


For years, Python has dominated the web scraping scene. But if you’re a JavaScript developer or simply prefer working with JavaScript, you’ll be glad to know that the Node.js scraping ecosystem has been growing steadily. In fact, by 2025, Node.js is just as strong a choice for web scraping as Python.
In this guide, we’ll go over the best libraries for web scraping with Node.js in 2025 and show you, step by step, how to use them to scrape real websites.
Why use Node.js and JavaScript for web scraping?
Node.js is an excellent choice for web scraping because of its event-driven architecture and how well it handles asynchronous tasks. This really comes in handy for large-scale scraping projects, where you often need to manage multiple requests efficiently.
Plus, Node.js has a solid ecosystem of open-source libraries like Cheerio, Playwright, and Crawlee, which make it easier to parse HTML, interact with web pages, and deal with dynamic content.
Step 1: Get data with an HTTP client
HTTP clients are end-point applications that use the HTTP protocol to send requests and get a response from servers. In the context of web scraping, they’re necessary to send requests to your target website and retrieve information such as the website’s HTML markup or JSON payload.
While there are plenty of HTTP clients available, including Node.js’s native fetch, we believe Got Scraping is your best choice for web scraping. But why?
Got Scraping is an HTTP client tailor-made for web scraping. It’s primary purpose is to address common challenges in web scraping by offering built-in features to make bot requests less detectable and reduce the chances of getting blocked by modern anti-scraping measures.
This is important because getting blocked is one of the most frustrating things that can happen when scraping. So, it’s worth using any tools that help lower the chances of that happening.
1. Installation
npm install got-scraping2. Code sample
Here’s an example of how to send a request to a website and retrieve its HTML using Got Scraping. After running the code below, you should see the HTML of the YCombinator’s Hacker News website logged to your console.
import { gotScraping } from 'got-scraping';
async function main() {
const response = await gotScraping.get('https://news.ycombinator.com/');
const html = response.body;
console.log(html);
}
main();3. Using the header-generator package
Got-scraping also comes bundled with the header-generator package, which enables us to choose from various browsers from different operating systems and devices.
It generates all the headers automatically, which can be handy when trying to scrape websites that employ aggressive anti-bot blocking systems. To work around this potential setback, we often need to make the bot requests look "browser-like" and reduce the chances of them getting blocked.
To demonstrate that, let's take a look at an example of a request using the HeaderGenerationOptions:
import { gotScraping } from 'got-scraping';
async function main() {
const response = await gotScraping({
url: 'https://api.apify.com/v2/browser-info',
headerGeneratorOptions: {
browsers: [{ name: 'firefox', minVersion: 80 }],
devices: ['desktop'],
locales: ['en-US', 'en'],
operatingSystems: ['linux'],
},
});
console.log(response.body);
}
main();Here's the result you can expect to be generated for the example above and logged to the console:
"headers": {
"user-agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:107.0) Gecko/20100101 Firefox/107.0",
"accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"accept-language": "en-US,en;q=0.9",
"accept-encoding": "gzip, deflate, br",
"upgrade-insecure-requests": "1",
"sec-fetch-site": "same-site",
"sec-fetch-mode": "navigate",
"sec-fetch-user": "?1",
"sec-fetch-dest": "document"
}Step 2: Parse HTML and XML data
In the previous step, we retrieved Hacker New’s HTML page content. But raw HTML on its own isn’t very useful, we need to turn that messy data into something more readable and understandable. In other words, we need to parse it.
For this, we’ll use a library called Cheerio, which is the most popular and widely used HTML and XML parser in the Node.js ecosystem.
What is Cheerio?
Cheerio is an implementation of core jQuery designed to run on the server. Because of its incredible efficiency and familiar syntax, Cheerio is often our go-to library for scraping pages that don't require JavaScript to load their contents.
1. Installation
npm install cheerio2. Code sample
Let's now see how we can use Cheerio + Got Scraping to extract the text content from all the articles on the first page of Hacker News.
import { gotScraping } from 'got-scraping';
import * as cheerio from 'cheerio';
async function main() {
const response = await gotScraping('https://news.ycombinator.com/');
const html = response.body;
// Use Cheerio to parse the HTML
const $ = cheerio.load(html);
// Select all the elements with the class name "athing"
const articles = $('.athing');
// Loop through the selected elements
for (const article of articles) {
const articleTitleText = $(article).text();
// Log each element's text to the terminal
console.log(articleTitleText);
}
}
main();A few seconds after running the script, you'll see the title and ranking from the 30 most recent articles on HackerNews logged to your terminal.
Output example:
1. US Department of Energy: Fusion Ignition Achieved (energy.gov)
2. Reddit's photo albums broke due to Integer overflow of Signed Int32 (reddit.com)
3. About the security content of iOS 16.2 and iPadOS 16.2 (support.apple.com)
4. Balloon framing is worse-is-better (2021) (constructionphysics.substack.com)
5. After 20 years the Dwarf Fortress devs have to get used to being millionaires (pcgamer.com)
...
25. How much decentralisation is too much? (shkspr.mobi)
26. What we can learn from vintage computing (github.com/readme)
27. Data2vec 2.0: Highly efficient self-supervised learning for vision, speech, text (facebook.com)
28. Pony Programming Language (github.com/ponylang)
29. Al Seckel on Richard Feynman (2001) (fotuva.org)
30. Hydra – the fastest Postgres for analytics [benchmarks] (hydras.io)
Step 3: Scrape dynamic websites
So far, we’ve used an HTTP client and an HTML parser to extract data from a static website. However, these tools aren’t enough for scraping dynamic websites.
To handle dynamic content, we need browser automation libraries like Playwright. It emulates a real browser, rendering JavaScript and loading content that standard HTTP requests and Cheerio can’t access. This makes it ideal for scraping pages with dynamically generated data.
1. Installation
# Run from your project's root directory
npm init playwright@latest2. Code sample
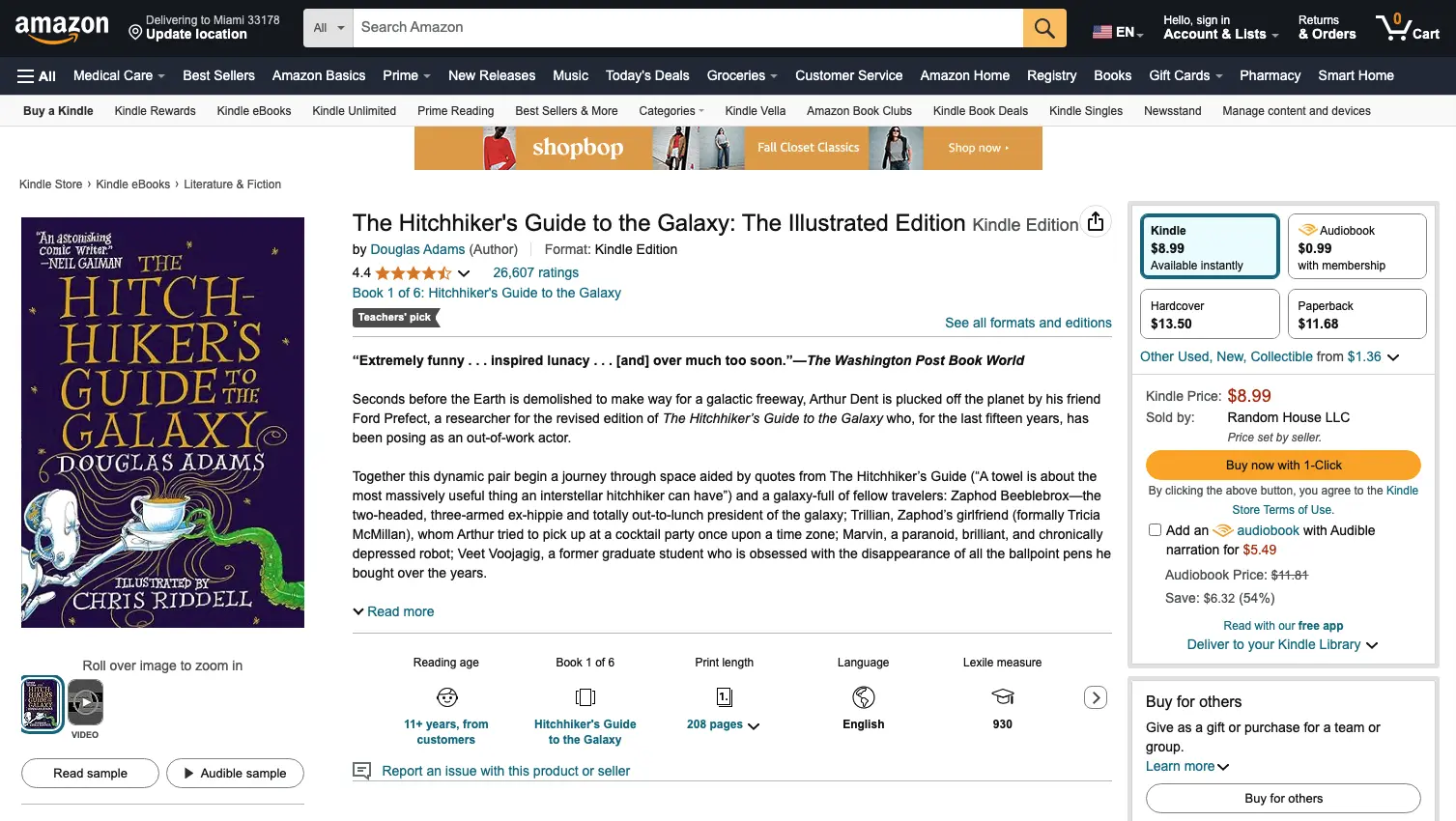
Here's an example of using Playwright to extract some data from the Amazon page for Douglas Adams' The Hitchhiker's Guide to the Galaxy:
import { firefox } from 'playwright';
async function main() {
const browser = await firefox.launch({
headless: false, // Set headless to false, so we can see the browser working
});
const page = await browser.newPage();
await page.goto(
'https://www.amazon.com/Hitchhikers-Guide-Galaxy-Douglas-Adams-ebook/dp/B000XUBC2C/ref=tmm_kin_swatch_0?_encoding=UTF8&qid=1642536225&sr=8-1'
);
const book = {
bookTitle: await page.locator('#productTitle').innerText(),
author: await page.locator('span.author a').innerText(),
kindlebackPrice: await page
.locator('#formats span.ebook-price-value')
.innerText(),
paperbackPrice: await page
.locator('#tmm-grid-swatch-PAPERBACK .slot-price span')
.innerText(),
hardcoverPrice: await page
.locator('#tmm-grid-swatch-HARDCOVER .slot-price span')
.innerText(),
};
console.log(book);
await browser.close();
}
main();
After the scraper finishes its run, the browser controlled by Playwright will close, and the extracted data will be logged into the console.
Step 4: Dynamic scraping using Playwright with Cheerio
As we saw earlier, the main reason we need a browser automation library for web scraping is to access dynamically generated content on pages that require JavaScript.
But learning yet another library’s syntax can feel like a chore. Wouldn’t it be great if we could leverage Puppeteer and Playwright’s power while still using Cheerio’s familiar jQuery-style syntax to extract data? That’s exactly what we’ll do in this section.
We’ll start by accessing the target website using Playwright, grabbing the page’s HTML, and feeding it into Cheerio’s load() function to parse the content.
For this example, we’ll scrape the product page from https://www.mintmobile.com/devices/samsung-galaxy-a14/4666704/. Since Mint Mobile relies on JavaScript to load most of the page’s content, it’s a perfect case for using Playwright in web scraping.
Mint Mobile product page with JavaScript disabled:
Mint Mobile product page with JavaScript enabled:
1. Installation
npm install playwright cheerio2. Code sample
Here is how we can use Playwright + Cheerio to extract the product data highlighted in the image above.
import { firefox } from 'playwright';
import * as cheerio from 'cheerio';
async function main() {
const browser = await firefox.launch({
headless: true,
});
const page = await browser.newPage();
await page.goto(
'https://www.mintmobile.com/devices/samsung-galaxy-a14/4666704/'
);
const html = await page.evaluate(() => document.body.innerHTML); // Save the page's HTML to a variable
const $ = cheerio.load(html); // Use Cheerio to load the page's HTML code
// Continue writing your scraper using Cheerio's jQuery syntax
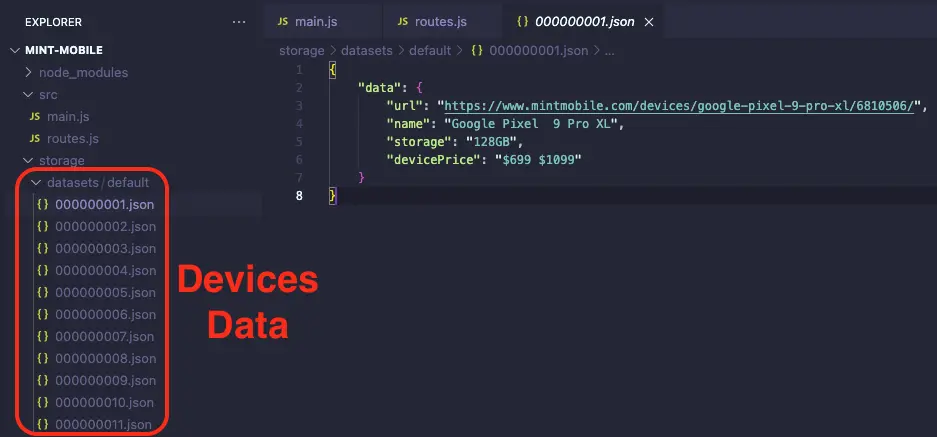
const phone = {
name: $('h1[data-qa="device-name"]').text().trim(),
storage: $('a[data-qa="storage-selection"] p:nth-child(1)')
.text()
.split(' ')
.pop(),
devicePrice: $('a[data-qa="storage-selection"] p:nth-child(2)')
.text()
.trim(),
};
console.log(phone);
await browser.close();
}
main();Expected output:
{
name: 'Samsung Galaxy A14 5G',
storage: '64GB',
devicePrice: '$120'
}Step 5: Using a full-featured Node.js web scraping library - Crawlee
First off, congrats on making it this far! By now, you’ve got a solid grasp of the top Node.js libraries for web scraping. But as you might have noticed, juggling multiple libraries can get messy. Plus, modern web scraping is about more than just extracting data — you often have to bypass advanced anti-scraping protections just to access the data you need.
That’s where Crawlee comes in. It’s the most comprehensive, full-stack web scraping library for Node.js, designed to simplify the whole process.

Crawlee is an open-source Node.js web scraping and automation library developed and maintained by Apify. It builds on top of all the libraries we’ve talked about so far Got Scraping, Cheerio, Puppeteer, and Playwright, and takes advantage of the already great features of these tools while providing extra functionality tailored to the needs of web scraping developers.
One of Crawlee's major selling points is its extensive out-of-the-box collection of features to help scrapers overcome modern website anti-bot defenses and reduce blocking rates. It achieves that by making HTTP requests that mimic browser headers and TLS fingerprints without requiring extra configuration.
Another handy characteristic of Crawlee is that it functions as an all-in-one toolbox for web scraping. We can switch between the available classes, such as CheerioCrawler, PuppeteerCrawler, and PlaywrightCrawler, to quickly access the features we need for each specific scraping use case.
Another handy characteristic of Crawlee is that it functions as an all-in-one toolbox for web scraping. We can switch between the available classes, such as CheerioCrawler, PuppeteerCrawler, and PlaywrightCrawler, to quickly access the features we need for each specific scraping use case.
1. Installation
npx crawlee create my-crawler2. File structure
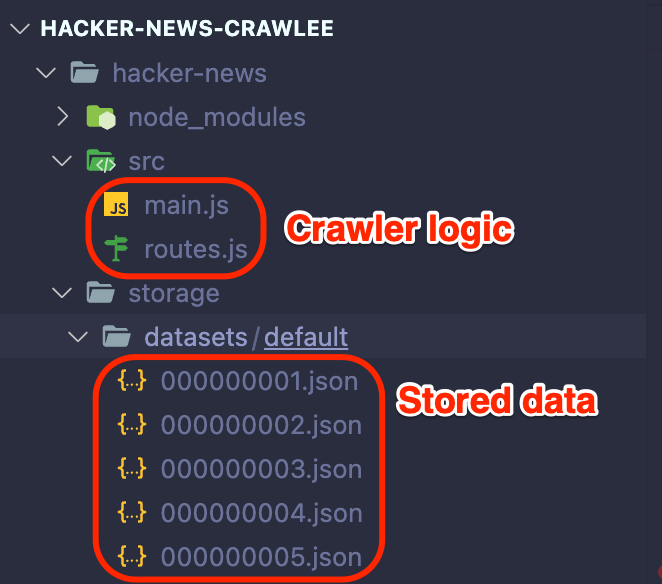
Before we jump into code examples, it’s important to understand the basic file structure you’ll get after running the npx crawlee create my-crawler command and selecting a starting template. The templates come with a lot of boilerplate code, saving you the hassle of setting everything up from scratch.
To promote code modularity, the crawler logic is split between two files, main.js and routes.js. Once you run your scraper, the extracted data will be automatically stored as json files in the datasets directory.
3. Code samples
👉 Using CheerioCrawler
In the first code sample, we will use Crawlee's CheerioCrawler to recursively scrape the Hacker News website.
The crawler starts with a single URL, finds links to the following pages, enqueues them, and continues until no more page links are available. The results are then stored on your disk in the datasets directory.
// main.js
import { CheerioCrawler } from "crawlee";
import { router } from "./routes.js";
const startUrls = ["https://news.ycombinator.com/"];
const crawler = new CheerioCrawler({
requestHandler: router,
});
await crawler.run(startUrls);// routes.js
import { Dataset, createCheerioRouter } from "crawlee";
export const router = createCheerioRouter();
router.addDefaultHandler(async ({ enqueueLinks, log, $ }) => {
log.info(`enqueueing new URLs`);
await enqueueLinks({
globs: ["https://news.ycombinator.com/?p=*"],
});
const data = $(".athing")
.map((index, post) => {
return {
postUrL: $(post).find(".title a").attr("href"),
title: $(post).find(".title a").text(),
rank: $(post).find(".rank").text(),
};
})
.toArray();
await Dataset.pushData({
data,
});
});Expected output (each stored JSON file will contain the results for the particular scraped page):
{
"data": [
{
"postUrL": "https://www.withdiode.com/projects/62716731-5e1e-4622-86af-90d8e6b5123b",
"title": "A circuit simulator that doesn't look like it was made in 2003withdiode.com",
"rank": "1."
},
{
"postUrL": "https://lwn.net/ml/linux-doc/20221214185714.868374-1-tytso@mit.edu/",
"title": "Documentation/Process: Add Linux Kernel Contribution Maturity Modellwn.net",
"rank": "2."
},
{
"postUrL": "https://computoid.com/APPerl/",
"title": "Actually Portable Perlcomputoid.com",
"rank": "3."
},
...
{
"postUrL": "https://www.axios.com/2022/12/14/twitter-elon-musk-jet-tracker-account-suspended",
"title": "Musk Bans His Twitter's Jet Tracker Account and Its Authoraxios.com",
"rank": "611."
},
{
"postUrL": "https://www.youtube.com/watch?v=10pFCIFpAtY",
"title": "Police Caught Red-Handed Making Bogus Traffic Stopyoutube.com",
"rank": "612."
},
{
"postUrL": "https://www.wsj.com/articles/tesla-investors-voice-concern-over-elon-musks-focus-on-twitter-11670948786",
"title": "Tesla Investors Voice Concern over Elon Musk’s Focus on Twitterwsj.com",
"rank": "613."
}
]
}
👉 Using PlaywrightCrawler
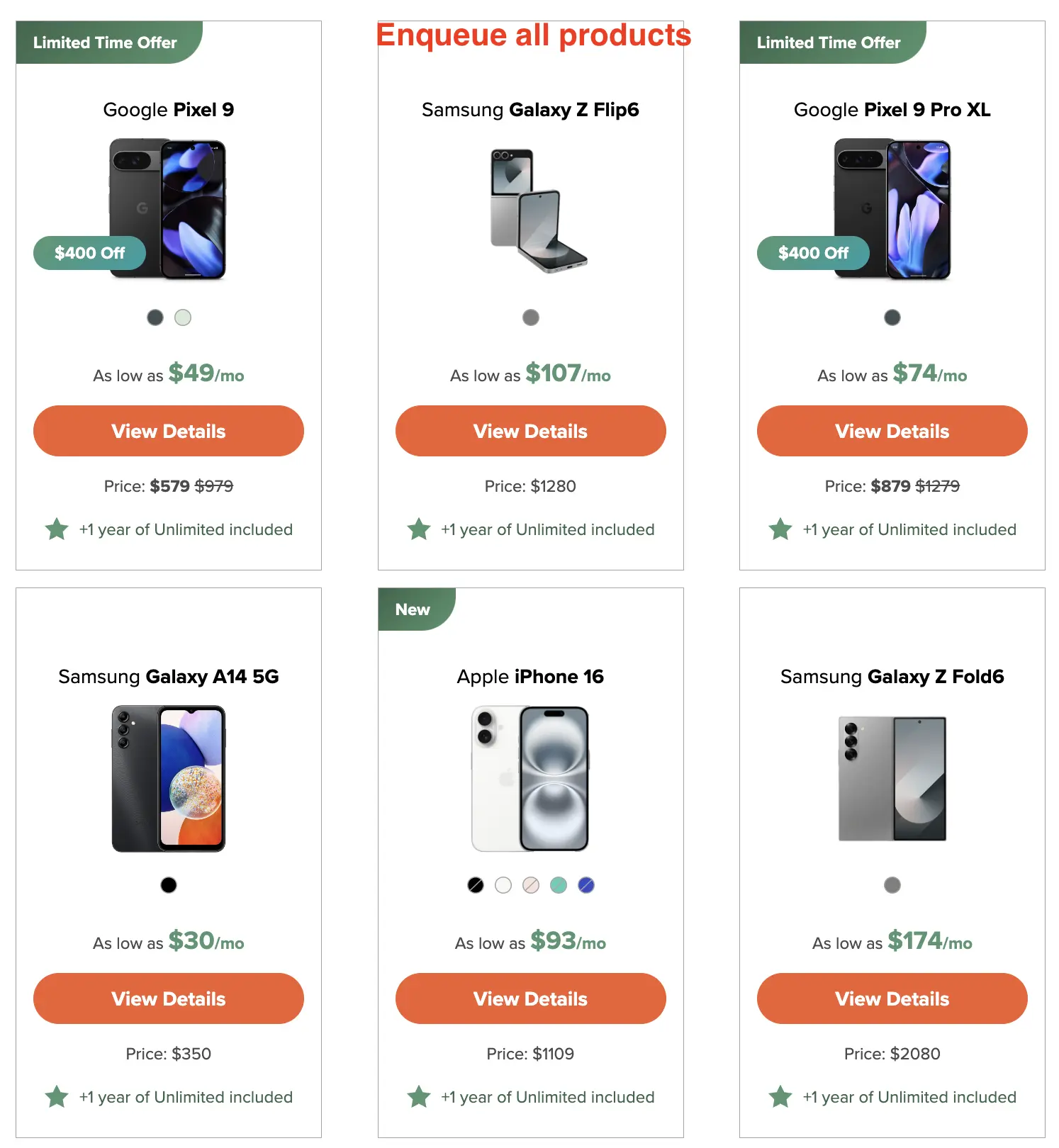
In the second code example, we’ll use Crawlee’s PlaywrightCrawler to scrape the product cards for each phone on Mint Mobile’s deals page. Building on the code we wrote earlier in the Playwright section, we’ll expand it with Crawlee to crawl through all the products and extract details from each one.
// main.js
import { PlaywrightCrawler } from "crawlee";
import { router } from "./routes.js";
const startUrls = ["https://www.mintmobile.com/deals/"];
const crawler = new PlaywrightCrawler({
requestHandler: router,
});
await crawler.run(startUrls);
// routes.js
import { Dataset, createPlaywrightRouter } from 'crawlee';
export const router = createPlaywrightRouter();
router.addDefaultHandler(async ({ log, enqueueLinks }) => {
log.info('Extracting data');
await enqueueLinks({ selector: 'a[data-elcat="CTA"]', label: 'detail' });
});
router.addHandler('detail', async ({ log, page }) => {
log.info('Extracting data');
const data = await page.evaluate(() => {
const scrapedData = {
name: document.querySelector('h1[data-qa="device-name"]').innerText,
storage: document.querySelector(
'a[data-qa="storage-selection"] p:nth-child(1)'
).innerText,
devicePrice: document.querySelector(
'a[data-qa="storage-selection"] p:nth-child(2)'
).innerText,
};
return scrapedData;
});
log.info('Pushing scraped data to the dataset');
await Dataset.pushData({
data,
});
});
Expected output:
Conclusion: why use JavaScript and Node.js for web scraping?
Node.js is a great option for web scraping, letting you tap into the full power of JavaScript on the server side. This means you can use the same familiar syntax along with a ton of powerful libraries to tackle scraping tasks.
To recap, Got Scraping simplifies handling HTTP requests, especially when you're trying to avoid getting blocked. Cheerio is ideal for parsing and extracting data from HTML. For more complex, dynamic websites, Playwright’s browser automation steps in to get the job done. And finally, Crawlee ties it all together, offering a full-stack solution that streamlines your scraping tasks and makes everything easier to manage.
Frequently asked questions
Can you use JavaScript for web scraping?
Yes, you can use JavaScript for web scraping. It is particularly effective for websites that are heavily dependent on JavaScript to render their content, allowing you to interact dynamically with the web page's elements.
Is JavaScript good for scraping?
Yes, JavaScript is good for web scraping because it executes web page scripts the same way a browser does, enabling access to dynamically generated content that other languages might miss.
What is the best web scraping tool for JavaScript?
The best web scraping tool for JavaScript depends on the task at hand. For sending requests, we recommend Got Scraping and Axios. For parsing, Cheerio is best. For scraping dynamic content, we recommend Playwright. For a complete web scraping library that combines all of these features, we recommend Crawlee.
Is Python or JavaScript better for web scraping?
Both Python and JavaScript are effective for web scraping, but the choice depends on the project's specifics. JavaScript is better for scraping dynamic content directly executed in the browser, while Python offers robust libraries like BeautifulSoup and Scrapy for diverse scraping needs.





