


There can be a certain beauty to simplicity when it comes to programming languages for web scraping. Python is a case in point. Its code is renowned for readability, making it easier to comprehend and write. It tends to involve fewer lines than other languages, such as JavaScript, and it also has fewer structural rules.
Without wishing to offend any Python masters reading this, Python is usually the beginner's choice for web scraping. If you know the language but you’re new to web scraping, you may be wondering whether it’s the best option for whatever cunning data extraction plan you’re concocting. Let’s swiftly go through some of the pros and cons of web scraping in Python and find out which tools you can use for extracting data from the web.
What are the pros of web scraping in Python?
A vast Python community
One great advantage of Python is its enormous community. You’ll get plenty of support from developers, and there are video and blog tutorials aplenty on the world wide web. Python is by far the most used language for web scraping, and there’s a huge amount of documentation and guidance on how to use it for web data extraction.
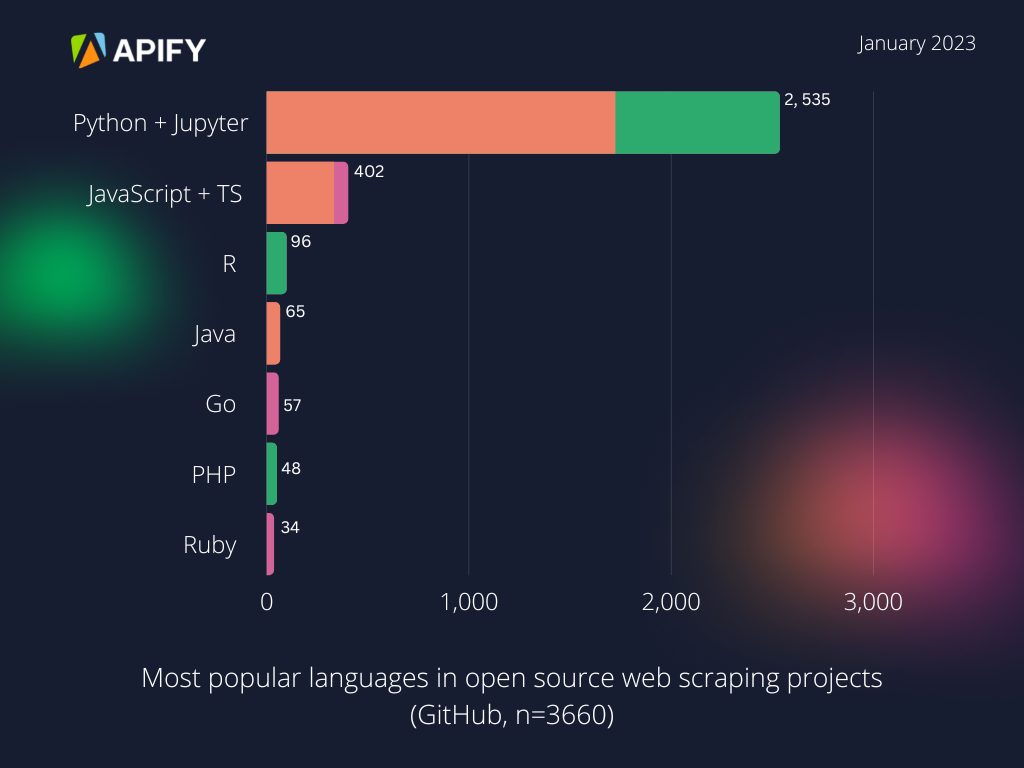
This chart from our blog post on the future of web scraping in 2023, based on data from GitHub, clearly demonstrates just how popular Python is compared to other languages.
Post-processing tools and visualization
The world of Python includes many post-processing and visualization tools, including but not limited to Pandas, Matplotlib, and Seaborn. Such tools are great for EDA (exploratory data analysis), data manipulation, and storing unstructured data in a structured format. That makes Python a great choice for adjusting scraped data to your needs.
Data pipelines in one language
One reason Python is such a popular language for data scientists is that Python’s packages make data pipelines so easy to create. This feature is no less useful for data acquired through web scraping. If you know Python, you can scrape something with libraries such as Requests and Beautiful Soup and then process it with Pandas and visualize it with Matplotlib.
What are the cons of web scraping in Python?
Browser scripting and executing JavaScript code
JavaScript is the language of the web. By that, we mean that the vast majority of websites require JS to run in the end user’s web browser to function. Yes, it’s possible for libraries such as Selenium to control web browsers with Python, and some libraries can execute JavaScript code, but it’s not very convenient to write half of your script in Python and the other half in JavaScript. Many developers prefer to use a single language for all their web scraping needs.
Scaling scraping tasks
When trying to scale up your scraping operations and run multiple tasks in parallel, other languages allow you to do that much easier than Python. To do it with Python, you need a library like Scrapy that manages the multiple threads for you. Whereas, with Node.js, for example, the built-in event loop allows you to run multiple scraping tasks in parallel easily and with superior performance.
A case in point is Daltix and its decision to move its scrapers from Python to JavaScript. The structural limits of the Python library, Scrapy, and the difficulty of integrating with browsers led to the decision to migrate their scrapers to the open-source Node.js library, Crawlee.
What are the best Python web scraping libraries?
The Python ecosystem contains some pretty powerful scraping tools. The six below are certainly among the most popular.
Requests
Requests is a library for Python that lets you easily send HTTP requests. You need to download the HTML with an HTTP client before you can parse it with something like Beautiful Soup or MechanicalSoup. With Requests, you don’t need to manually add query strings to your URLs or form-encode POST data. This tutorial on using Requests for web scraping will help you get started.
Beautiful Soup
Beautiful Soup is a popular Python library for parsing HTML and easily navigating or modifying a DOM tree. Extracting HTML and XML elements from a web page requires only a few lines of code, making it ideal for tackling simple scraping tasks with speed. You can learn how to use Beautiful Soup for web scraping here.
MechanicalSoup
MechanicalSoup is great for automating interaction with websites, clicking links, filling in forms, and storing cookies. It doesn’t, however, execute client-side JavaScript. That means it might not be the best bet for complex websites which need this to load paginated data.
Scrapy
Scrapy is among the most popular tools for extracting data from websites. Scrapy is a full-fledged web scraping framework that can use the previously mentioned libraries to extract data from web pages. It allows you to scrape multiple pages in parallel and export the data into a format of your choice. You can learn how to use Scrapy here.
Selenium
This browser automation tool, primarily developed for web testing, is commonly used for web scraping. It uses the WebDriver protocol to control headless browsers, and its ability to render JavaScript on a web page makes it helpful for scraping dynamic websites (most modern websites use JS to load content dynamically).
That being said, given it was not designed for web scraping, it isn’t the most user-friendly option. If you’re new to web scraping, Beautiful Soup is much easier to set up and master. Another notable disadvantage of Selenium is that it isn’t ideal for large-scale extraction, as scraping large amounts of data with Selenium is a slow and inefficient process compared to other options out there.
Playwright
Although it’s a fairly new library, Playwright is rapidly gaining popularity among developers due to its cross-browser and multi-language support, ease of use, and other cool modern features. While it’s primarily for controlling browsers rather than a web scraping tool, its versatility and auto-awaiting function make it a very popular choice for web scraping.
Ready to begin scraping?
Our web scraping with Python tutorial is packed with information and shows you how to get started, so if you’ve got your heart set on Python, check it out.




