Apps rely heavily on web data, especially when you want to train your AI tools, power competitive pricing engines, or feed event-driven systems. One way to get that data is by building your own web scraping tools, but this approach can easily become a constant battle: you have to handle rotating proxies, CAPTCHAs, and headless browsers, while your requests might still get throttled or blocked as anti-bot systems evolve.
That’s why many developers turn to web scraping APIs. Instead of managing proxies, fingerprints, and infrastructure, you can offload the whole pipeline to an API built to survive modern bot defenses. With a single request, you get structured, reliable data - rendered pages, JavaScript-heavy sites, even those with aggressive blocking. With a good scraping API:
- You can prototype in minutes
- You don’t need scraping expertise up front
- You avoid weeks of trial-and-error tuning
In this guide, we’ll compare the top web scraping APIs for developers in 2026, focusing on features, pricing, and overall developer experience.
Top 11 web scraping APIs for 2026
1. Apify
Apify is a platform for web scraping and automation that lets developers turn any website into an API, providing access to a library of 10,000+ pre-built scrapers. The Apify API facilitates scalable and efficient data extraction and management.
Developers can also build their own scrapers and data APIs in Apify Console using templates or custom code, and monetize them through Apify Store. The platform provides an open-source SDK, cloud runtime with scheduling, scaling, and monitoring.
- Built-in proxy management
- Anti-bot evasion support
- Integrated storage with structured exports in CSV/Excel/JSON
- Input configuration schema with standardized parameters (URLs, keywords, limits, etc.)
- REST API endpoint for start, stop, and data retrieval
Each Apify Actor is effectively a web scraping API that targets popular websites. They can be used with the default settings or as a starting point for custom scraping projects.

Pricing: Flexible pricing with pay-as-you-go options: Starter plan from $29. There’s also a forever-free tier with $5 monthly to spend on Apify Store or on your own Actors.
Pros:
- Apify Proxy is completely integrated into the platform and runs seamlessly in the background for most scraping tasks
- Apify was designed by devs for devs, so you can fetch from a repository, push code from your local computer, or use the online code editor
- Apify scrapers can use all popular libraries, including Python and JavaScript frameworks and toolsets such as Scrapy, Selenium, Playwright, and Puppeteer. Apify also maintains an open-source web scraping and browser automation library for Node.js, Crawlee
- Includes scheduling, monitoring, and management tools for long-running scraping jobs.
- Designed to handle large volumes of data
- Flexibility - you can define custom scraping tasks using JavaScript or Python, or choose a pre-built scraper from Apify Store
- Full-featured cloud-based infrastructure that eliminates the need for separate hosting solutions
- An active developer community on Discord, which makes it easier for users to find solutions to their problems and connect with other like-minded web scraping enthusiasts
- Multiple data formats to export, such as JSON, CSV, or Excel, making it versatile for different data processing needs
- Pre-built external integrations with services like Gmail, Google Drive, Make, Zapier, and more. By utilizing the Apify API and running scrapers on their platform, users can leverage these integrations for enhanced functionality and productivity
Cons:
- A steeper learning curve for users who are new to web scraping or API integrations and prefer a plug-and-play solution - you need to learn how Actors are built and configured first
2. Oxylabs
Oxylabs offers both industry-specific scraping APIs (SERP, e-commerce, real estate) and a more flexible general-purpose Web Scraper API, that can be adjusted to scrape virtually any website with the optional Headless Browser feature. The APIs are tightly integrated with one of the largest residential and mobile proxy networks available, allowing developers to offload IP rotation, geotargeting, session management, and blocking mitigation to a managed service. Oxylabs is primarily designed for high-volume, production-grade scraping.
Pricing: Micro plan starts at $49 + domain-specific result cost (e.g., successful results with JS rendering cost $1.35 per 1k results). A free trial is available for up to 2,000 results.
Pros:
- Extensive residential and mobile proxy networks - important for high-volume and hard-target scraping
- Production features such as rotating proxies, session persistence, geotargeting, CAPTCHA handling, JavaScript rendering, and automatic retries are included
- Oxylabs focuses on high success rates and consistent response formats, with retry logic and enterprise-grade SLAs on higher-tier plans
- Headless Browser feature as a part of the Web Scraper API allows rendering JavaScript and extracting data from complex web pages
Cons:
- Oxylabs doesn’t offer full control over custom crawling logic, which might be limiting for advanced or highly customized scraping workflows
3. Scrapingdog
Scrapingdog is an API-first web scraping service designed for developers who want fast setup and predictable behavior on common scraping targets. It handles proxy rotation, JavaScript rendering, and basic anti-bot defenses, returning structured JSON responses for both general scraping and popular platforms such as Google Search, Amazon, LinkedIn, Walmart, and X.
Instead of a single highly flexible endpoint, Scrapingdog focuses on dedicated, purpose-built APIs that handle common scraping scenarios with minimal configuration.
Pricing: Lite plan starts at $40 monthly with 200,000 credits, where API requests cost you a different amount of credits (e.g., Google SERP API - 5 credits, Profile Scraper - 50 credits).
Pros:
- Cost-effective for common targets - pricing scales with usage, making it attractive for startups, internal tools, and high-volume but predictable scraping workloads
- API is easy to integrate and well-documented, allowing developers to get usable data with minimal setup. Parsed JSON responses reduce the need for custom logic
- Performs well on mainstream sites such as search engines and major e-commerce platforms
Cons:
- Scrapingdog’s reliance on dedicated endpoints can be restrictive for complex or unconventional scraping tasks. Developers needing fine-grained control over crawling logic, request sequencing, or custom parsing may find the API limiting

4. ScrapingBee
ScrapingBee is a lightweight web scraping API focused on simplicity and reliability. It handles proxy rotation, JavaScript rendering, and CAPTCHA challenges behind a single HTTP endpoint, making it easy to integrate into existing applications and data pipelines. It’s designed for developers who want a drop-in scraping API without managing infrastructure or building custom scrapers. You control behavior through request parameters (for example, enabling JS rendering or adjusting timeouts), while the service decides how to fetch the page reliably. The result is a rendered HTML response or extracted data that can be plugged directly into existing applications.
Pricing: Starts at $49 for the Freelance plan, with 250,000 credits and 10 concurrent requests
Pros:
- ScrapingBee’s intuitive API design and clear documentation make it easy to use for developers at any experience level. Most scraping tasks require minimal configuration
- The API automatically manages IP rotation, CAPTCHA solving, and browser rendering
- Usage-based pricing requires little upfront setup or cost, making it suitable for prototyping, internal tools, and small-to-medium production workloads
Cons:
- Limited control over scraping logic - especially if you need advanced crawl control, multi-step workflows, or custom extraction logic
- No cloud execution, job scheduling, or workflow management. These must be implemented externally by the user
5. Zyte
Zyte is a web scraping and data extraction platform that utilizes machine learning to automate and enhance the scraping process. While Zyte originally built its reputation around the Scrapy framework, its offering is now centered on API-driven scraping and automatic data extraction, with infrastructure and anti-bot mitigation handled for you
Developers can interact with Zyte through high-level APIs that return structured data, or use the lower-level tooling for more control
Pricing: From $0.06 per 1,000 successful responses, depending on monthly commitment and website complexity
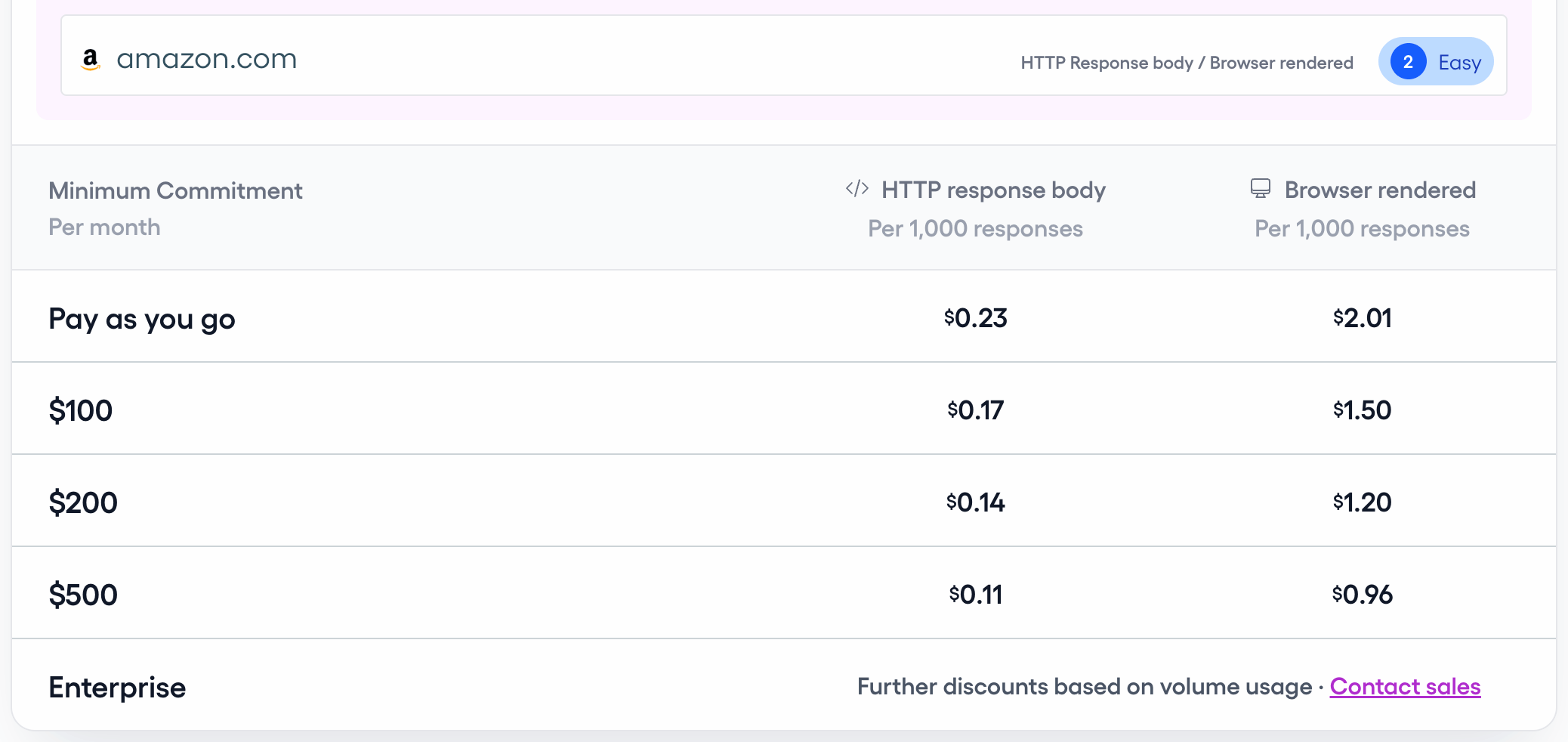
Pros:
- Automatic structured data extraction without the need for custom parsing logic
- Zyte runs scraping workloads in the cloud, handling proxy rotation, retries, browser rendering, and blocking mitigation behind the scenes. This makes it well-suited for large-scale or hard-to-scrape targets
- Advanced users can still leverage Scrapy for custom spiders and fine-grained control, while others can rely entirely on Zyte’s APIs without writing scraping logic themselves
Cons:
- Developers who choose to work directly with Scrapy or advanced configurations may face a steeper learning curve compared to simpler, API-only scraping services
- Zyte’s pricing spans multiple products and usage metrics, which can make cost estimation difficult. Combining extraction, proxies, and additional services may lead to higher-than-expected costs without careful planning
6. Bright Data
Bright Data, a well-known proxy provider, offers an API marketplace, which focuses on providing specialized APIs for popular websites such as Amazon, YouTube, LinkedIn, and Instagram. Works well for projects where data is needed fast, and the site you’re targeting is already supported. Another standout feature of Bright Data is its dataset marketplace, where users can purchase custom datasets from specific websites, eliminating the need to engage in the scraping process altogether.
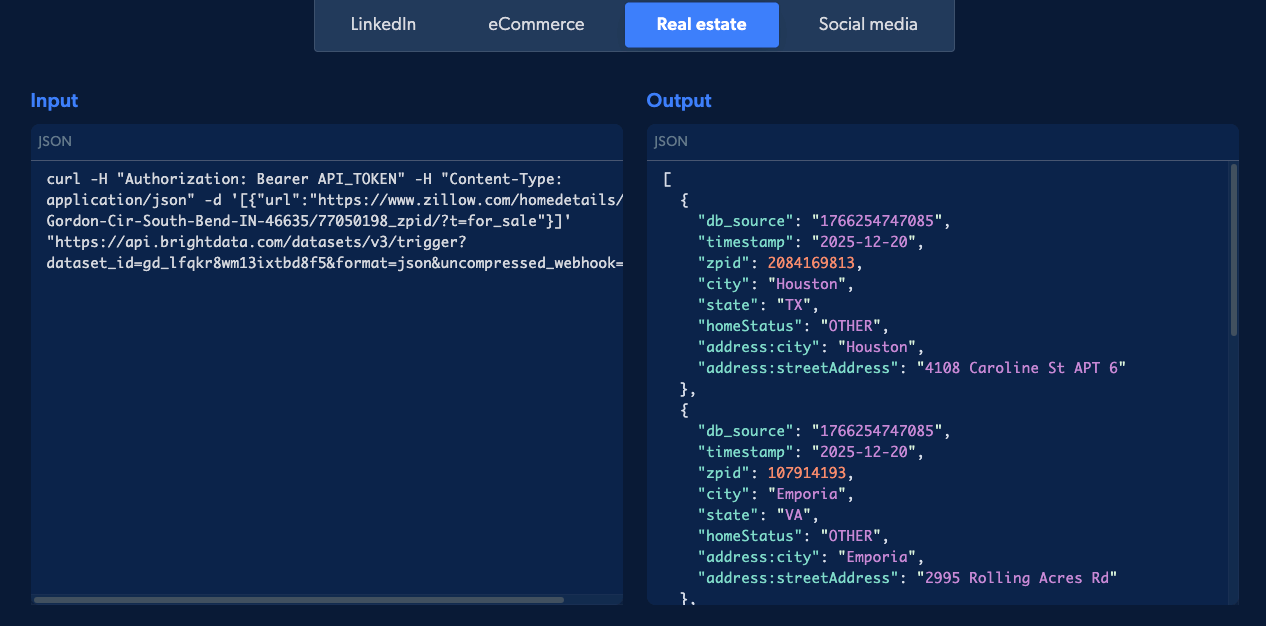
Pricing: Pay-as-you-go plans starting at $1.5 per 1,000 results.
Pros:
- Bright Data operates the largest and most diverse proxy network available, including residential, mobile, ISP, and datacenter IPs across nearly every geographic region. This makes it especially effective for geo-sensitive and heavily protected targets
- The infrastructure was built for scale and supports massive concurrency and throughput, making it a good choice for larger projects such as SERP monitoring, price intelligence, and AI dataset generation
- The platform offers JavaScript rendering, CAPTCHA handling, session control, and detailed request configuration. Developers have significant control over how scraping is performed, which is useful for complex or non-standard targets
Cons:
- If you need to target a site not included in the API library or customize logic, you'll need to switch to the Web Scraper IDE, which is browser-based only
- There’s no official support for local development, CLI deployment, GitHub workflows, or version control
- Bright Data’s breadth comes at the cost of complexity - getting from prototype to production can require careful configuration and platform-specific knowledge
7. Scrape.do
Scrape.do is a web scraping API with a deliberately minimal surface: one HTTP endpoint, a target URL, and query parameters for every advanced behavior. The same endpoint accepts a URL whether the target is a static page, a JavaScript-heavy SPA, or a geo-gated e-commerce catalog.
That API shape has two practical consequences. First, integration is trivial: any language with an HTTP client (curl, requests, fetch, Go's net/http) can call Scrape.do without an SDK or wrapper, and existing scraping code can often be retrofitted by changing a single URL. Second, the response format is consistent across every domain, so there's no per-site branch in the calling code. Status codes follow normal HTTP semantics, and the API charges only for successful requests.
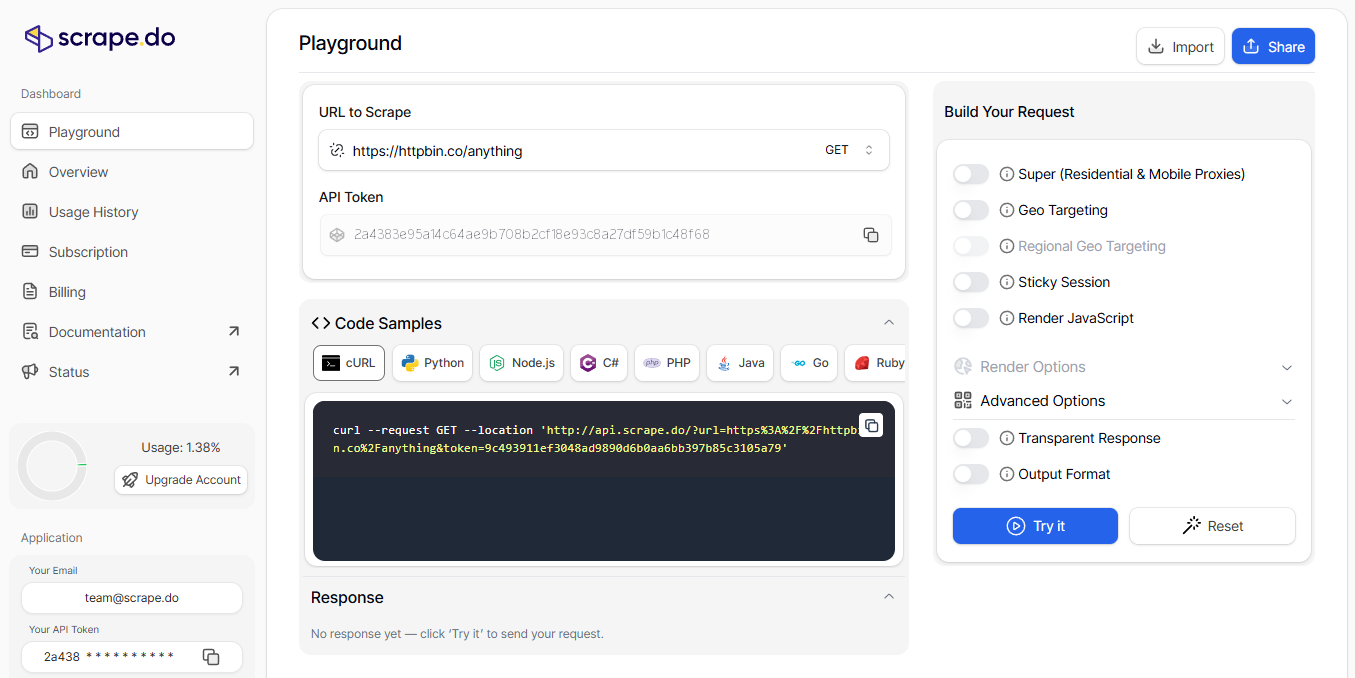
Pricing: Free forever plan with 1,000 monthly requests, no card. The Hobby plan starts at $29/month for 250,000 requests with all features included, which works out to roughly $0.12 per 1,000 requests at base rate. Effective cost per 1K drops further on larger plans. Credit multipliers apply on advanced calls: JS rendering costs 5 credits, premium proxies cost 10, and both together cost 25.
Pros:
- One endpoint, query-parameter API, works with any HTTP client and drops into existing codebases without an SDK
- Consistent response shape across every target domain, which removes per-site branching in calling code
- Billed per successful request only
- 110M+ IPs across datacenter, residential, and mobile pools covers most protected targets from the same endpoint
- Dedicated Google SERP API covers search results, AI Overviews, Shopping, Maps, and Trends with pre-parsed JSON, so SERP work doesn't require maintaining brittle DOM selectors
- Markdown output is a first-class return type, which removes a parsing step in LLM and RAG ingestion pipelines
Cons:
- Credit multipliers for tougher sites means your costs can increase significantly based on domain
- No marketplace for community created scrapers, limited structured output
- No pay-as-you-go and credit balance structure for flexible usage
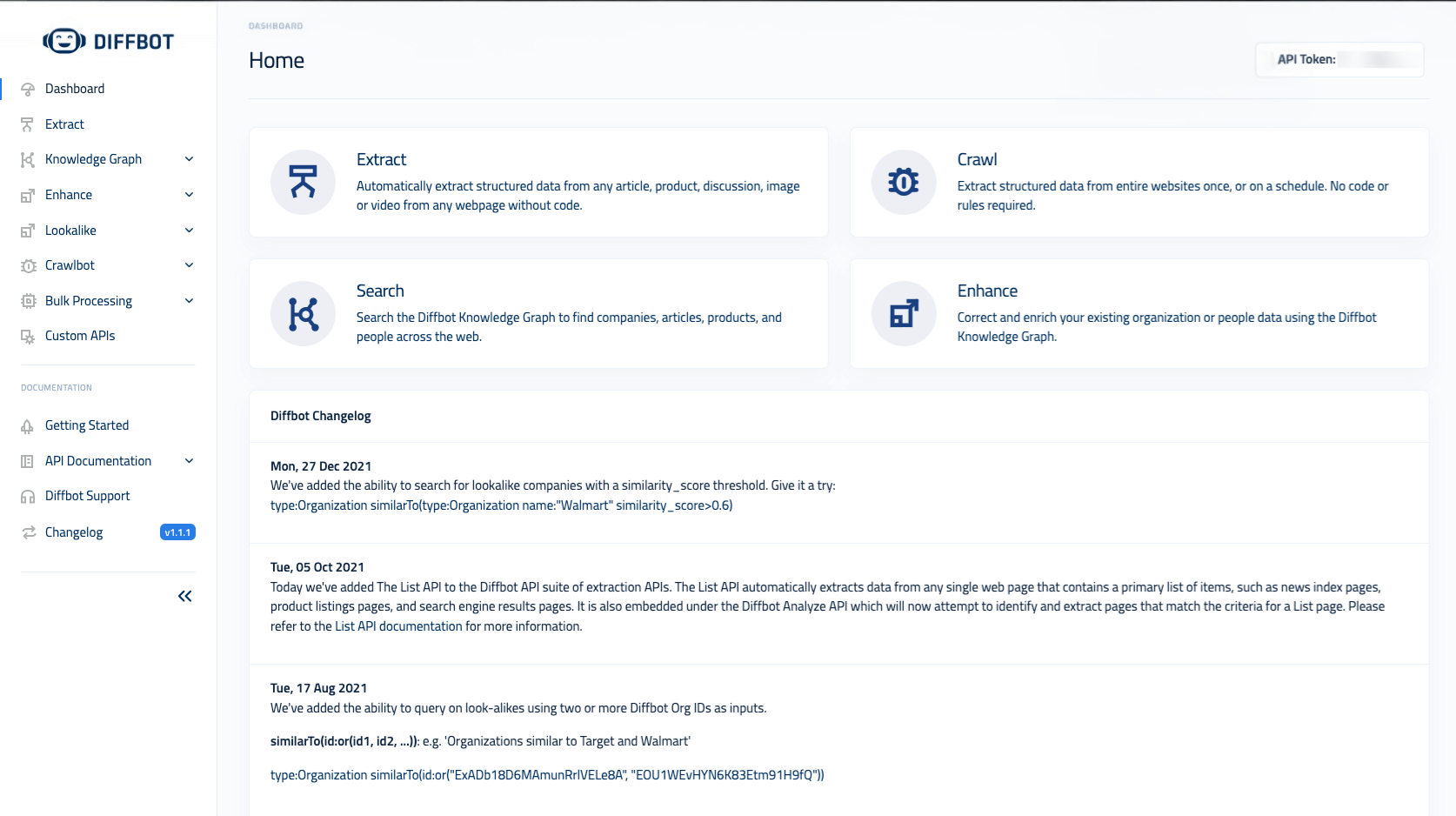
8. Diffbot
Diffbot analyzes a page’s structure to understand what kind of content it contains and automatically applies the right extraction model. At the core of Diffbot’s approach are two main API types:
- Analyze API inspects a page and determines its content type (article, product, discussion, etc.)
- Extract APIs - page-type-specific endpoints (Article, Product, Image, Video, Event, Job, and more) that return normalized, schema-based JSON output
For cases where the automatic models don’t extract everything you need, Diffbot also offers a Custom API. While it includes a visual configuration UI, it’s fully usable programmatically and lets developers extend or override extraction logic for specific domains.
Pricing: Startup plan at $299 per month, with a free tier available. All plans include a credit limit.
Pros:
- Diffbot handles page classification and data extraction automatically, so you don’t need to maintain brittle selectors or parsing rules. You send a URL and get structured data back
- Each Extract API returns standardized fields, which makes Diffbot especially useful for large datasets, analytics pipelines, and AI or NLP workflows where consistency matters
- Diffbot’s REST APIs are easy to integrate and fit well into existing systems as a pure data service rather than a full scraping platform
Cons:
- Diffbot is not a budget-friendly scraping tool. While there are entry-level options, large-scale extraction and bulk crawling are priced for professional and enterprise use cases
- Because Diffbot abstracts away most scraping mechanics, you have less control over navigation logic, multi-step flows, or highly custom extraction behavior. It works best for known page types
9. WebScrapingAPI
WebScrapingAPI is an API-based web scraping service that focuses on fast setup and minimal configuration. It offers both general-purpose scraping and site-specific APIs for common targets like Google Search and Amazon, returning ready-to-use responses without requiring you to manage scraping infrastructure.
The platform is designed for developers who want a drop-in scraping API rather than a full scraping framework.
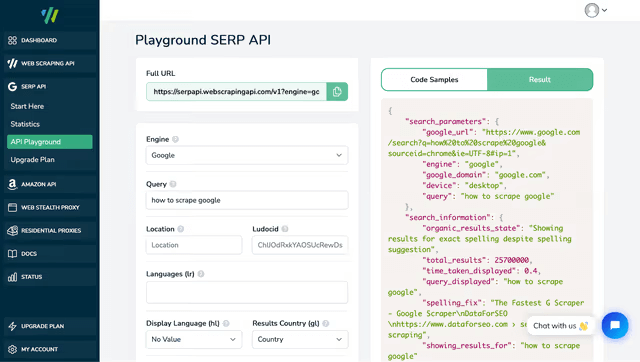
Pricing: Starter plan at $19 per month with a 7,000 call limit. Specific use cases (Google SERP or Amazon) cost extra.
Pros:
- Out-of-the-box solution - WebScrapingAPI handles browser execution, proxy rotation, JavaScript rendering, and basic anti-bot measures automatically. No infrastructure needed
- The API is well-documented, making it easy to add web data extraction to an application or internal tool with minimal setup
- Dedicated APIs work great if you only need data from a specific source (such as SERPs or a major marketplace)
Cons:
- WebScrapingAPI prices the general scraper and site-specific APIs separately. This can be cost-effective for narrow use cases, but costs may add up if you rely on multiple APIs at once, compared to platforms that bundle features into a single plan
- Developers who need multi-step navigation, custom crawling logic, or fine-grained control over requests may find it restrictive compared to code-centric scraping platforms
10. ZenRows
ZenRows is an API-first web scraping service designed to make JavaScript-heavy and dynamically rendered pages easier to scrape. It combines features that many other APIs sell separately under one umbrella: proxies, JavaScript rendering (headless browser), anti-bot bypass, IP rotation, fingerprinting bypass, structured output, and analytics - all accessible through a single Universal Scraper API. That means you can enable or disable capabilities per request without switching products or endpoints.
Also, instead of having separate credit buckets for each scraper or feature, ZenRows uses a shared balance system where your plan’s usage quota can be spent on any combination of tools (Scraper APIs, proxies, scraping browser, etc.).
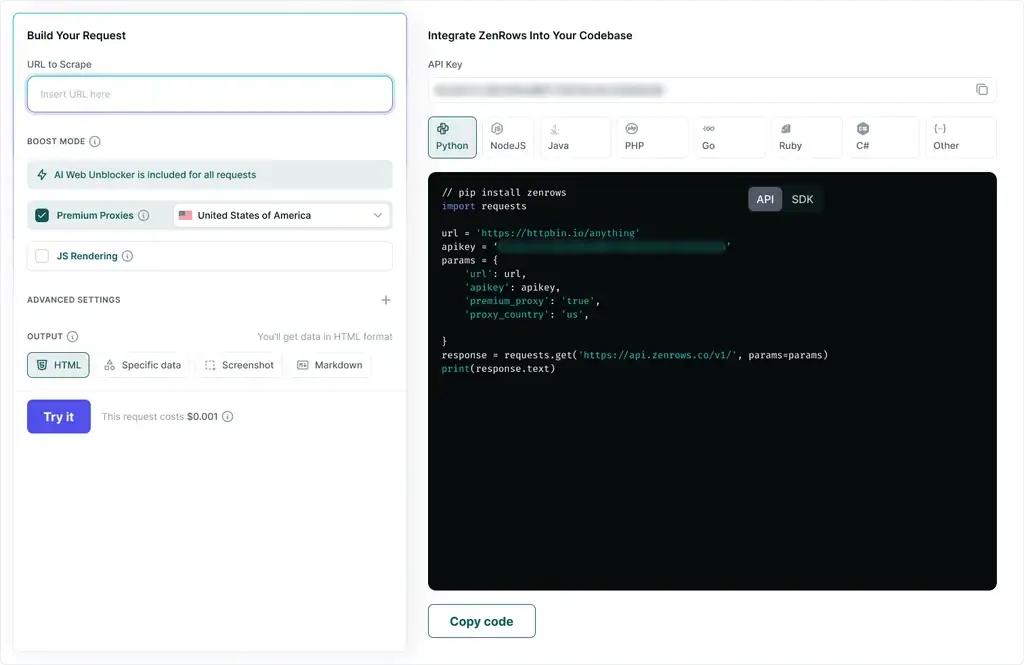
Pricing: Developer plan at €69 monthly for 250,000 basic results
Pros:
- ZenRows automatically renders pages, executes JavaScript, and navigates dynamic content, making it suitable for sites that break traditional HTTP-based scrapers
- Usage-based pricing model can be attractive for teams with variable workloads or sporadic scraping needs, as you pay primarily for what you use
- The API is easy to integrate, and responses are ready for consumption in downstream pipelines without requiring additional parsing
Cons:
- ZenRows abstracts most scraping mechanics behind its API, which limits customization for complex workflows, multi-step navigation, or highly specialized extraction logic
- No built-in orchestration or hosting - there’s no job scheduling, workflow management, or cloud execution for scraping tasks. Developers are responsible for running and coordinating scraping jobs within their own infrastructure
11. ScrapingAnt
ScrapingAnt is an API-first web scraping service designed for quick integration and minimal setup. It focuses on making it easy to extract data from JavaScript-rendered and dynamic websites without running your own browsers or managing proxy infrastructure.
ScrapingAnt sits in the same category as lightweight scraping APIs like ScrapingBee and ZenRows, offering a simple HTTP interface for fetching rendered pages and structured responses.
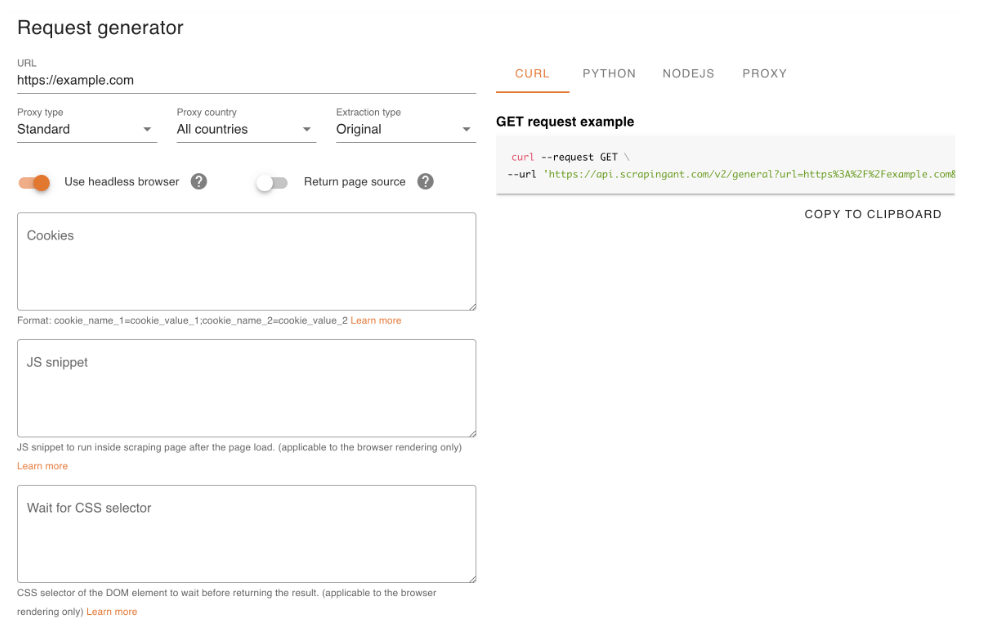
Pricing: Starting at $19 per month for the Enthusiast plan (100,000 API credits).
Pros:
- Handles dynamic and JavaScript-heavy pages, manages cookies, and renders dynamic content automatically
- Built-in anti-bot handling - the API includes proxy rotation, session management, and automated CAPTCHA handling, reducing the amount of scraping logic developers need to maintain
- Fast time to first request - ScrapingAnt’s API is well-documented, allowing developers to get results quickly without complex configuration or onboarding
Cons:
- Limited flexibility for complex workflows. Developers needing multi-step navigation, custom crawl logic, or advanced extraction pipelines may find it restrictive
- No orchestration or cloud execution - there’s no scheduling, workflow management, or hosted execution for scraping jobs. Users must run and coordinate scraping tasks within their own infrastructure
Find the best web scraping API for your needs
A solid web scraping API should do more than just fetch pages - it should reduce the amount of engineering work needed to process raw web data. Look for APIs that let you fine-tune requests with flexible query parameters, handle pagination and result limits reliably, and return data in formats that plug easily into your existing pipelines. Support for JavaScript rendering, authentication, and dynamic content is essential for modern websites, as is smart handling of blocking defenses and good scraping practices like rate limiting.
FAQ
What is a web scraping API?
A web scraping API is a tool that enables developers to extract data from websites by automating the process of sending requests, parsing HTML content, and returning structured data. It provides a programmatic interface for accessing web content and extracting information that can then be used for other purposes.
A good web scraping API will make it easier for the devs to get data by using standard API calls and adhering to RESTful API guidelines. The web scraping API acts as an intermediary between the developer and the target website, handling the underlying complexities of web scraping, such as sending requests, parsing HTML, rendering JavaScript, and managing proxies, all while providing a clean and easy-to-use interface for data extraction.
What’s the difference between normal web scraping and using a web scraping API?
Web scraping can mean writing custom scripts to send requests, parsing HTML, and extracting data in a time-consuming, prone to errors process. Web scraping APIs encapsulate all those activities into a single, standardized service, allowing the user to focus on getting the right data rather than the mechanics of scraping.
Is it legal to use a web scraping API?
Using a web scraping API is legal, but it's important to mind the various regulations and third-party rights.
Note: This evaluation is based on our understanding of information available to us as of January 2026. Readers should conduct their own research for detailed comparisons. Product names, logos, and brands are used for identification only and remain the property of their respective owners. Their use does not imply affiliation or endorsement.