The applications of NLP are increasing day by day, starting from voice assistants like Alexa and Siri, automatic text summarization, and sentiment analysis. Even YouTube and Netflix use NLP to suggest what we should watch next. These applications were not easy to implement during the early days of NLP, which relied on traditional approaches. Recent advancements in the field of NLP have made things easier to implement and use.
But our goal for today is to learn about some basic NLP techniques, as these definitely still have their uses in the era of LLMs. In this article, we’ll use Twitter data scraped using the web scraping and automation platform, Apify and implement NLP techniques on that data.
How to set up the environment
To start setting up NLP and Apify, you'll need to create a new directory and a Python file. You can do this by opening your terminal or command line and entering the following commands:
mkdir NLP
cd NLP
touch main.ipynb
Let's install the packages. Copy the command below, paste it into your terminal, and press Enter.
pip3 install apify-client nltk pandas scikit-learn spacy
This should install the dependencies in your system. To confirm that everything is installed properly, you can enter the following command in your terminal:
pip3 freeze | egrep '(apify-client|nltk|pandas|scikit-learn|spacy)'
This should include both the dependencies with their versions. If you spot any missing dependencies, you may need to re-run the installation command for that specific package.
Once we're done with the installation, we're ready to write our code.
Scrape data with a Twitter scraper
We’ll scrape the data for these techniques using a Twitter scraper, a data extraction tool to scrape tweets from any public profile. In this example scenario, we’ll extract tweets from The New York Times Twitter account.
from apify_client import ApifyClient
# Initialize the ApifyClient with your API token
client = ApifyClient("Apify_API_Key")
# Prepare the actor input
run_input = {
"max_tweets": 500,
"language": "any",
"user_info": "user info and replying info",
"max_attempts": 5,
# You can provide a list of profiles here
"from_user": ['nytimes'],
"only_tweets":True
}
# Run the Actor and wait for it to finish
run = client.actor("shanes/tweet-flash").call(run_input=run_input)
# Fetch and print Actor results from the run's dataset
for item in client.dataset(run["defaultDatasetId"]).iterate_items():
print(item['text'])This should print a list of 500 tweets from The New York Times Twitter profile. Then we’ll convert this data into a Python DataFrame.
import pandas as pd
# Initialize an empty list to store the tweets
tweets = []
# Iterate over the items in the dataset
for item in client.dataset(run["defaultDatasetId"]).iterate_items():
# Add the 'text' field of each item to the list
tweets.append(item['text'])
# Convert the list to a DataFrame
df = pd.DataFrame(tweets, columns=['Tweet'])
# Print the DataFrame
print(df)
The conversion of this dictionary data into a DataFrame will allow us to manipulate the data more efficiently and conveniently.
Now our data is ready, and we can start applying different techniques to this DataFrame.
Removing special characters
One of the first techniques we often use when working with raw data is to remove special characters like punctuation marks, symbols, etc. These characters don't carry any meaningful information and are typically irrelevant to the NLP models. By removing them, we can clean and normalize the text, making it easier to understand its overall meaning.
For this, we’ll make a regular expression that will help us to remove irrelevant characters.
# Import the regular expression
import re
# Apply the regex on each tweet using the lambda function
df['Cleaned Tweet'] = df['Tweet'].apply(lambda text: re.sub('[^a-zA-Z0-9\\s]', '', text))
# Print the cleaned data
df
Tokenization
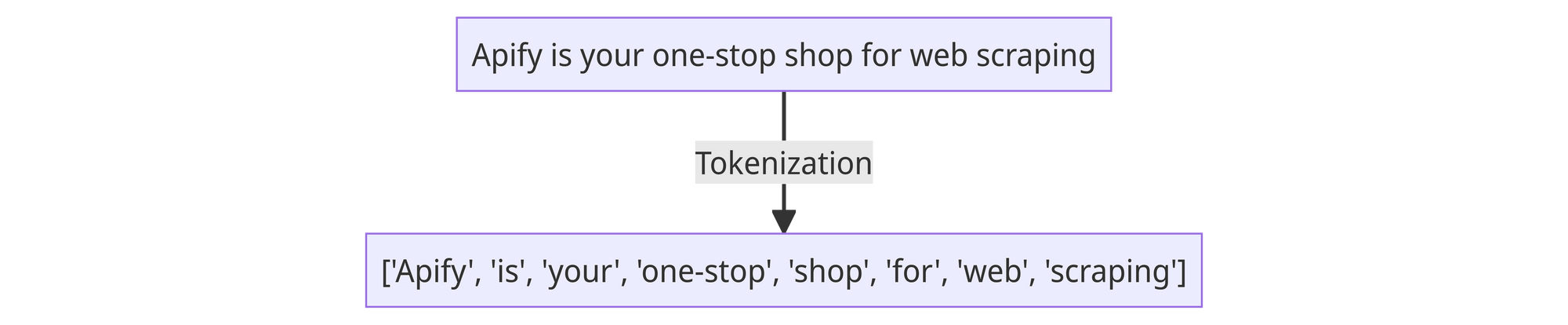
This is often the most used step in any NLP task. Tokenization allows us to break text into tokens or smaller pieces of text that make sense. We can tokenize by sentences or words, but most people use word tokenization. It breaks the text into tokens wherever it finds a white space. For example, the sentence "Apify is your one-stop shop for web scraping" will look like this ['Apify', 'is', 'your', 'one-stop', 'shop', 'for', 'web', 'scraping'].
Tokenization by word allows us to get the words that appear most often. For example, if we’re analyzing a group of ads or tweets related to jobs, we might find that "Python" has been used the most frequently. Let's look at an example.
import nltk
from nltk.probability import FreqDist
# Download the Punkt Tokenizer Models.
nltk.download('punkt')
# Apply the tokenization to every tweet
df['Tokenized Tweet'] = df['Cleaned Tweet'].apply(nltk.word_tokenize)
# Creating a single list containing all the words
all_words = [word for tokens in df['Tokenized Tweet'] for word in tokens]
# Calculate the frequency of each twwet
fdist = FreqDist(all_words)
# Get the most used word
most_common_word = fdist.max()
print('Most frequent word:', most_common_word)
The above code first tokenizes each tweet into tokens and then creates a single list of all the tokens. In the end, the function FreqDist takes the list all_words and finds the most repeated token in the list.
An issue related to SSL may arise on macOS due to the system's security settings. Press the arrow button and use the code below to remove the issue.
!pip install certifi
import certifi
import ssl
if hasattr(ssl, '_create_unverified_context'):
ssl._create_default_https_context = ssl._create_unverified_context
Stemming and Lemmatization
Stemming and lemmatization are the most important and widely used normalization techniques during preprocessing as both techniques reduce the words to the basic form. Let's see how:
- Stemming: Stemming changes the word to its basic form simply by truncating the last or first few letters by considering a few prefixes and postfixes found in a word. For example, it will change the words "Jumps", "Jumping", and "Jumped" to "Jump" which is a valid word. But most of the time, it fails to generate a valid word. For example, the stem of the words "Running", "Ran", and "Run" might be "Runn" which is not a valid word.
- Lemmatization: Lemmatization is a proper normalization technique that reduces the word to its basic or root form, and unlike stemming, the result is always a valid word. For example, it will change the word "Running" to "Run" and "faster" to "fast".

So, a question arises here. If lemmatization performs well, why do we need stemming? Lemmatization is slower than stemming, so if speed is your goal rather than accuracy, stemming is an appropriate approach. However, if accuracy is crucial, use lemmatization.
Let's see coding examples for both stemming and lemmatization:
Stemming example
We’ll use the PorterStemmer class from the nltk.stem module. This is a stemming algorithm that is used to reduce words to their root form. This is often used in NLP tasks to normalize text data.
from nltk.stem import PorterStemmer
# Create an instance of PorterStemmer
stemmer = PorterStemmer()
# Apply the stemmer to each word in each tokenized tweet
df['Stemmed Tweet'] = df['Tokenized Tweet'].apply(lambda x: [stemmer.stem(i) for i in x])
# Print the Stemmed Tweets
df['Stemmed Tweet']
We’ll add a new column named Stemmed Tweet in the DataFrame with words in their root form.
Lemmatization example
We’ll use the WordNetLemmatizer class from the nltk.stem module. This is used to perform lemmatization using the WordNet lexical database of English words. As we’ve already discussed, lemmatization is a more effective method than stemming as it uses vocabulary analysis to reduce words to their root form.
from nltk.stem import WordNetLemmatizer
# Download the wordnet
nltk.download('wordnet')
# Create an instance of WordNetLemmatizer
lemmatizer = WordNetLemmatizer()
# Lemmatize each word in each tokenized tweet
df['Lemmatized Tweet'] = df['Tokenized Tweet'].apply(lambda x: [lemmatizer.lemmatize(i, pos='v') for i in x])
df['Lemmatized Tweet']
A new column named Lemmatized Tweet is added in the DataFrame with words in their root form.
Removing stop words
This technique is used to remove stop words like is, am, are, and they from the text, which is considered unnecessary in most NLP tasks. They do not have any meaning attached to them individually, as these are the words that are used to connect sentences or to show the relationship of a word with other words.
Let's remove these words and only go with the words or tokens with a meaning attached. We will use the stopwords corpus from the nltk.corpus module. It's a list of common words that are often considered noise in text data.
from nltk.corpus import stopwords
nltk.download('stopwords')
stop_words = set(stopwords.words('english'))
# Remove stop words from each tokenized tweet
df['Tweet Without Stopwords'] = df['Lemmatized Tweet'].apply(lambda x: [word for word in x if word.lower() not in stop_words])
print(df['Tweet Without Stopwords'])
We’ll remove stopwords from the lemmatized column and add a new column named Tweet Without Stopwords.
Bag of Words (BoW)
The BoW model is used to convert text into fixed-length vectors. Later, we can use these vectors to feed our Machine Learning models. The BoW model doesn't care about the sequence of the words but only about the frequency and creates an n-dimensional vector against all the documents.
For example, the three sentences:
Sentence 1: "I love Apify"
Sentence 2: "I love to scrape data"
Sentence 3: "I love to code"
After removing the Stop words, the vector would look like this:
| love | Apify | scrape | data | code | |
|---|---|---|---|---|---|
| Sentence 1 | 1 | 1 | 0 | 0 | 0 |
| Sentence 2 | 1 | 0 | 1 | 1 | 0 |
| Sentence 3 | 1 | 0 | 0 | 0 | 1 |
Let's see how it's done in Python. We’ll take the Cleaned Tweet column and convert it into a numerical format using CountVectorizer from the sklearn library. CountVectorizer turns the text into a matrix of token counts, representing words as numbers. After processing, each row in the resulting DataFrame corresponds to a tweet, and each column represents a unique word, with values indicating the word's occurrence count in each tweet.
import pandas as pd
# Import the countVectorizer
from sklearn.feature_extraction.text
import CountVectorizer
# Create an instance of CountVectorizer with English stop words
Vectorizer = CountVectorizer(stop_words='english')
# Passing tweets to CountVectorizer
vectorizer_matrix = Vectorizer.fit_transform(df['Cleaned Tweet'])
# Create a matrix with words as columns and tweets as rows
final_df = pd.DataFrame(vectorizer_matrix.toarray(),
columns=Vectorizer.get_feature_names_out())
# Print the matrix
final_df
Named Entity Recognition (NER)
As the name suggests, NER is an information retrieval technique used to find and classify the named entities from text into categories like person, organization, place quantities, and so forth. The use cases of NER are text classification, customer support, recommendation systems, etc.
| Sentence | Entity 1 | Entity Type 1 | Entity 2 | Entity Type 2 |
|---|---|---|---|---|
| Apify is your one-stop shop for web scraping, data extraction, and RPA located in Czechia. | Apify | ORGANIZATION | Czechia | LOCATION |
| Barack Obama was born in Hawaii. | Barack Obama | PERSON | Hawaii | LOCATION |
We’ll use the spacy library to extract named entities from the Cleaned Tweet column and save them in a new column called entities .
We need to download a model that will perform name entity recognition for us. Run the following command in your notebook cell to download it.
!python3 -m spacy download en_core_web_smOnce the downloading is completed, we can execute the code below.
import spacy
# Load Spacy model
model = spacy.load("en_core_web_sm")
# Function to get entities
def get_entities(text):
doc = model(text)
return [(X.text, X.label_) for X in doc.ents]
# Create a new column with entities
df['entities'] = df['Cleaned Tweet'].apply(get_entities)
# Print the DataFrame
df[['Cleaned Tweet', 'entities']]
In the code above, we’re using spaCy’s pre-trained model for the English language calleden_core_web_sm. We’re using this model to find named entities from the Cleaned Tweet column. We’ve defined a function to identify entities (like persons, organizations, locations, etc.) from each tweet. The final output is a DataFrame displaying the cleaned tweets with their named entities.
Sentiment Analysis
Sentiment analysis is one of the most used NLP techniques to extract emotions or sentiments expressed in a text. This text is mostly comments, reviews, or tweets. The labels are mostly positive, negative, and neutral.

We’re performing sentiment analysis on the cleaned_data column using NLTK's Sentiment Intensity Analyzer and the VADER lexicon. It's specifically designed to perform sentiment analysis on any data.
from nltk.sentiment import SentimentIntensityAnalyzer
# Download the vader_lexicon
nltk.download('vader_lexicon')
# Create an instance of Sentiment Intensity Analyzer
sia = SentimentIntensityAnalyzer()
# Define a function to calculate the sentiment score
def get_sentiment_score(tweet):
return sia.polarity_scores(tweet)['compound']
# Get the sentiment score of each tweet and saving in a new column
df['Sentiment Score'] = df['Cleaned Tweet'].apply(get_sentiment_score)
# This function assigna a label to each twwet depending on the score
def assign_label(score):
if score > 0.05:
return 'positive'
elif score < -0.05:
return 'negative'
else:
return 'neutral'
# Pass the score of each tweet to the function above
df['Sentiment'] = df['Sentiment Score'].apply(assign_label)
# Display the DataFrame
print(df[['Cleaned Tweet', 'Sentiment', 'Sentiment Score']])
First, we define a function that get_sentiment_score calculates the sentiment score for each tweet based on the analyzer's polarity_scores function. We apply this function to the Cleaned Tweet column and store the sentiment scores in a new sentiment_score column.
Next, we define a function assign_label to assign a label depending on the numerical sentiment scores into categorical labels ('positive', 'negative', 'neutral').
NLP vs. LLM: context, tone, syntax, and semantics
Problems with traditional NLP
NLP models have many use cases but they have limitations as well. Let's discuss them one by one.
- Understanding context: when it comes to understanding the context, traditional approaches fail to get the complete context of the sentence. For example, the sentence "He is feeling blue today". Humans know that this sentence is related to the person's mood, but traditional NLP won't get this.
- Sarcasm and humor: another big issue is detecting sarcasm and humor. We know that sarcasm can be an art form, but it's not detected by NLP systems. They can fail to identify sarcastic or humorous remarks. We humans use tone, context, and prior knowledge to assume these elements, and it's hard to program a system to do the same.
- Syntax vs. semantics: NLP techniques are usually very good at understanding sentence structures, but they struggle with the meaning of sentences. For example, "The man bites the dog" and "The dog bites the man" have the same words and structure but entirely different meanings. Traditional NLP techniques don’t always pick up on these differences.
The rise of Large Language Models (LLMs)
In the field of Natural Language Processing (NLP), a remarkable shift has occurred with the emergence of Language Models (LMs). Traditional algorithms that once dominated the field are now being dominated by the power and capabilities of LMs.
Large Language Models (LLMs) like GPT-4 have drastically changed the field of Natural Language Processing. They’re called Large Language Models because they’re trained on huge datasets with the ability to overcome all the limitations of traditional NLP.
- Understanding context: LLMs are far better at understanding the context of a conversation or a sentence compared to traditional NLP systems. They are based on transformers that allow them to keep track of the entire sequence of a conversation, which helps to interpret ambiguous sentences more accurately.
- Sarcasm and humor: Although sarcasm and humor detection is a tricky issue, LLMs are trained on a huge amount of data including a wide variety of linguistic styles, tones, and contexts. Moreover, the transformer-based architecture allows them to get a better grasp of sentences.
- Syntax vs. semantics: LLMs are trained in such a way that they recognize patterns that allow them to understand both syntax and semantics. This enables them to differentiate between phrases with the same structure but different meanings.
Apify and LLMs
Apify has responded to the rise of LLMs by providing support for these models with their existing Actors (serverless cloud programs). This allows businesses to easily extract data from the web and train their own LLMs.
Apify also provides support for LangChain, which is a platform that allows businesses to train their own LLMs on their own data. This is important because ChatGPT, which is one of the most popular LLMs, is trained on data that was collected before 2021. This means that ChatGPT may not be as accurate or up-to-date as LLMs that are trained on more recent data.
By providing support for LLMs, Apify is helping businesses take advantage of the latest NLP technologies. This will allow companies and organizations to improve their products and services, and to better understand their customers.
If you're interested in LangChain and want to train an LLM with your own data, here are a few helpful guides for you:
- What is LangChain?
- Integrate Apify and LLMs using LangChain
- How to use LangChain with OpenAI, Pinecone, and Apify
Frequently asked questions
What is Natural Language Processing (NLP)?
NLP is a field of Artificial Intelligence (AI) that aims to make computers understand, interpret, and generate human language.
What are Large Language Models (LLMs)?
LLMs are machine learning models trained on a large corpus of text. They can understand, interpret, and generate human language.
How do LLMs work?
LLMs are pre-trained on a large corpus of text data and then fine-tuned on a specific task. This allows them to leverage the knowledge learned during pre-training to perform well on a range of tasks.
What are some applications of LLMs?
LLMs have a wide range of applications, including sentiment analysis, text generation, question answering, text summarization, and machine translation.
What are the challenges of using LLMs?
The challenges with LLMs include the high cost of training, ethical concerns related to bias and misinformation, and issues with explainability and interpretability.