


Lots of businesses and startups out there will claim that they are powered by AI, working on AI, or connected to AI in some shape or form. But in reality, all that’s happening is just some good old attempt at internet hype, the recipe for which goes as follows: slap a machine learning sticker on it and suddenly your tool seems to be supernaturally efficient, smart, and smooth. Scratch a little deeper than the surface talk and the fancy taglines, and those AI enthusiasts won’t be able to tell the difference between machine learning, deep learning, and artificial intelligence, let alone know their Asimovs and Čapeks.
And when it comes to web scraping, things get even more complicated technically. One might think - what’s so difficult about it, you are literally creating web robots, what’s the issue with teaching them a thing or two? Well, it turns out that combining RPA and AI is so technically challenging, that we here at Apify are one of the few on the market consistently working in that direction (no pressure though, for our pioneers in AI Lab).
In any case, there are many ways to teach a machine how to scrape the web better. We’re here to share the knowledge and outline 3 web scraping projects our AI team has been working on: Product Mapping, Automated Product Detail Extraction, and Browser Fingerprint Generator. Let’s have a quick look at how we can automate the automation.
1. Product mapping - a case for business
or how to train an AI model for e-commerce
What do you imagine when you hear about such things as competitor analysis in, let’s say, retail? Probably not a team who spends their working days manually comparing similar products displayed on two different online catalogs, finding matching pairs, logging their details into some sort of document, and compiling the results.
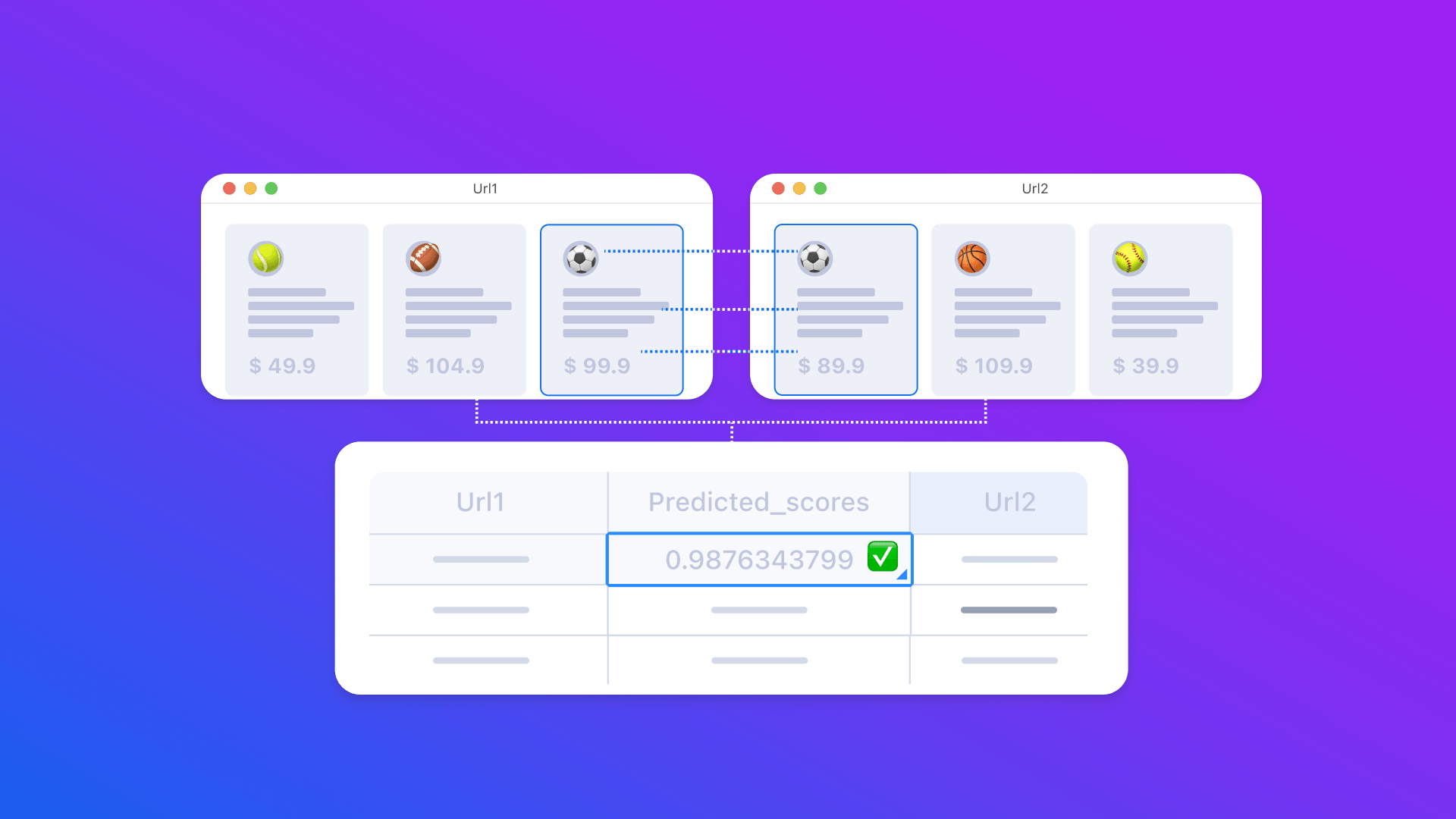
Believe it or not, this is what competitor analysis usually looks like in real life, even in the days of automation at seemingly every corner. That’s because usually, humans are still much better and more accurate at executing this task than most of the available tools. Way to go, humans! You’d be surprised how hard it is to program a machine capable of comparing a few products and figuring out which of their differences matter. In any case, this is exactly what our AI Lab has set out to accomplish. Matěj and Kačka are creating a model capable of telling whether this laptop on Amazon and that laptop on eBay are indeed the same item with perhaps a slightly different price tag.
In order to make this happen, our team has created a dataset of pairs of similar products from several different categories, such as electronics or household supplies. All the pairs have been manually pre-checked for being equivalent. The pairs were then made into a special dataset to be fed to the model for training. In theory, this is how the model learns the concept of similarity, and then applies this algorithm to decide whether the items in each category are the same or not.
Here’s where we run into a whole batch of issues: as you (as a browsing customer) might notice, the way online catalogs present their products differs from case to case. It’s an easy distinction for us humans to make, but not for machines. There are quite a few different product attributes to take into account (names, descriptions, precise specifications, and so on). All of these attributes and their placement on the webpage have a big influence on the AI’s decision-making process. To give you an example - reworded naming, a missing attribute, or even a slight change in image size or rotation might already be challenging. The task of our AI team is to teach the algorithm to be able to deal with these cases. So there’s a lot of work there in Product Mapping.

We've made several models using the most common machine learning techniques: linear and logistic regression, decision trees and random forests, neural networks, and SVM classifiers. And the beginning looked quite optimistic: with the original code, without any prior training from the datasets, the AI model was already able to identify (some) pairs. It curated a pool of both match and no-match pairs, out of which most were true matches. Those matches that the model did identify correctly constituted more than half of all available matches of the task.
These two figures are called precision and recall, the alpha and omega of the AI sphere. They are also flexible to our needs. For example, we can shift the algorithms to find fewer matches but with a higher rate of certainty. Or vice versa - find more results in general, but with less certainty that those would be the ones we need. It’s important to have space for experimentation here because whether the precision or recall should be fine-tuned depends on the specific use case.
You’ll say wait, what about the language? Would the model have to be adapted to every language separately? We’ve challenged our model with Czech products first - and doing that actually proved beneficial because of the complex Czech morphology, declination and conjugation, so the English results are expected to be even higher quality (spoiler alert: they are). In addition, the most important part of the model, the classifier, is language-blind, so we can apply it to other domains as well.
Product matching AI is out!
We've finished training our Al model for e-commerce. See how and why to use it for collecting and monitoring prices and retail data.
The goal and the big idea is to create an AI model that is as generic as possible, meaning flexible and easily adaptable to various use cases. Right now we have 5 stages that the model has to go through: check scraped data and adjust preprocessing, annotate a sample of data, fine-tune the pre-trained model, estimate performance, and run for production data. And there are many directions for improvements at every stage: starting from having better-labeled data and improvements in data preprocessing and parsing to introduction of code optimizations, more sophisticated classifiers, and perhaps even rewriting parts of code from Python to C++ to make it run faster.
But as we get more and more data and confidence in the results that the system achieves, we are certain we’ll be able to create an Actor that would work in a generic way. And we did! As we'd hoped, the deployment process is now simplified looks like this: you simply give this Product Matching Actor 🔗 a pair of datasets, and it runs for production immediately. The AI model is user-friendly, fast and ready for anyone to try doing product mapping with AI.
The Product matching AI tool is ready! Check out how it works.
2. Automated product detail extraction - a case for web automation developers
or how to build a sniper scope for CSS selectors
AI in web scraping (and in general) is all about finding patterns and using them to your advantage. One pattern that the web developers would really love not to see anymore is web scrapers breaking. It happens quite often: the layout of the scraped website slightly changes, and voila - hours of work are gone. Now you have to spend time finding the exact spot where your scraper has to be reworked and then fixing it to fit the new layout. And you have to do this quite often. It’s challenging to call yourself a web automation dev after that.
Wouldn’t it be great to have a program able to find and look at the old layout, quickly detect the new CSS selector and fix it in the scraper? Well, if this were easy, would it have made it onto our AI web scraping projects list?
A lot of things that look obvious to us are difficult for a machine to differentiate. To the machine, names, descriptions, prices on a webpage are all just data. While on the website interface you can clearly notice that the price part has been moved elsewhere, the machine won’t be able to easily pinpoint it because it doesn’t know what a price is. So Jan’s task, who is working on this project, is to teach the machine how price differs from the rest of the attributes and so on.
If Jan’s program perfects Automated Product Detail Extraction, it can be applied to generating brand new scrapers or automatically refreshing old ones. A true lifesaver for a web automation developer as well as for businesses whose bottom line depends on smooth and unimpeded web data extraction. Our end goal is to have a tool take away a lot of the burden of manual search and selector detection from the web devs, saving them time for some real coding.

3. Fingerprint and header generators - a case for anti-anti-scraping protections
or how to become a web scraping ninja
Long gone are the days when one could just build a scraper that worked from the get-go. If you've ever tried building a scraper of your own, you know the drill: what usually works for a simple website runs into strong rebuffs from a larger one. This is why these days, the web scraping scene is nothing short of an arms race where one side develops powerful anti-scraping measures, and another is coming up with smart workarounds to bypass them.
Websites have come up with many elaborate strategies to detect whether the visiting device is a bot or belongs to a person. User behavior analysis, HTTP request analysis, browser fingerprinting… and probably more of those still cooking. Even if you bypass all those challenges, there’s still a chance to get IP-blocked in the end anyway. And these measures are, to an extent, understandable, as a careless targeted stream of requests can easily bring down a website.
One of the most efficient recent anti-bot measures is fingerprinting-based detection. A fingerprint is usually a complicated formula with lots of variables consisting of data points that the website gets about the visitor: particular device, operating system, IP address, and browser specifications via cookies. Surface analysis of user behavior combined with this data allows websites to label visitors as human or bot traffic with rather high accuracy rates. So if a profile of a page visitor matches with known bot fingerprints, it can get labeled as a bot and banned. For such cases, simply switching up user agents or rotating a few IP addresses won’t be enough. Web scraping needs to step up its game.
So how do powerful scrapers do it? Cue in: generating realistic browser headers and fingerprints. But how does one design an anti-fingerprinting program that imitates human-browser fingerprints? By capturing the dependencies in real headers and fingerprints using a dependency model, such as a Bayesian network, and using that to generate the fingerprints. It is a given that the webpages are using a certain level of machine learning to analyze user behavior, detect bots with high accuracy and block them out. So what you have to do is to figure out the rules that this model plays by and outsmart it.
In reality, this means our team has to collect data on browsing patterns and train the model to generate plausible combinations of browsers, OSs, devices, and other attributes collected when fingerprinting that guarantee bypassing anti-scraping measures. They do this by first collecting the known “passing” fingerprints into a database, then labeling them by category and feeding the data to the AI model to steer its learning. Ideally, the AI model should provide fingerprints that are random but still human enough not to be discarded by the website. Monitoring success rates per fingerprint and creating a feedback loop can also help the AI model improve with time.
As you can see, generating realistic web fingerprints is not exactly your web scraping crash course. ML-based anti-bot algorithms gave rise to AI-powered dynamic fingerprinting, machine against machine. But these days it would be quite hard to scrape at scale and stay on top of the data extraction business without such technology and strategy behind it.
We’ve covered 3 web scraping powered by AI projects here: generating web fingerprints for combating anti-scraping measures, identifying CSS selectors for quick scraper repairs, and product mapping for competitor analysis. Hopefully, we’ve managed to shine some light on this complicated combo and the machines will spare our lives when they will inevitably go to war against each other and, ultimately, humanity. Cheers!
Apify can bring the vast amounts of data from the web to your fingertips




