Over the years, web scraping has become an increasingly popular method for extracting structured data from websites.
Automating web data extraction is key to unlocking the web's full potential and efficiently using the endless amount of information accumulated on the internet. And this is still true in 2022.
In this article, we will examine the world of modern data extraction in an effort to identify what opportunities, and risks, lie on the horizon for web scraping in 2022.
Web scraping: the cornerstone of the big data revolution
“Without big data, you are blind and deaf and in the middle of a freeway.” Geoffrey Moore
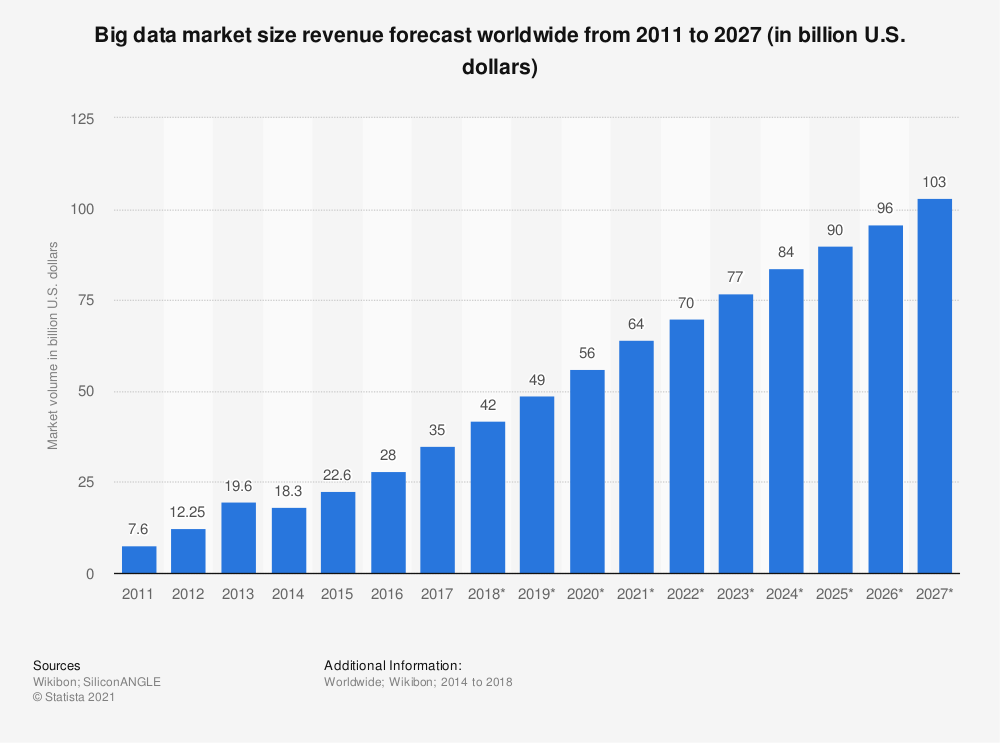
Big data has been responsible for some most impactful technological breakthroughs in the last decade, and web scraping is an integral part of this revolution.
Web scraping is the cornerstone of the rapidly growing big data market
Big data can be defined as large data sets that are analyzed computationally to reveal patterns, trends, and associations, especially relating to human behavior and interactions.
Just as a computer is required to analyze big data, navigating and gathering these data is also not a task for humans. Web scraping is essential for extracting extensive amounts of data which are the cornerstone of big data analytics, Machine Learning (ML), and Artificial Intelligence (AI) algorithm training.
Web scraping e-commerce in 2022
Keeping ahead of the competition is an age-old battle for any business. This statement is especially true in the online space, where businesses face worldwide competition.
In an increasingly data-driven world, efficient data-collection methods are of crucial importance to any brand aspiring to rise to the top of its market.
How to use web scraping to build a sucessful e-commerce business in 2022 📈
The demand for data is at its historical apex and shows no signs of slowing down. In fact, quite the opposite.
The growth of big data and its associated industries directly impacts the demand for reliable and scalable web scraping solutions capable of extracting huge amounts of data from the web. In other words, the future looks favorable to web scraping.
Is web scraping legal?
Web scraping is legal, and it remains so in 2022. However, misconceptions and rumors about the legality of web scraping are still an ongoing topic.
It's important to note that not all kinds of web scraping are legal. Like any technology available to humans, web scraping can be used for both honorable and nefarious purposes.
Legal and ethical debates around web scraping are a hot topic in 2022.
While scraping the web, you must be aware of the boundaries between ethical and non-ethical web scraping. For example, extracting personal data or any data that infringe upon the intellectual property regulations is not acceptable and may cause you problems.
Only extract publicly available data, and refrain from scraping data protected by password authentication and/or copyright laws.
Do not use the information collected to copy the target's website business model, and cause it to lose market share.
The rise of anti-bot protections in 2022
Anti-scraping protections are becoming increasingly more sophisticated, and dealing with these barriers is now, more than ever, an integral part of the workflow when developing efficient and scalable scraping solutions.
Advanced anti-scraping techniques, such as user behavior analysis and browser fingerprinting, are often combined with more traditional methods like IP rate limiting and HTTP request analysis. So, what can you do to avoid being blocked while scraping?
Browser fingerprinting is used to set humans and bots apart
Websites are leaning heavily on fingerprinting-based detection, acquiring vast amounts of information about users' devices, operating systems, and browsers.
Dealing with sophisticated fingerprinting-based tracking techniques usually involves a lot of trial-and-error testing, resulting in multiple proxies being banned, which, in turn, considerably increased the maintenance and development costs of web scraping solutions.
Despite the new challenges, web scrapers are still able to rapidly adapt to new circumstances and stay one step ahead of the most advanced anti-bot methods in 2022. Novel technologies, such as Apify's fingerprinting generator, are capable of creating realistic browser fingerprints and matching headers to make bots appear to be real human users and not get blocked.
Mobile app scraping - web scraping's new frontier
Mobile apps are rapidly overtaking websites. Apps usually offer users more features and personalized experiences, supplementing or even replacing traditional websites.
Following this trend, a new way to collect data is gaining traction in 2022 : mobile API scraping. This technique taps directly into mobile app APIs, enabling you to extract data from apps and automate workflows.
Imagine automatizing food delivery orders or extracting large amounts of valuable data from the most popular apps without lifting a single finger. Not bad, right?
Mobile app data is increasing in popularity and importance, rivaling traditional websites
Mobile apps usually employ significantly fewer anti-scraping protections than websites. Many mobile apps do not hide their data behind a login, limiting their bot protections to IP address rate limiting methods, which can be easily dealt with by using proxies. In other words, scraping data from mobile APIs is extremely efficient and has enormous potential, so it is likely to continue to grow in popularity in 2022 and beyond.
Web scraping libraries and frameworks to watch for in 2022
Python and Node.js are still at the top of the web scraping game. However, Node.js has been growing steadily and even gaining the upper hand over Python in scalability and avoiding anti-scraping protections in large-scale projects.
To test the popularity of the different programming languages for web scraping, we've recently conducted a poll on Reddit to find out the language of choice for the members of the r/webscraping subreddit in 2022.
Python is still the most popular language for web scraping in 2022
Python
Requests is a widely popular HTTP Python library. Its popularity is still holding up in 2022, with 1,000,000+ repositories depending on it.
Beautiful Soup, a Python library used to extract HTML and XML elements from the web, is the right choice for efficiently solving simple tasks. Its user-friendliness is one of the main reasons why Beautiful Soup maintains its position as the ideal web scraping tool for beginners.
Scrapy remains the go-to choice for large-scale scraping projects in Python due to its efficiency and completeness in features.
Node.js
Got scraping is apackage extension for Got HTTP client that offers out-of-the-box solutions to address common challenges in modern web scraping and avoid anti-scraping protections.
Cheerio is a fast and flexible implementation of core jQuery designed to run and work with HTML data on the server-side.
Apify SDK is an open-source web scraping and automation Node.js library. The Apify SDK is particularly efficient at automatically scaling your projects and seamlessly integrating scraping solutions with a vast pool of proxies to help you bypass anti-scraping barriers.
Best browser automation tools for web scraping in 2022
Because of its ability to render JavaScript on a web page, browser automation tools are fundamental while scraping dynamic websites. This is a handy feature, considering that many modern websites, especially in e-commerce, use JavaScript to load their content dynamically.
Selenium is a tool primarily developed for web testing, which also found an off-label use as a web scraper. Selenium is popular in the Python community, but it is also supported in JavaScript (Node.js), Python, Ruby, Java, Kotlin, and C#.
Puppeteer is a Node.js library developed and maintained by Google. It provides a high-level API to manipulate the Chrome browser programmatically. Besides web scraping, Puppeteer is used for automated testing and workflow automation.
Playwright is a relatively new library in the web automation space but is rapidly gaining adepts amongst the developer community. With its modern features, cross-browser, multi-language support, and ease of use, Playwright is becoming the natural choice for web scraping and browser automation in 2022.
2022: a year full of opportunities for web scraping
2022 is a year full of opportunities for web scraping. Of course, there are also challenges, such as the increasing sophistication of anti-bot protections. However, with the constantly growing number of libraries and frameworks, web scrapers are managing to stay at least a few steps ahead.
Apify Store boasts hundreds of ready-made web scraping tools which you can start using for free to extract data in a matter of minutes. If you need a specific scraper tailored for your use case, simply request a custom solution, and we will handle all the work for you.