


Before you begin any web scraping project, you need to inspect the target website to see how it's structured. Otherwise, you'll choose the wrong tools for the job and fail to retrieve all the data you need.
One of the things to watch out for is if and how the website is paginated.
This tutorial aims to show you how to scrape paginated websites using Python, specifically Beautiful Soup.
Pagination examples
There are various ways websites can be paginated. Here are the most common pagination types:
- Next and Previous buttons: A very straightforward approach where users can navigate to the next or previous page using dedicated buttons. This is often accompanied by a simple counter (e.g., "Page 3 of 10").
- Numeric pagination: This type displays a series of numbers, each representing a page. Users can click on a number to jump directly to that page. It's a common approach for sites with a moderate number of pages.
- Infinite scroll: While not pagination in the traditional sense, infinite scroll automatically loads content as the user scrolls down the page. This is often used on social media platforms and news sites.
- Load More button: Similar to infinite scroll, this method loads a certain amount of content initially and then offers a "Load More" button to fetch additional content without navigating to a new page.
- Dropdown pagination: Some sites use a dropdown menu for navigation, allowing users to select a page from the dropdown list so they can navigate large datasets more quickly.
- Ellipsis for skipping pages: Used in conjunction with numeric pagination, ellipses (…) indicate skipped portions of a large page range. Clicking near the ellipsis typically jumps ahead or back several pages.
- Arrows: Very similar to Next and Previous buttons. Websites paginated with arrows (often in the form of "<" and ">") are used for simple forward and backward navigation. They may stand alone or complement other pagination methods, such as numeric pagination.
- First and Last buttons: In addition to or instead of arrows, some sites include "First" and "Last" buttons to quickly jump to the beginning or end of the content. It's commonly used for very long lists.
- Tabbed pagination: Websites paginated this way separate content into tabs, often categorized by type or date. While not traditional pagination, it organizes content in a paginated fashion within each tab.
- Sliders: On websites where pagination is used to navigate through items, sliders allow users to move left or right through content. This method is popular for galleries and product views.
- Alphabetic pagination: Used primarily in directories or lists that can be sorted alphabetically, as it allows users to select a letter to view items starting with that letter.
To a normal user of a website, these different types of pagination are just a matter of design and UX, but for web scrapers, each requires slightly different code and sometimes different frameworks.
For example, if you're dealing with infinite scroll, you'll need a browser, which means you'll require a tool like Playwright or Selenium.
I won't cover every type of pagination in this tutorial. Instead, I'll provide a complete solution for one pagination type by focusing on building a scraper for a particular website.
In this case, we'll be targeting a demo website - Books to Scrape - which is paginated with 'next' buttons, like so:
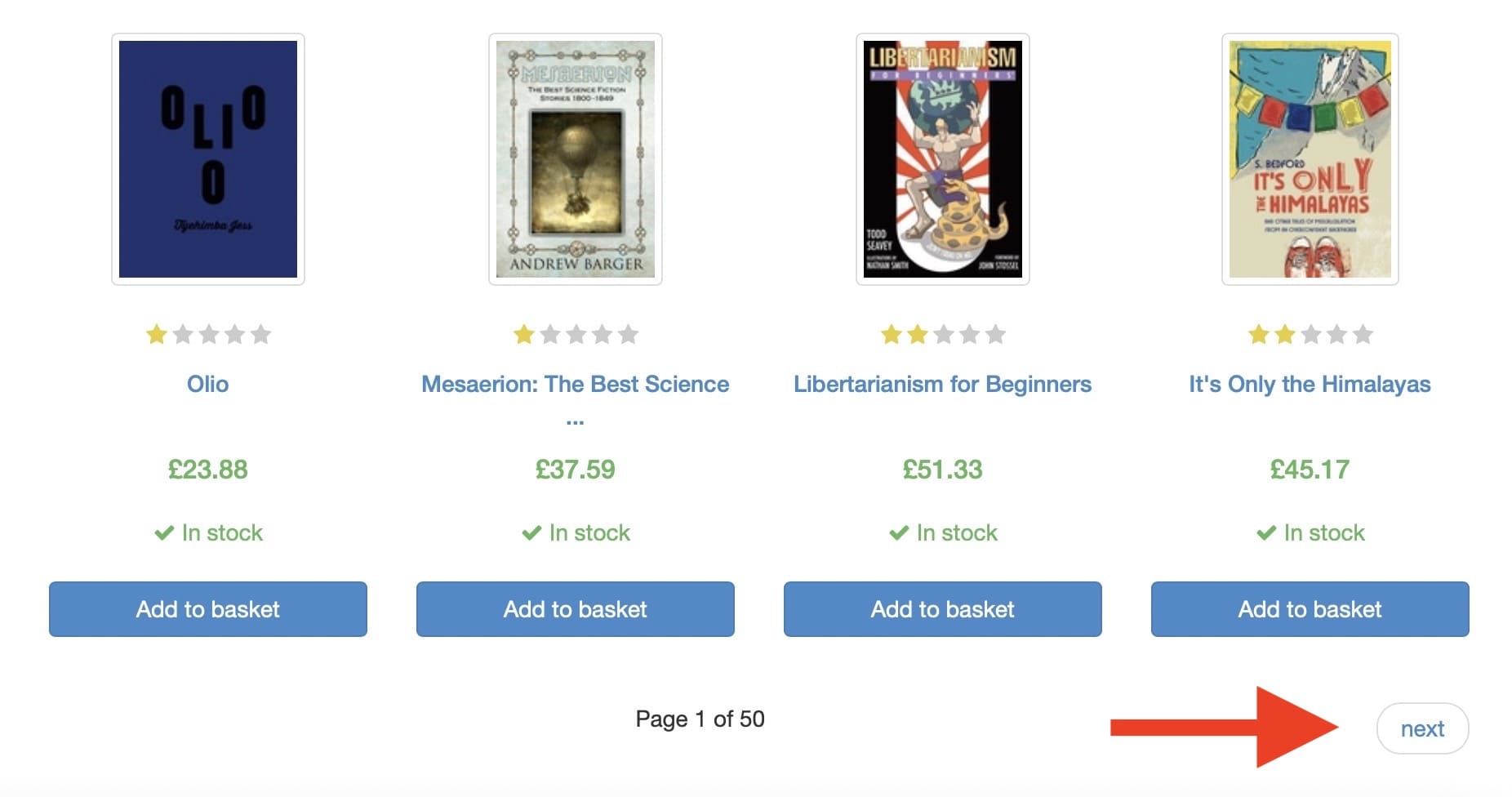
When dealing with very large and complex websites, such as Amazon, there’s a limit to the number of pages shown in pagination.
The pagination limit is usually between 1,000 and 10,000 products. Here’s a three-step solution to this limitation:
- Use search filters and go to subcategories
- Split them into ranges (e.g. price ranges of $0-10, $10-100)
- Recursively split the ranges in half (e.g. split the $0-10 price range into $0-5 and $5-10)
Learn more about how to scrape paginated sites and split pages with range filters here
How to scrape a paginated website with Python
For this tutorial, we're going to build a web scraper locally with the Apify CLI and a Python web scraping template.
We'll then deploy the scraper to the cloud (Apify, in this case).
Apify is a full-stack web scraping and browser automation platform. Deploying scrapers to the Apify cloud platform means you'll be able to make use of its storage, proxies, scheduling features, integrations, and a lot more.
For our target website, we won't need to scrape any dynamically loaded content. Beautiful Soup and HTTPX will do the trick nicely. So, we'll use the template for Beautiful Soup and HTTPX and adjust it to our needs.
1. Install Python
Ensure you have Python installed on your system, as both Beautiful Soup and HTTPX are Python libraries. You can download Python from the official website. It's recommended to use Python 3.6 or later.
2. Set up your environment
You can find a complete guide to installing the Apify CLI and the Beautiful Soup and HTTPX template here. But let's break it down.
➡️ a) Install the Apify CLI globally on your device using npm with the following command:
npm i -g apify-cli.
➡️ b) Create a new Actor using the Beautiful Soup template by running the command below:
apify create my-actor -t python-beautifulsoup
This will create a new Actor named my-actor, which you can rename as you see fit.
➡️ c) Navigate to the Actor's directory and run it with the following commands:
cd my-actor
apify run
These commands move you to the my-actor directory and run the scraper locally.
3. Adapt the Python code for the paginated website
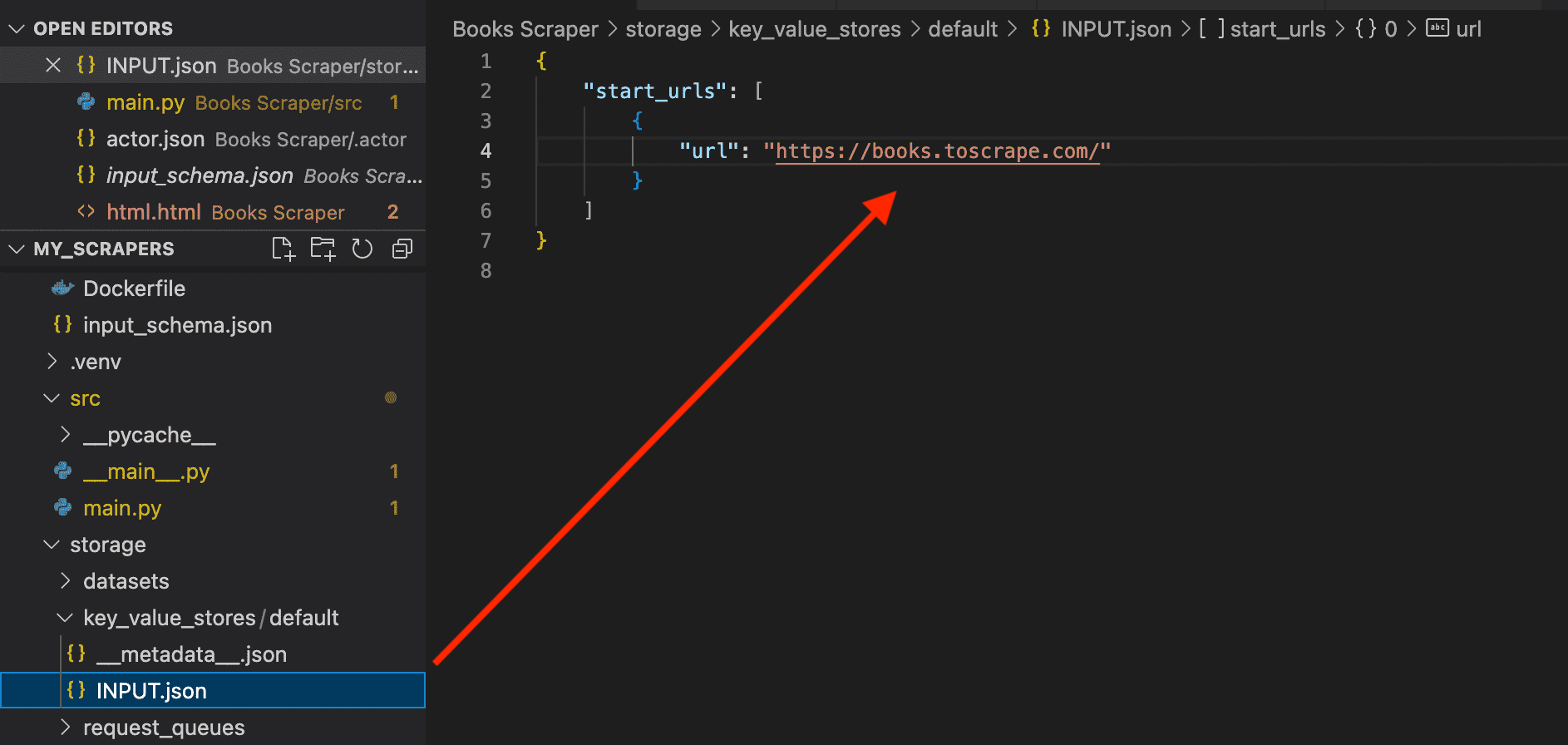
In your code editor, go to the ./storage/key_value_stores/default/INPUT.json file to add the URL you want to scrape:
{
"start_urls": [
{
"url": "https://books.toscrape.com/"
}
]
}
Now, go to the ./src/main.py file to adapt the code for your use case. This is the template you'll begin with:
"""
This module defines the `main()` coroutine for the Apify Actor, executed from the `__main__.py` file.
Feel free to modify this file to suit your specific needs.
To build Apify Actors, utilize the Apify SDK toolkit, read more at the official documentation:
https://docs.apify.com/sdk/python
"""
from urllib.parse import urljoin
from bs4 import BeautifulSoup
from httpx import AsyncClient
from apify import Actor
async def main() -> None:
"""
The main coroutine is being executed using `asyncio.run()`, so do not attempt to make a normal function
out of it, it will not work. Asynchronous execution is required for communication with Apify platform,
and it also enhances performance in the field of web scraping significantly.
"""
async with Actor:
# Read the Actor input
actor_input = await Actor.get_input() or {}
start_urls = actor_input.get('start_urls', [{'url': 'https://apify.com'}])
max_depth = actor_input.get('max_depth', 1)
if not start_urls:
Actor.log.info('No start URLs specified in actor input, exiting...')
await Actor.exit()
# Enqueue the starting URLs in the default request queue
default_queue = await Actor.open_request_queue()
for start_url in start_urls:
url = start_url.get('url')
Actor.log.info(f'Enqueuing {url} ...')
await default_queue.add_request({'url': url, 'userData': {'depth': 0}})
# Process the requests in the queue one by one
while request := await default_queue.fetch_next_request():
url = request['url']
depth = request['userData']['depth']
Actor.log.info(f'Scraping {url} ...')
try:
# Fetch the URL using `httpx`
async with AsyncClient() as client:
response = await client.get(url, follow_redirects=True)
# Parse the response using `BeautifulSoup`
soup = BeautifulSoup(response.content, 'html.parser')
# If we haven't reached the max depth,
# look for nested links and enqueue their targets
if depth < max_depth:
for link in soup.find_all('a'):
link_href = link.get('href')
link_url = urljoin(url, link_href)
if link_url.startswith(('http://', 'https://')):
Actor.log.info(f'Enqueuing {link_url} ...')
await default_queue.add_request({
'url': link_url,
'userData': {'depth': depth + 1},
})
# Push the title of the page into the default dataset
title = soup.title.string if soup.title else None
await Actor.push_data({'url': url, 'title': title})
except Exception:
Actor.log.exception(f'Cannot extract data from {url}.')
finally:
# Mark the request as handled so it's not processed again
await default_queue.mark_request_as_handled(request)
This will work for scraping apify.com but won't work for what we want just yet. So, let's see what needs to be changed to scrape all the paginated pages on books.toscrape.com.
4. Inspect the website
Explore the website and identify the data you want to extract so you know what tags you need to scrape and identify any problems that might come up.
By inspecting the elements on the web page with DevTools, we can see the first thing we need to adjust:
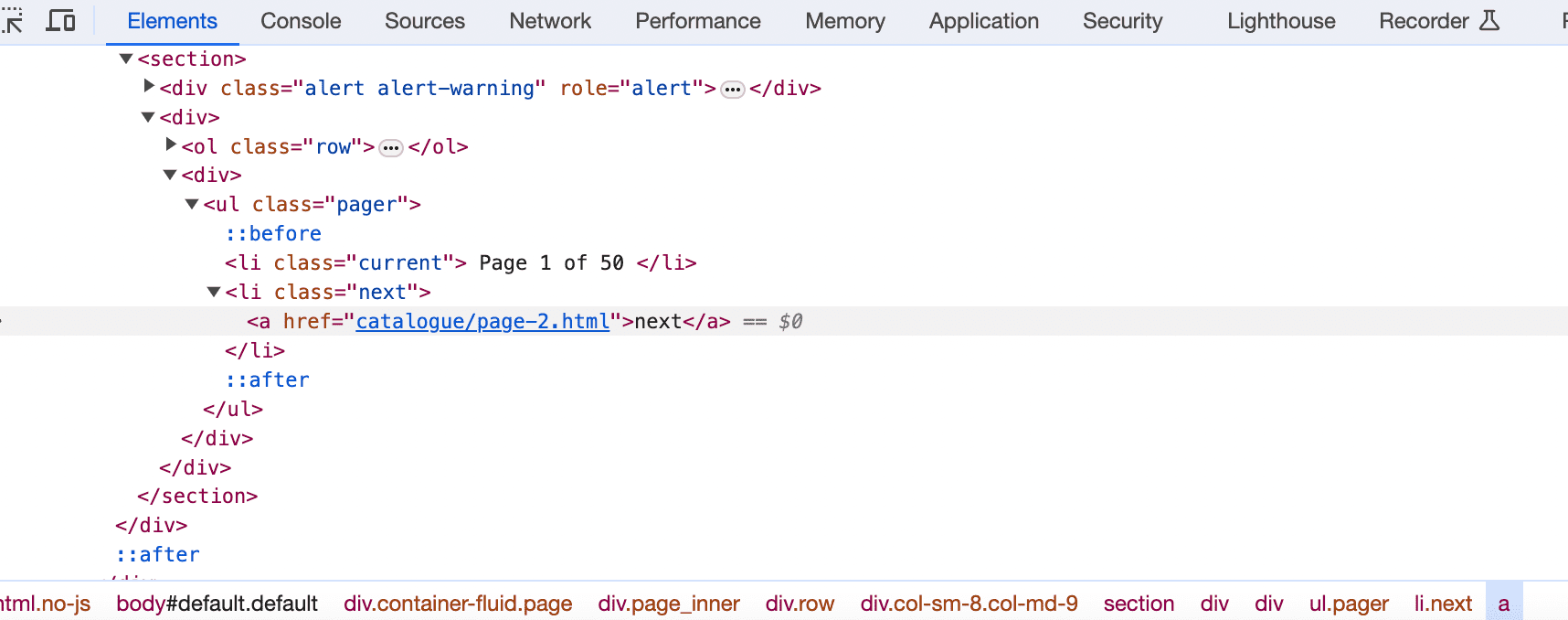
Highlighted is the anchor tag (<a>) with the text "next", which is the clickable part for the user to go to the next page. The href attribute of this anchor tag is "catalogue/page_2.html", which is the relative URL to the second page of the paginated content. So, let's update the code…
5. Crawl paginated links
To adjust the code accordingly using Beautiful Soup, we need to add the CSS selector .next a to crawl pagination links to the next page(s) of a list or search results:
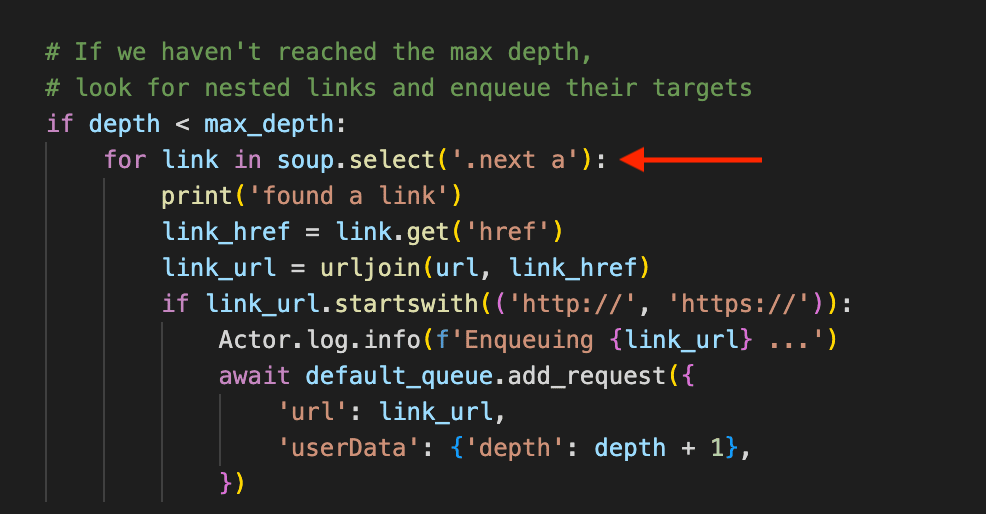
Here's the adapted code:
# If we haven't reached the max depth,
# look for nested links and enqueue their targets
if depth < max_depth:
for link in soup.find_all('.next a'):
print('Found a link')
link_href = link.get('href')
link_url = urljoin(url, link_href)
if link_url.startswith(('http://', 'https://')):
Actor.log.info(f'Enqueuing {link_url} ...')
await default_queue.add_request({
'url': link_url,
'userData': {'depth': depth + 1},
})
For each link, this will extract the href attribute and construct an absolute URL with urljoin(). The code will handle relative URLs correctly by combining them with the base URL of the current page. Doing this checks if the URL is a valid HTTP or HTTPS link.
If the URL is valid, it logs a message indicating that the URL is being enqueued and then asynchronously adds a new request to a queue (default_queue.add_request) for further processing.
To make sure you don't end up scraping pages you don't want, always check the last paginated page in case there's another button (or arrow or ellipsis, etc.) that leads to a different section of the website. If there is, you'll need to specify where the scraper should stop.
Books to Scrape has 50 paginated pages, each leading to the following page via a 'next' button. Is there a button on the final page to lead the user to another section of the website?
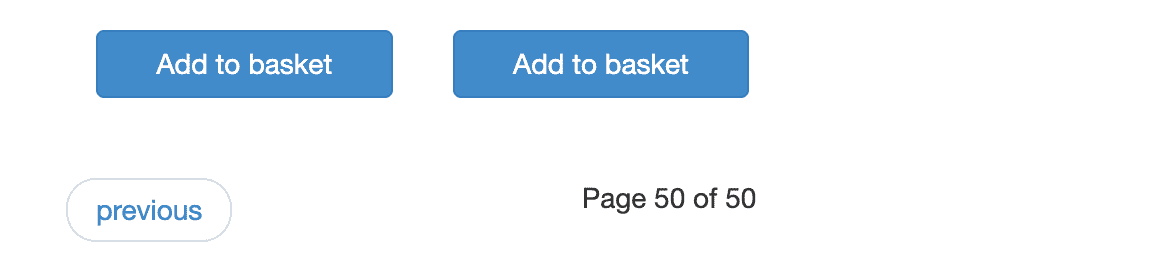
Nope! We're good!
6. Extract and store the data you need
To know what changes you should make to your code, you need to identify the elements - CSS selectors and whatnot - relevant to the data you're targeting.
In this instance, we want to extract the title, price, availability, rating, and image URL for every product (book) on all 50 pages.

Let's adjust our code accordingly, and then we can run the scraper:
for item in soup.select('.product_pod'):
await Actor.push_data({
'title': item.select_one('h3').get_text(),
'price': item.select_one('.product_price > p').get_text(),
'availability': item.select_one('.availability').get_text().strip(),
'rating': item.select_one('.star-rating').attrs['class'][1],
'image': urljoin(url, item.select_one('.thumbnail').attrs['src'])
})
The code iterates over elements matched by the CSS selector .product_pod for the products listed on the page.
For each item, it extracts the title, price, availability, rating, and image URL. The title, price, and availability are directly extracted from the text content of the specific child elements. The rating is derived from the second class of the element matched by .star-rating, and the image URL is constructed using urljoin() to ensure it is an absolute URL.
Now, we can run the scraper, log the extracted data, and push it to the dataset. The scraped data is asynchronously pushed into a default dataset using Actor.push_data(). This stores the data for later use.
Success! The scraped data from all 50 pages has been stored.
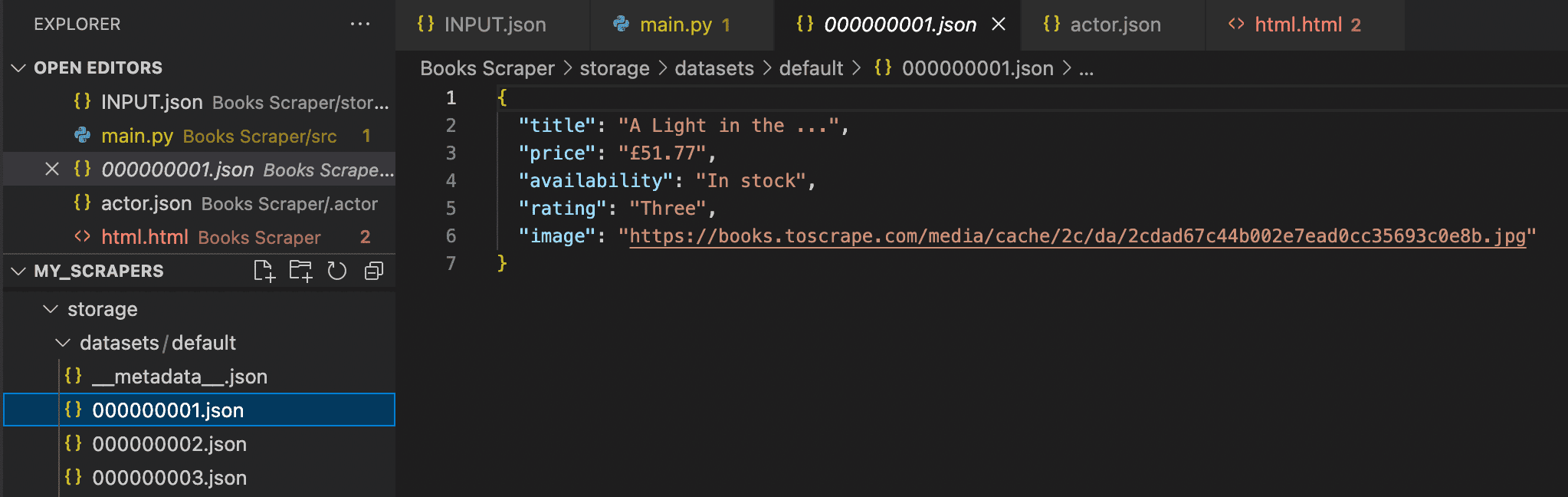
7. Deploy your scraper to the cloud
Now, to deploy the scraper, I need to log in to my Apify account via my IDE with the command below. That's precisely what you would do, too:
apify login
You'll be prompted to enter your Apify API token, which you can copy from your account in Apify Console. You can create multiple tokens, so if you don't want to use your default token, just create a new one, like I did:

Now you can deploy your scraper to the cloud by pushing your Actor to Apify with this simple command:
apify push
This uploads the project you created to the cloud platform and builds an Actor from it.
You'll now find the scraper in Apify Console under My Actors. It will look something like the one I created for this demo.
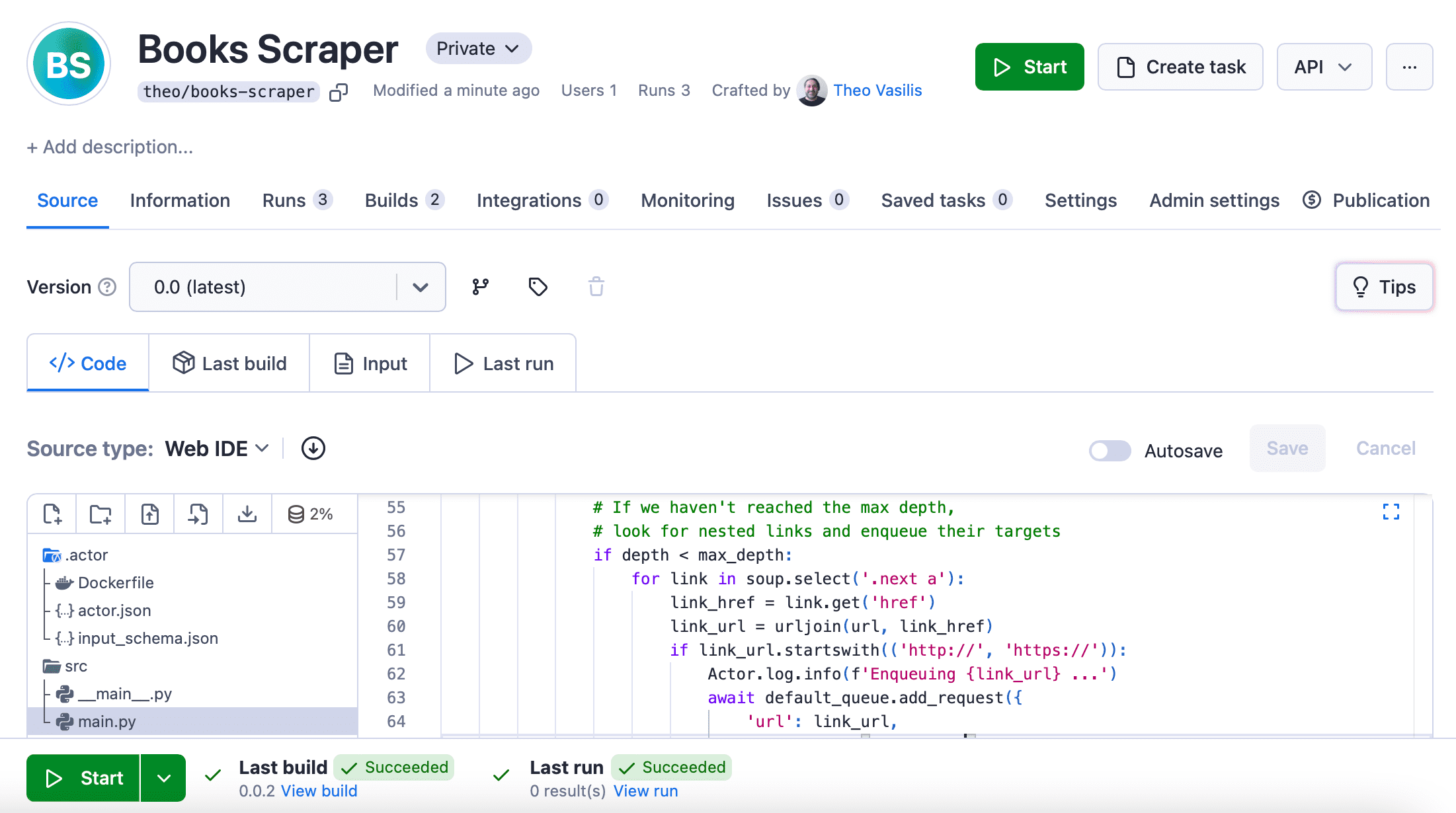
But it's not ready to run just yet…
8. Adjust the input
When developing locally, we provide the Actor input in the INPUT.json file. However, when we deploy the same Actor to the Apify platform, the input will come from the values provided in the platform UI created by the schema defined on input_schema.json.
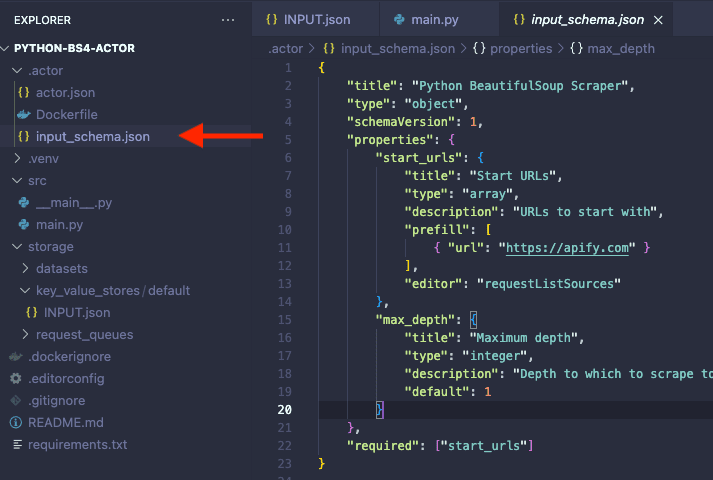
Therefore, in the Actor, we have to replace the placeholder value of “Start URLs” with our desired target.
Additionally, in order for the pagination to work as expected and extract all the books available on the website, we need to adjust the max_depth value. This is because the max_depth will serve as a limit of how far your scraper should go on the website.
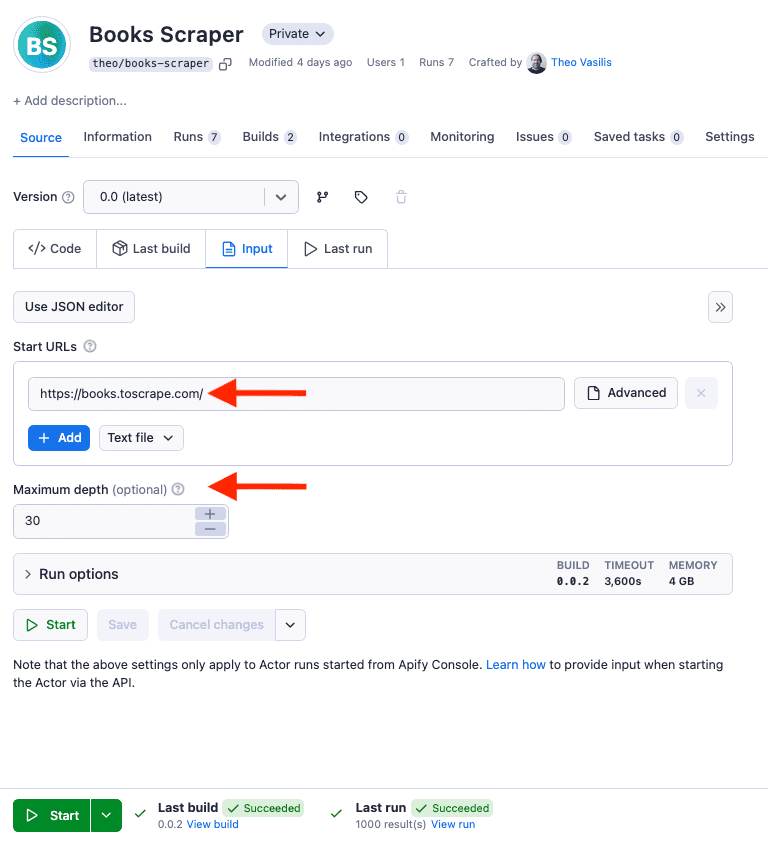
Now the scraper is ready to run in the cloud. I only need to click the Start button at the bottom to run the Actor.
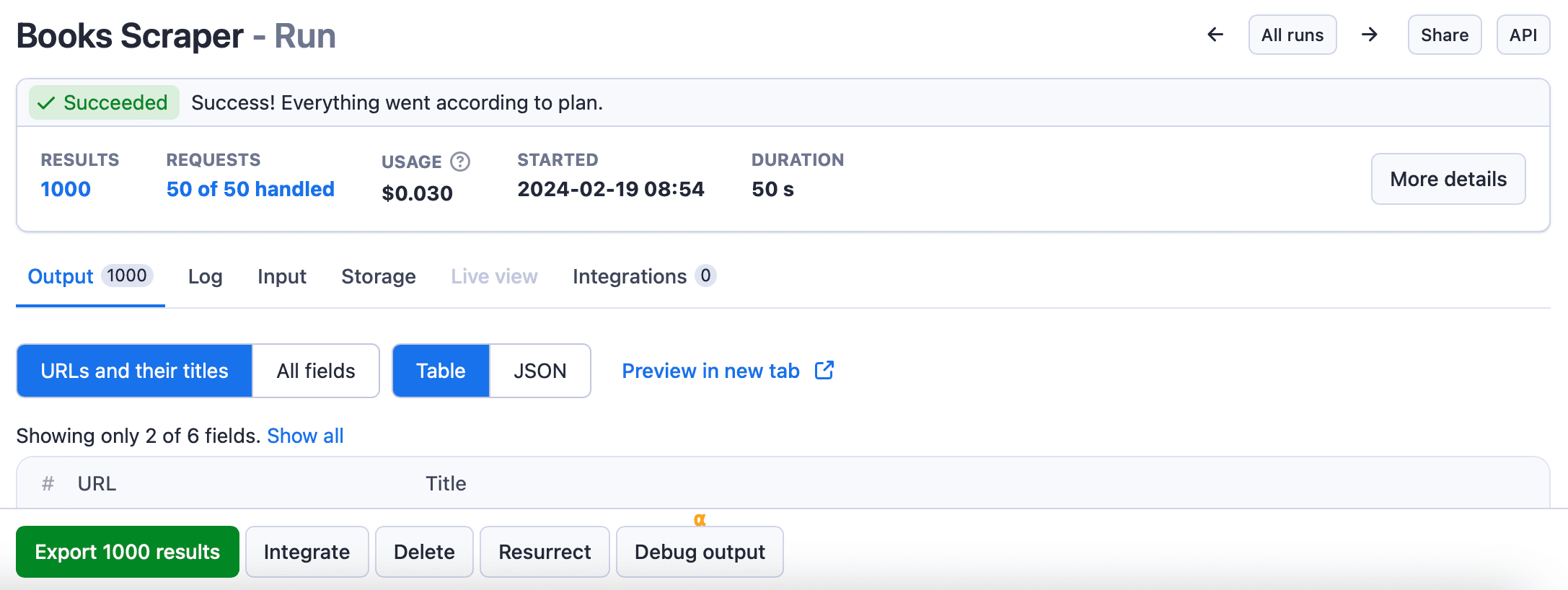
The Actor scraped all 1,000 results from the 50 paginated pages!
By clicking on the Export results button, I can view and download the data in multiple formats, such as JSON, XML, CSV, Excel, and others.
It doesn't have to end here
Whether you want to scrape paginated websites for e-commerce or build scrapers in Python or other languages for different purposes, Apify offers the infrastructure you need. By deploying your scrapers to the cloud and turning them into Actors, you can make the most of all the features the Apify platform has to offer.
But you can do even more than that.
If you want to make your Actors public and monetize them, you can publish what you've built in Apify Store. To learn how to do it, check out our guide to publishing and monetizing Actors in Apify Academy.
Learn more about web scraping with Python
Want to continue learning about using Python for web scraping? We have plenty of Python content for you to check out. Here's a short list for starters:
- Web scraping with Python: a comprehensive guide
- What are the best Python web scraping libraries?
- How to parse JSON with Python
- Web scraping with Beautiful Soup and Requests
- How to parse HTML in Python with PyQuery or Beautiful Soup
- Scrapy vs. Beautiful Soup: which one to use for web scraping?
- Web scraping with Selenium





