


Hi! We're Apify, a full-stack web scraping and browser automation platform. If you're interested in using Python for web scraping, this article shows you an easy way to scrape HTML tables.
HTML tables are a common structure of information storage on the web. So, when scraping websites, you're quite likely to encounter tabular data. I'm going to show you a really fast way to scrape them with Python using Pandas.
Pandas is a great open-source software library for the Python language. It's a really fast, powerful, and flexible tool for data manipulation and analysis.
Why use Pandas to scrape HTML tables?
You might be thinking, why not use BeautifulSoup, MechanicalSoup, or even Scrapy for such a task? And yes, if you're looking to scrape images or any other kind of element, you'll need to use one of those tools. But if all you need is HTML tables, using Pandas is a great shortcut, and you won't need to open DevTools even once!
Pandas has a read_html() function that lets you turn an HTML table into a Pandas DataFrame. That means you can quickly extract tables from websites without having to work out how to scrape the site's HTML.
How to scrape HTML tables with Python
Prerequisites
To emulate what I'm about to show you, you'll need to have Python installed. If you don't have it already, you can download Python from the official website. Use Python 3.6 or later.
You can use any code editor, but for this, I'm going to use Jupyter Notebook.
If you haven't set it up yet, you can do so by installing the entire Anaconda distribution (which includes Jupyter and many other useful data science packages), or you can install Jupyter separately via pip in your virtual environment:
pip install notebook
You can then activate your virtual environment where Jupyter was installed and run jupyter notebook in your terminal or command prompt. This command will start the Jupyter Notebook server and open the interface in your default web browser.
Now click on New, choose Python 3, and then name your file. I'm going to call this project Yahoo_Pandas.

Setting up the environment
You'll need to install Pandas and lxml, which Pandas uses under the hood to parse HTML. Type the following command in your terminal:
pip install pandas lxml
Then import Pandas:
import pandas as pdUsing the Pandas read_html function
Pandas has a really convenient function, pd.read_html, which automatically parses tables from a given HTML page. I'll use it to fetch tables from the 'Stocks: Most Actives' page on the Yahoo Finance website:
yahoo = pd.read_html ("https://finance.yahoo.com/most-active/")
yahoo
yahoo doesn't have any inherent function; it's merely a label for the data that is being manipulated. The choice of variable name is subjective and depends on your preferences and the context of the code. In this case, I chose the name yahoo because I named the project Yahoo_Pandas, and it clearly indicates the source of the data.In my case, this worked just fine:
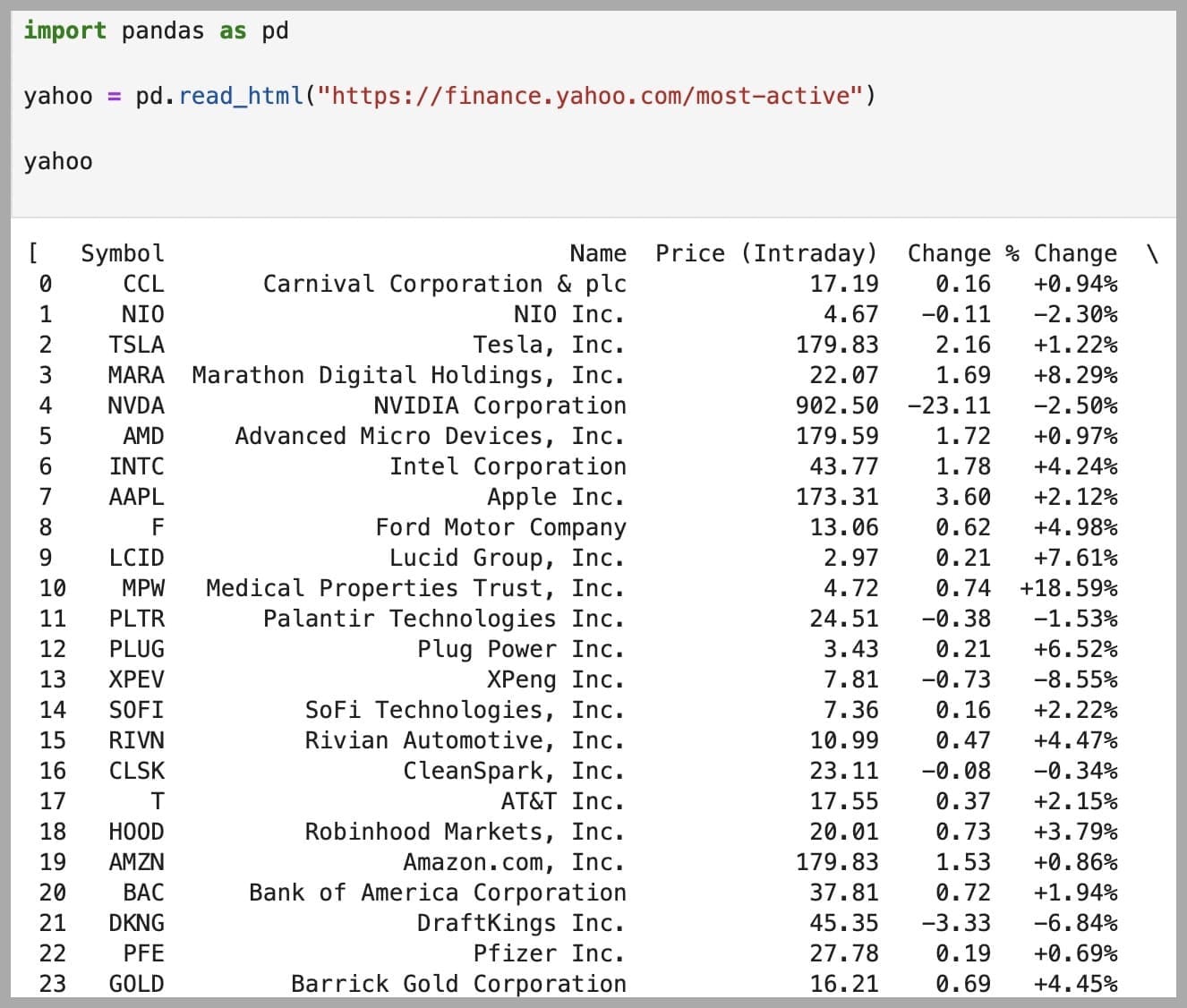
However, depending on what machine you're using, it's possible that this could result in an SSL Certificate Verification Error.
If that happens, you can fix the problem by importing SSL and adding the following: ssl._create_default_https_context = ssl._create_unverified_context.
So, the code would now look like this:
import pandas as pd
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
yahoo = pd.read_html ("https://finance.yahoo.com/most-active/")
yahoo
Scraping a single table
pd.read_html returns a list of all tables found on the page. If you're interested in a specific table, you'll need to identify it by its index (use 0 for the first table, 1 for the second, etc):
# Assuming you want the first table
table_df = yahoo[0]
print(table_df.head())
Make sure that the variable you use after pd.read_html is the one you attempt to index from to get your desired table. In this case, yahoo is the variable that holds the list of DataFrames returned by pd.read_html.
So, your code will look like this:
import pandas as pd
yahoo = pd.read_html("https://finance.yahoo.com/most-active")
table_df = yahoo[0]
print(table_df.head())
If you needed to fix an SSL Certificate Verification Error, it would now look like this:
import pandas as pd
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
yahoo = pd.read_html("https://finance.yahoo.com/most-active")
table_df = yahoo[0]
print(table_df.head())
And here's the result:
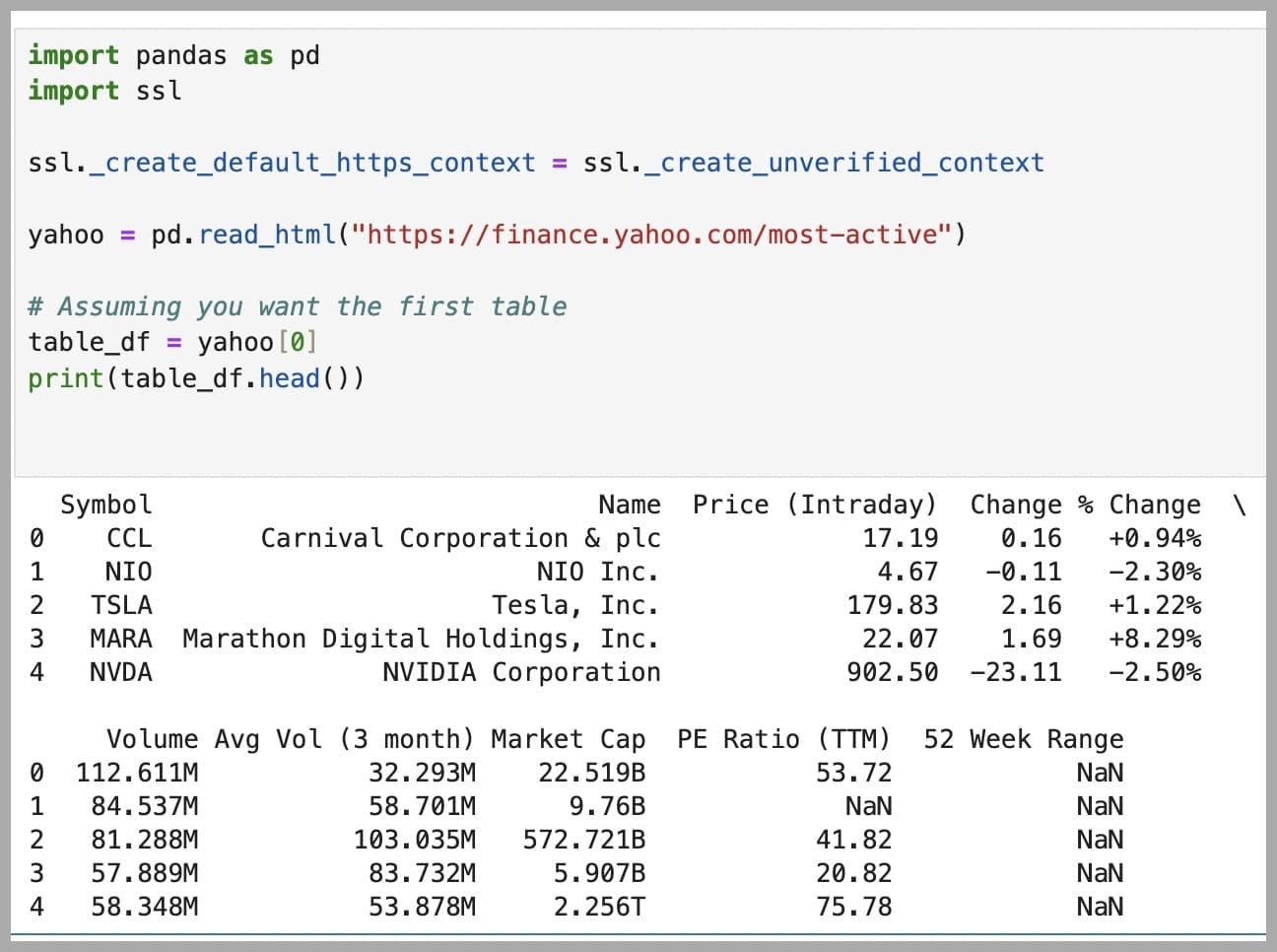
Now that you have all the values you want in a Pandas DataFrame, you can upload it to an SQL server for data organization, querying, and analysis or turn the DataFrame into a plot with Matplotlib for data visualization.
Benefits of using Pandas over MechanicalSoup or BeautifulSoup
Using Pandas for scraping HTML tables not only saves a lot of time but also makes code more reliable because you're selecting the entire table, not individual items inside the table that may change over time.
The read_html method lets you directly fetch tables without needing to parse the entire HTML document. It's way faster for extracting tables since it's optimized for this specific task, and it directly returns a DataFrame, which makes it easy to clean, transform, and analyze the data.
Disadvantages of Pandas: when you need traditional scrapers
read_html is a great shortcut for scraping HTML tables, but it lacks the flexibility to scrape other types of data or interact with the page (e.g., filling out forms, clicking buttons, navigating pages). And while it works with well-defined tables, it may struggle with complex or irregular HTML structures.
In those cases, you should opt for a traditional web scraping tool like MechanicalSoup, BeautifulSoup, or Scrapy.
You can learn more about web scraping with these tools below.
Further reading
- Web scraping with Beautiful Soup and Requests
- How to parse HTML with PyQuery or Beautiful Soup
- MechanicalSoup: a good tool for web scraping?
- Web scraping with Scrapy 101
- Scrapy vs. Beautiful Soup: which one to choose for web scraping?
- Why is Python used for web scraping?
- What are the best Python web scraping libraries?





