


If you need to monitor prices, product details, or availability across Amazon, Walmart, eBay, and other e-commerce sites, you may be running into two problems:
- Fragmented data collection — having to run separate scrapers for each site or type of page.
- Incomplete coverage — category pages are great for finding new items, but can miss updates to important products; product detail pages give precise tracking but no discovery.
We'll show you how to solve these problems with E-commerce Scraping Tool via an API and Python.
The scraper can extract data from multiple e-commerce websites, using category, product detail URLs, or both - so you can get complete, deduplicated datasets in one export. It can also scrape marketplaces using keywords instead, if you’re interested in product discovery or market analysis.
What you need to get started
To follow along with this tutorial, make sure you have:
- An Apify account
- A basic understanding of how Apify Actors work when called via API
- Python 3.10+ installed locally
- An IDE (e.g., Visual Studio Code with the Python extension or PyCharm)
- Familiarity with Python syntax and the HTTP request mechanism
Set up the e-commerce project
Make sure you’re already in the directory where you want the scraper project to live. Once you’re there, create the project folder and step into it.
mkdir e-commerce-products
cd e-commerce-products
Next, let’s set up a virtual environment inside of it:
python -m venv .venv
To activate the virtual environment on Windows, execute this command in the IDE's terminal:
.venv\Scripts\activate
Equivalently, on Linux/macOS, run:
source .venv/bin/activate
Access the Apify Actor
Start by logging into your Apify account. If you don’t have one, you can easily create one for free. You’ll enter Apify Console - your dashboard for running Apify scrapers.
Then, navigate to Apify Store - a marketplace of 10,000+ scrapers and automation tools, called Actors.
- Built-in proxy management
- Anti-bot evasion support
- Integrated storage with structured exports in CSV/Excel/JSON
- Input configuration schema with standardized parameters (URLs, keywords, limits, etc.)
- REST API endpoint for start, stop, and data retrieval
- Easy integration with third-party apps or other Actors
Every Apify Actor can be triggered programmatically via the Apify API, opening up lots of ways to integrate it into your workflows.
On Apify Store, search for E-commerce Scraping Tool and select it from the list:
You’ll be redirected to the Actor page.
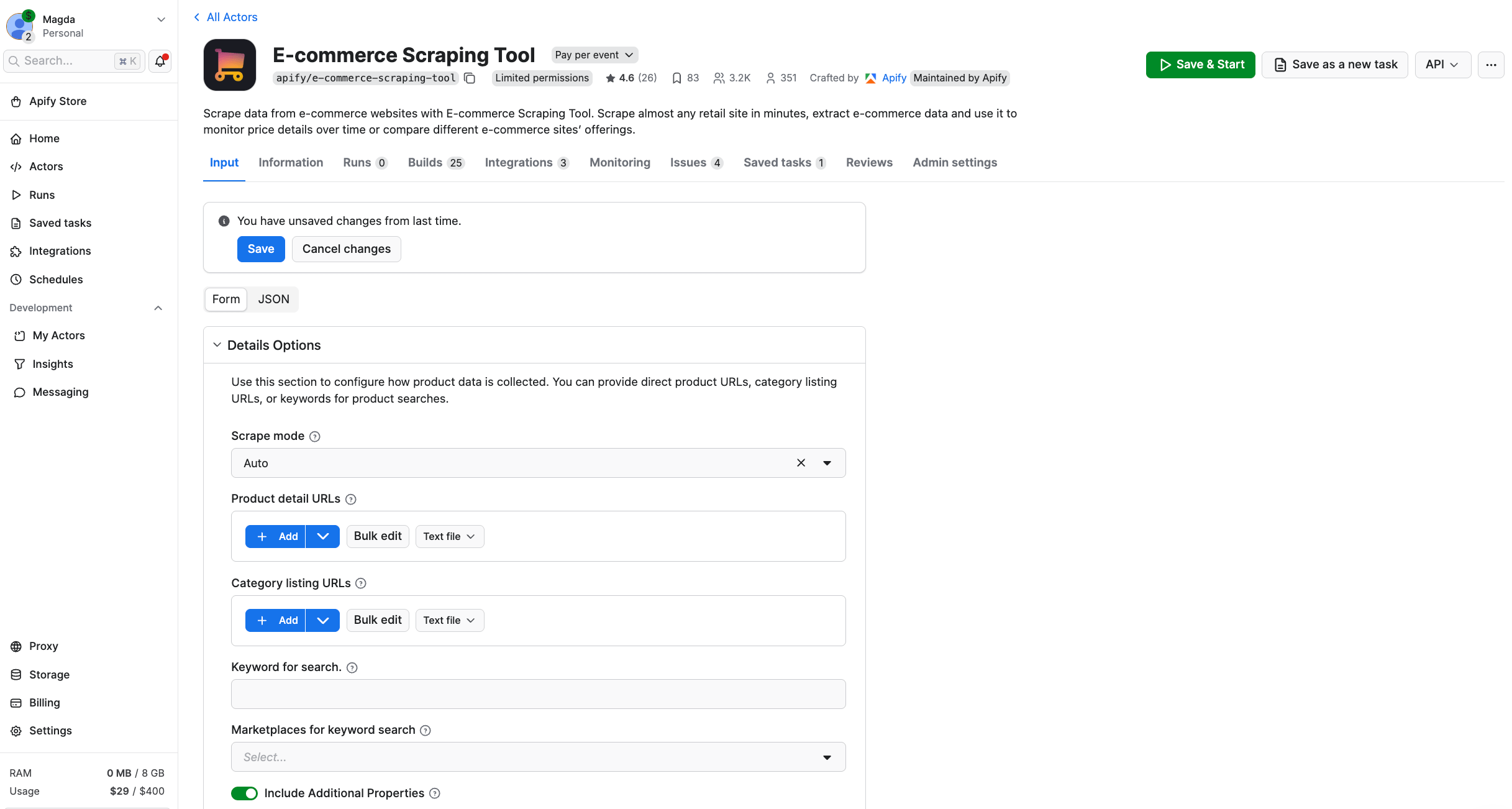
Test the scraper
Before diving into the Python integration, let’s test E-commerce Scraping Tool in a no-code workflow inside Apify Console. This is a convenient way for non-technical users to retrieve e-commerce product data.
To configure the Actor, you can choose one of the three input methods: Category listing URLs, Product detail URLs, and Keywords search.
| Input type | What it is | When to use it |
|---|---|---|
| Category listing URLs | Search results or category pages with multiple products | Discover many products, monitor whole categories, find new arrivals |
| Product detail URLs | URLs pointing directly to a single product page | Monitor known SKUs, track specific items for price/stock changes |
| Keyword search | Search marketplaces (i.e. amazon.de, ikea.com, kaufland.at) by keywords | Fast search — no need to gather URLs. Great for market research |
We’ll use product details URLs in this example, extracting product information from eBay, Target, Alibaba, and Alza. You can use URLs from any e-commerce platform and add them all in bulk to the Input tab.
You can also try the AI analysis feature, which allows you to get more out of your data, using natural-language instructions. To use it, define which dataset fields are relevant, and add a custom prompt for the scraper.
Click Start to launch the Actor. Once the scraper finishes running, you can preview your results in the Output section or download your dataset in Excel, JSON, XML, or other formats.
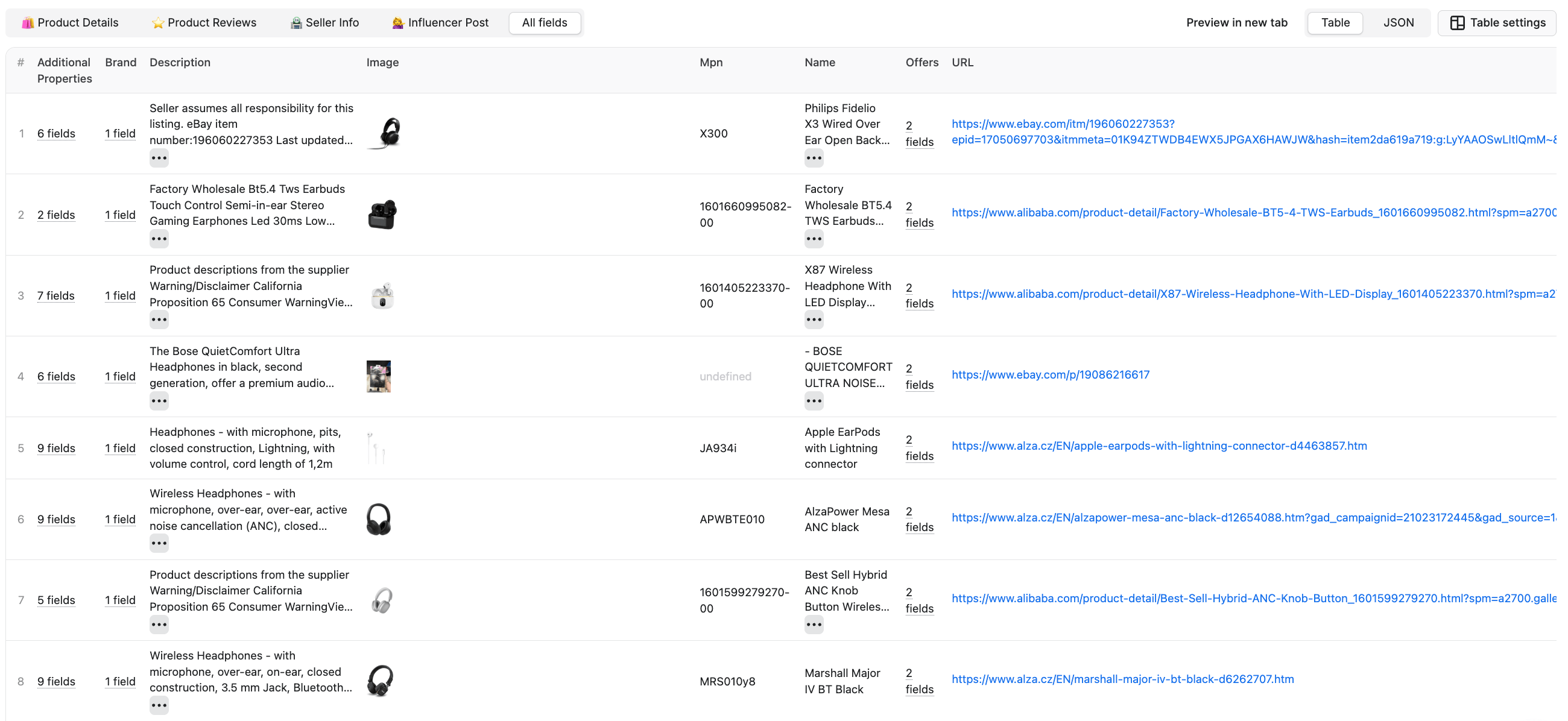
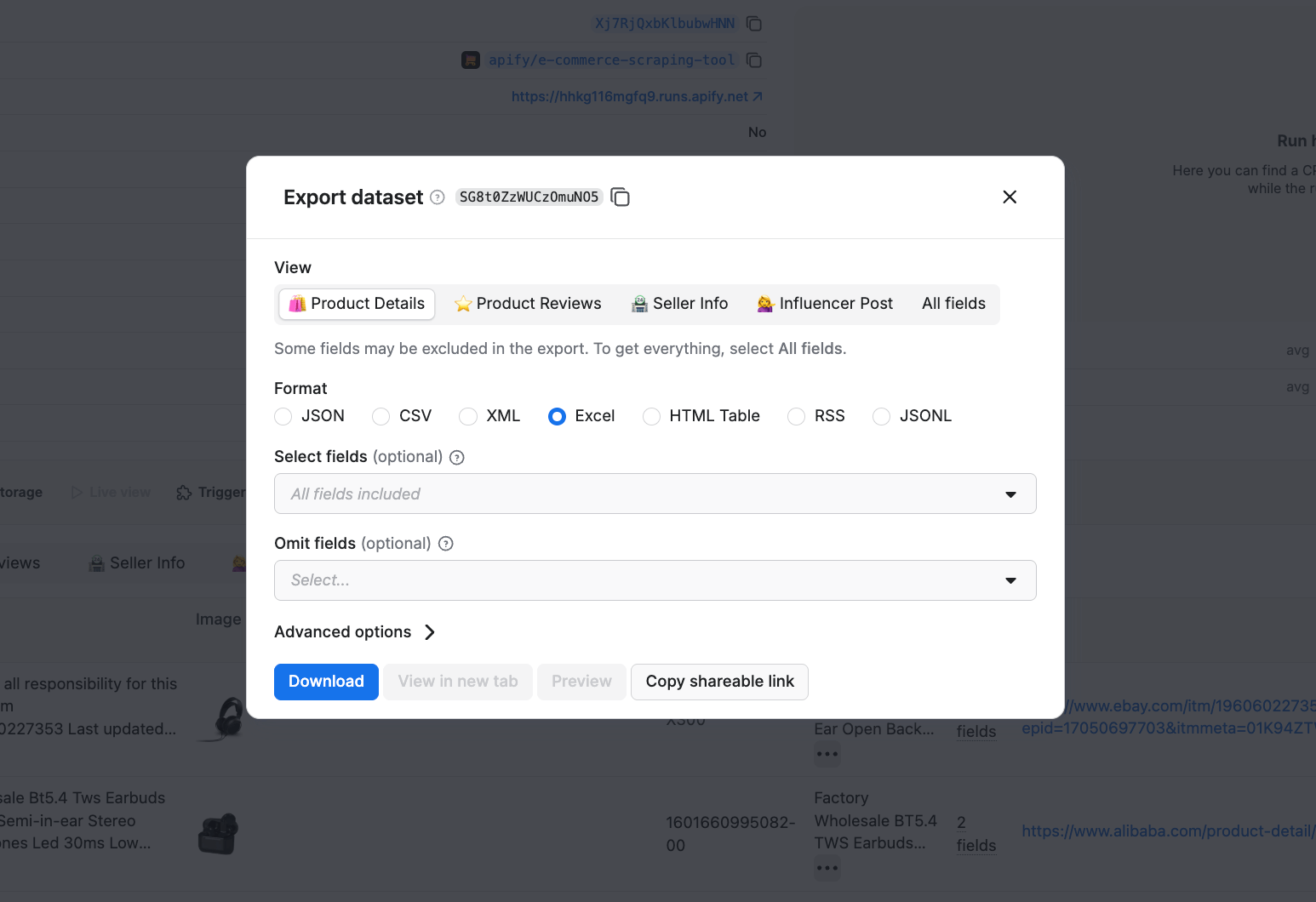
Scraped results are shown in a preview table. You can download your dataset in multiple formats.
As you can see, the Actor can extract product names, descriptions, prices, product IDs (SKUs, MPNs, GTINs, EANs, UPCs, ISBNs), images, and product variants. You can also go deeper with product review scraping.
Next, we’ll run it via an API.
Get started with the API integration setup
To set up E-commerce Scraping Tool for API usage, locate the API dropdown in the top-right corner of the Apify platform. Then, select API clients:
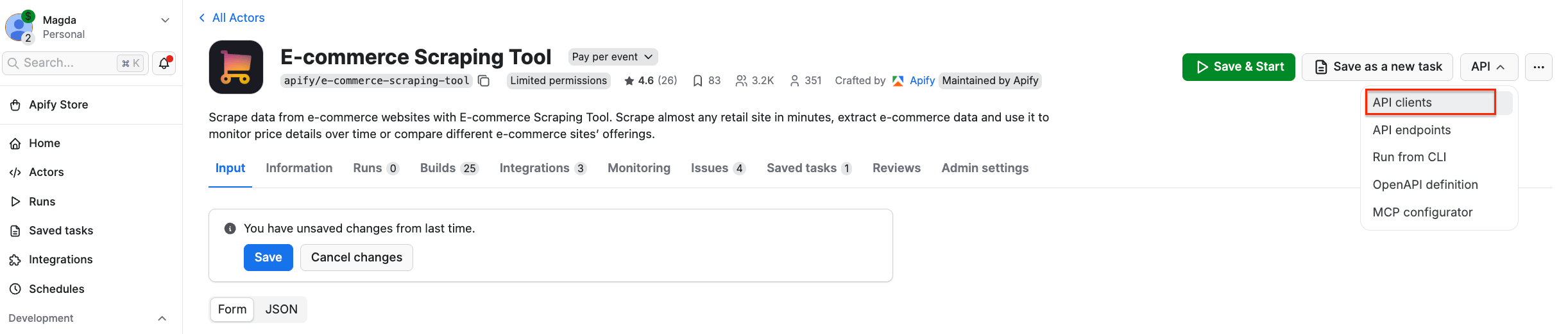
This will bring up a modal with ready-to-use code snippets for interacting with the Actor via the Apify API client. By default, it displays a Node.js snippet, so switch to the Python tab:
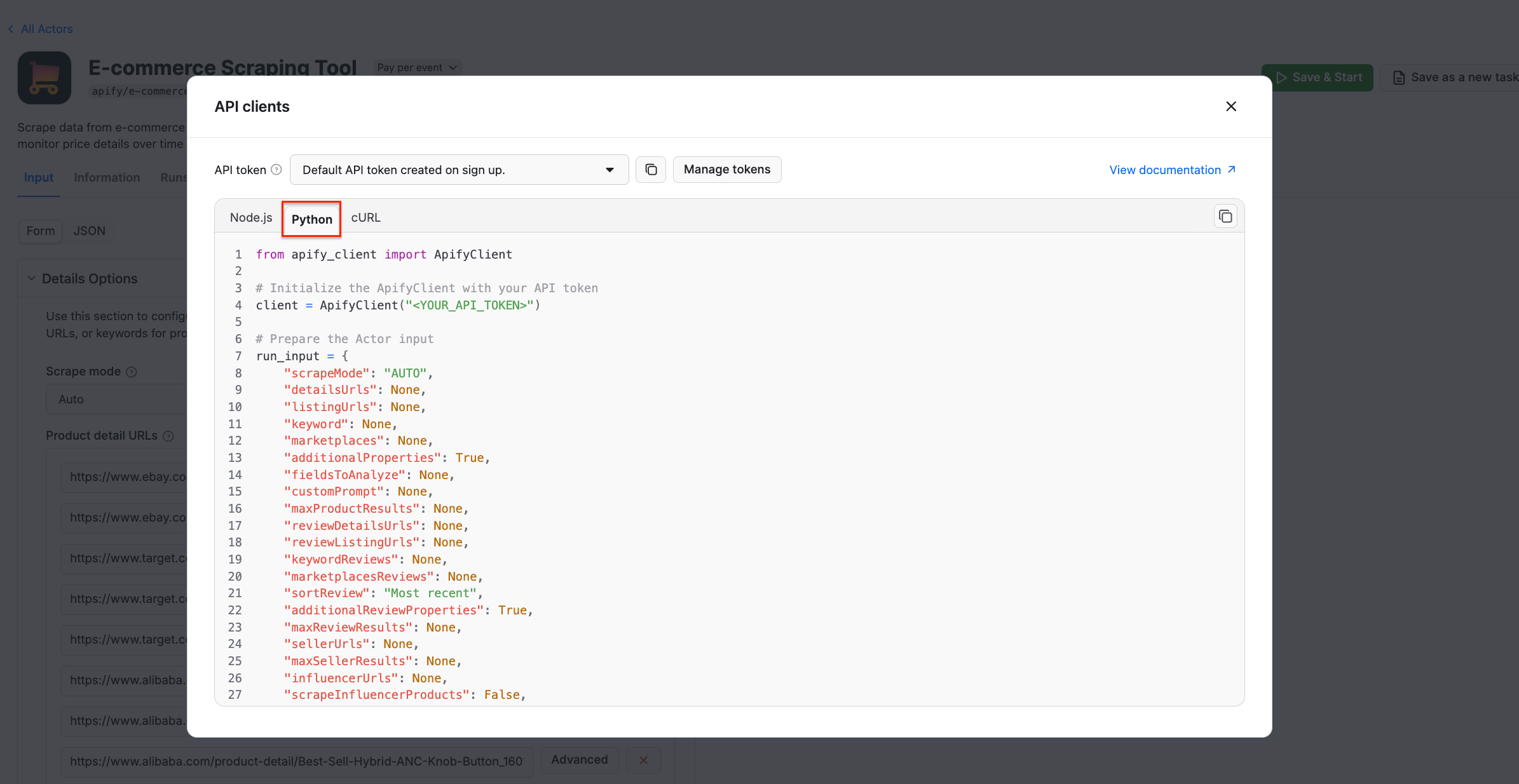
Copy the Python snippet from the modal and paste it into your Python file. Keep the modal open, as we’ll refer back to it in the next step.
After pasting the code into your file, you’ll likely see a warning that says Import apify_client could not be resolved . That simply means the package isn’t installed yet. To fix it, just run the command below inside the activated virtual environment:
pip install apify_client
Get and set your Apify API token
The next step is to retrieve your Apify API token and replace the placeholder <YOUR_API_TOKEN> in the file with your actual token. That is the final step required for scraping e-commerce websites via API integration with E-commerce Scraping Tool.
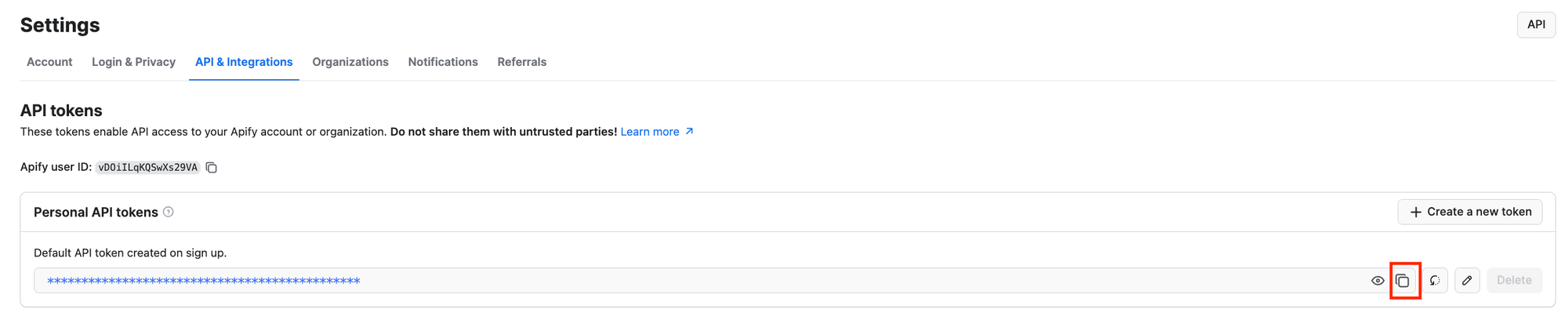
Go back to the Console, and in the API clients modal, click the Manage tokens button:

You’ll reach the API & Integrations section of the Settings page of your Apify account. To access your Apify API token, press the Copy to clipboard icon next to the Default API token created on sign-up entry:
Finally, replace the placeholder with the API token you just copied from your account:
# Replace the <YOUR_API_TOKEN> placeholder with your actual API token
client = ApifyClient("<YOUR_API_TOKEN>")
Configure E-commerce Scraping Tool
Like all Actors, E-commerce Scraping Tool requires input parameters to retrieve data. When using the ApifyClient, these parameters specify which pages the Actor should scrape via API.
In this example, we’ll target products listed on eBay, Target, Alibaba, and Alza. To simplify the input configuration process, open the Input section on the Actor’s page. Visually interact with the Product detail URLs field, and paste in the target URLs, just like in the testing section above:
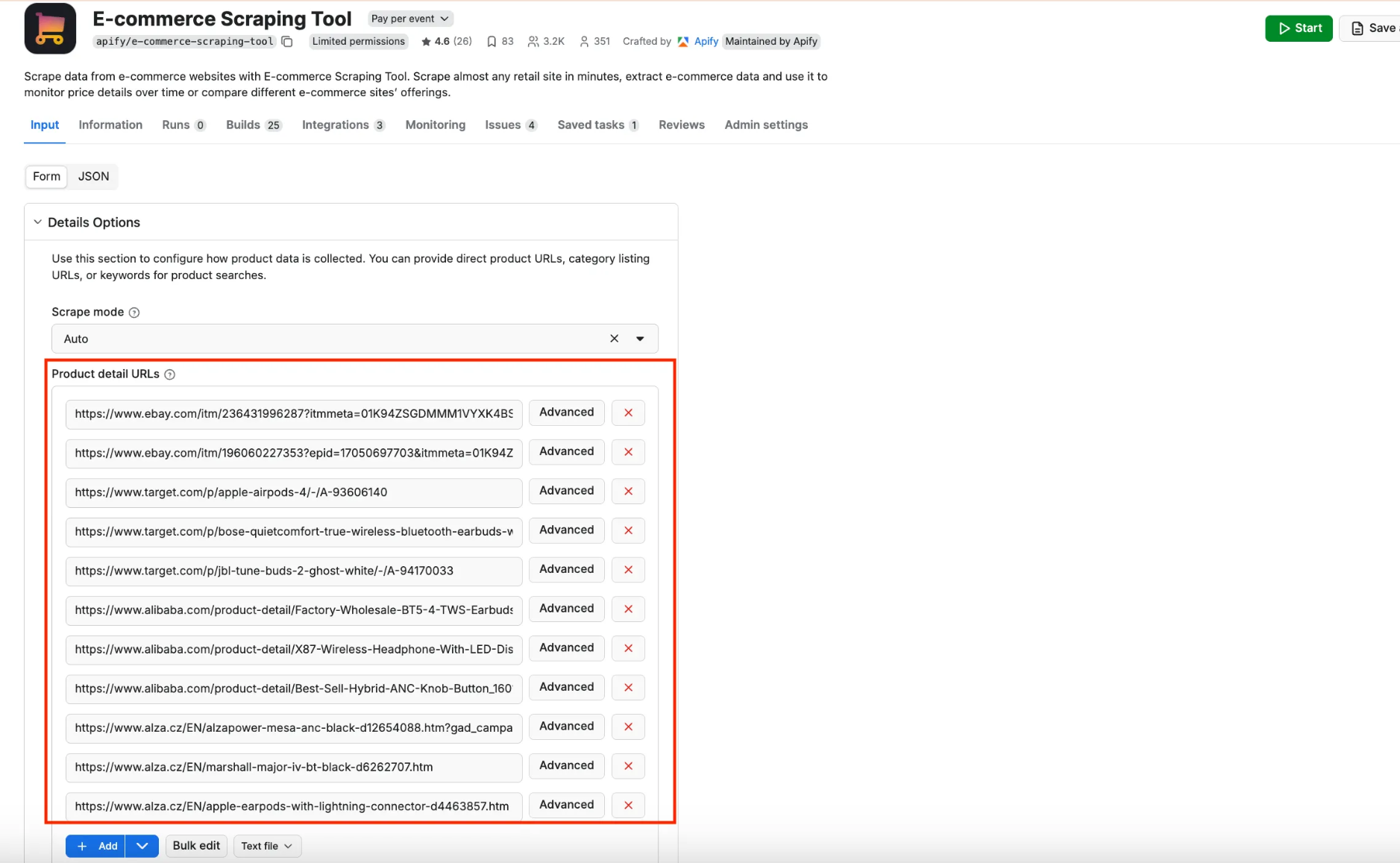
Then, switch to the JSON view, which looks like this:
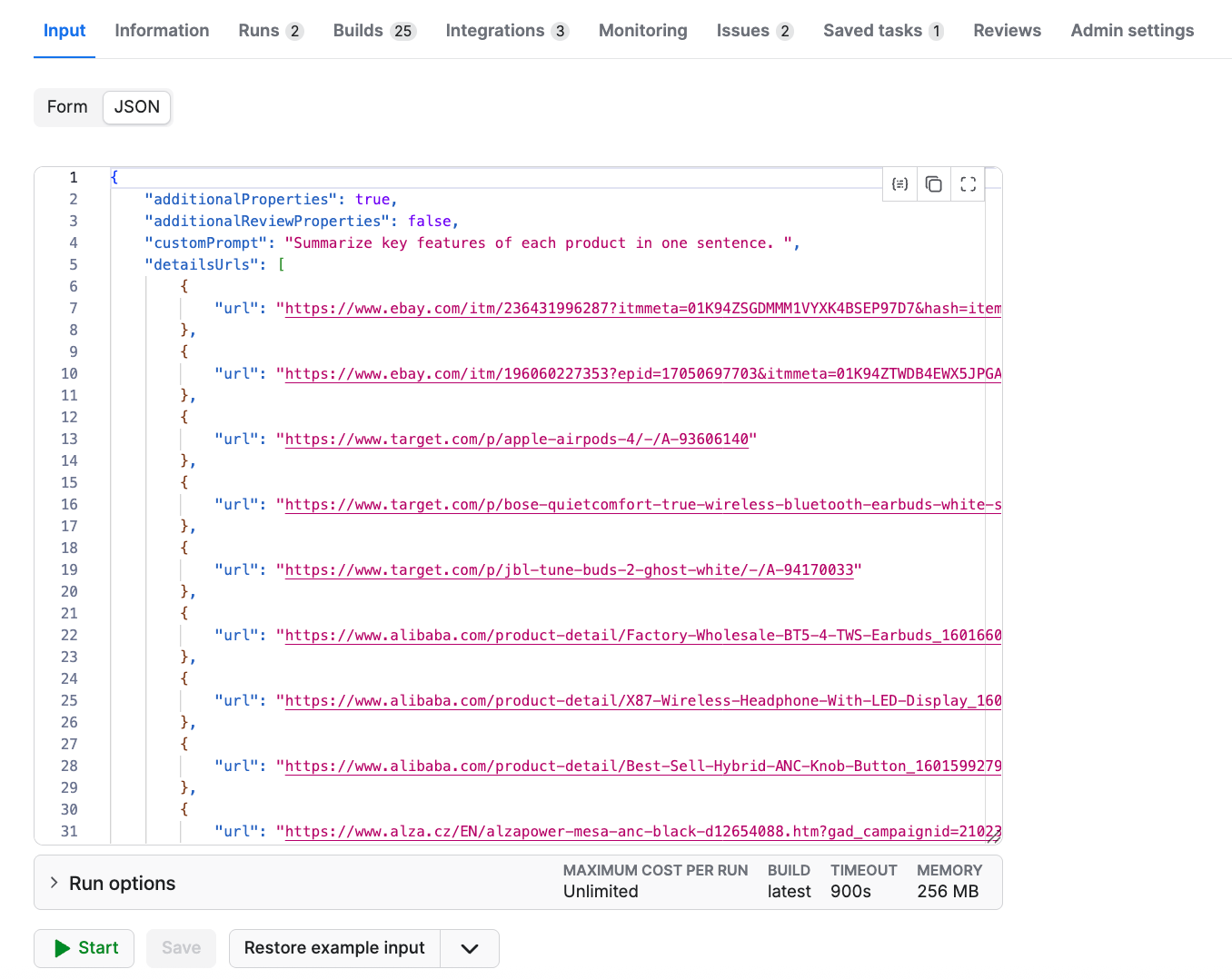
Now, follow this structure and populate the input dictionary in Python and call E-commerce Scraping Tool as shown below:
run_input = {
"additionalProperties": True,
"additionalReviewProperties": False,
"customPrompt": "Summarize key features of each product in one sentence. ",
"detailsUrls": [
{
"url": "https://www.ebay.com/itm/236431996287?itmmeta=01K94ZSGDMMM1VYXK4BSEP97D7&hash=item370c71f57f:g:z20AAeSwWLNo9kHw&itmprp=enc%3AAQAKAAAAwNHOg0D50eDiCdi%2FfP0r02vG3MW9kGYDp22UaUpcSd1sdyIRlg00DM9ettCv0QO%2FWA2rTphzCQpqNrhaaizM0LOXRBELHtSGH1GbX23vk10cxjDXccT0nQQxDiUdDzGS0U2F27otFO62E1uLpcEyQb5TWBhTK%2BPFCPRWbp%2Bdvt0qC6J4oav%2FUqJiv3ksaa7TFIRqzOx%2FkK1ufhbtbUSh5GNdw7W5GZ8KcfQ2CRf9eaIL%2Bqkyy5OP0pyPRdyEfXlGYQ%3D%3D%7Ctkp%3ABk9SR_qG5p_JZg"
},
{
"url": "https://www.ebay.com/itm/196060227353?epid=17050697703&itmmeta=01K94ZTWDB4EWX5JPGAX6HAWJW&hash=item2da619a719:g:LyYAAOSwLltlQmM~&itmprp=enc%3AAQAKAAAA4NHOg0D50eDiCdi%2FfP0r02vy9MMQ7Pa53jsfl40xwecjAMymZNbe1EXt%2Ffmm9%2BKmaHpHXfpt6HRi%2BlGjwJFU23Mng7oukJQ4QAyVKSmLd61Za9KYSL4ZZLBIddkkE8P%2B8YTIGSNOFo%2FWCyyNus3i53pB1an7OC8170XmqHPIVcvNf17oyyGGUqc6QjO%2Fjrjt4YdSNlv7EX42QqNGKgrQqtUl91jolKqNdyNv35geLceiZ1MViyJVdGsdWA6Vml2m3hX2kQpeEEZg54nauvkzJURSy4XkqjqWHX5OSV8K0NaL%7Ctkp%3ABFBM5Mbrn8lm"
},
{
"url": "https://www.target.com/p/apple-airpods-4/-/A-93606140"
},
{
"url": "https://www.target.com/p/bose-quietcomfort-true-wireless-bluetooth-earbuds-white-smoke/-/A-92407082#lnk=sametab"
},
{
"url": "https://www.target.com/p/jbl-tune-buds-2-ghost-white/-/A-94170033"
},
{
"url": "https://www.alibaba.com/product-detail/Factory-Wholesale-BT5-4-TWS-Earbuds_1601660995082.html?spm=a2700.galleryofferlist.p_offer.d_image.69c813a0OtVA8D&priceId=6067e48ae0e04b06998faa3ae1aaa494"
},
{
"url": "https://www.alibaba.com/product-detail/X87-Wireless-Headphone-With-LED-Display_1601405223370.html?spm=a2700.galleryofferlist.normal_offer.d_title.69c813a0OtVA8D&selectedCarrierCode=SEMI_MANAGED_STANDARD%40%40STANDARD&priceId=6067e48ae0e04b06998faa3ae1aaa494"
},
{
"url": "https://www.alibaba.com/product-detail/Best-Sell-Hybrid-ANC-Knob-Button_1601599279270.html?spm=a2700.galleryofferlist.p_offer.d_title.69c813a0OtVA8D&priceId=6067e48ae0e04b06998faa3ae1aaa494"
},
{
"url": "https://www.alza.cz/EN/alzapower-mesa-anc-black-d12654088.htm?gad_campaignid=21023172445&gad_source=1&gbraid=0AAAAAD2xsm6sOY8IHhq7Lz3jKJpZMfJ8T&gclid=Cj0KCQiAyP3KBhD9ARIsAAJLnnaRyiEhJWiZnncvRx2UuTII94fX1t5qiOffOnNFtsQRTktMglfqpFAaAhTbEALw_wcB&kampan=adwav_audio-video_pla_rh-top_sluchatka_c_9197834___690849174209_~154090792970~&setlang=en-GB"
},
{
"url": "https://www.alza.cz/EN/marshall-major-iv-bt-black-d6262707.htm"
},
{
"url": "https://www.alza.cz/EN/apple-earpods-with-lightning-connector-d4463857.htm"
}
],
"maxProductResults": 100,
"scrapeInfluencerProducts": False,
"scrapeMode": "AUTO",
"sortReview": "Most recent"
}
# Run the Actor and wait for it to finish
run = client.actor("2APbAvDfNDOWXbkWf").call(run_input=run_input)Now that the code is set up to scrape data from the e-commerce sites, we can run it to trigger the API call.
After it finishes, go back to Apify Console and open the Runs tab. You’ll see the latest E-commerce Scraping Tool run, with its origin marked as API, which confirms the code worked.
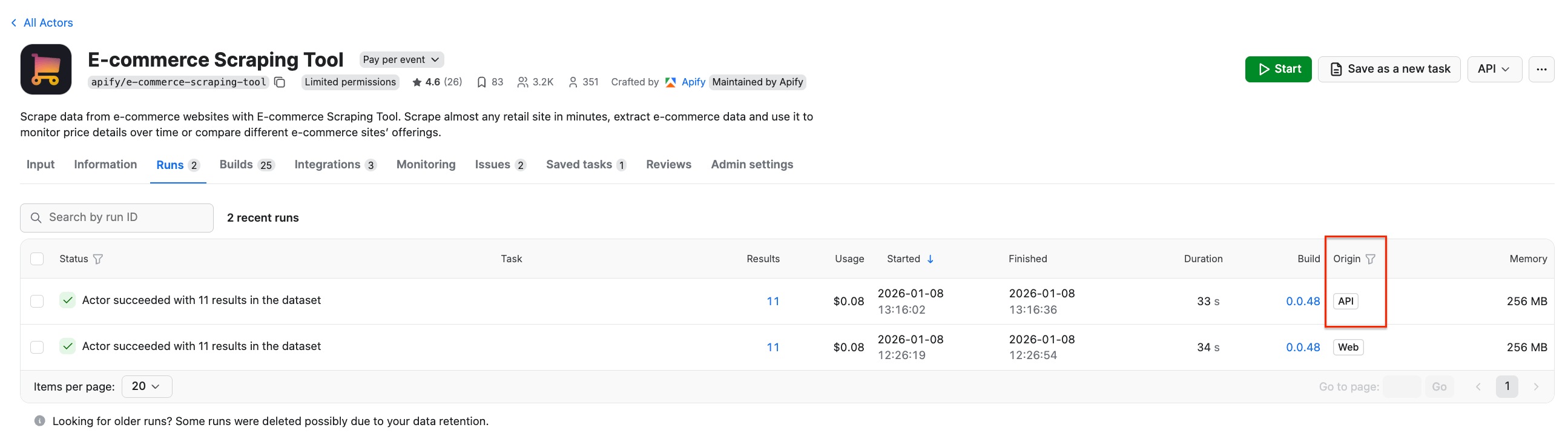
By clicking on the run, we can find the extracted results just like we would if we had started this run from the platform UI instead.
How much will your run cost?
E-commerce Scraping Tool uses a pay per event pricing model. You pay for:
- Actor start (per run)
- Listings scraped (for each pagination page)
- Details (for product, reviews, or seller)
- Optional: Residential proxy use (per product)
- Optional: Browser rendering (per product)
- Optional: AI summary
Higher subscription plans unlock lower Actor costs, as seen when comparing Free and Business plans:
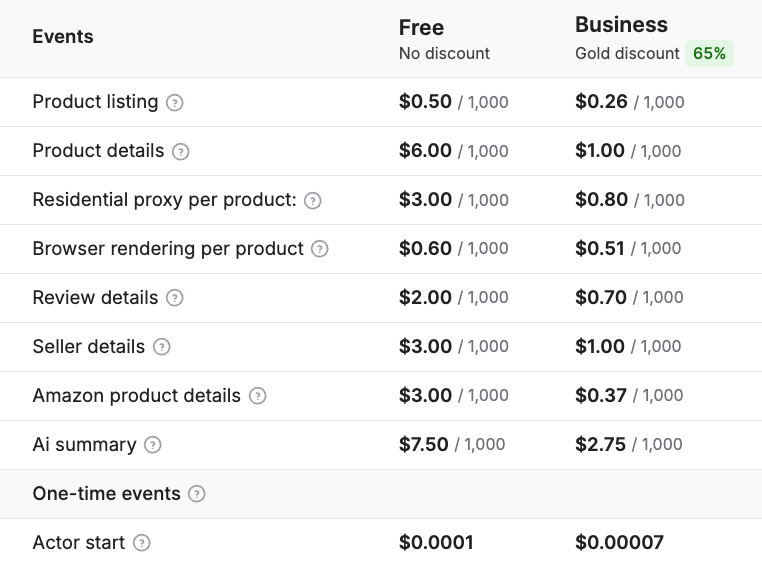
Example: Scraping 1,000 listing pages (~20,000 products)
🟡 Business plan (gold discount of 65%)
No proxies or browser rendering:
- Actor start = $0.0007
- Listings = $0.26 (for 1,000 listings)
- Product details = 20,000 × ($1.00 / 1,000) = $20.00
- Total = $0.0007 + $0.26 + $20.00 = $20.2607 → ≈ $20.26
With proxies + browser rendering:
- Actor start = $0.0007
- Listings = $0.26
- Product details = $20.00
- Residential proxy = 20,000 × ($0.80 / 1,000) = $16.00
- Browser rendering = 20,000 × ($0.51 / 1,000) = $10.20
- Total = $0.0007 + $0.26 + $20.00 + $16.00 + $10.20 = $46.4607 → ≈ $46.46
Try E-commerce Scraping Tool
For e-commerce product data, you can collect information from both listing and detail URLs across multiple websites and store it in one dataset. This lets you discover many products, track down known SKUs, and get maximum coverage in one deduplicated dataset. You can run the scraper via UI for simplicity, or programmatically via API for integration into your workflow. To track changes over time, set up webpage change alerts.





