


We’re Apify, and our mission is to make the web more programmable. Part of that, is getting data for AI. Check us out 👈
OpenAI’s ChatGPT has rapidly evolved into a very powerful and versatile tool. People have been using it to generate text, answer questions, translate languages, and much more.
Trained on data up to September 2021, a big ChatGPT limitation is its inability to answer questions based on more recent information. So, how can we use OpenAI to create a system that can answer questions from current data?

Several tools, including LangChain, Pinecone, and Apify, offer the ability to extend and enhance the capabilities of OpenAI's AI models.
- LangChain: a framework designed for the development of applications that leverage language models. It allows us to integrate large language models like OpenAI and Hugging Face with different applications.
- Pinecone: an external tool that allows us to save the embeddings online and extract them whenever we need.
- Apify: a web scraping and automation platform that significantly streamlines the process of data collection. It provides the capability to scrape data and subsequently feed it to LLMs. This allows us to train LLMs on real-time data and develop applications.
In this tutorial, we will extract data using one of Apify’s many pre-built web scraping tools, the Airbnb Scraper. We'll scrape Airbnb data from New York City and feed it to the LLM to make a system that will answer questions from that data.
How to set up LangChain and Apify
To start setting up LangChain and Apify, you'll need to create a new directory and a Python file. You can do this by opening your terminal or command line and entering the following commands:
mkdir LangChain
cd LangChain
touch main.ipynb
Let's install the packages. Copy the command below, paste it into your terminal, and press Enter. These packages will provide the tools and libraries we need to develop our AI web scraping application.
pip3 install langchain==0.0.189 pinecone-client openai tiktoken nest_asyncio apify-client chromadb
This should install all the dependencies in your system. To confirm that everything is installed properly, you can enter the following command in your terminal.
pip freeze | egrep '(langchain|pinecone-client|openai|tiktoken|nest_asyncio|apify-client|chromadb)'
This should include all the installed dependencies with their versions. If you spot any missing dependencies, you may need to re-run the installation command for that specific package.
Now, we're ready to write our code once we're done with the installation.
 Theo Vasilis
Theo Vasilis
Set up the environment variables
First, we must provide the API keys for OpenAI and Apify to set up the environment variables. You need to replace the empty quotes with your own API keys.
import os
# Add your OPENAI API key below
os.environ["OPENAI_API_KEY"] = ""
# Add your APIFY API key below
os.environ["APIFY_API_TOKEN"] = ""
How to use Airbnb Scraper to extract data
Now, we will use the Apify API to scrape data from Airbnb listings and then save that data into a structured format (as Document objects). ApifyWrapper from langchain.utilities allows us to interact with Apify, Document from langchain.document_loaders.base is used to structure the scraped data, and json is a standard Python library for working with JSON data.
from langchain.utilities import ApifyWrapper
from langchain.document_loaders.base import Document
import json
Next, we'll create an instance of ApifyWrapper. This object will provide us with methods for interacting with the Apify API and help us to scrape data from Airbnb listings.
apify = ApifyWrapper()
Now, we need to scrape data through Airbnb Scraper. There are two ways to use this scraper:
1. Apify Console: You can go to Apify Console and open Airbnb Scraper. From there, you can choose the data you want to select according to your needs. If you have no preferences, you can just enter the city and press Start.
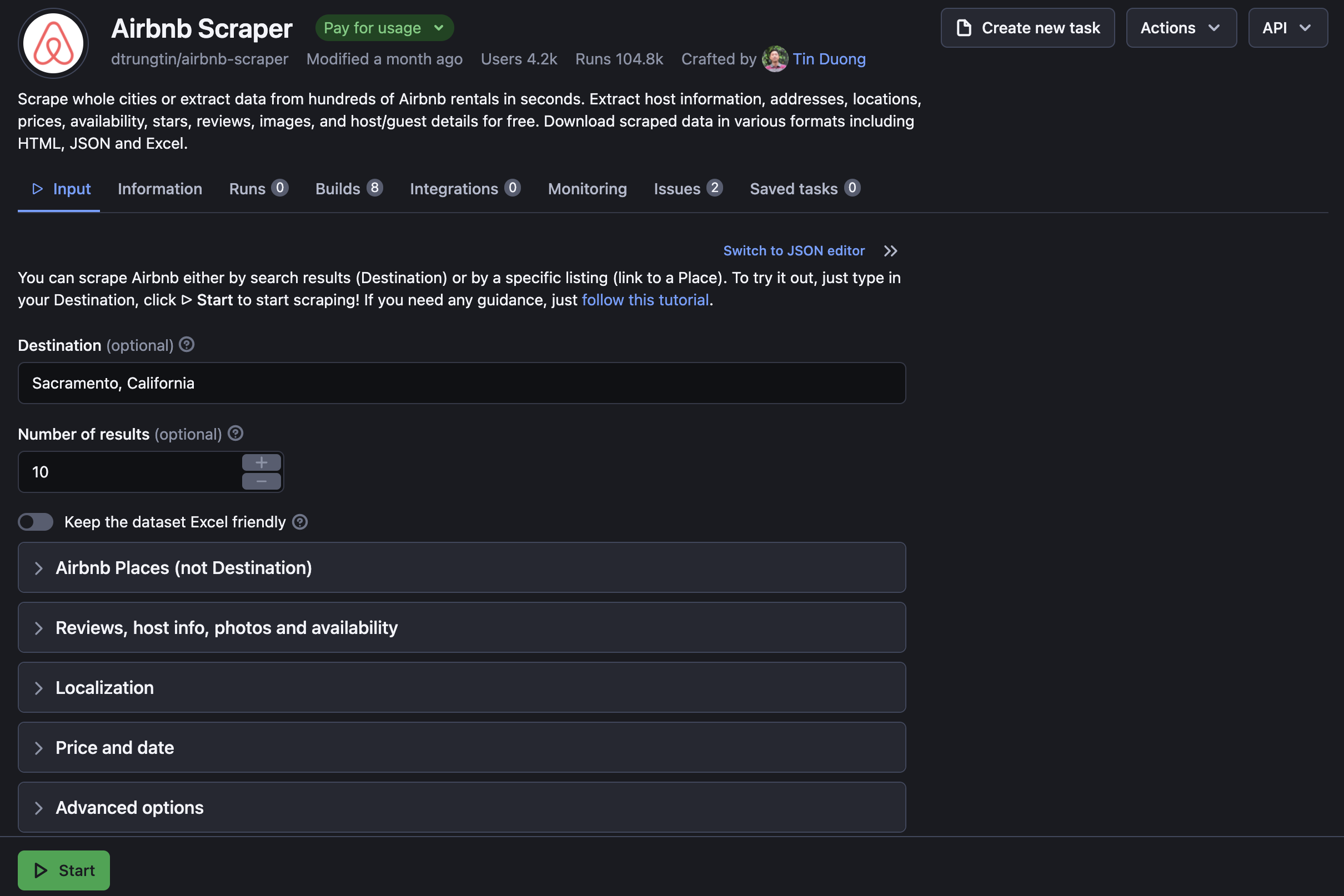
2. Apify API: We can use the Apify API to extract data. We will use this method in this tutorial. You can read more about the Airbnb Scraper API on the README and change the data you want to extract.
Next, we run the Actor, which is basically our Airbnb scraper, and wait for it to finish the execution. It will fetch the results in a LangChain document loader.
loader = []
loader = apify.call_actor(
actor_id = "dtrungtin/airbnb-scraper",
run_input = {
"currency": "USD",
"maxListings":500,
"locationQuery": "New York, ",
"proxyConfiguration": {"useApifyProxy": True},
"maxConcurrency": 50,
"limitPoints": 100,
"timeoutMs": 300000,
},
dataset_mapping_function = lambda item: Document(
page_content = json.dumps({
'name': item['name'],
'room_type': item['roomType'],
'city': item['city'],
'stars': item['stars'],
'address': item['address'],
'number_of_guests': item['numberOfGuests'],
'pricing': {
'rate': "$"+ str(item['pricing']['rate']['amount']),
'currency': item['pricing']['rate']['currency'],
},
'url': item['url'],
'host': {
'first_name': item['primaryHost']['firstName'],
'is_superhost': item['primaryHost']['isSuperHost'],
'about': item['primaryHost']['about'],
'member_since': item['primaryHost']['memberSince'],
'languages': item['primaryHost']['languages'],
'badges': item['primaryHost']['badges']
},
'reviews': [
{
'author': {
'first_name': review['author']['firstName'],
},
'comments': review['comments'],
'created_at': review['createdAt'],
'rating': review['rating'],
'localized_date': review['localizedDate']
}
for review in item['reviews']
]
}),
metadata = {"source": item["url"]}
)
)
While the Actor is running, especially if it's scraping a large dataset, you can monitor its progress by going to Apify Console.
Once the execution is completed, all the data will also be saved on the Apify platform. You can learn to load the extracted data in this notebook, but we will not load data from Apify in this tutorial. In that notebook, you'll also find an explanation of the dataset_mapping_function, which is used to map fields from the Apify dataset records to LangChain Document fields.
Theo Vasilis
Learn more about how generative AI works and what it means for developers
Load and process data with LangChain and Pinecone
Next, let's explore how to use LangChain for loading and processing the data we've scraped, and look at how Pinecone contributes to this process.
Get the data from the document
Now, load the data from the page_content property of the Document object. This property contains the JSON representation of the Airbnb listing. The load() method will parse the JSON string and create a dictionary that represents the Airbnb listing.
loader = loader.load()
Split the data into chunks
Due to memory limitations and computational efficiency, language models, including those used by LangChain, can only process a certain amount of text at a time. By splitting the data into smaller chunks, we can feed these chunks into the language model one at a time, which can help to improve the performance of the LLM.
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size = 1200,
chunk_overlap = 200
)
docs_chunks = text_splitter.split_documents(loader)
print(docs_chunks)
After executing this code, we will see documents with a chunk size of 1200 characters, and an overlap of 200 to maintain the semantics.
Theo Vasilis
Learn how to split data into chunks with PDF Text Extractor and do QA from PDF files with LangChain
Create and save the embeddings to Pinecone
Initialize Pinecone by providing values to the api_key and environment arguments.
import pinecone
pinecone.init(
api_key = "",
environment = ""
)
Once Pinecone has been initialized, we can set up an index, which is like a database for storing and querying our embeddings. We provide a name for our index and specify the type of embeddings we're using.
from langchain.vectorstores import Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
index_name = "index_name"
embeddings = OpenAIEmbeddings()
#create a new index
docsearch = Pinecone.from_documents(docs_chunks, embeddings, index_name=index_name)
A new index with the name index_name will be created, and all the embeddings will be stored. There are other types of embeddings, but we will use OpenAIEmbeddings().
Theo Vasilis
Load the embeddings
Next, we'll load the Pinecone index we created in the previous step. This means we're preparing to access and use the stored embeddings.
testingIndex = Pinecone.from_existing_index(index_name, embeddings)
Use similarity search
Now, we have embeddings, and LangChain allows us to make a similarity search against our query. A similarity search works by calculating the distance between the embeddings of our query and the embeddings of each item in our dataset. It then returns the items with the "nearest" (most similar) embeddings.
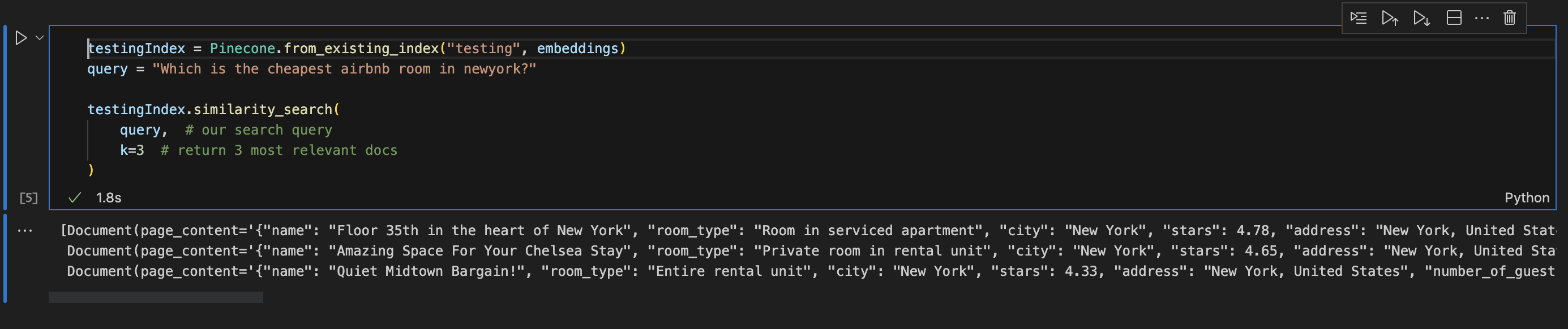
query = "Which is the cheapest airbnb room in newyork?"
testingIndex.similarity_search(
query, # our search query
k=3 # return 3 most relevant docs
)
It creates the embeddings and applies similarity search for the nearest distance embeddings. It then returns the top 3 results like this:
Create a Q/A using OpenAI and LangChain
Let's start creating a Q/A system by importing the OpenAI library and creating an instance of the ChatOpenAI class.
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(
temperature = 0.0
)
The temperature parameter controls the randomness of the output. The temperature parameter controls the randomness of the output. A lower temperature value (like 0.0) makes the model's output more deterministic, meaning it will generate the next word that is most statistically likely given the previous words.
Next, we need to define a chain that will receive input and give us output as an answer.
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(
llm = llm,
chain_type="refine",
retriever=vectorstore.as_retriever()
)
There are different types of chains provided by LangChain for specific domains, but we will use the refine chain because it loops over each document and updates the answer according to the query.
Let's make a query.
qa.run(query)
It will produce an output like this.
'The cheapest Airbnb room in New York is "Quiet Midtown Bargain!" with a rate of $140 per night. You can find more information about it here.'
The price may appear somewhat high, but this is because we have only scraped 500 listings, and it's the least expensive option among them all.
Theo Vasilis
Make a more robust system with LangChain Agents
In LangChain, agents are components that have access to tools provided by us, and they can use them depending on their need. Let's add an agent to our system to make it more effective and robust.
from langchain.agents import Tool
from langchain.agents import initialize_agent
tools = [
Tool(
name = 'Knowledge Base',
func = qa.run,
description = (
'use this tool to answer questions'
'more information about the topic'
)
)
]
agent = initialize_agent(
tools=tools,
llm=llm,
verbose=True,
)
query="Which is the cheapest airbnb room in newyork?"
agent(query)
We are defining a tool in the above code and giving that tool to the agent. We have set the parameter verbose to True. By doing so, we can see the whole thinking process of the agent like this:
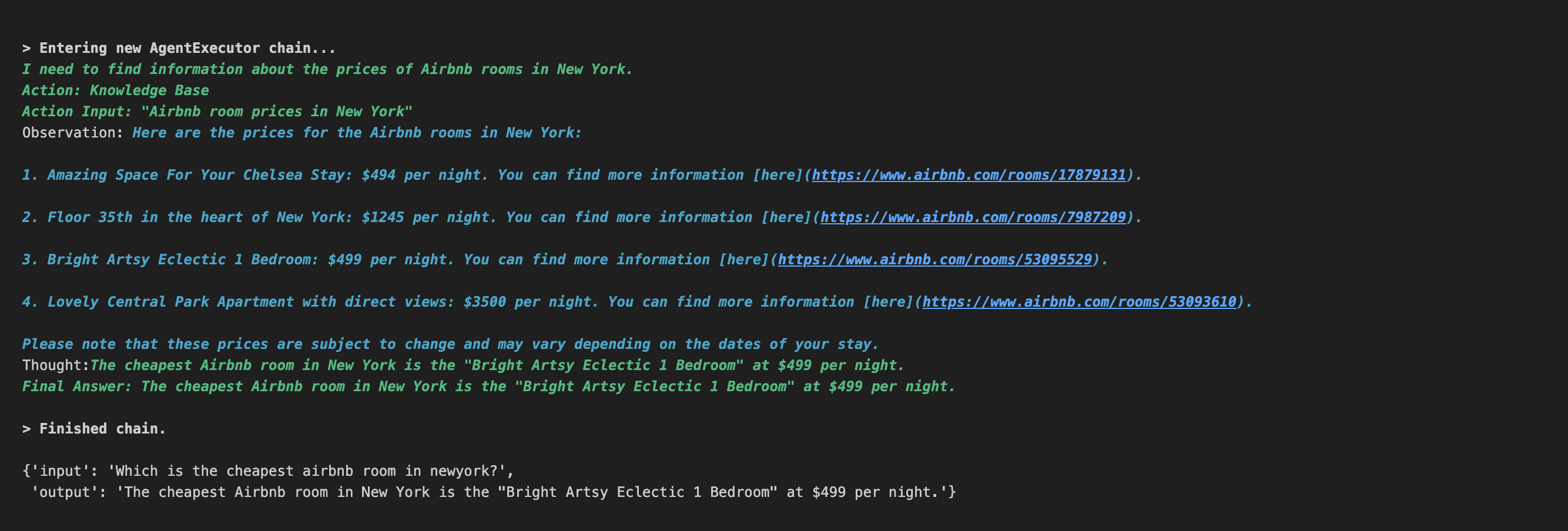
If it's set to False, it will just return the input with output.
Add memory to the agent
By default, all the conversations in the agents and chains are volatile; they don't remember anything. But we can add memory to save the previous conversations. Let's do that.
from langchain.chains.conversation.memory import ConversationBufferWindowMemory
conversational_memory = ConversationBufferWindowMemory(
memory_key='chat_history',
k = 5,
return_messages = True
)
Let's update our agent and add memory to it.
newAgent = initialize_agent(
agent = 'chat-conversational-react-description',
tools = tools,
llm = llm,
verbose = True,
max_iterations = 3,
early_stopping_method = 'generate',
memory = conversational_memory
)
query = "My name is Apify"
newAgent(query)
After adding ConversationBufferWindowMemory to the agent, it'll remember the last five questions that we asked. That's because we have set the limit k=5 . Now let's ask another question.
query = "What is my name?"
newAgent(query)
It will return a result like this:
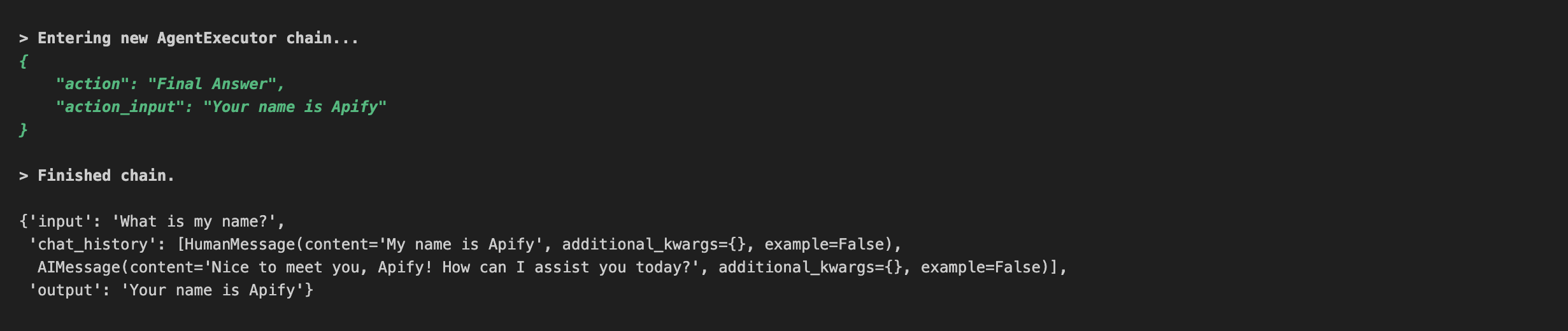
In the image above, we can see that it remembers the history and answers the questions related to that as well.
A few of the sample queries and their answers are attached below.
First, I asked the agent to show me the room with the best reviews:
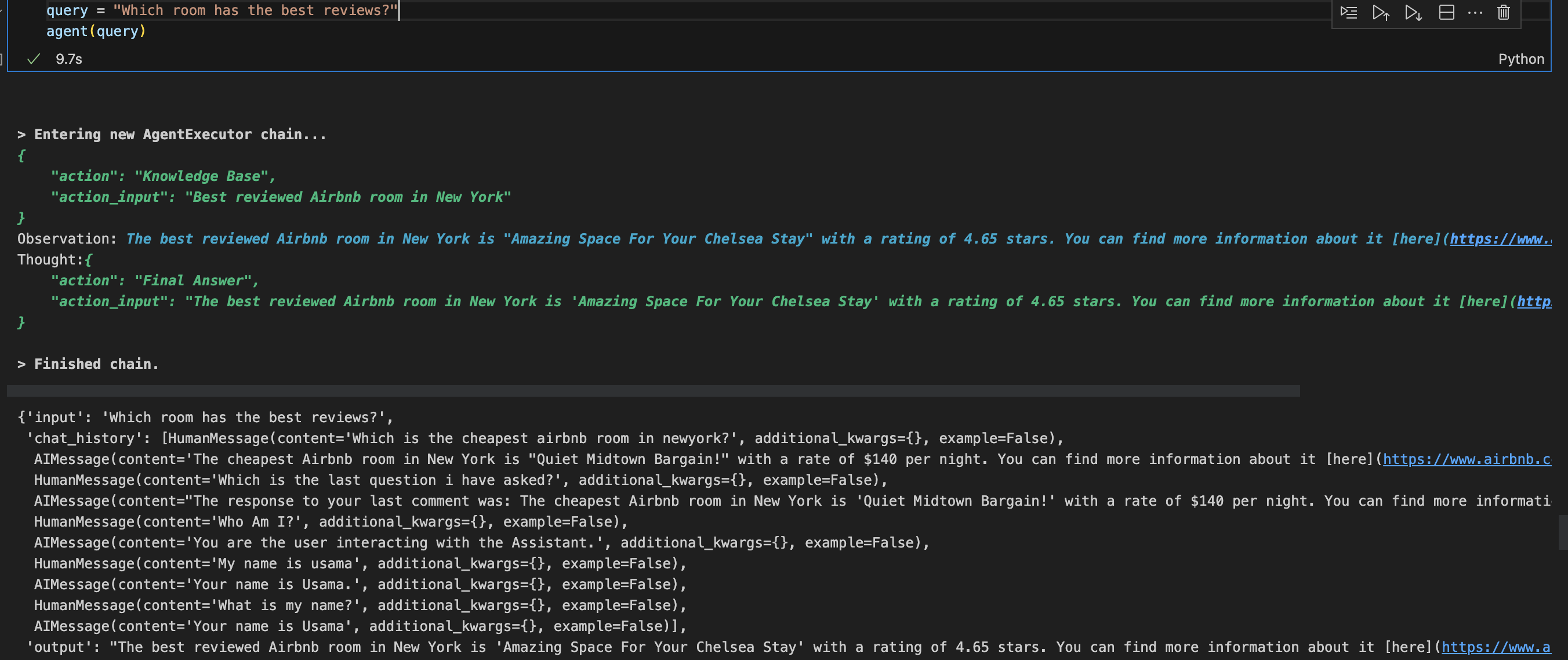
Then I asked the agent to give me the name of the owner:
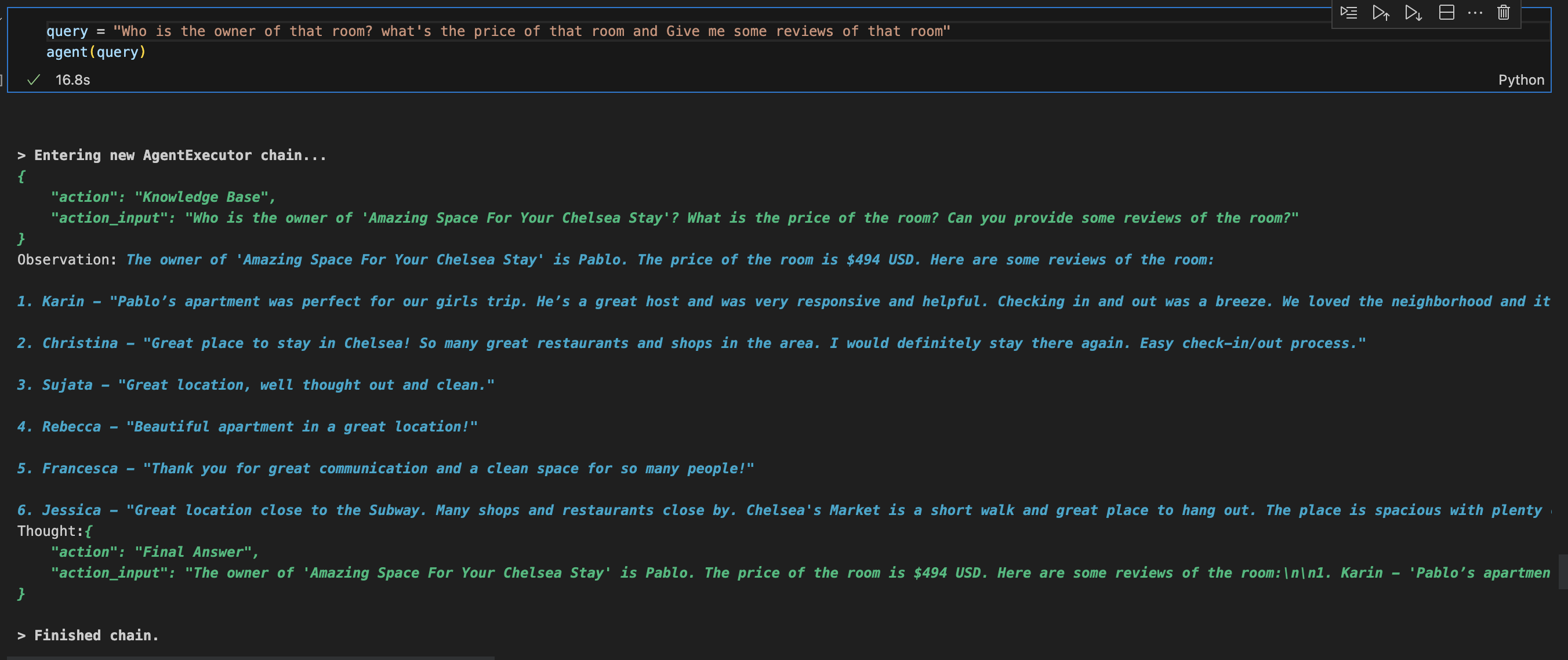
And that's how you can ask a dataset any question you like using LLMs when combined with LangChain and Pinecone!
Theo Vasilis
Doing more with OpenAI, LangChain, and Apify
This simple application of LangChain and Apify barely scratches the surface of what you can achieve by combining these tools. You can do a lot more by choosing any Apify Actor, integrating with OpenAI through LangChain, and developing any application you need.
If you want to see what other GPT and AI-enhanced tools you can integrate with LangChain, just check out Apify Store.
Jiří Moravčík
How to create an AI chatbot with LangChain, Streamlit, and Apify




