In this article, you will learn how to build a simple scraper to extract valuable information like job titles, companies, job URLs, and locations on LinkedIn. You'll also learn the intricacies of crawling LinkedIn jobs using Python.
Imagine collecting, analyzing, and visualizing information such as job openings without lifting a finger. Automated web scraping allows you to do this. Web scrapers can be useful for recruiters, salespeople, and marketers to gather data on potential clients or employees.
If you're excited about learning about LinkedIn job scraping as much as I am writing about it, then let's dive right in 🚀
Prerequisites and preparing your environment
To follow along with this article and understand the content and code samples showcased here, you need to satisfy the following:
- Have Python installed on your computer.
- Have a basic understanding of CSS selectors.
- Be comfortable navigating browser DevTools to find and select page elements.
- Have a text editor installed on your machine, such as VSCode, PyCharm, or any editor of choice.
- Basic terminal/command line knowledge to run commands for initializing projects, installing packages, deploying sites, etc.
- Apify CLI installed globally by running this command:
npm -g install apify-cli. Check out otter installation methods in our documentation. - An account with Apify. Create a new account on the Apify platform.
Assuming that you satisfy the requirements in the prerequisites above, let's begin with setting up your development environment for scraping LinkedIn jobs
For this tutorial, I'll use an Apify Actor template, specifically, the Apify Python Starter, to quickly scaffold my project.
This template comes pre-installed with libraries such as Beautifulsoup, Apify, and HTTPX. In a previous post, I detailed everything you need to know and the steps to create your Apify Actor - from writing the script to its deployment on the Apify platform.
Is it hard to scrape LinkedIn data using Python?
Building a simple scraper to crawl smaller or less established websites is relatively straightforward and minimally complex. However, when you try web scraping on websites with greater traffic, such as LinkedIn, with dynamically loading pages and JavaScript, you may be faced with a set of challenges.
Beyond merely scraping LinkedIn jobs, you need to bypass LinkedIn's sophisticated anti-scraping measures. This will require you to scrape responsibly and also adopt techniques such as rotating proxies, rate limiting, respecting robots.txt, and IP rotation to avoid detection and possibly getting blocked by LinkedIn firewalls.
How to scrape LinkedIn with Python step-by-step
1. Getting started with Apify templates
Your first step in building your scraper entails choosing a code template from the host of templates provided by Apify.
The Actor templates allow you to quickly build the foundation of your scraper and benefit from the Apify platform's features right from the start. This saves you valuable development time and gets you scraping faster. Head over to the Actor templates repository and choose one.
Libraries included in the template
- Beautiful Soup is a Python library for extracting data from HTML and XML files. It requires minimal code and presents itself as a lightweight option for efficiently tackling basic scraping tasks.
- HTTPX offers a comprehensive set of features for making HTTP requests in Python. It allows for both synchronous and asynchronous programming styles and even has an integrated command-line client.
Running your Actor locally
To start using the Apify template to scaffold your project, run the following command in your terminal:
apify create python-actor-example -t python-start
The above command does the following:
- Uses the Apify CLI to create a new folder name
python-actor-exampleusing thepython-starttemplate from Apify. - Installs all necessary libraries, as shown in the screenshot below. This will take a couple of minutes.
Below is my folder structure of the files and folders generated:
├───.actor
│ └───actor.json
│ └───Dockerfile
│ └───input_schema.json
├───.idea
│ └───inspectionProfiles
├───.venv
├───src
│ └───__main__.py
│ └───__pycache__
│ └───main.py
└───storage
├───datasets
│ └───default
├───key_value_stores
│ └───default
│ └───INPUT.json
└───request_queues
└───default
Each of these files and folder have their respective functions. I covered the functionality of each folder and file especially in the .actor folder. Read more about their functionalities in my earlier article on Automating Data Collection with Apify: From Script to Deployment.
To run your Actor, navigate to the newly created Actor's folder and run it locally. Run the following commands to do this:
cd python-actor-example
apify run
The above commands change your working directory to python-actor-example, and then use the Apify CLI runcommand to run the scraper locally.
In the next section, I'll walk you through making changes to some of these files. You'll also learn how to use Chrome DevTools to understand LinkedIn’s site structure and scrape LinkedIn jobs.
2. Using Chrome DevTools to understand LinkedIn’s site structure
There are two ways to search for LinkedIn jobs:
- Advanced search (with cookies): Search as an authenticated user (you'll need to provide your LinkedIn cookies)
- Basic search (without cookies): Search as an unauthenticated user (this entails crawling through the LinkedIn job search page as a visitor; you won't need to provide your cookies). This is safer and supports proxy rotation for faster scraping with concurrency.
We'll focus on the second method: scraping LinkedIn job data as a visitor.
3. Find your jobs, then extract the data
- Head over to LinkedIn's job search page (as a guest - don't be signed in)
- Apply the filters you need to narrow down your search. In this case, I'm searching for jobs that match 'Software Developer' in 'United States' posted 'Any time".
- Once you're happy with the results, copy the entire URL from your browser's address bar (see screenshot below).
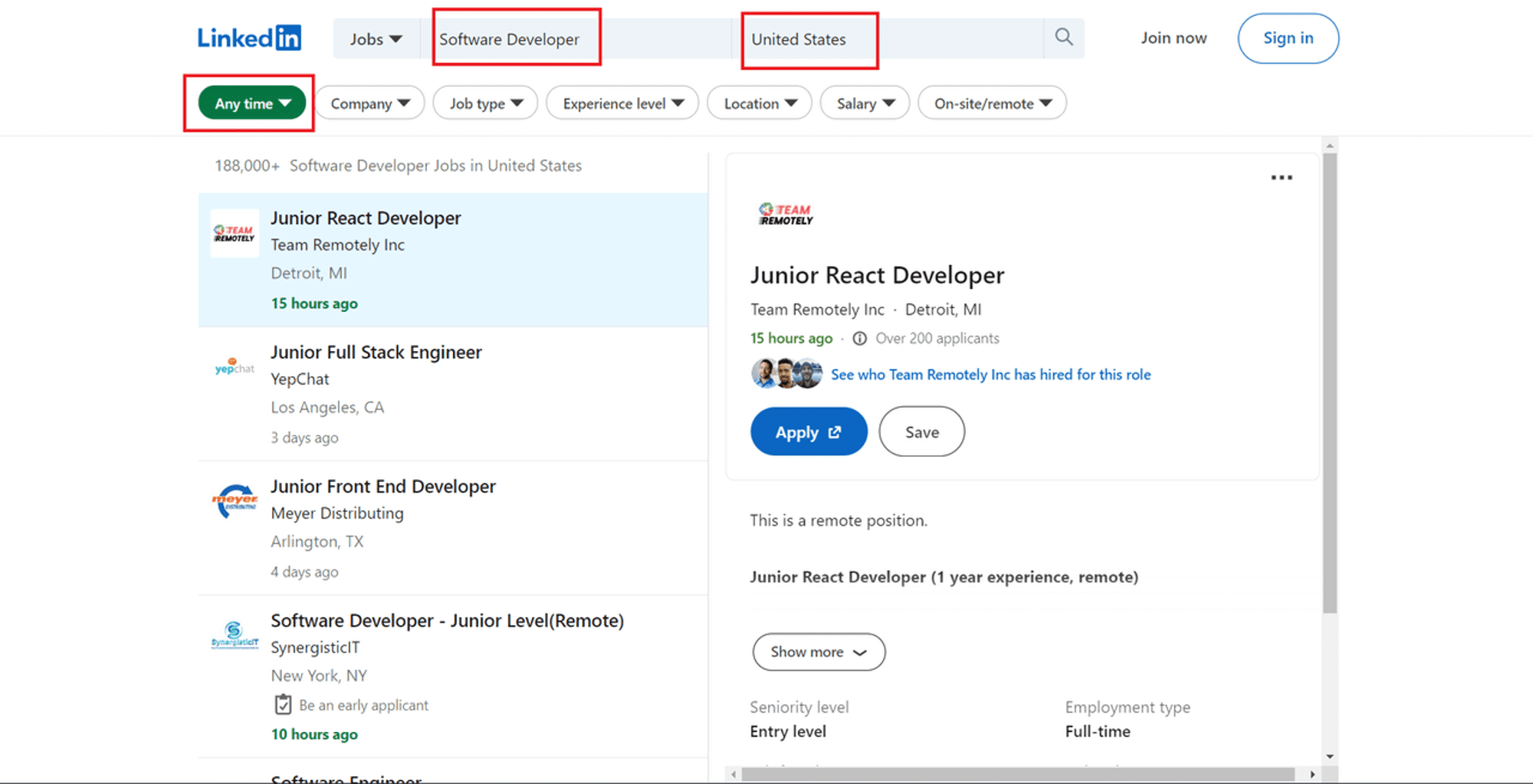
Open Chrome DevTools by pressing F12 or right-clicking anywhere on the page and choosing Inspect. Inspecting the page from the URL above reveals the following:
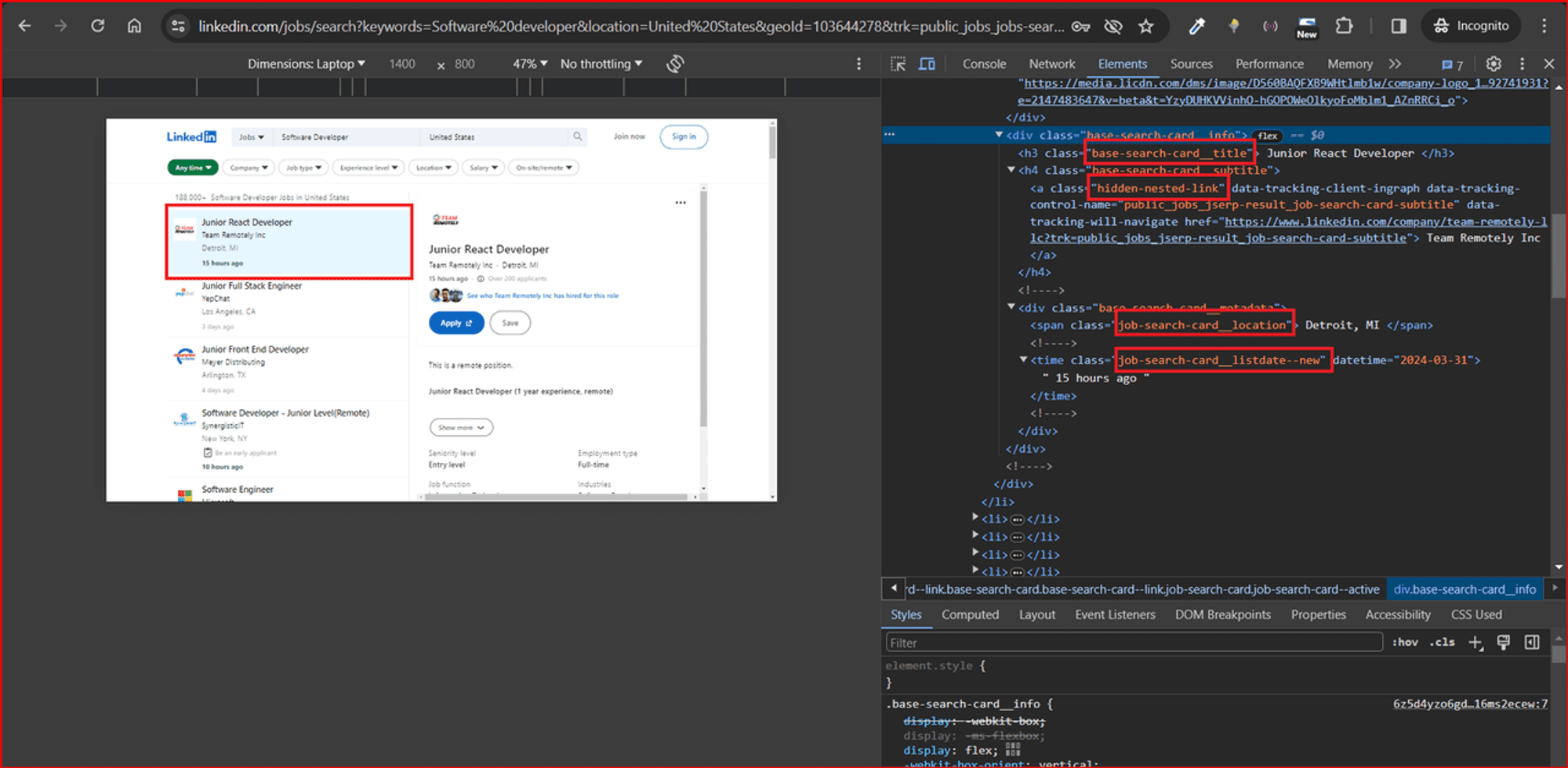
Running the commands below in the console returns the respective details about each job posting, such as job title, company name, job URL, job location, and date posted:
$(".base-search-card__title").textContent.trim()returns 'JavaScript Developer'$(".job-search-card__location").textContent.trim()returns 'Charlotte, NC'$(".job-search-card__listdate--new").textContent.trim()returns '9 hours ago'$(".base-card__full-link").getAttribute("href")returns this page.$(".hidden-nested-link").textContent.trim()returns 'Phoenix Recruitment'
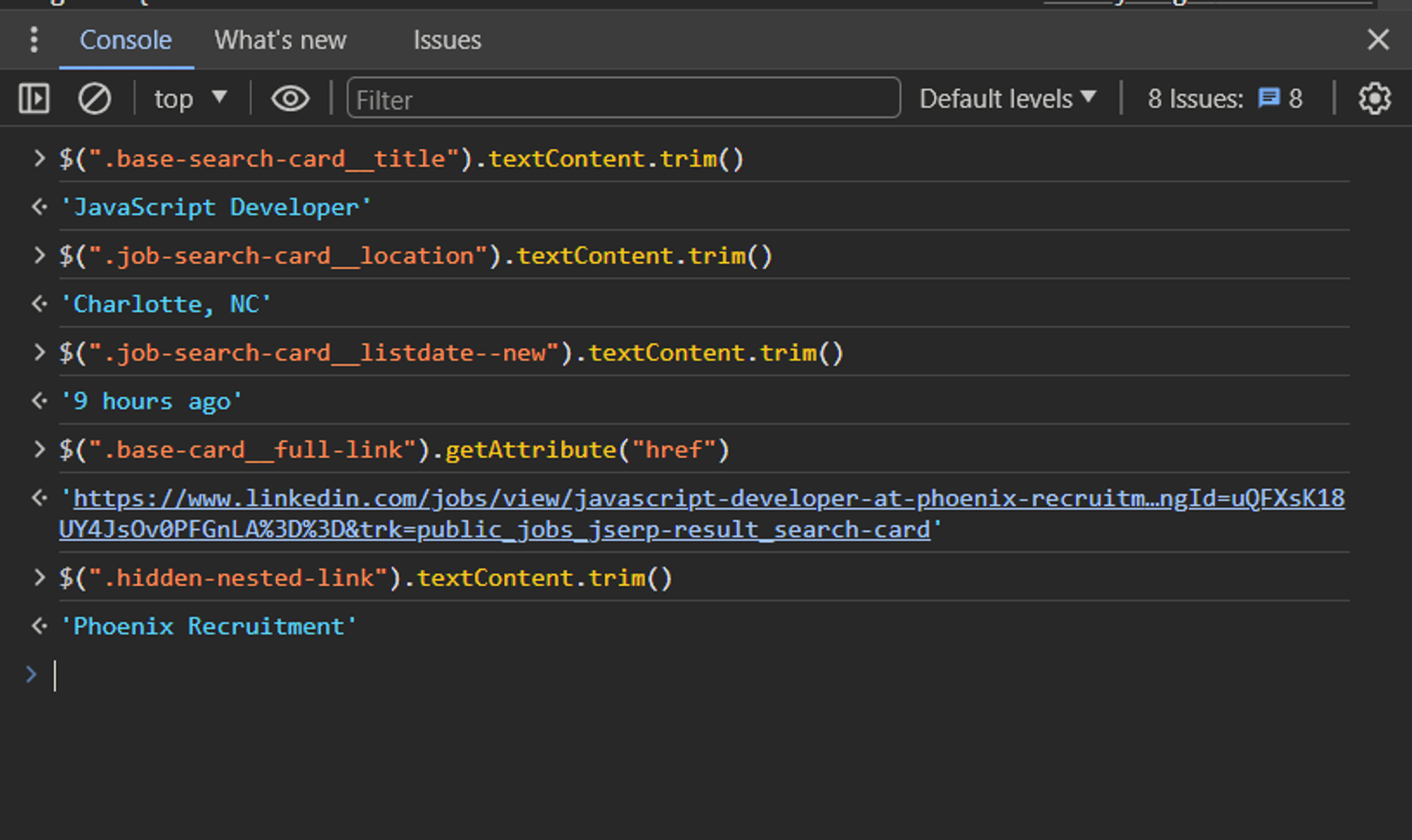
This information will constitute the data returned by the LinkedIn job scraper.
4. Dealing with infinite scrolling
LinkedIn is one of those social media websites that adopted infinite scrolling. Infinite scrolling replaces pagination to improve the user experience and increase engagement. While infinite scrolling has numerous advantages, it poses serious issues for web scraping.
You might have noticed that as soon as you scroll down on the LinkedIn job search page, additional content keeps loading. This means that new job listings are loaded dynamically as you scroll down the page, making it difficult to extract data from all available jobs in a single request.
To solve this infinite scroll problem, I'll modify the search page URL with the DevTools' network tab.
Using DevTools to bypass infinite scroll
- Open the network tab: Open your browser's developer tools and navigate to the network tab. This tab displays all the requests made by the page as it loads.
- Search for jobs requests: When you scroll down on the LinkedIn jobs page, you will see new requests appear in the Network tab. Look for requests that are related to fetching new job listings. This contains the keyword "search" in the URL.
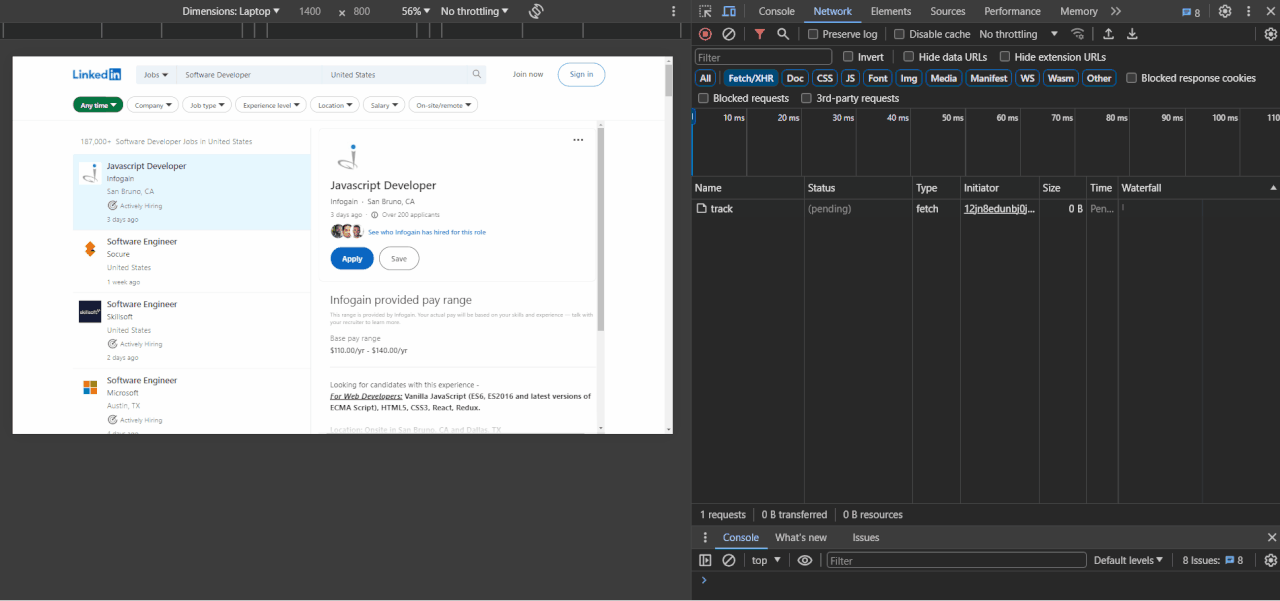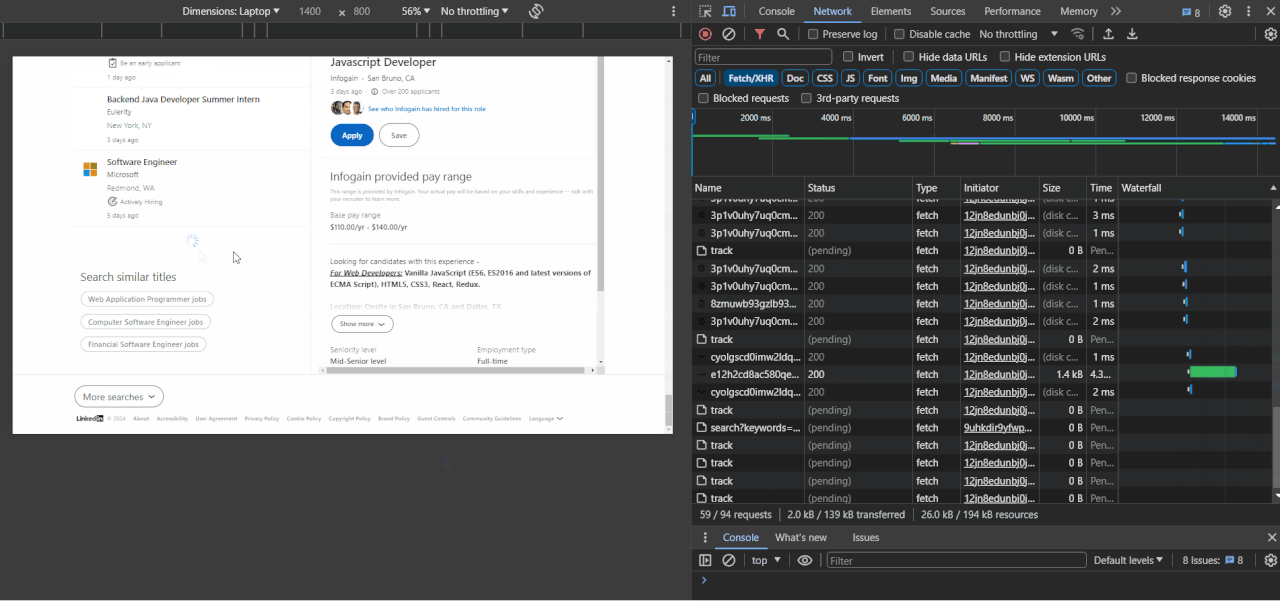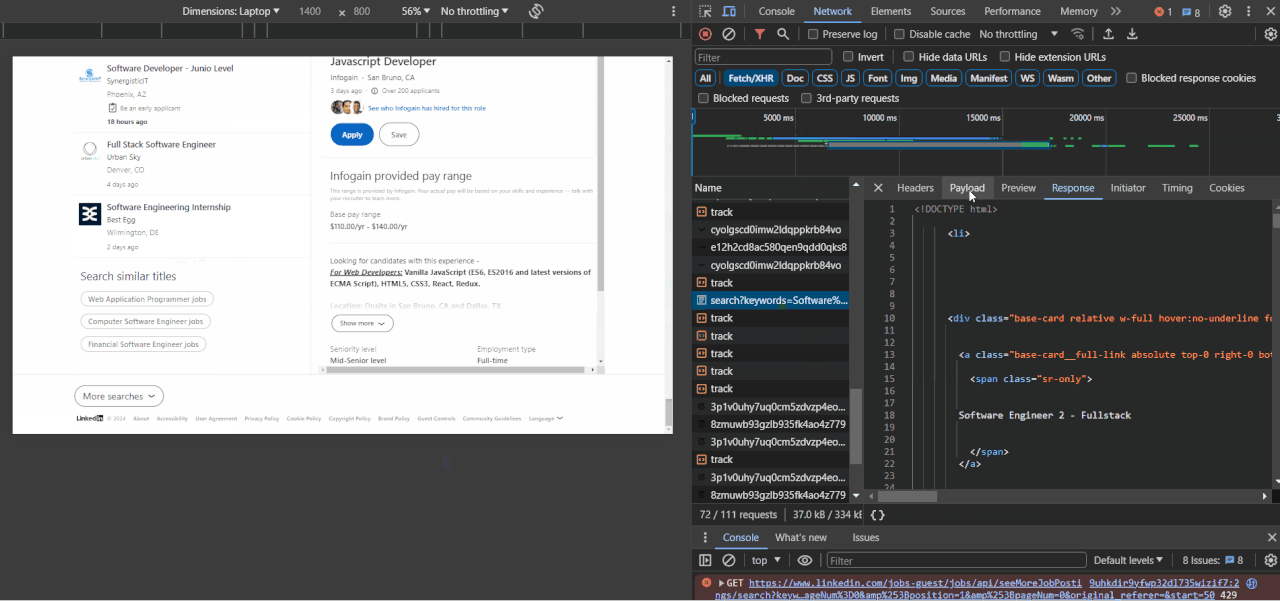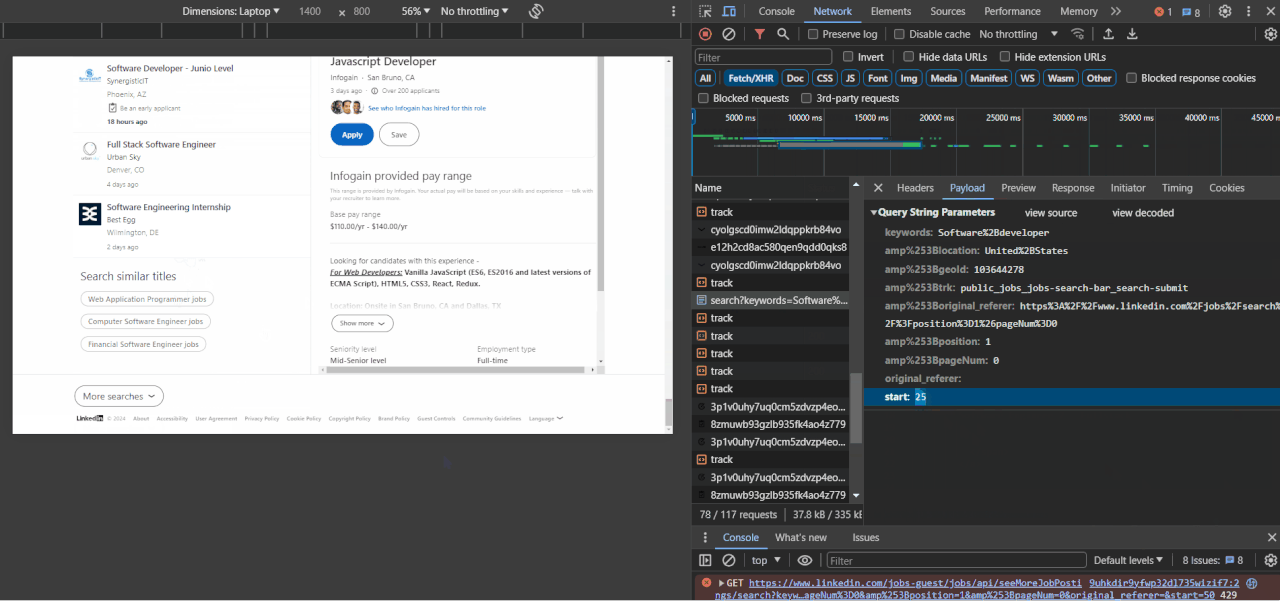
- Identify pagination parameters: Once you've identified the relevant request, click on it and examine the details. Look for parameters in the URL that change as you scroll down. You'll notice that the "start" parameter changes from
0and increases as more job data are loaded on the page.
In the next step, we'll focus on the main purpose of this article: how to scrape LinkedIn job postings.
5. Scraping LinkedIn job data
You'll need to re-visit the Actor you created earlier. Open the INPUT.json file in ./storage/key_value_stores/default/INPUT.json and then replace https://apify.com/ with the LinkedIn job search page URL like so:
{
"url": "https://www.linkedin.com/jobs/search?keywords=Software%20developer&location=United%20States&geoId=103644278&trk=public_jobs_jobs-search-bar_search-submit&original_referer=https%3A%2F%2Fwww.linkedin.com%2Fjobs%2Fsearch%2F%3Fposition%3D1%26pageNum%3D0&position=1&pageNum=0"
}
Now, open your ./src/main.py file, and let's make some changes to this file to allow scraping of the different job details about each job posting.
Copy and paste this:
# main.py
# leave other imports as they are
async def main() -> None:
"""
The main coroutine is being executed using `asyncio.run()`, so do not attempt to make a normal function
out of it, it will not work. Asynchronous execution is required for communication with the Apify platform,
and it also enhances performance in the field of web scraping significantly.
"""
async with Actor:
# Structure of input is defined in input_schema.json
actor_input = await Actor.get_input() or {}
url = actor_input.get('url')
# Create an asynchronous HTTPX client
async with AsyncClient() as client:
# Fetch the HTML content of the page.
response = await client.get(url, follow_redirects=True)
# Parse the HTML content using Beautiful Soup
soup = BeautifulSoup(response.content, 'html.parser')
# Extract all job details from the page
jobs = []
for job_card in soup.find_all("div", class_="base-card"): # Because job details are
# within ".base-card" class
job_details = {}
# Extract job title
job_title = job_card.find("h3", class_="base-search-card__title")
if job_title:
job_details["title"] = job_title.text.strip()
else:
job_details["title"] = None # Handle cases where title is missing
# Extract company name
company_name = job_card.find("a", class_="hidden-nested-link")
if company_name:
job_details["company"] = company_name.text.strip()
else:
job_details["company"] = None # Handle cases where company name is missing
# Extract job URL
job_url = job_card.find("a", class_="base-card__full-link")
if job_url:
job_details["job_url"] = job_url["href"]
else:
job_details["job_url"] = None # Handle cases where job URL is missing
# Extract job location
job_location = job_card.find("span", class_="job-search-card__location")
if job_location:
job_details["location"] = job_location.text.strip()
else:
job_details["location"] = None # Handle cases where location is missing
# Extract date posted (assuming class reflects posting time)
date_posted = job_card.find("time", class_="job-search-card__listdate--new")
if date_posted:
job_details["date_posted"] = date_posted.text.strip()
else:
job_details["date_posted"] = None # Handle cases where date is missing
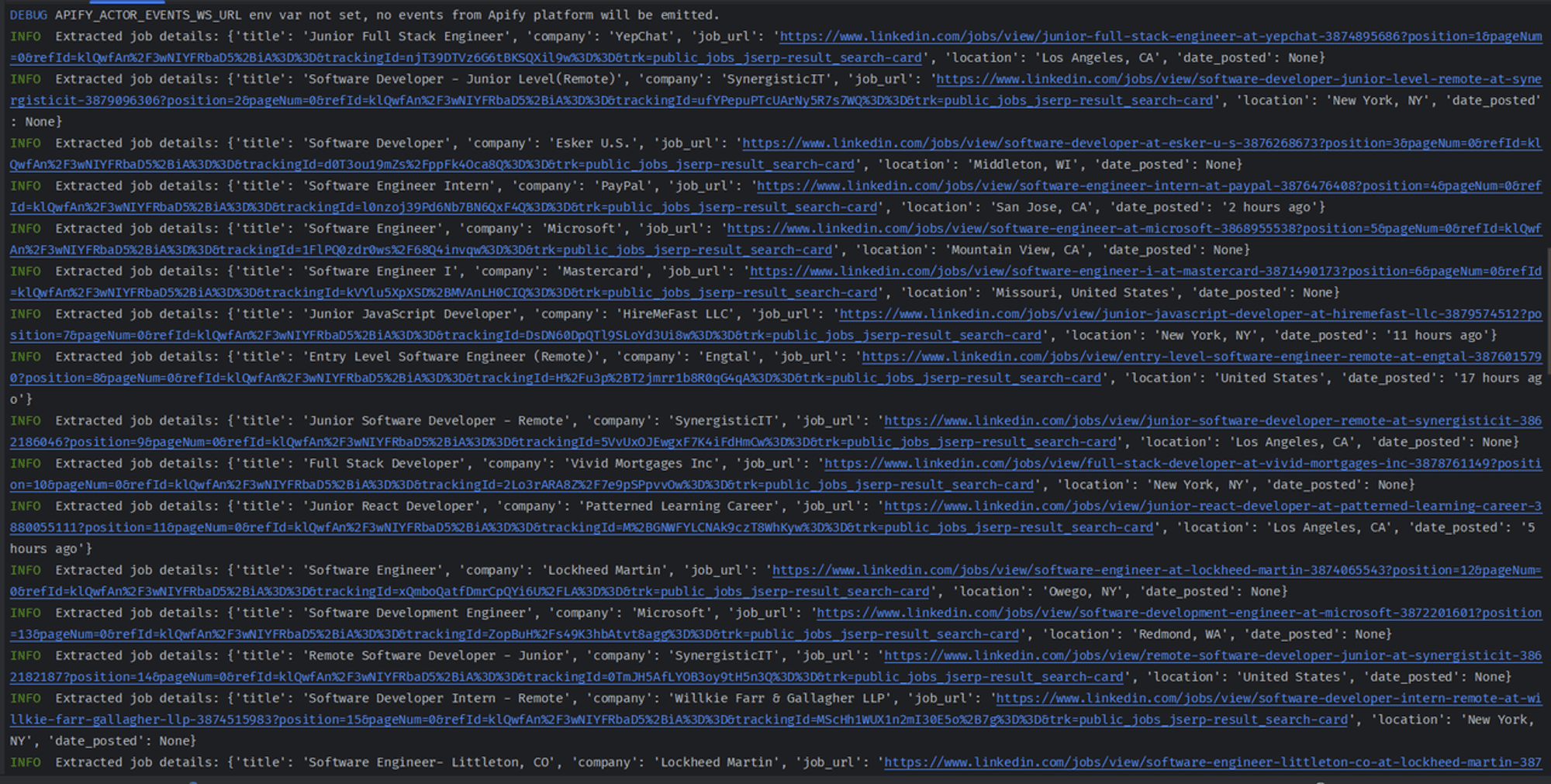
Actor.log.info(f"Extracted job details: {job_details}")
jobs.append(job_details)
# Save jobs data to Apify Dataset
await Actor.push_data(jobs)
What the above code snippet does
The url corresponds to the URL from the INPUT.json file. The code then uses the Beautiful Soup library to extract data. After getting the job data, I iterate over the job data. I then find all elements on the webpage that represent individual job listings based on a specific class name "base-card" representing the parent CSS class for each job.
I extract the job title, job URL, company name, job location, and date posted iteratively by looping through each job listing. I return None if any of these details are missing. I then use Apify SDK to save the list of extracted job details into a dataset.
To run your scraper, insert the following command in your terminal:
python src/__main__.py
Next, we'll go through how to export the scraped data to a CSV file.
6. Exporting scraped LinkedIn data to a CSV file
To export data to CSV format, you'll need to import the csv Python library. However, CSV files can be inconsistent, incomplete, or messy, which can affect the quality and reliability of your analysis.
Data cleaning is important because it ensures you have data of the highest quality, which can prevent errors, increase productivity, and improve data analysis and decision-making.
For this reason, you'll also need to import the re library, a Regular expression operations Python library.
Update the code above to the following:
# other imports remain unchanged
# Import libraries for data cleaning
import re
import csv
# ...
# Save jobs data to CSV file
with open("scraped_linkedin_jobs.csv", "w", newline="", encoding="utf-8") as csvfile:
fieldnames = job_details.keys() # Get field names from first job dictionary
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(jobs)
# Save jobs data to Apify Dataset
await Actor.push_data(jobs)
Inside the loop that iterates through jobs, I added a block to clean the data. The code iterates through each key-value pair in the job_details dictionary.
If a value exists, it uses a regular expression (re.sub) to replace any non-alphanumeric characters (\\\\w) or spaces (\\\\s) with an empty string (''). This helps ensure cleaner data for the CSV file.
I opened a CSV file for writing with open(). I then retrieved the field names (column headers) from the keys of the first job_details dictionary.
Using the csv library, I created a DictWriter object specifying the fieldnames and wrote the header row (writer.writeheader()).
Finally, I used writer.writerows(jobs) to write all the job details dictionaries to the CSV file.
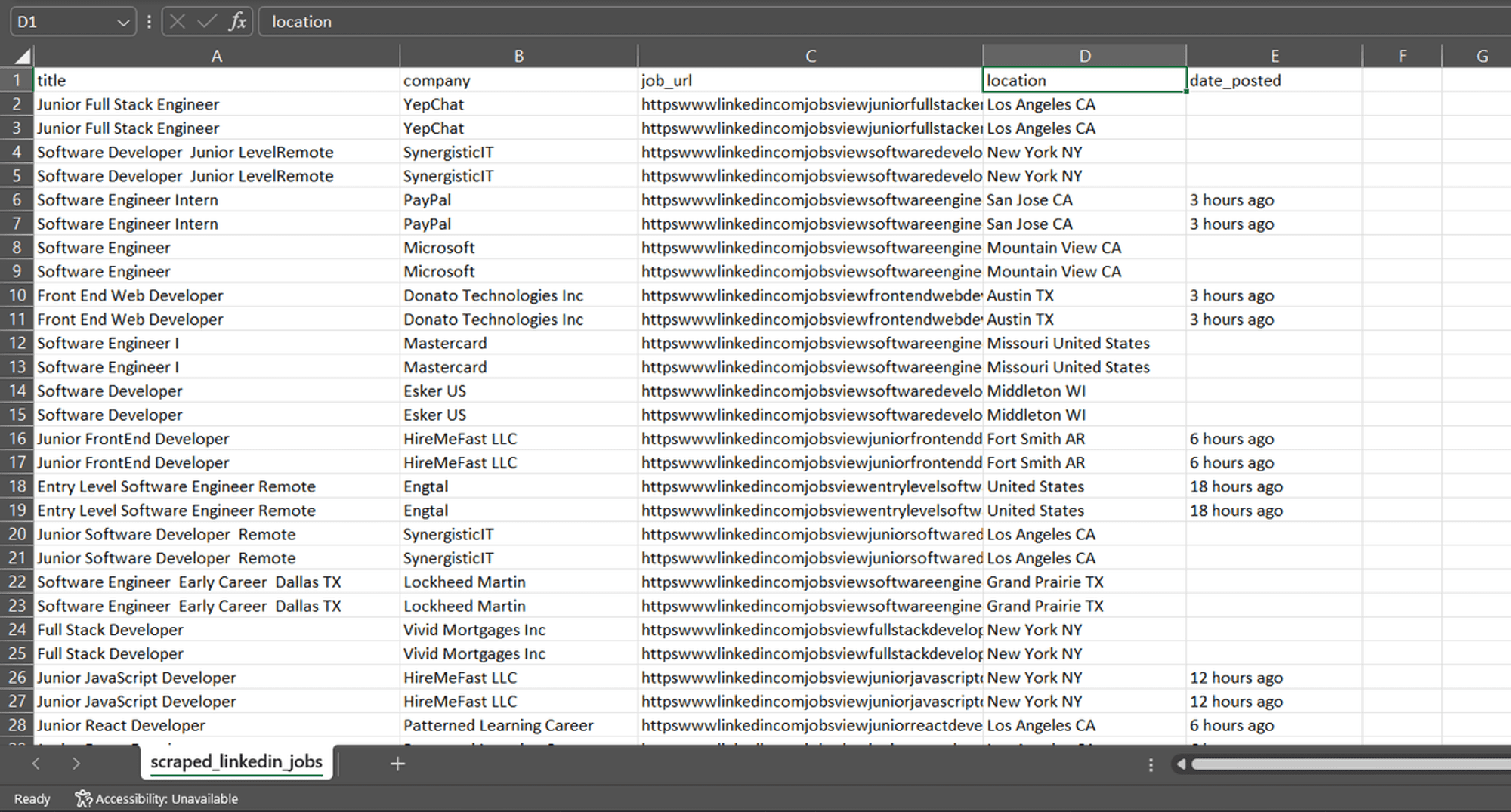
I'm still using the Apify SDK to save the list of extracted job details into a dataset.
7. Bypassing anti-bot detection
When scraping small or less established websites, you might not face any blocking issues. But if you try to scrape established websites or dynamically loading pages with JavaScript, you might run into issues such as blocked requests, IP address blocking and blacklisting, Cloudflare errors (403, 1020), and more.
To bypass these restrictions, you must employ some responsible behaviors while scraping. Some of these include:
- Respecting the robots
- Rotate your IPs
- Using CAPTCHA solvers
- Configuring a real user agent
- Updating your request headers
- Avoiding the honeypots
- Wiping your fingerprints
- Using a headless browser
Learn more about these points in our detailed post on how to crawl a website without getting blocked.
8. Scheduling and monitoring your LinkedIn job scraper
You can configure your scraper to run at different schedules and triggers. This will allow you to scrape data at designated periods of time. The Apify platform also allows you to manage and monitor your scraper.
Follow the steps below to learn how to deploy and automate your scraper (Actor).
Log in to your scraper on your Apify account
You'll need to create an account with Apify if you haven't already done so.
Connect your Apify account with your Actor locally. To complete this action, you'll need to provide your Apify API token.
To get your Apify API token, navigate to API Console. Then click on "Settings" > "Integrations" and copy your API token.
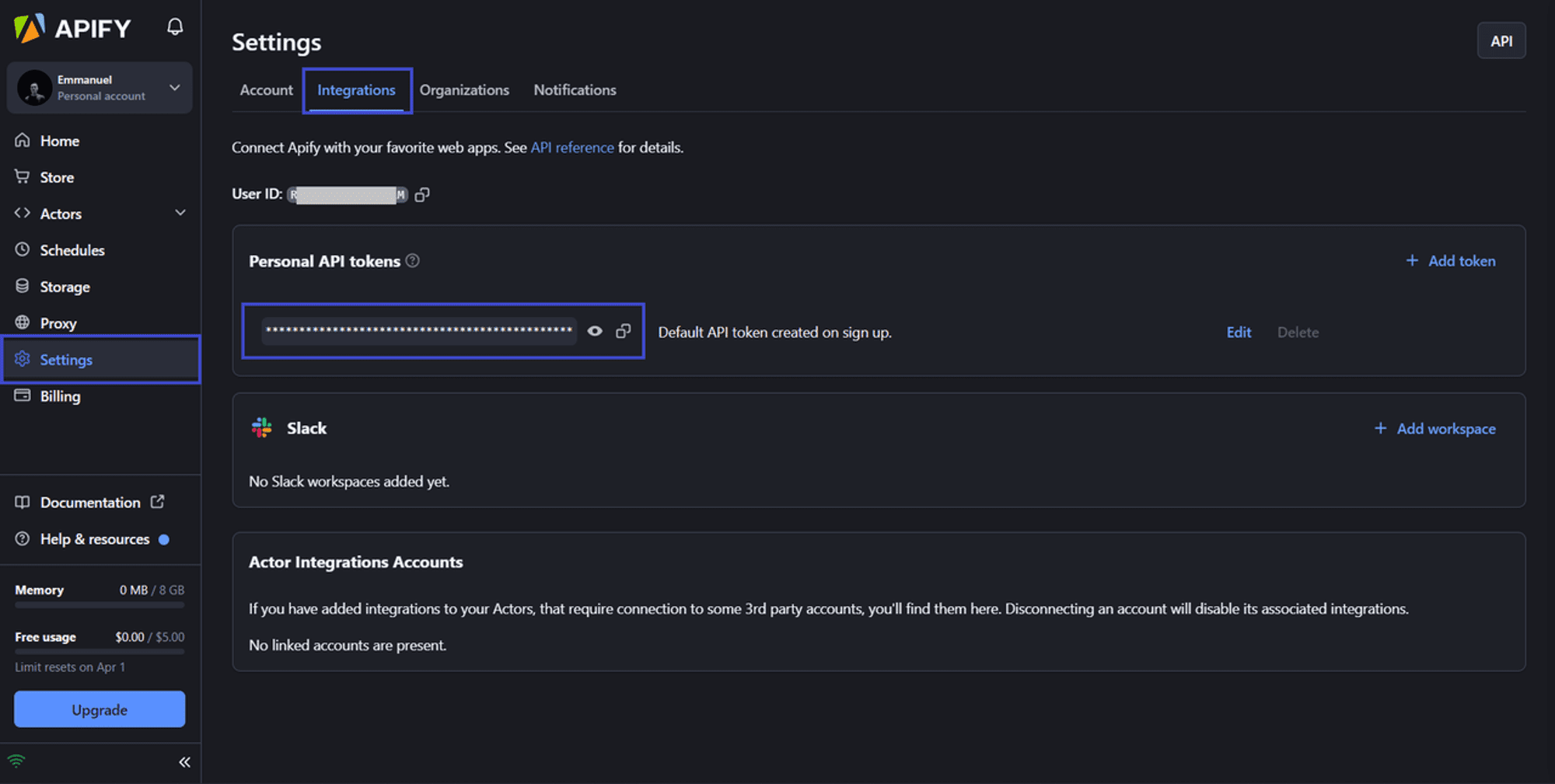
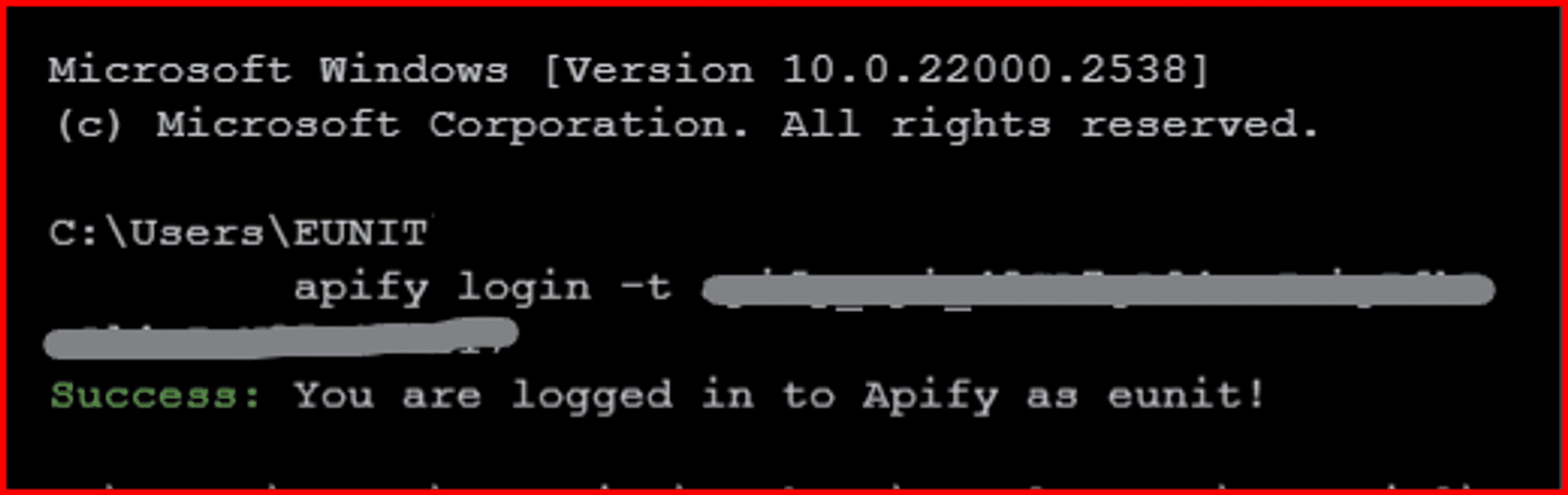
Now, in your terminal, change the directory into the root directory of your created Actor, then run this command to sign in:
apify login -t YOUR_APIFY_TOKEN
Replace YOUR_APIFY_TOKEN with the token you just copied.
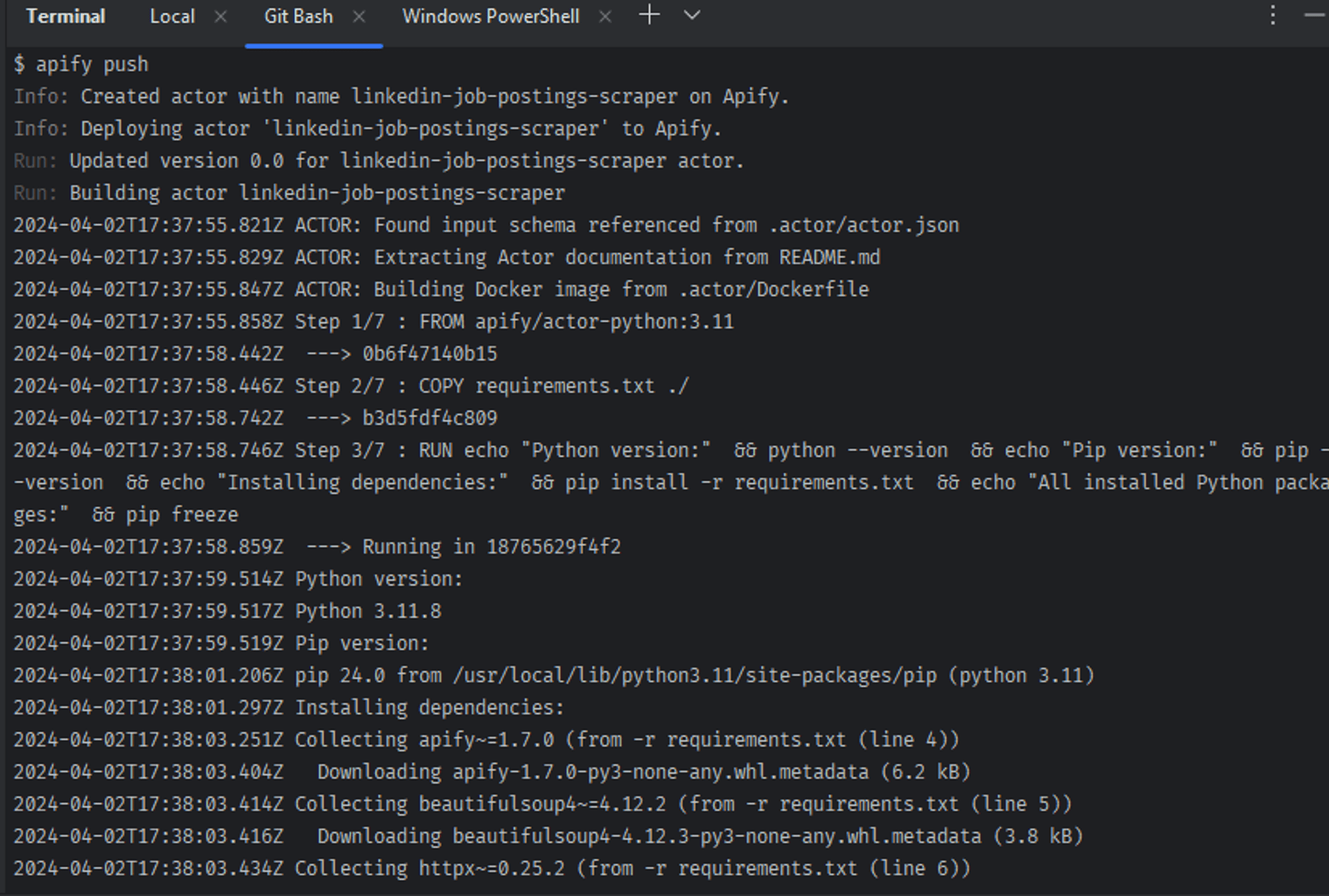
Deploy your scraper to the cloud
The Apify CLI provides a command that you can use to deploy your Actor to the Apify Actor store
apify push
The command above will push your created Actor to the Apify cloud and will display some logs on your terminal (see screenshot below).
You can find your newly created Actor under My Actors.
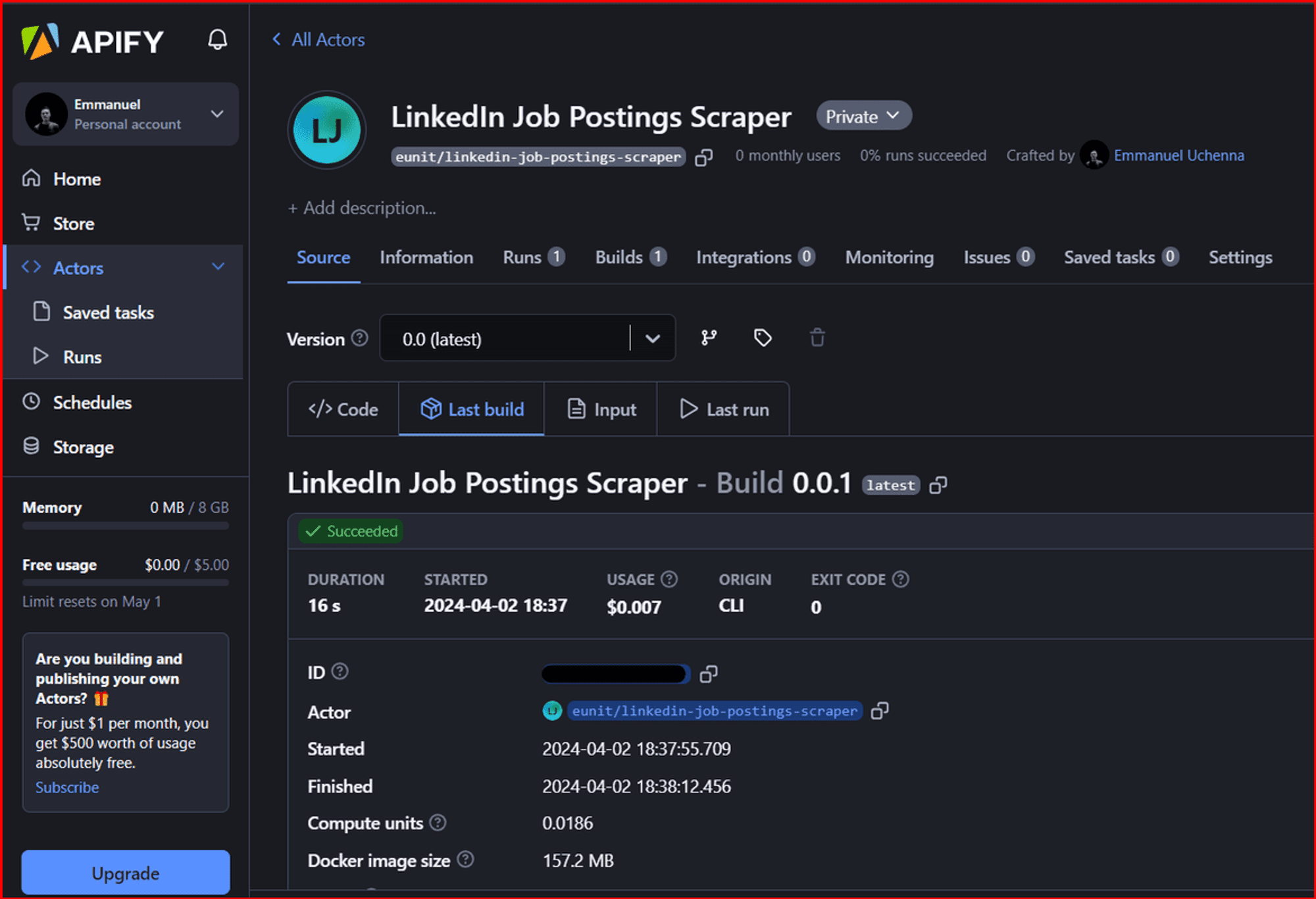
The Actor tabs allow you to see the code, last build, input, and last run.
You can also export your dataset by clicking on the Export button. The supported formats include JSON, CSV, XML, Excel, HTML Table, RSS, and JSONL.
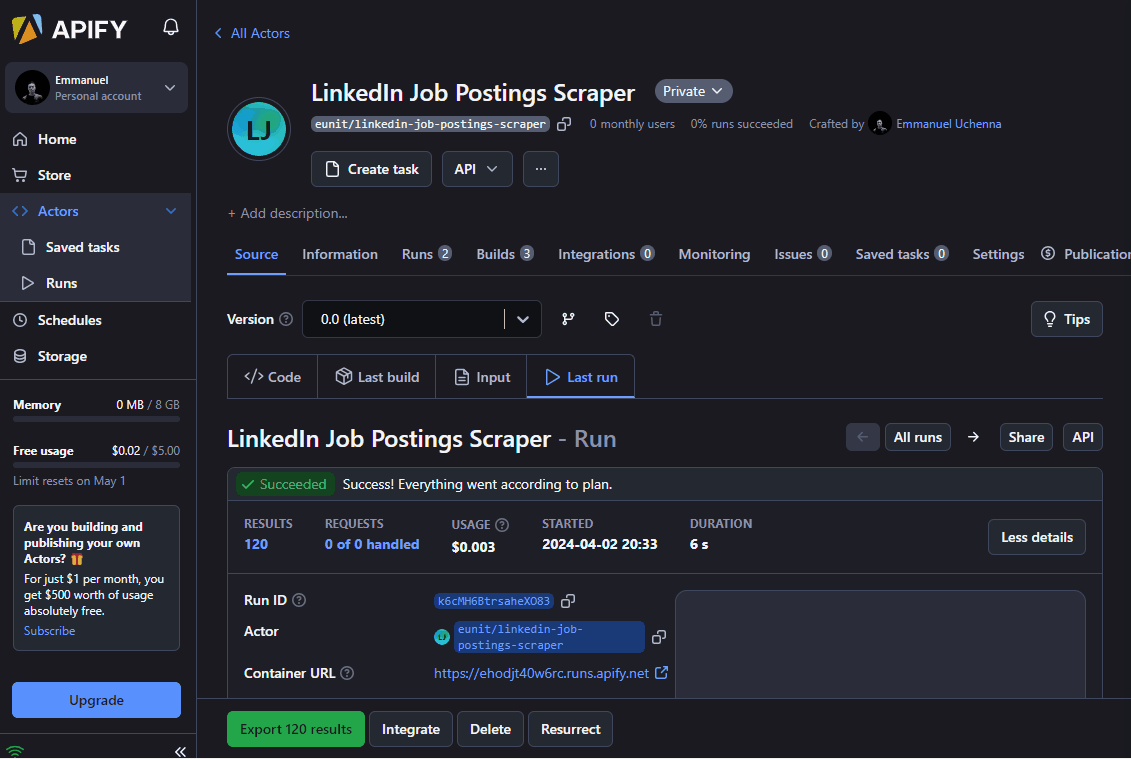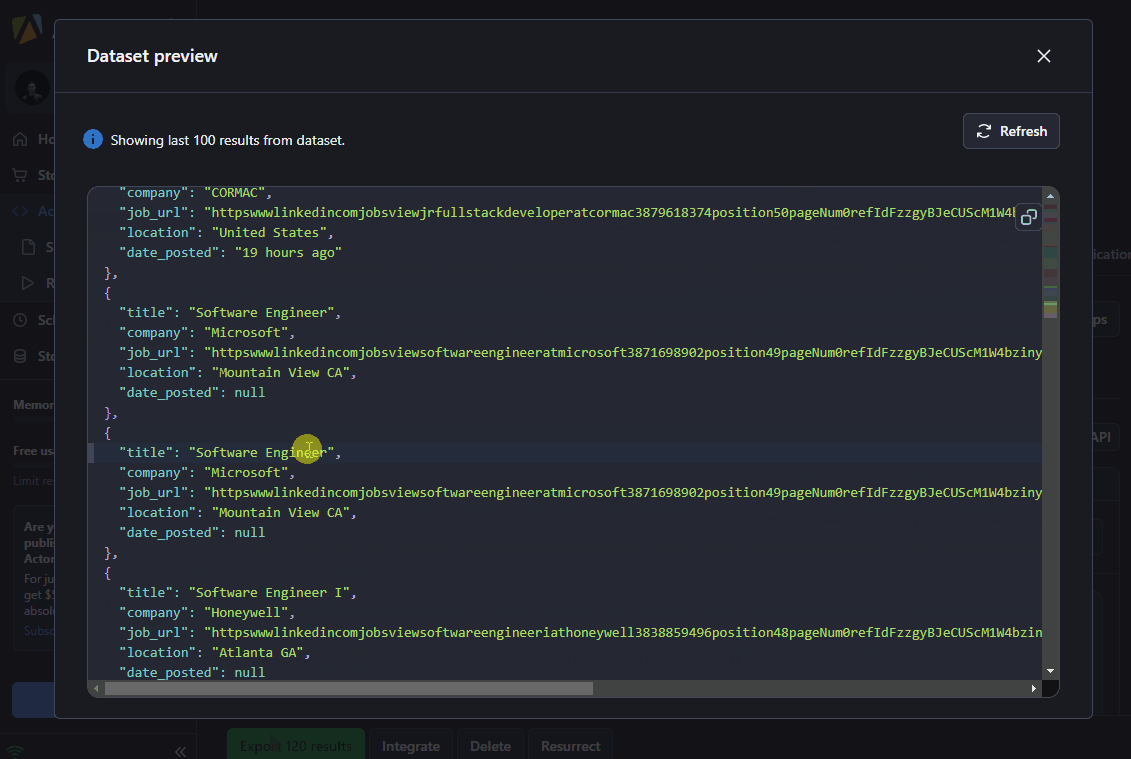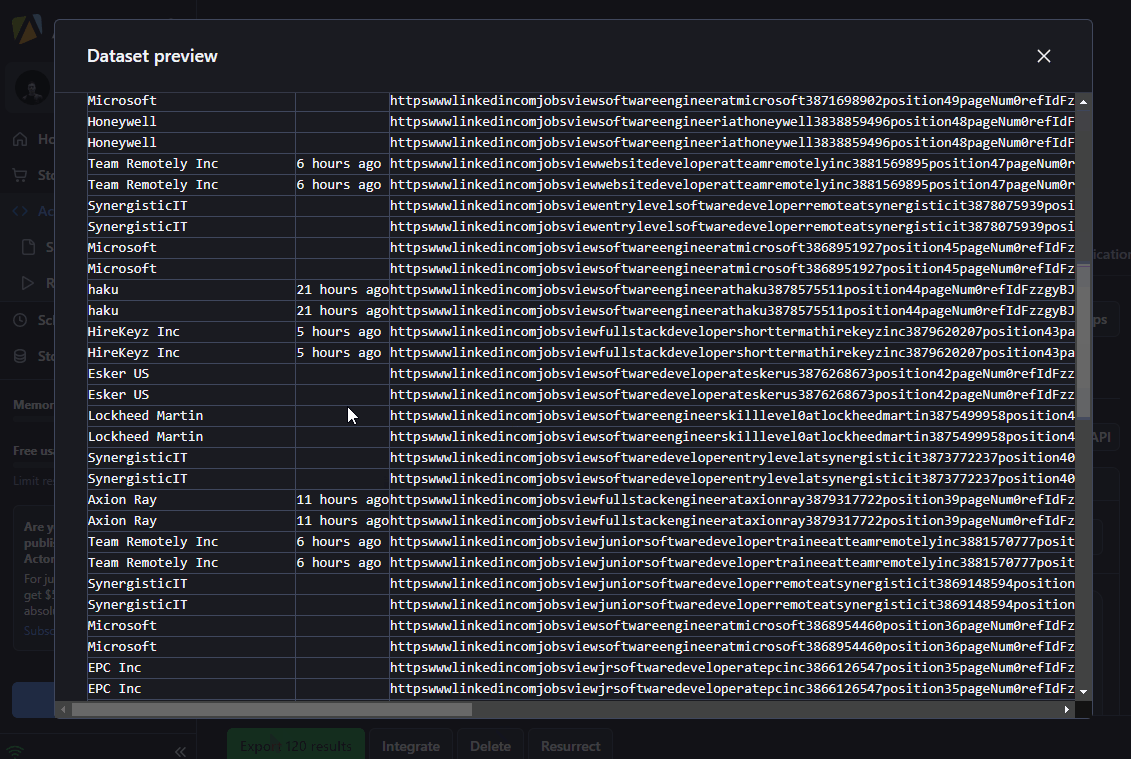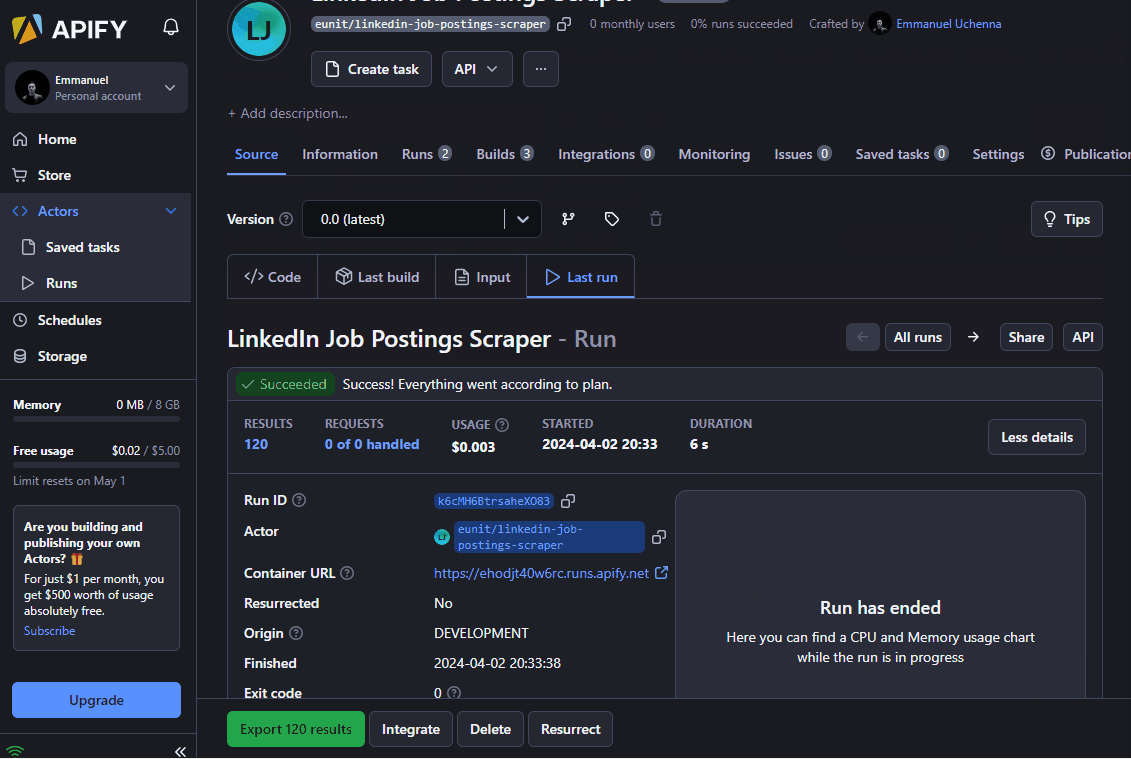
Check out the LinkedIn Job Postings Scraper on Apify Store 🚀
FAQs
Is it legal to scrape LinkedIn?
Yes, it is legal to scape LinkedIn for publicly available information, such as job postings. But it's important to remember that this public information might still include personal details. We wrote a blog post on the legal aspects of web scraping and ethical considerations. You can learn more there.
Is there a LinkedIn API that can be used with Python?
Yes, LinkedIn offers an official API that you can use to create applications that help LinkedIn members. However, it might not be the most suitable solution for your project.
Many developers have reported some drawbacks of the LinkedIn API, citing various reasons. Among the drawbacks cited are LinkedIn's API rate limits and limited data scope.
Wrapping up
In this article, I walked you through everything you need to know to build your LinkedIn job posting scraper with Python and Apify.
You learned how important LinkedIn is as a source of valuable data, including job listings, profiles, and connections. This data can be useful for various purposes like lead generation, talent sourcing, and market research.
Apify offers a vast documentation library and a supportive community to guide you in becoming a web scraping expert.
Get started with Apify today 🚀