


There are times when the amount of data you need from a website and the speed at which you need to collect it is more than the average web scraping tool can handle. If you want to extract data from a thousand or even tens of thousands of web pages, normal scraping will get the job done. But what if we're talking about millions of pages? That requires a different workflow.
Large-scale scraping involves extracting data from huge or complex websites. It could involve extracting millions of pages monthly, weekly, or even daily.
We'll show you how to overcome the challenges of collecting data from such websites. But first, it would be helpful to know when you need a large-scale scraping workflow. To answer that, let's first clarify what a normal workflow looks like.
A normal web scraping workflow
Step 1. Open the homepage of the target website
For this example, we'll choose the website fashionphile.
Step 2. Enqueue top-level categories
Let’s click on the bags category and choose 'Shop all bags'.
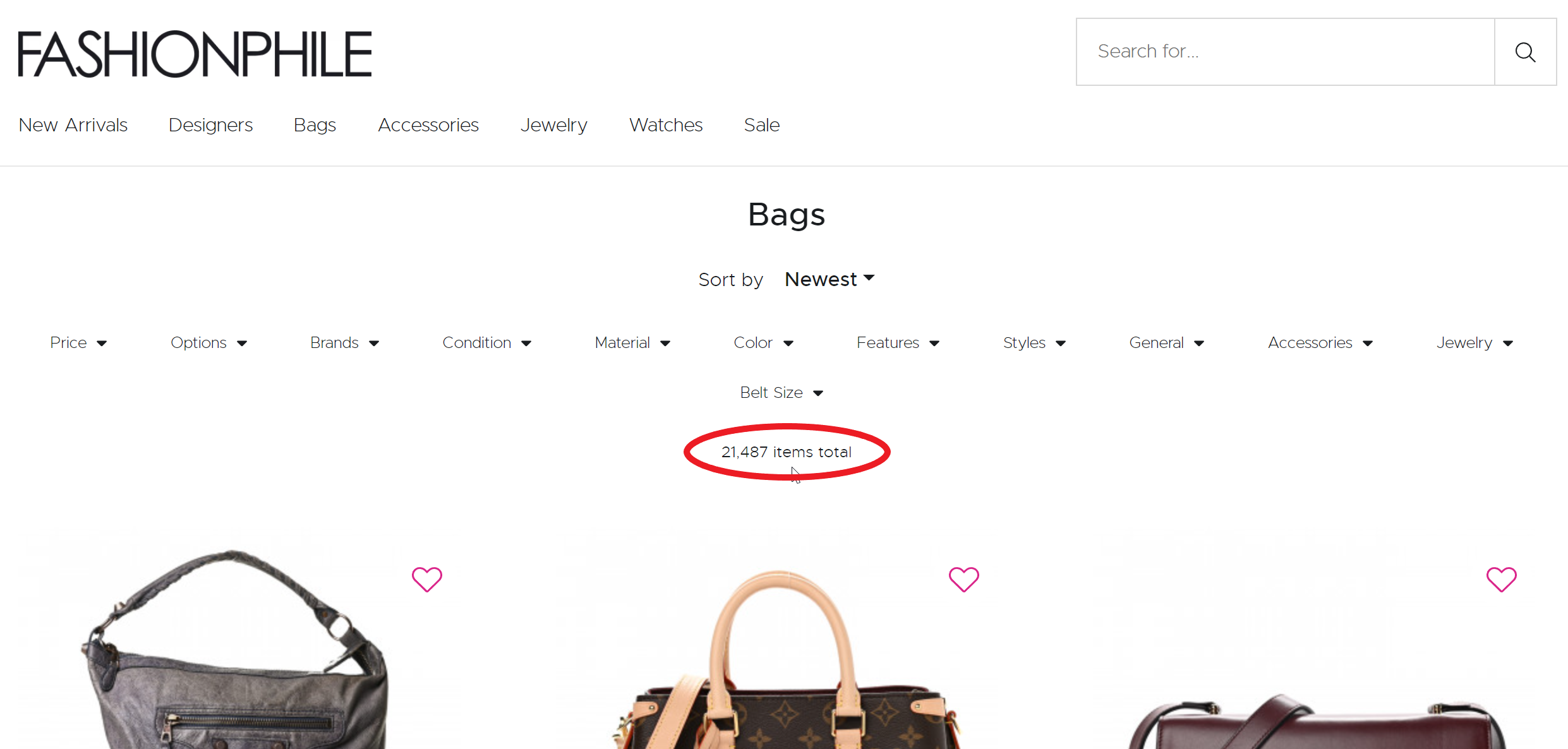
The total number of bag items on the site is 21,487, so we know that the maximum number of items we want to scrape is 21,487.
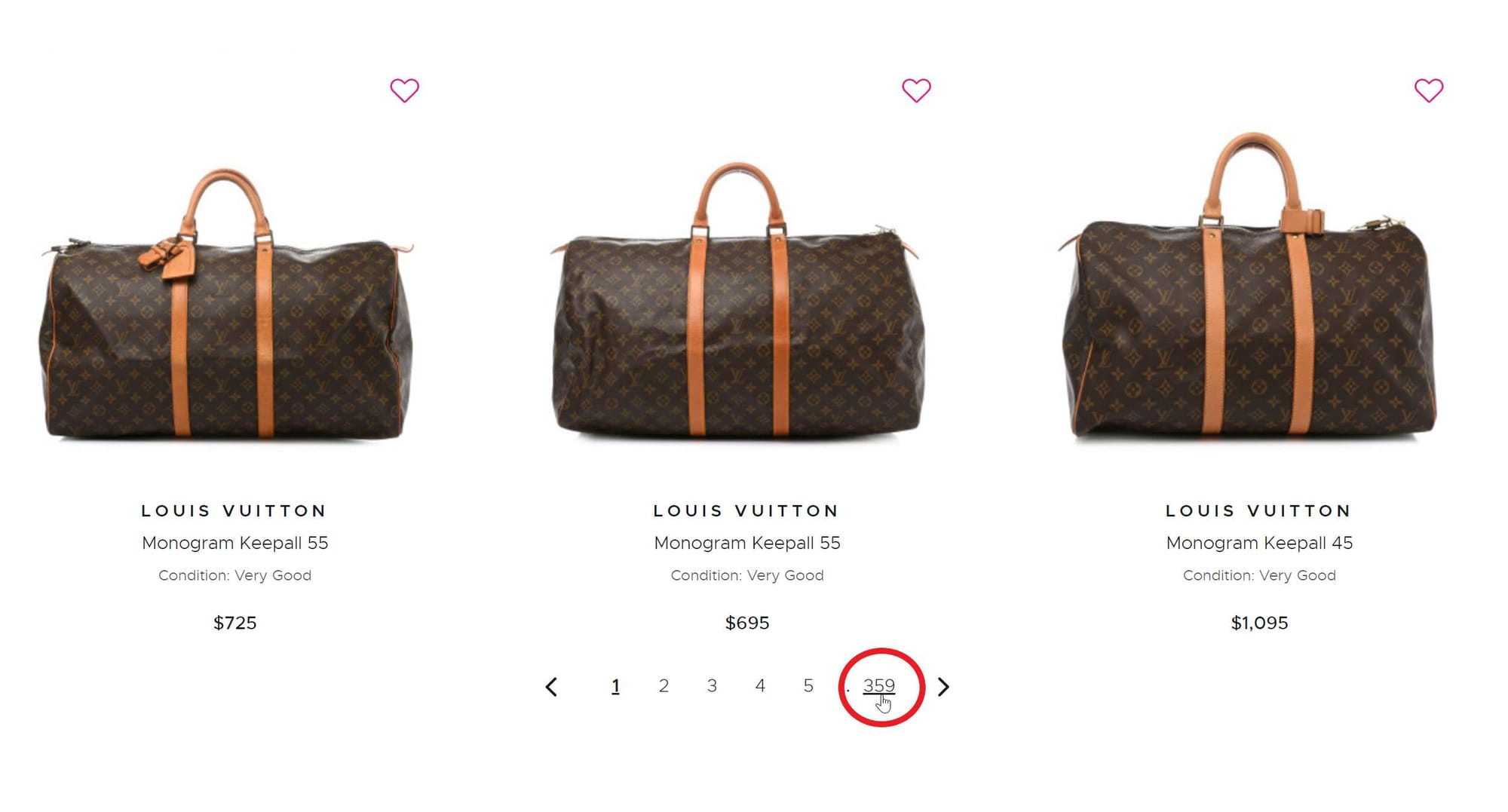
If you scroll to the end of the page, you'll see the total number of pages for the bags category: 359. So, 359 pages contain 21,487 items.
Step 3. Scrape each product detail
You can now scrape product details such as brand names, bag colors, price ranges, and so on. For example, Louis Vuitton bags are priced between $1,000 and $2000.
Step 4. Run on a single server
With this information, you can run a scraper to extract the data you're looking for.
So, why does this not work for very large or complex websites, like Amazon? Because:
- There's a limit to the number of pages shown in pagination
- A single server is not big enough
- Default proxies might not scale
Here's how to solve these problems.
How to solve the challenges of large-scale scraping
1. Handle pagination limits
The pagination limit on large e-commerce websites, like Amazon, is usually between 1,000 and 10,000 products. Here’s a three-step solution to this limitation:
- Use search filters and go to subcategories
- Split them into price ranges (e.g., $0-10, $10-100)
- Recursively split the ranges in half (e.g., split the $0-10 price range into $0-5 and $5-10)
2. Overcome limited memory and CPU
Since there's a limit to making the server bigger (vertical scaling), you need to add more servers (horizontal scraping). This means you have to split runs across many different servers, which will run in parallel. However, managing this distributed system can become challenging, as system data takes so much processing power and coordination to keep everything running smoothly across multiple servers. This is how to do it:
- Collect products and redistribute them among servers
- Create servers as needed
- Merge the results back into a single dataset, and then unify and deduplicate using the Merge, Dedup & Transform Datasets Actor (accessible on Apify Store).
3. Choose the right proxies
Your choice of proxy impacts your web scraping costs. Datacenter proxies are likely to get banned if you are scraping at scale. Residential proxies are expensive. So the best solution is to combine datacenter proxies, residential proxies, and external API providers.
This is why Apify provides a super proxy that wraps multiple third-party providers. It rotates between them to ensure higher reliability. If one provider fails, requests are routed to others, making it more dependable than relying on a single source.

Remember: Don't overload the website
Before you begin any large-scale data collection project, be aware of what the target website can handle. There’s a big difference between scraping a large website like Amazon and scraping the site of a small, local business. A website that is not used to huge traffic may not be able to cope with a large number of requests sent by bots. Not only will this skew the company’s user statistics, but it could also cause the website to run slower and even crash. So, play nice and don‘t overburden your target website. If in doubt, do a little online research to find out how much traffic the website receives.
In summary
Large-scale scraping is complicated, so remember:
- Plan before you start
- Minimize the overload on web servers
- Extract only valid information
Need help with large-scale scraping? Apify has extensive experience in overcoming the challenges posed by complex websites. If large-scale data extraction is what you need, contact Sales for a demo or custom-made solution.




