Finding accurate, up-to-date data at scale has become essential for market research, competitor monitoring, pricing analysis, and countless other business processes. But manually collecting data from websites is slow, error-prone, and impossible to scale, especially when you need thousands - or millions - of records.
Web scraping tools solve this challenge - they’re no longer an outlier but part of the technological stack of all kinds of companies. Data extraction solutions range from simple no-code Chrome extensions to enterprise-grade cloud platforms that handle rotating proxies, CAPTCHAs, and JavaScript-heavy websites for you.
In this guide, we break down the best web scraping tools available right now, what they do, who they’re for, and how to choose the one that fits your exact needs.
What to look for in a web scraping tool
Let's make one thing clear. Despite the title of this article, there's no such thing as 'the best web scraping tool'; only the best tool for the job at hand. That being said, there's much more to consider than choosing the right features for the target website or for your workflow. Each of the tools in our list meets at least one of the following five criteria:
- Ease of use
- Cost
- Performance
- Versatility
- Customer support
Other considerations, such as web scraping software, storage, proxies, integrations, and anti-blocking features, depend on the scale and scope of your project, the kind of data you need, and what you want to do with it. We'll also refer to these in our list.
Best web scraping tools in 2026
1. Apify
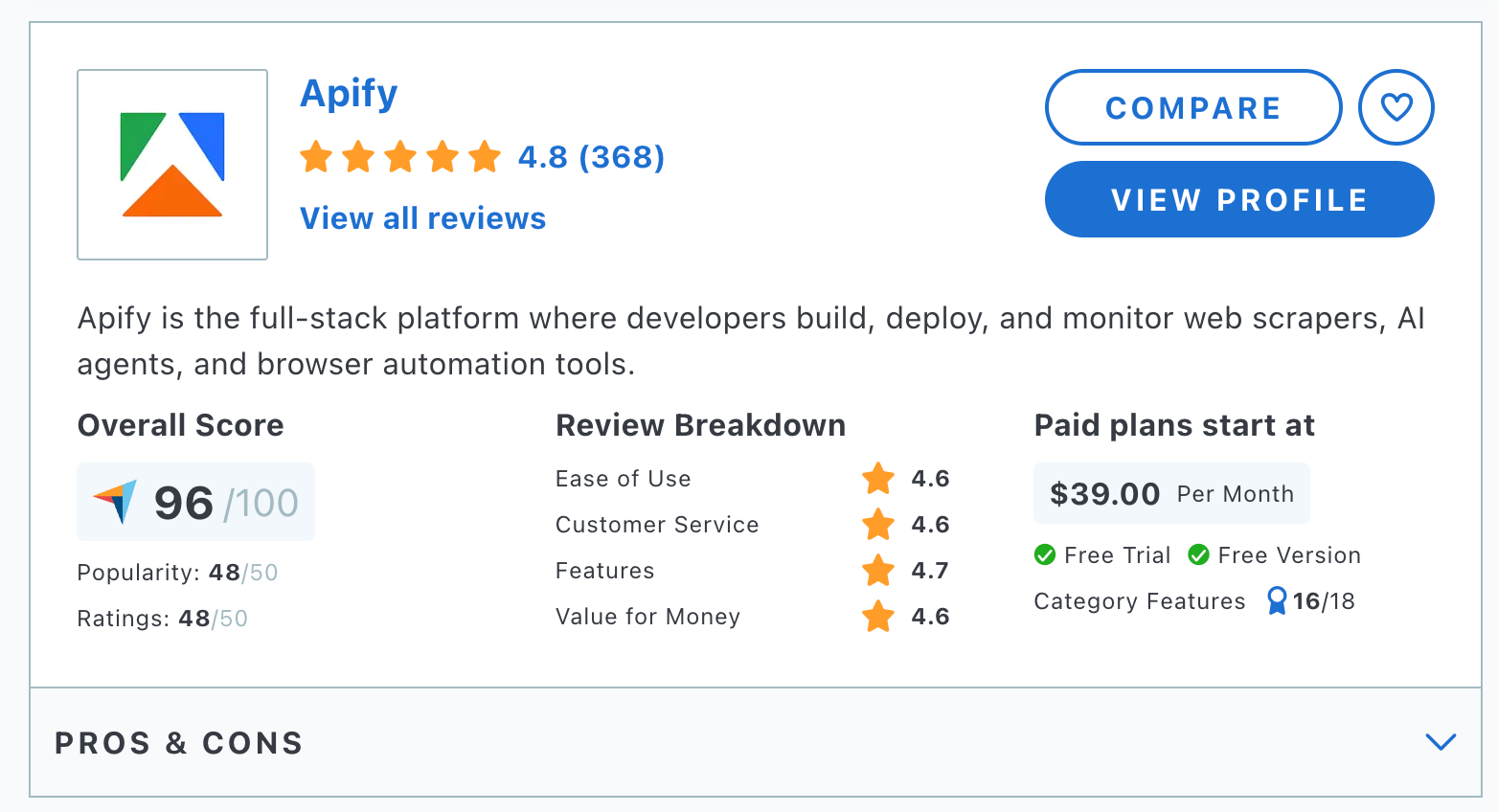
Apify is the largest marketplace of tools for AI, where you can develop and host your own data extraction tools in the cloud and build scalable web crawlers. Apify offers two paths for your data collection strategy - each designed for different use cases. You can either choose a quick, pre-made solution from Apify Store or let the Apify experts handle the whole process for you, providing you with a fully customized end-to-end data collection solution.
Best for
Developers seeking a comprehensive tool for scraping data at scale and browser automation.
Features
- JavaScript rendering
- Proxies
- API access
- Cloud data storage
- Scheduling and integrations for scraping automation
Pricing
Paid plans start at just $29 per month, but there's no time limit on the free plan, which gives you $5 worth of credit every month. This makes Apify one of the most affordable web scraping tools for starting out on small projects.
Why Apify?
- Versatility ✅
Apify offers a wide range of automation tools beyond scraping, providing a comprehensive marketplace of tools for web automation and AI.
- Performance ✅
Apify provides smart proxy rotation and anti-blocking to make your web scrapers performant and fast while keeping costs to a minimum.
- Customer support ✅
Apify offers solid customer support, including email, chat, and phone assistance, to help users when needed. It also provides comprehensive guides, API documentation, and a community forum where developers can exchange ideas and best practices.
- Library of pre-built web scraping tools
While Apify is a versatile and scalable platform for developers, it's also a good option for the less technical. Its library of pre-built web scrapers (the Actors in Apify Store) is a collection of scraping tools created by developers that you can use and configure for your use case with a user-friendly UI.
- Integration capabilities
Apify provides extensive options for data integration, including support for various output formats and cloud delivery options, which can significantly ease the process of integrating scraped data into business workflows.
- Fully-managed custom enterprise solutions
For organizations requiring tailored solutions that cater to specific business needs, Apify handles the end-to-end management of projects, from the initial consultation and custom software development to ongoing support and maintenance.
2. Oxylabs
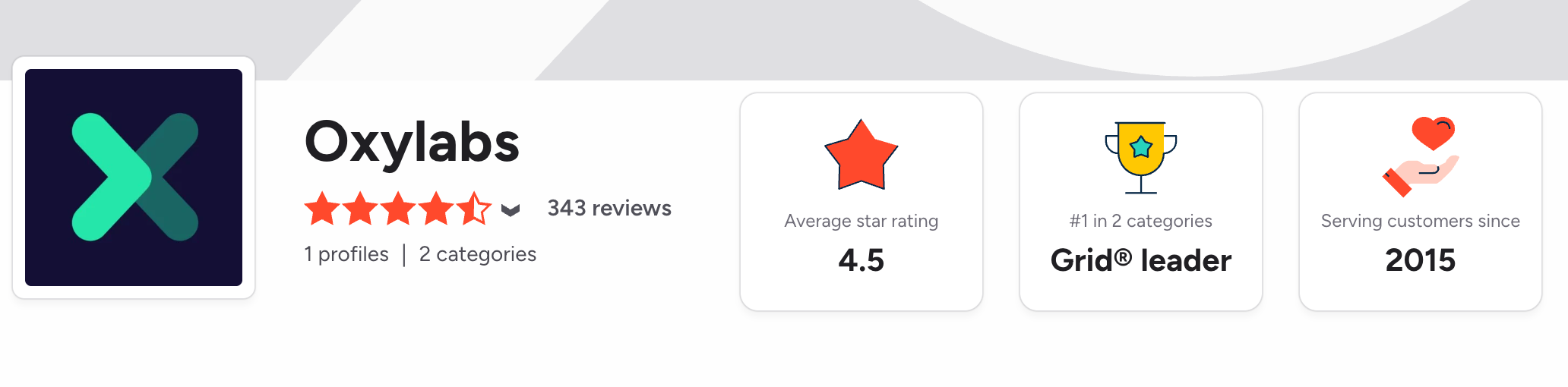
Oxylabs is a leading provider of proxy services and web scraping solutions designed to support large-scale data extraction needs across various industries. It is highly regarded for its extensive pool of over 100 million residential proxies and powerful web intelligence capabilities.
Best for
Large enterprises and professionals who require reliable, scalable web scraping solutions and extensive proxy management to handle complex data collection at scale.
Features
- Extensive proxy pool with over 100 million IPs
- Advanced proxy rotation and management
- Automated unblocking and CAPTCHA bypass
- SERP scraper and e-commerce APIs
Pricing
Oxylabs offers various pricing tiers for its web scraping APIs, starting at $49 per month for its micro package. This includes up to 17,500 results per month and a rate limit of 10 requests per second. There's a 7-day free trial period.
Why Oxylabs?
- Performance ✅
With features like the SERP Scraper, Web Scraper, and E-commerce Scraper APIs, Oxylabs allows for efficient scraping of complex and dynamic websites.
- Customer support ✅
Oxylabs provides 24/7 support with access to live representatives, which is a significant advantage for businesses that rely on continuous data access and need immediate assistance.
- Integration requirements
While Oxylabs provides powerful web scraping APIs, integrating these tools into existing systems or workflows might require significant technical effort. Businesses need to assess their current infrastructure and possibly invest in additional software or expertise to utilize Oxylabs' capabilities fully.
- Long-term scalability and cost management
Oxylabs' pricing model, based on usage and features, necessitates careful planning for businesses that anticipate scaling their data extraction needs. As usage grows, costs can increase substantially, so it's important for users to monitor their data usage closely and choose the right plan to maintain cost-effectiveness.
3. Bright Data
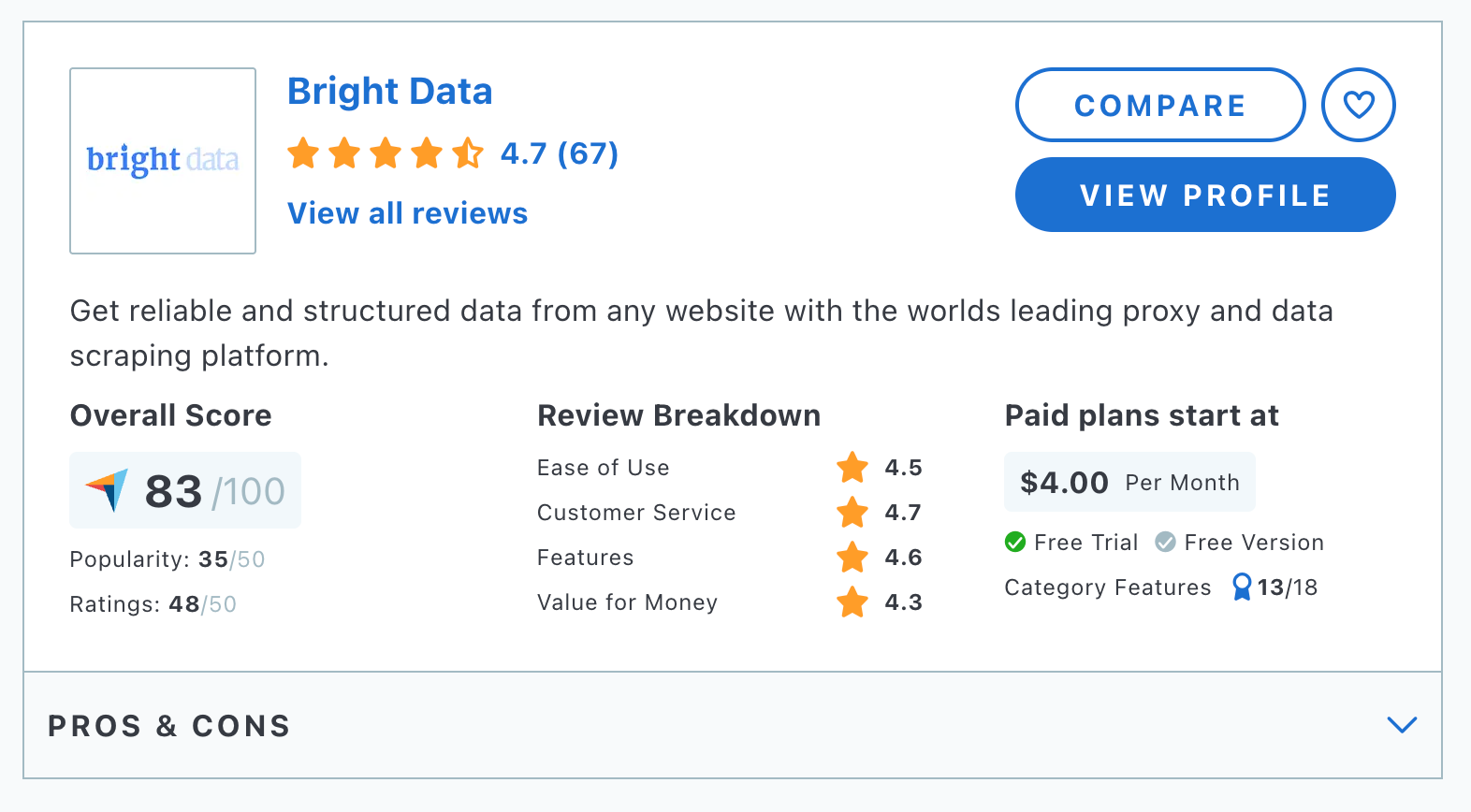
Bright Data is acclaimed for its sophisticated proxy network and comprehensive data collection capabilities. It caters to diverse industries, including market research, brand protection, and digital marketing. It emphasizes speed, reliability, and extensive geographic and network coverage.
Best for
Businesses in need of advanced proxy solutions and large-scale data extraction, especially those dealing with highly secure or difficult-to-scrape websites.
Features
- Extensive proxy networks
- Advanced data collection tools
- High success rate with bypassing CAPTCHAs and geo-restrictions
- Comprehensive API support and integration with major platforms
Pricing
Bright Data offers various pricing plans. The Web Scraper IDE plan begins at $499 per month, but there are also pay-as-you-go options for its IDE, SERP API, Web Unlocker, and Scraping Browser starting at $1.5/1,000 records.
Why Bright Data?
- Performance ✅
Bright Data's extensive and speedy proxy network ensures reliable and efficient data collection across diverse internet landscapes. It's designed to handle large-scale operations and complex data gathering at high speeds.
- Customer support ✅
Bright Data offers excellent customer support, available 24/7 with a range of support options including live chat, phone, and a detailed knowledge base.
- Anti-blocking
Bright Data's Web Unlocker tool is designed to tackle site-blocking challenges effectively.
- Flexible and scalable
Bright Data's pricing and services are flexible, allowing businesses of all sizes to scale their data collection efforts as needed.
4. ParseHub

ParseHub is a user-friendly web scraping tool designed to handle the complexities of extracting data from dynamic and JavaScript-heavy websites without requiring coding skills. ParseHub allows users to navigate through forms, dropdowns, infinite scroll pages, and more to turn web content into structured data.
Best for
Users with limited technical skills needing to scrape data from websites using JavaScript.
Features
- Visual editor for selecting data
- Support for AJAX and JavaScript-heavy websites
- Scheduled scraping
- API for integration
Pricing
Paid plans start from $189 per month. A limited free plan is available.
Why ParseHub?
- Ease of use ✅
ParseHub offers a visual interface that allows users to point and click to select data, making it simple to set up and run scraping projects without any programming knowledge.
- Performance ✅
Capable of handling complex websites that utilize AJAX and JavaScript, ParseHub can manage data extraction tasks that involve navigating through multiple layers of content.
- Platform compatibility
ParseHub is available as a desktop application for both Windows and Mac, meaning a broad range of users can access its functionality without compatibility issues.
- Advanced features for higher plans
While the basic plan offers a good start, advanced features like unlimited pages per run and priority support are reserved for higher-tier plans, which might be necessary for users handling large-scale data extraction projects.
5. Diffbot

Diffbot is a cutting-edge web scraping and data management platform that utilizes advanced artificial intelligence to transform unstructured web data into structured, actionable information. It's known for its ability to automatically crawl, analyze, and parse vast amounts of web data using its AI-driven tools.
Best for
Developers and businesses needing turnkey data extraction using natural language processing.
Features
- Automatic site structure analysis
- Uses machine learning to extract data
- API access
- Integration with several databases and platforms
Pricing
Plans start from $299 per month. A quick-start free plan is available for personal or budget-conscious projects.
Why Diffbot?
- Performance ✅
Diffbot excels in extracting data with high accuracy due to its sophisticated AI algorithms that can intelligently navigate and interpret a wide array of web formats and structures.
- API-first approach
Diffbot provides an API-centric service, which is great for developers looking to integrate web data directly into their applications or services. However, this might require some technical knowledge to implement effectively, which could be a consideration for teams without dedicated development resources.
6. Octoparse
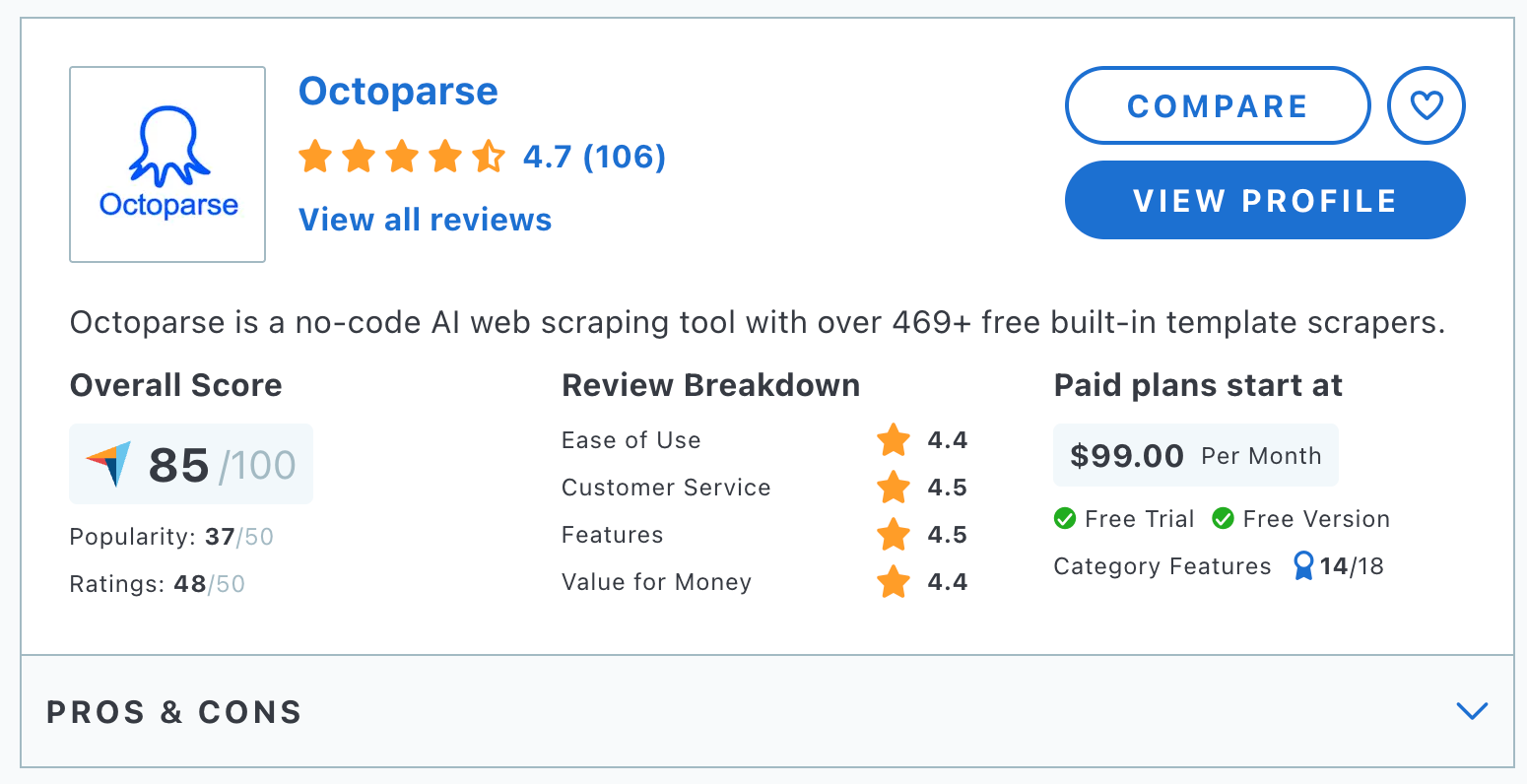
Octoparse is a web scraping tool designed to simplify the process of data extraction from websites for users of all skill levels, particularly beginners. With its intuitive user interface and no-code approach, Octoparse allows users to quickly set up and execute data scraping tasks without any programming knowledge.
Best for
Non-programmers and businesses that require data extraction from complex websites without coding.
Features
- Point-and-click interface
- Automatic IP rotation
- Cloud-based or local execution
- Export data to various formats
Pricing
Paid plans start from $83 per month (the Capterra profile is not up-to-date). A free plan for small, simple projects is also available.
Why Octoparse?
- Ease of use ✅
Octoparse is known for its easy-to-use interface that guides users through the process of creating data extraction tasks using simple point-and-click techniques.
- Customer support ✅
Octoparse provides excellent customer support, with resources such as tutorials, a comprehensive knowledge base, and responsive support staff.
- Platform compatibility
While Octoparse is highly effective on Windows, it's worth noting that there is limited support for other operating systems, which could be a drawback for users on macOS or Linux.
- Learning curve for advanced features
Although Octoparse is user-friendly, using some of its more advanced features might require a steeper learning curve. New users should be prepared to spend some time learning the tool to exploit its capabilities fully.
7. Scrape.do

Scrape.do is a web scraping tool used by data teams to pull structured data from protected sites without building and maintaining the unblocking stack themselves. The product runs on a proxy network of 110 million+ IPs across datacenter, residential, and mobile pools, and ships with a dashboard for account setup, usage tracking, request logs, credit balance, and team access.
Best for
Data teams and product engineers who want a reliable scraping tool they can evaluate on the entry plan, monitor from a dashboard, and keep under a single vendor relationship as use cases grow.
Features
- Dashboard with usage analytics, request logs, and credit tracking
- Proxy pool of 110M+ IPs across datacenter, residential, and mobile, spanning 100+ countries
- JavaScript rendering, CAPTCHA handling, retries, session management, and geo-targeting
- Output in HTML, JSON, XML, or markdown, selectable per request
- Team access and API key rotation from the account panel
Pricing
Plans start with a free tier of 1,000 monthly requests (no card required). The Hobby plan is $29/month for 250,000 requests with all features included, which works out to roughly $0.12 per 1,000 requests at base rate. Effective cost per 1K drops further on larger plans. Advanced features consume credit multipliers on the base plan: JS rendering costs 5 credits, premium proxies cost 10, and both together cost 25.
Why Scrape.do?
- Performance ✅
The 110M+ IP pool and server-side handling of rotation, rendering, and retries are the core of the reliability story on protected targets. Since every feature is available from the entry plan, teams don't hit a "buy the bigger plan to unlock the real product" wall mid-evaluation.
- Cost ✅
The $29 entry plan includes every feature (JS rendering, premium proxies, geo-targeting, markdown output). Base-rate pricing lands near $0.12 per 1,000 requests, and effective cost drops further on larger plans.
- Dashboard and monitoring
The dashboard covers usage, logs, and credit status at an account level, which is the view a team lead or data engineer actually needs for ongoing operation. Per-request debugging data is available without tailing server logs.
8. ScrapingBee
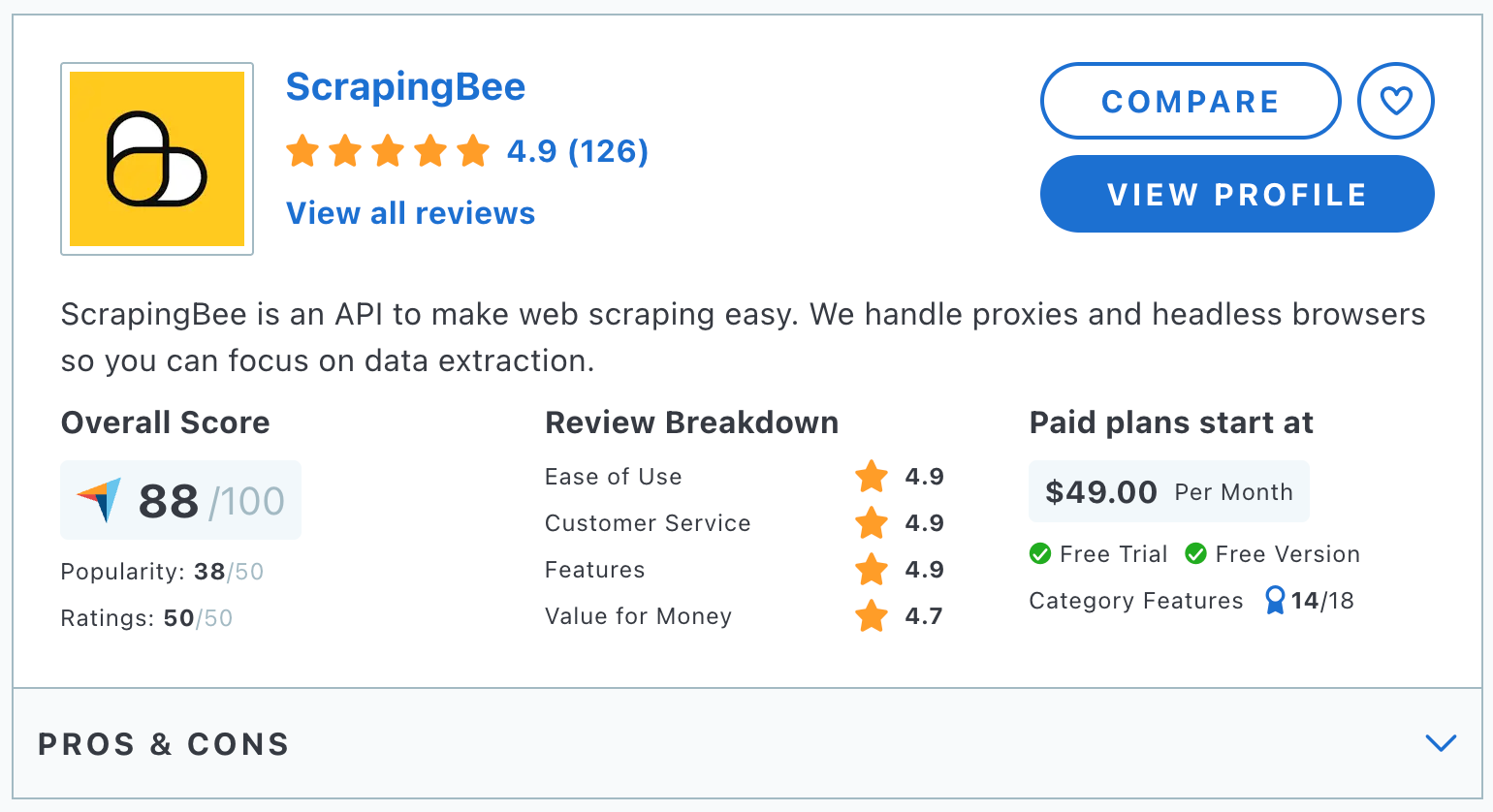
ScrapingBee is a powerful web scraping API that manages the complexities of headless browsers, proxies, and CAPTCHAs, simplifying the data extraction process for its users. This tool is designed to handle both simple and complex websites efficiently, making it ideal for developers needing reliable data extraction without investing in extensive infrastructure.
Best for
Developers needing straightforward API for scraping websites that require rendering JavaScript.
Features
- Handles JavaScript-heavy sites
- API-driven approach
- Proxy management
- Google SERP scraping
Pricing
Plans start from $49 per month. This scales up based on the number of API credits and features required. A free trial plan is available.
Why ScrapingBee?
- Performance ✅
ScrapingBee is favored for its straightforward API that facilitates easy integration and rapid setup. The platform also offers efficient proxy management that rotates IPs to avoid detection and provides high success rates in data extraction.
- Cost ✅
ScrapingBee offers a range of pricing plans starting from $49 per month and a generous free plan, which can accommodate small projects.
- Documentation and tutorials
The platform provides extensive documentation and excellent web scraping tutorials to assist users.
9. ScraperAPI
ScraperAPI is a versatile tool designed to streamline web scraping by efficiently handling complexities like proxies, browsers, and CAPTCHAs. ScraperAPI's infrastructure facilitates efficient data extraction from various websites, enabling users to fetch HTML content through a straightforward API call.
Best for
Developers looking for an API to handle web scraping complexities such as proxies, browsers, and CAPTCHAs.
Features
- Geolocation targeting
- API-driven approach
- JavaScript rendering
- Structured data endpoints
Pricing
Paid plans start from $49 per month, and with a free plan providing 100,000 free API credits, ScraperAPI is one of the cheapest starter options on our list.
Why ScraperAPI?
- Performance ✅
With features like smart proxy rotation and automatic retries, Scraper API excels in managing proxies effectively. This capability ensures high success rates in scraping activities.
- Cost ✅
ScraperAPI offers a range of pricing plans starting at $49 per month and a generous free plan, which can accommodate small projects.
- Geolocation targeting limitations
Geolocation targeting is restricted to the US and EU for all ScraperAPI plans except the business plan. The business plan gives full access to geolocation targeting.
- API playground and DataPipeline
A couple of new helpful features are currently in beta. API Playground is a visual API request builder that offers a much more user-friendly way to build and test custom API requests before integrating them into your code. With DataPipeline, users can schedule pre-configured jobs for both custom URLs and structured data endpoints.
10. Zyte

Zyte is a sophisticated web scraping and data extraction platform that utilizes machine learning to automate and enhance the scraping process. It offers features like automatic proxy rotation, smart ban detection, and scriptable browser support. This makes it a popular choice for complex and large-scale scraping tasks.
Best for
Large enterprises and developers who need a powerful tool to automate and manage web data extraction at scale.
Features
- AI-driven data extraction
- Automatic proxy rotation and retries
- Smart ban detection
- Geolocation targeting
- Extensive API functionalities
Pricing
Zyte’s pricing is usage-based: you pay per successful scraped request, with costs varying by website difficulty and whether browser rendering is required. Monthly spending can range from just a few dollars for light scraping to hundreds or more for large-scale or complex websites.
Why Zyte?
- Performance ✅
Zyte's use of AI and advanced technologies ensures efficient and accurate data extraction, even under challenging conditions.
- Versatility ✅
Zyte provides a comprehensive platform for web scraping automation.
- Integration capabilities
Zyte provides extensive options for data integration, including support for various output formats and cloud delivery options, which can significantly ease the process of integrating scraped data into business workflows.
- Maintenance and updates
Zyte's platform involves complex systems that require regular updates and maintenance to ensure optimal performance and security. Potential users should consider the frequency of updates and how these might affect their scraping activities.
11. Import.io

Import.io provides users with intuitive tools and powerful APIs to gather and manage web data efficiently. Its point-and-click tools make it a go-to solution for businesses aiming to utilize web data for market intelligence and to improve customer understanding.
Best for
Businesses and analysts who need data extraction without coding.
Features
- Point and click interface
- Integration with popular data analytics platforms
- Real-time data extraction
- API access
Pricing
Import.io does not show clear prices directly on its official website; you have to contact their sales team for a quote.
Why Import.io?
- Ease of use ✅
Import.io is known for its user-friendly interface that makes web scraping accessible even to those without deep technical expertise.
- Customer support ✅
The platform provides solid customer support, including email, chat, and phone assistance, to help users when needed.
- Web data integration across industries
With its flexible data extraction capabilities, Import.io serves a wide range of industries, helping businesses use accurate and timely market intelligence regardless of their specific market segment.
- Managed custom solutions
For enterprises with specific and complex requirements, Import.io offers custom solutions and managed services. This includes everything from initial setup to ongoing management.
12. Webscraper.io

Webscraper.io is a versatile web scraping extension designed for Chrome and Firefox that simplifies the data extraction process directly within your browser. This tool is particularly effective for handling dynamic web pages and sites with complex navigation structures. Its point-and-click interface makes it accessible to users without any coding expertise.
Best for
Individuals and small to medium-sized businesses that need an easy-to-use tool for extracting data directly from the browser without requiring programming knowledge.
Features
- Point-and-click interface
- Dynamic website extraction
- JavaScript execution
- Data customization with sitemaps
Pricing
Pricing for cloud-based features starts at $50 per month. It also offers a free browser extension for local use only.
Why Webscraper.io?
- Ease of use ✅
Webscraper.io's intuitive interface allows even non-technical users to configure and run scrapers effectively, making web scraping accessible to a broader audience.
- Integrations
While Webscraper.io offers integration with services like Google Sheets and Amazon S3, setting up these integrations might require some technical understanding, especially for automated workflows.
- Technical limitations
Although Webscraper.io is capable of handling a variety of websites, it may not perform optimally on sites with highly complex structures or heavy use of JavaScript that requires advanced rendering.
That was a lot to take in! So, before we recap, let's boil it down with a comparison table.
Top web scraping tools compared
This table compares 12 web scraping tools across five criteria: ease of use, cost, performance, versatility, and customer support.
| Tool | Best for | Ease of use | Cost | Performance | Versatility | Customer support |
|---|---|---|---|---|---|---|
| Apify | Developers | $29 | ✅ | ✅ | ✅ | |
| Oxylabs | Large enterprises | $49 | ✅ | ✅ | ||
| Bright Data | Large enterprises | $499 | ✅ | ✅ | ||
| ParseHub | Non-programmers | ✅ | $149 | ✅ | ||
| Diffbot | Developers | $299 | ✅ | |||
| Octoparse | Non-programmers | ✅ | $119 | ✅ | ||
| Scrape.do | Data teams and product engineers | ✅ | $29 | ✅ | ✅ | |
| ScrapingBee | Developers | $49 | ✅ | |||
| Scraper API | Developers | $49 | ✅ | |||
| Zyte | Large enterprises | $100 | ✅ | ✅ | ||
| Import.io | Businesses | ✅ | $399 | ✅ | ||
| Webscraper.io | Non-programmers | ✅ | $50 |
The best web scraping tool?
Keep in mind that the purpose of this review isn't to pick a winner. Not all of these tools are alike and can be combined for different types of tasks. While developers might prefer full-stack platforms like Apify or Zyte to build and deploy scrapers or easy-to-use APIs like ScrapingBee or Scraper API, others may prefer easy point-and-click tools without advanced features and integrations. So, choose whatever tools meet the requirements of your projects and tasks.
That being said, let's recap what these tools offer in terms of our five main criteria:
- Apify = Performance, Versatility, Customer support ⭐️⭐️⭐️
- Oxylabs = Performance, Customer support ⭐️⭐️
- Bright Data = Performance, Customer support ⭐️⭐️
- ParseHub = Ease of use, Performance ⭐️⭐️
- Diffbot = Performance ⭐️
- Octoparse = Ease of use, Customer support ⭐️⭐️
- Scrape.do = Performance, Cost ⭐️⭐️
- ScrapingBee = Performance ⭐️
- ScraperAPI = Cost ⭐️
- Zyte = Performance, Versatility ⭐️⭐️
- Import.io = Ease of use, Customer support ⭐️⭐️
- Webscraper.io = Ease of use ⭐️

Note: This evaluation is based on our understanding of information available to us as of December 2025. Readers should conduct their own research for detailed comparisons. Product names, logos, and brands are used for identification only and remain the property of their respective owners. Their use does not imply affiliation or endorsement.