


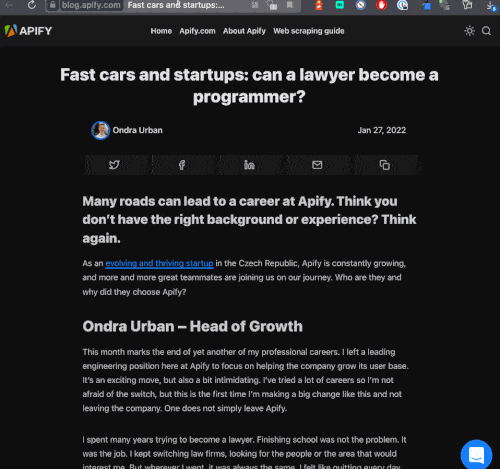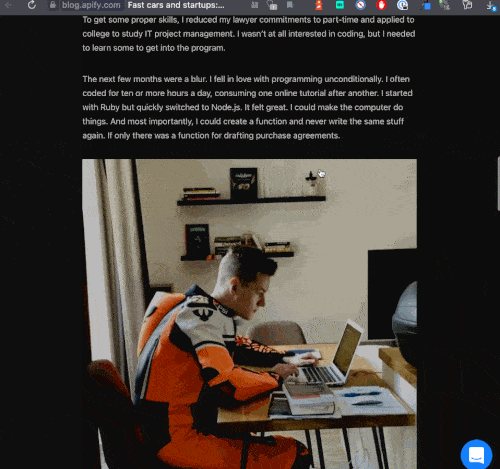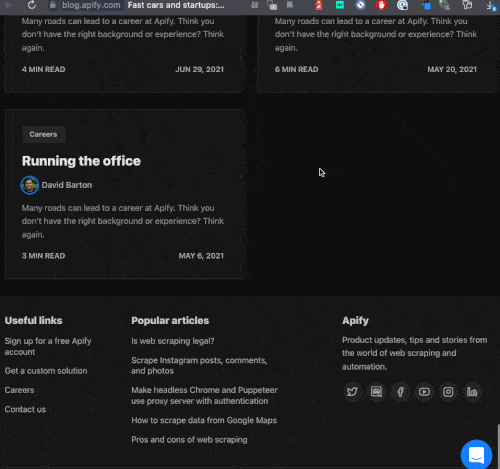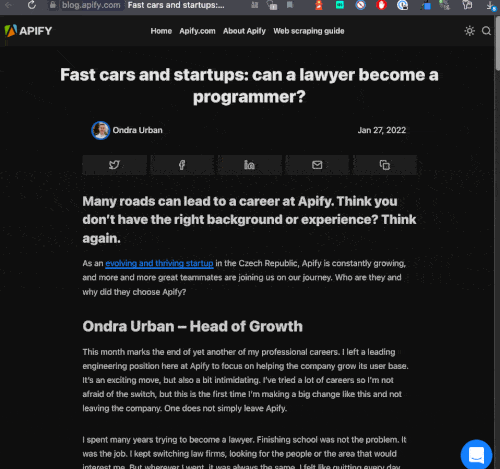
If you've been reading up on web scraping, you've most likely at least once heard the words "dynamic page" or "dynamic loading." To a seasoned web automation engineer, these technical terms are a part of our daily lives, but for someone fairly new to scraping, they can sound confusing and a bit daunting. By the end of this article, any confusion you may have regarding these terms will be cleared right up.
What makes a page "dynamic"? 🤔
Some websites load all of the page's content immediately when you first load the page, while others return some content on the first load, and then more is rendered "dynamically" (updating the DOM) based on certain actions you may take (scrolling, clicking, hovering, etc.). The latter is the definition of a dynamic site, and once you know what that entails, it's quite easy to spot one!
Here are some defining factors of a dynamic site. If a page meets any of these criteria, it's most likely dynamic:
- It is written in a JavaScript library such as React (You can detect pages written in React with the React DevTools Chrome extension).
- It has lazy loading for content such as posts/images (depending on the type of lazy loading being used).
- New "Fetch/XHR" requests for page data that will be rendered onto the DOM can be seen in Chrome's network tab after doing certain actions on the page.
Example of a dynamic page
Let's take a look at X.com (formerlytwitter.com).
Here is a GIF of me scrolling through my Twitter feed:
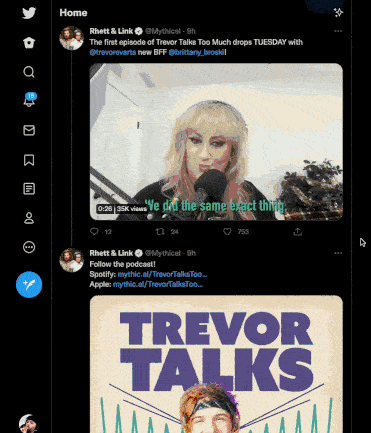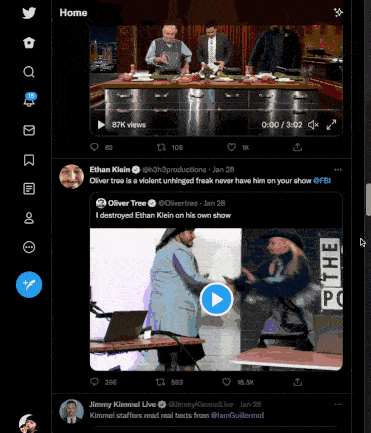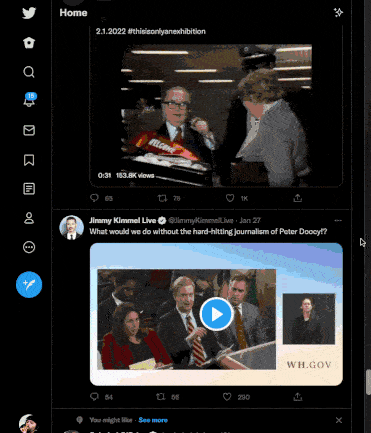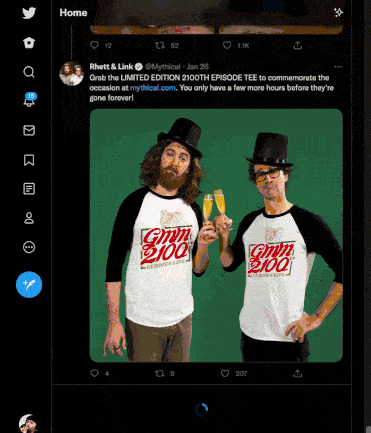
Take note of these factors:
- When we reach the bottom of the page, the scroll bar jumps back up, indicating that more content has been fetched from the backend and rendered onto the page dynamically after the page's initial load.
- As we scroll, images and videos for posts are not visible for a split second (they are loading).
Going a step further, we can take a look at the DOM (the HTML of the site) to watch these elements being rendered live as we scroll and confirm our hunch that a page is, in fact, dynamic:
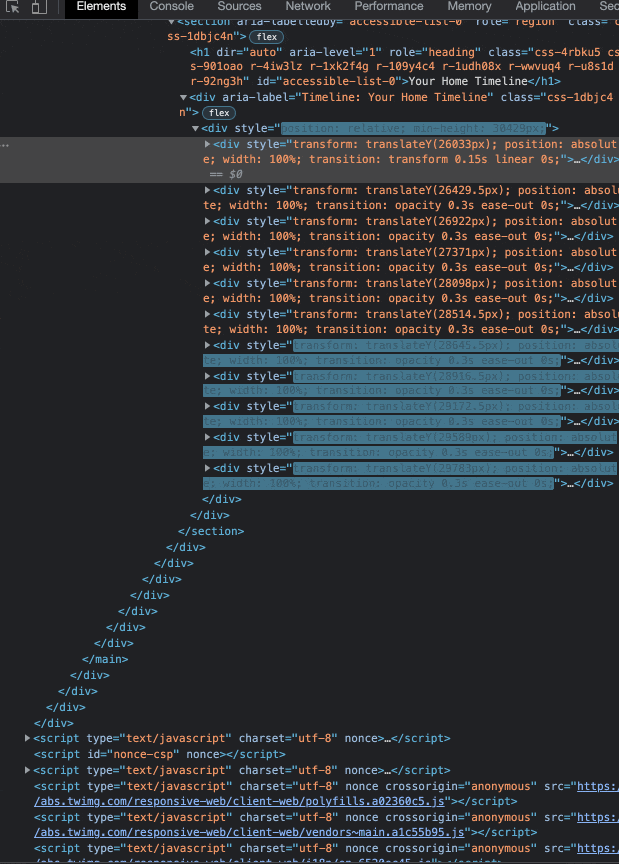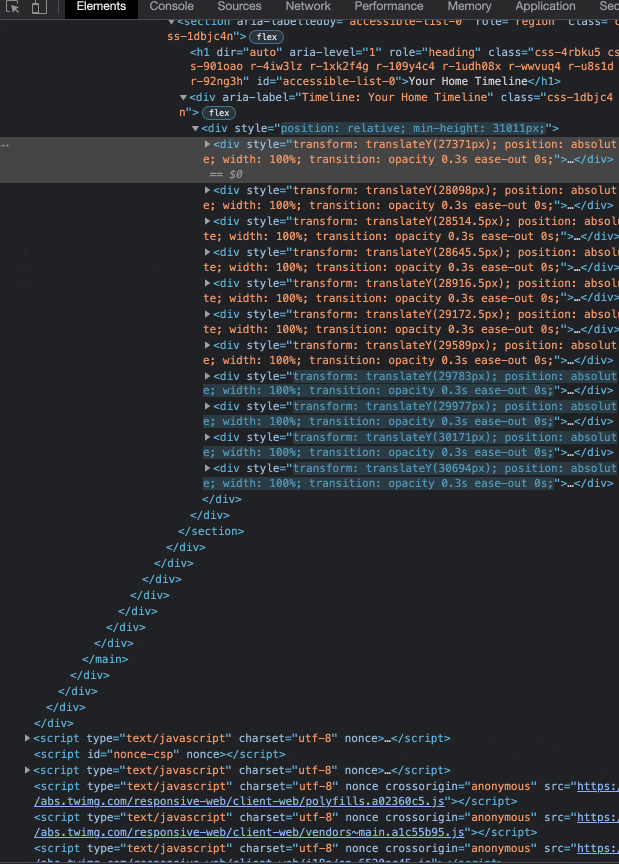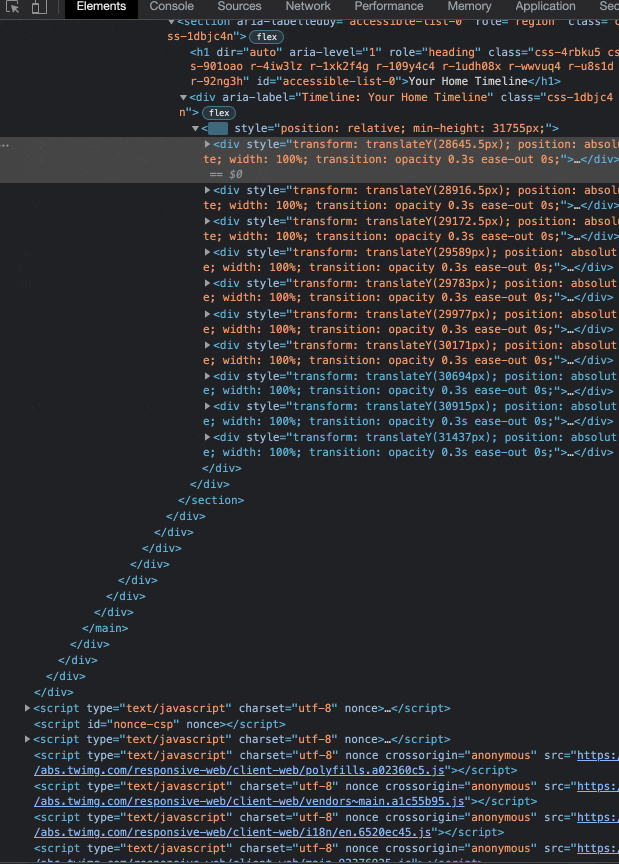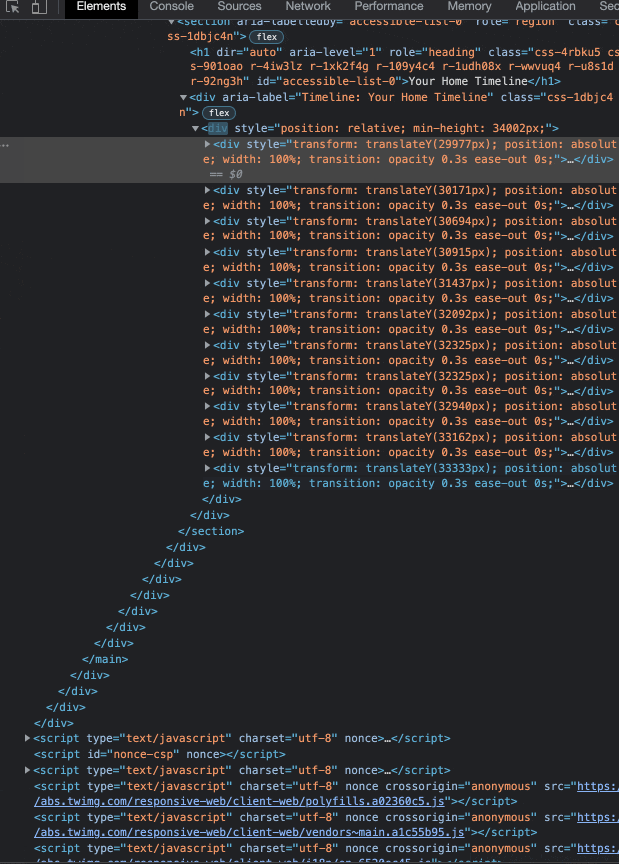
X is most definitely a dynamically loaded web app, as it aligns with all of the criteria defined in the previous section. Not only does it lazy-load content and dynamically fetch page data to be rendered, but it is also written in React (the current most popular front-end JavaScript framework).
Static vs. dynamic
To reiterate, a dynamic web page is simply a page where the DOM gets updated in some way after the initial load. More often than not (99.9% of the time), a web app will use JavaScript to render new content. This means that we can use tools like the "Quick JavaScript Switcher" Chrome extension to help us.
We want to scrape this article on the Apify Blog. Let's go ahead and utilize our new JavaScript Switcher tool to discern whether it's a static or dynamic page.
| With JavaScript Enabled | With JavaScript Disabled |
|---|---|
 |
 |
Because JavaScript has been disabled, the theme of the blog site switches back to light mode instead of my preferred dark mode; however, that is insignificant. All of the article's data and content on the page remain the same between our two GIFs, which means that all of the content we want to scrape is provided on the first load of the page. This page is static, NOT dynamic.
Why does this matter when building a web scraper?
Whether or not a page is dynamic heavily affects the tools we use and the approaches we take when building a scraper.
When a page is non-dynamic, we can easily retrieve all of its content within one single GET request, which allows us to use tools like CheerioScraper or CheerioCrawler.
The extra complexity comes when the page IS dynamic. Because content (usually containing data we want to scrape) loads dynamically, we must use a tool that simulates a browser, such as Puppeteer Scraper or Playwright Scraper. Tools like Puppeteer and Playwright utilize headless browsers that allow us to load the page's JavaScript (essential for sites written in libraries like React), as well as programmatically take actions on a page (just like a real human does!).
This is not necessarily a problem; however, the downside of these tools and the methods that come along with them is that they are significantly less performant than something like Cheerio, as it simply takes longer for the computer to automate browser actions. Because of this, when dealing with a dynamic site, it's a good idea to first check out different avenues of scraping, such as sniffing out the web app's API and utilizing that instead of automating a headless browser and scraping the HTML for data.
Static or dynamic? A challenge for you 💪
Hopefully, we've been able to clarify some things about dynamic web pages. To end on a strong note, here is a small challenge.
For each of these links, determine whether or not the page is dynamic:





