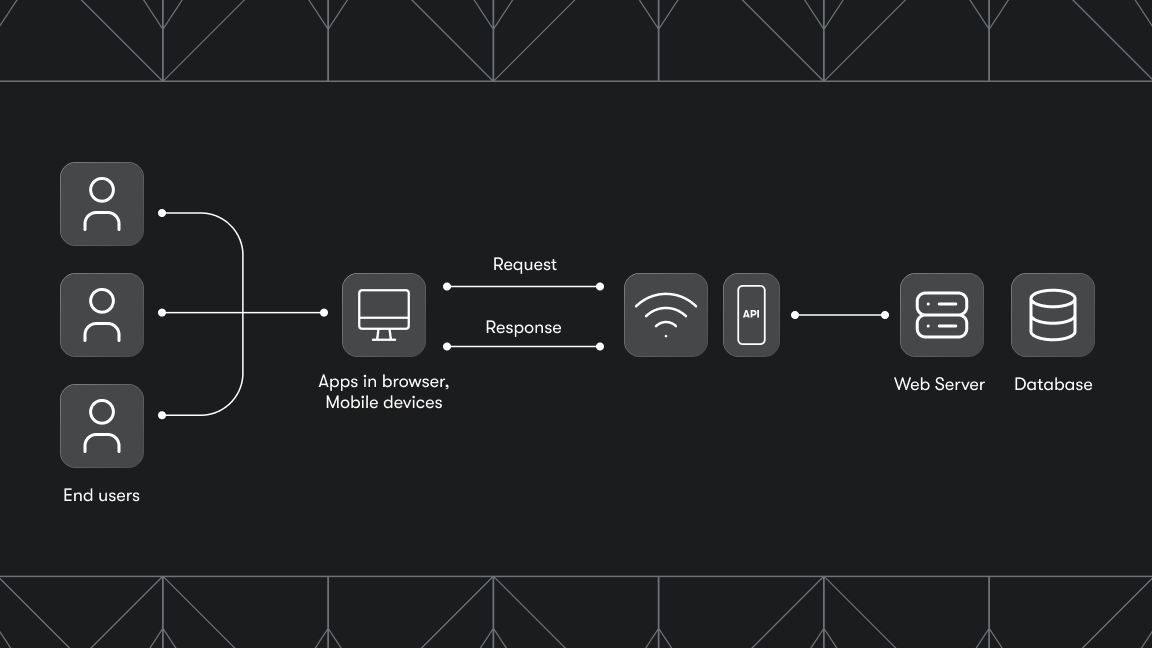
Data extraction, also known as web scraping, is the process of collecting raw data from a website and replicating it elsewhere. Despite the word ‘extraction,’ which may give the false impression that there’s some sort of theft involved, web data extraction just involves copying data so it can be stored, processed, and repurposed.
Web pages are unstructured data sources. That’s fine for humans, but for computers to process that information, the data needs to be stored in a language that machines can understand, which is to say, in a structured format. The purpose of data extraction is to make all that unstructured web data structured. That way, it can be processed by data analysis tools or integrated with computer systems.
Why extract data from the web?
The web is by far the largest library of information the world has ever known. It holds vital data for a range of industries, including:
- Machine learning
- Lead generation
- Sentiment analysis
- RPA - robotic process automation
- Price comparison
- Market research
- Product development
- Generative AI
Let's take, for example, training large language models - the largest and most reported use case of data extraction to date. The data used to train GPT was 575 gigabytes of data from the web (an unfathomable amount when you consider that it was just words, not images and videos). Every link in every web page was crawled, and the text was scraped. Then the process was repeated, with every link systematically followed until every piece of written content on the web was extracted. Without web scraping software and automated methods of data collection, this feat would have been simply impossible.
Training LLMs is not the only example of large-scale web scraping. While GPT is undoubtedly the biggest case of data extraction the world has ever seen, there are plenty of other industries, such as e-commerce, that benefit from collecting web data on a huge scale.
That's not to say that web data extraction is only for the largest of scraping projects. Any task that involves finding relevant web data, automating its collection, and storing it for processing, is a job for data extraction tools.
How does data extraction work?
We can break down the data extraction process into six main steps:
1. Find the URLs you want to scrape
In most cases, data extractors are given one or more URLs from which to scrape data. The scraper will then extract all the data or the data you've specified. The URLs you choose will depend on the purpose of your project. For example, if your goal is price comparison, extracting Amazon product data might be a good place to start.
2. Inspect the page
Before coding a scraper, you need to tell it what data to extract. Even if it seems obvious to you where the data is on a web page, a computer needs very precise instructions to find what you want. To start with, you need to inspect the web page with DevTools. Every major browser has them. If you want to open Chrome DevTools, for example, just press F12 or right-click anywhere on the page and choose Inspect.
3. Locate the data you want to extract
Now you have to choose the data you want to scrape (product reviews, for example). You'll need to identify the unique selectors that contain the relevant content, such as <div> tags. Attributes such as classes or IDs make them unique and these are what you need to look out for. For instance, if product reviews are contained within a <div> tag with a class of review-item, you would instruct your web scraping tool to find all <div> elements with that class to scrape the reviews.
4. Write the code
Now that you have your tags, you can incorporate them into your scraping script with your chosen data extraction software and specify the types of data you want the extractor to parse and store. If you're looking for book reviews, for example, you'd want to extract things like the title, author name, and rating.
5. Execute the code
Now you can execute your code so the scraper will begin the data extraction process, a process which we can summarize in 3 steps:
- Make an HTTP request to a server
- Extract and parse the website’s code
- Save the data locally
6. Store the data
After collecting the data you want, you need to store it somewhere for further use. You can add extra lines to your code to instruct your scraper to store the data in your desired format, be it Excel, CSV, or HTML.
Monitoring the extraction process
That's the data extraction process in a nutshell, but an extra step that is important in long-running large-scale scraping projects is to monitor your scraper.
You may encounter problems, such as blocking, the HTML moving to another page, and resource usage. It's best to test your scraper with a small dataset first and identify problems and bottlenecks before you move to a larger dataset.
You won't get everything right the first time. You'll need to iterate and adjust the scraper as needed. So scrape it till you make it!
Data extraction tools
Now you know the basic process of data extraction, it's time to show you some of the best tools to use for your web scraping projects. We've divided them into HTTP Clients, HTML and XML parsers, browser automation tools, and full-featured web scraping libraries. Which you choose to use and combine depends on the nature of your project.
🧰 HTTP Clients
You need HTTP Clients to send requests to servers to retrieve information, such as the website's HTML markup or JSON payload. Here are a few popular options to choose from:
- Requests (Python)
Dubbed “HTML for humans”, Requests is the most popular HTTP library for the Python programming language. It's easy to use and great for simple data-collection tasks.
- HTTPX (Python)
Though similar to Requests in functionality and syntax, HTTPX offers a few features that Requests doesn't have: async, HTTP/2 support, and custom exceptions.
- Axios (Node.js)
If you prefer JavaScript, then you might want to try Axios. It's a promise-based HTTP Client capable of making XMLHttpRequests from the browser and HTTP requests from Node.js.
- Got Scraping (Node.js)
Got Scraping was designed primarily to tackle anti-scraping protections. It offers out-of-the-box browser-like requests to blend in with the website traffic and reduce blocking rates.
🖥 HTML and XML parsers
You need HTML and XML parsers in data extraction projects to interpret the response you get back from your target website, usually in the form of HTML. Two popular options are Beautiful Soup and Cheerio.
- Beautiful Soup (Python)
Beautiful Soup can parse nearly any HTML or XML document with a few lines of code. Comparatively easy to use, it's a lightweight and popular Python option for doing simple data extraction quickly.
- Cheerio (Node.js)
The most popular and widely-used HTML and XML parser for Node.js, Cheerio is highly efficient and flexible for data extraction, provided you don't need to scrape web pages that require JavaScript to load their content.
💻 Browser automation libraries
Browser automation libraries can come in very handy for data extraction. They can emulate a real browser, which is essential for accessing data on websites that require JavaScript to load their content. Here are three popular options to choose from:
- Selenium (multi-language)
A Python framework with cross-browser support and multi-language compatibility, Selenium is a popular choice for data extraction due to its ability to render JavaScript.
- Playwright (multi-language)
A Node.js framework also with cross-browser and multi-language support, Playwright is similar to Selenium but with some extra features, such as its auto-await function. This means it waits for elements to be actionable before performing actions, eliminating the need for artificial timeouts.
- Puppeteer (Node.js)
Effectively the predecessor of Playwright, Puppeteer is similar, but doesn't have its multi-language flexibility. Like Selenium and Playwright, Puppeteer's ability to emulate a real browser allows it to render JavaScript. That makes it a useful tool when you need to extract data from pages that load content dynamically.
📚 Full-featured web scraping libraries
Full-featured web scraping libraries are the most powerful and versatile data extraction tools in a developer's arsenal. Both Scrapy and Crawlee fall into this category and are great options for web scraping at any scale.
- Scrapy (Python)
Scrapy offers a complete suite of tools to help you even in the most complex data extraction jobs. You can also integrate it with data-processing tools and even other libraries and frameworks like those we have already mentioned.
- Crawlee (Node.js)
Crawlee builds on top of many of the previously mentioned libraries and frameworks (Got Scraping, Cheerio, Puppeteer, and Playwright) while providing extra functionality tailored to the needs and preferences of web scraping developers. An all-in-one toolbox for data extraction, Crawlee lets you switch between the available classes, such as CheerioCrawler, PuppeteerCrawler, and PlaywrightCrawler, to quickly access the features you need for each specific data extraction task.
Learn more about data extraction tools
If you want to delve deeper into the features of the above-mentioned data extraction tools, look at code examples, and see how they work in practice, you can learn more in the tutorials below.
Extracting data with Python
🔖 Web scraping with Python Requests
🔖 Web scraping with Beautiful Soup
🔖 How to parse JSON with Python