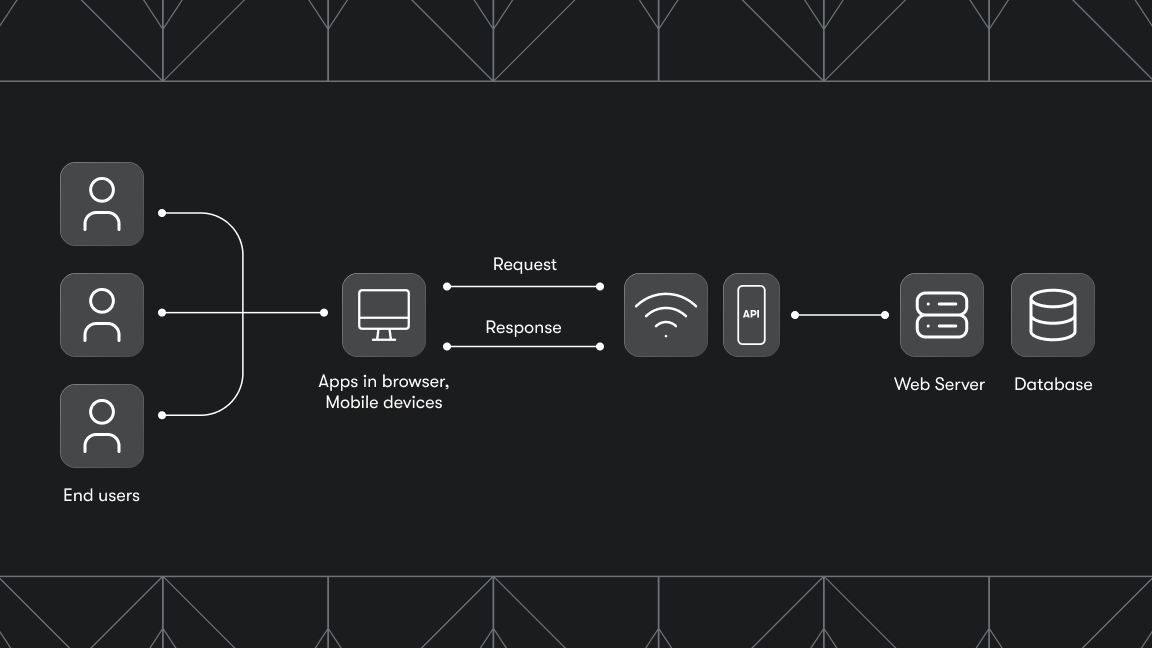
What is a web crawler?
Imagine you’re looking for a book in an enormous library. You might search the shelves' categories, genres, and authors to find it. If you haven’t found what you’re looking for, you can ask the librarian to check the files to see if the book is there and where to get it. The library stores information about the books, such as title, description, category, and author. This makes it easy to find books when you need them.
The internet is a library, and even though it’s by far the most extensive library in history, it has no central filing system. So how do we get hold of the information we‘re looking for? The answer is web crawlers.
Web crawlers, also known as site crawlers, can fulfill two functions:
Web indexing (or web spidering)
Web crawlers systematically browse the web to index content for search engines. In this sense, web crawlers, also known as web spiders or spiderbots, are the librarians of the world wide web. They index all the pages on the internet by using automated scripts or programs so we can find information quickly.
Web scraping
Web crawlers are also used by companies other than search engines to retrieve web information. This is known as web scraping or web data extraction. Web scraping involves using web crawlers to scan and store content from a targeted webpage to create a dataset, be it product prices for e-commerce or finance news for investment analysis.
How do web crawlers work?
Before crawling a webpage, web spiders check the page's robots.txt file to find out about the rules of that specific page. These rules define which pages the crawler can access and which links they can follow. Then they start to crawl by using a set of known URLs. The spiders follow the hyperlinks contained in those pages and repeat the cycle on the newly found websites. The crawler's goal is to download and index as much content as possible from the websites it visits. We could sum this up as a simple three-step process.
- 1. A web crawler downloads the website's robots.txt file.
- 2. It crawls a page and discovers new pages through hyperlinks.
- 3. It adds URLs to the crawl queue so that they can be crawled later.
What do Google web crawlers do?
If web crawlers are the librarians of the web, then Google is the closest thing we have to a central filing system. Google web crawlers explore publicly available web pages, follow the links on those pages, and crawl from link to link. They bring the data back to Google’s servers, and the information is organized by indexing.
Search indexing is like creating a library catalog. This makes it possible for search engines like Google or Bing to know where to retrieve information when we search for it. The most extensive search index is the Google Search index. It contains hundreds of billions of web pages with entries for each word every page includes.
What does web crawling do for SEO?
SEO stands for search engine optimization. Content that makes it easy for web crawlers to identify the relevance of your page for search queries is search-engine-optimized content. Web crawlers determine whether your page has information relevant to the question that people insert into search engines. They can ascertain whether your content is likely to provide the answer you‘re looking for and whether it‘s a copy of other online materials.
If your page appears to answer those questions and contains hyperlinks relevant to those inquiries, it improves the likelihood that your content will appear on the first page of Google when you enter a query in the search engine.
One of the biggest obstacles to achieving this is broken links since following hyperlinks is essential for crawlers to index web pages. Google web crawlers are unforgiving creatures. When they identify broken links, they make digital notes and lower the website’s rating. That means there‘s less chance of people finding your web page.
Web crawlers vs. web scrapers
While both terms - web crawling and web scraping - are used for data collection, there‘s a difference. Web scraping is a more targeted form of crawling to extract structured data from web pages. This can be achieved either with a general web scraper like this one which crawls arbitrary websites, or with a bot explicitly designed for the target website.
Even with a general scraper, it’s possible to extract data from websites without crawling them, assuming you already have a specific target website or list of URLs. For example, this web scraping tutorial for beginners shows you how to extract data from CNN.
How to build a web crawler
To build your own web crawlers, you need to know a programming language such as JavaScript or Python. You can use an open-source web scraping library to build your crawlers.
The architecture of a self-built crawler system is made up of six steps:
- 1. Seed URL (the initiator URL)
- 2. URL frontier (rules the crawler must follow)
- 3. Fetching and rendering URLs (retrieving the required data)
- 4. Content processing (downloading and storing pages for further use)
- 5. URL filtering (removing or blocking certain URLs)
- 6. URL loader (determining whether a crawler has crawled a URL)
Tips for web crawling
Before you begin, keep in mind that websites employ different techniques to manage crawler traffic. For example, browser fingerprinting is a technique that can be used to identify web browsers and collect information about visitors in order to detect non-human traffic and block a bot's IP address. To avoid detection, remember to rotate your IP addresses and change your browser fingerprints.
Proxy management and browser fingerprint generation are two things you can automate with the web scraping library, Crawlee, so be sure to check it out!