTP
Early MCP servers spoke over Server-Sent Events (SSE). That was fine on a laptop, but in production, SSE created headaches:
- Enterprise firewalls often block or time out long-lived SSE connections.
- Cloud functions such as AWS Lambda can’t keep an open socket alive for minutes.
- Back-pressure was clunky: you either waited for the whole tool result or you polled.
The Streamable HTTP upgrade (released March 26, 2025) fixes all three issues by tunnelling a bidirectional byte-stream through a single, ordinary HTTP request that supports chunked transfer encoding. In practice, it means:
- You can deploy an MCP server as a stateless Lambda/Fargate task; it spins up, emits streamed chunks, then shuts down.
- Corporate proxies treat it as just another HTTPS call, so network teams stop saying “no”.
- Agents start receiving partial results - say, the first 100 database rows - while the rest of the tool call is still running, which cuts perceived latency and lets the LLM answer sooner.
If you build on serverless or behind locked-down enterprise networks, this one feature may cut weeks from your rollout schedule.
2. Typed schemas
- Elicitation schema
- A server can describe - in JSON - exactly what information it needs from the client (e.g.
{ "query": "string", "date_range": "YYYY-MM-DD…" }). Your UI can auto-render the right form controls. Your agent no longer has to guess the prompt that will satisfy the server, reducing error-handling glue code.
- A server can describe - in JSON - exactly what information it needs from the client (e.g.
- Tool output schema
- A server declares the JSON shape it will return. Instead of pasting raw unstructured text into the LLM’s context window (token-hungry and brittle), the client can inject a concise, structured object - often 10–20× smaller. That leaves more budget for the actual reasoning tokens.
3. Sampling and Roots
Sampling and Roots are two primitives that are currently overlooked and underexplored. The keynote speech at the summit highlighted these. They're not new, but they can improve the security between agent interactions.
- Sampling
- Think of sampling as the server’s right to call back into your LLM for a small completion. It’s handy when the server wants, say, a short summary in the style the user already sees. Centralizing those completions in the client keeps API keys and model choice under your control.
- Roots
- Before an agent starts browsing your Git repository, you can hand the server a roots object like
["/repos/acme-payments", "/repos/acme-docs"]. It’s an advisory scope marker - not a hard permission check - but servers that respect roots avoid needless crawling and keep responses focused. Pair it with normal ACLs (Access Control Lists) for real enforcement.
- Before an agent starts browsing your Git repository, you can hand the server a roots object like
Together, these primitives facilitate richer, cooperative workflows without inventing extra protocol layers.
4. OAuth 2.1
Traditional OAuth flows assume the server redirects a human user to an auth page - a poor fit when the “user” is now an autonomous agent. Okta’s Aaron Parecki proposed (and the community adopted) an agent-first OAuth 2.1 pattern:
- The MCP client initiates the flow, directs the human user (or a service account) to sign in via SSO, and receives the access token.
- The MCP server only verifies the token and reads a tiny
server.jsonthat lists scopes and endpoints.
- Why it matters
- For enterprise IT: You preserve existing SSO, MFA, and audit logs; nothing new to approve.
- For server authors: You skip building an OAuth UI, reduce your liability surface, and still accept any standards-compliant identity provider out of the box.
Put differently, OAuth 2.1 “done right” lets you keep security teams happy and ship features faster - a rare win-win in compliance-heavy environments.
Bottom line for agent builders
- Streamable HTTP gets your packets through corporate walls
- Typed schemas shrink token usage and UI glue code
- Sampling and Roots add power when you need it
- The revamped OAuth flow turns a traditional security blocker into a check-box exercise.
When you combine these four concepts, you’ll have crossed 80 percent of the gap between a weekend MCP demo and a production-ready, enterprise-approved deployment.
How to experiment with MCP right now
- Try a turnkey client. Claude Desktop bundles a local MCP server; LibreChat and LangGraph have first-class clients.
- Create your own server. Official SDKs exist in Python, TypeScript, and Go. Deploy with Streamable HTTP on Fly.io, Lambda, or a bare VM.
- Try Apify's MCP Server.
- Apify has built an MCP server that allows AI agents or frameworks that implement Model Context Protocol to access 5,000+ Apify Actors (microapps for web automation) as tools for data extraction, web searching, and other tasks.
- This implementation lets agents collect data from websites (e.g. Facebook posts, Google search results pages, URLs), summarize web trends, and execute automated workflows without requiring user intervention.
- The Actors MCP Server offers a bidirectional streaming endpoint at
https://mcp.apify.com, a legacy SSE endpoint athttps://mcp.apify.com/sse, and local stdin/stdout connections started withnpx -y @apify/actors-mcp-server. - Users can interact with the server through clients like Claude Desktop, LibreChat, the VS Code MCP extension, and Apify's Tester MCP Client.
- For more details, check out the docs.
Learn how to set up Apify MCP Server on Claude, add Actors, and get data in any format you want in this video
Why Model Context Protocol is worth the hype
MCP is still evolving, but its trajectory is clear. Just as HTTP unified the early web, Model Context Protocol is rapidly becoming the connective tissue of agentic AI. Getting familiar with it today is the surest way to future-proof your stack for whatever models and business demands arrive next.
Read more about MCP and AI agents
- How to use MCP with Apify Actors - Learn how to expose over 5,000 Apify Actors to AI agents like Claude and LangGraph, and configure MCP clients and servers.
- How to build an AI agent - A complete step-by-step guide to creating, publishing, and monetizing AI agents on the Apify platform.
- What are AI agents? - The Apify platform is turning the potential of AI agents into practical solutions.
- LLM agents: all you need to know in 2025 - LLM agents are changing how we approach AI by enabling interaction with external sources and reasoning through complex tasks.
- 10 best AI agent frameworks - 5 paid platforms and 5 open-source options for building AI agents.
- Best low-code and no-code AI agent builders in 2025 - If frameworks like LangGraph or Haystack are too challenging for you, these AI agent builders might be what you're looking for.
- AI agent workflow - building an agent to query Apify datasets - Learn how to extract insights from datasets using simple natural language queries without deep SQL knowledge or external data exports.
- AI agent vs. chatbot - We break down the differences between agents and chatbots to help you decide which one to use for your business goals.
- AI agent orchestration with OpenAI Agents SDK - Learn to build an effective multiagent system with AI agent orchestration.
- 5 open-source AI agents on Apify that save you time - These AI agents are practical tools you can test and use today, or build on if you're creating your own automation.
- 6 AI agent tools that keep your agents grounded in current data - Apify Actors give agentic systems the ability to query the live web at production scale. Here are 6 you should try.
- AI agent architecture in 1,000 words - A comprehensive overview of AI agents' core components and architectural types.
- 11 AI agent use cases (on Apify) - 10 practical applications for AI agents, plus one meta-use case that hints at the future of agentic systems.
- 7 real-world AI agent examples in 2025 you need to know - From goal-based assistants to learning-driven systems, these agents are powering everything from self-driving cars to advanced web automation.
- 7 types of AI agents you should know about - What defines an AI agent? We go through the agent spectrum, from simple reflexive systems to adaptive multi-agent networks.