Hi. We're Apify, a full-stack web scraping and browser automation platform. If you're just getting started on web scraping, Selenium is one of the tools you can use to extract web data in Python. In this tutorial, we explain the value of the Selenium Wire package and how to use it.
Selenium offers an excellent web scraping and automation solution and has been the go-to tool for developers and testers. However, while Selenium is great at working with the DOM, there are some limitations when accessing network traffic.
In this article, you'll learn how Selenium Wire solves this problem, the features it offers, and some practical use cases.
What is Selenium Wire?
Selenium Wire is a lightweight Python package that extends the standard traditional Selenium WebDriver functionality (bindings) with a more advanced ability to access the underlying network requests made by the browser.
It acts like a proxy server between the internet, Selenium WebDriver, and your web browser, intercepting and logging all HTTP/HTTPS traffic in real time.
With Selenium Wire, developers get additional APIs to monitor, modify, inspect, or block requests and responses during web automation. Selenium Wire also possesses a rich set of features for troubleshooting issues.
You might also be interested in reading about:
The need for network traffic access
Over the years, web automation/scraping has become increasingly difficult, especially when dealing with complex and data-driven web applications that rely heavily on dynamically fetched data through multiple AJAX API calls and other real-time update techniques.
Traditional Selenium alone will not be sufficient for testing such scenarios, as it primarily focuses on the UI elements. Selenium Wire was made to bridge this gap by providing access to network data, hence enabling testers and developers to:
- Identify and troubleshoot data retrieval, API calls, and authentication issues.
- Verify and validate the correctness of responses while also checking for data leakages.
- Simulate more real-world scenarios that users often experience, such as server errors, network latency issues, etc.
Traditional Selenium vs. Selenium Wire
| Feature | Selenium | Selenium Wire |
|---|---|---|
| Primary use case | Web automation and testing | Web automation, testing, and traffic inspection/modification |
| Traffic inspection | No built-in support for inspecting and modifying network traffic | Supports capturing and modifying HTTP/HTTPS traffic during web automation |
| Language support | Supports multiple programming languages, including Java, Python, C#, Ruby, and JavaScript. | Currently, only supports Python. |
| Request and response handling | Limited capabilities for handling requests and responses. | Provides APIs for intercepting and modifying requests and responses. |
| Browser support | Currently, supports multiple browsers like Chrome, Firefox, Safari, Edge, etc. | It inherits its browser support from Selenium, so some advanced features may have limited support depending on the browser. |
| Performance | Efficient for web automation tasks and generally faster than Selenium Wire due to less overhead. | Slightly slower than Selenium due to the additional traffic inspection/modification overhead. |
Key features of Selenium Wire
Selenium Wire offers an array of features that enhance Selenium's capabilities. They include:
- HTTP request and response interception: With Selenium Wire, you can capture and analyze HTTP requests and responses made by an application when running test scripts, including headers, bodies, and status codes.
- Modification of request and response: Selenium Wire allows you to modify requests and responses on the fly, which is suitable for advanced use cases.
- Resource blocking: Selenium Wire can block specific requests (like large images). This makes the web scraper lighter and faster, thus optimizing testing performance.
- Proxy support: It supports using proxies to mask your IP address or bypass restrictions.
- Undetected ChromeDriver support: Using Selenium Wire, you can use undetected ChromeDriver to evade browser detection and scraping blocking.
- Handling authentication: Selenium Wire can handle basic authentication while running automated tests by providing built-in support for injecting auth credentials in requests.
Setting up Selenium Wire
Before getting started, make sure you have Python version 3.7 or later installed on your machine. You can confirm what version you have by using the command below:
python3 --version
Selenium Wire also requires OpenSSL to decrypt HTTPS requests. Though this should already be found on your computer, you can check by running openssl version, but if not installed, run the commands below:
For macOS:
brew install openssl
For Linux:
# For apt based Linux systems
sudo apt install openssl
# For RPM based Linux systems
sudo yum install openssl
# For Linux alpine
sudo apk add openssl
For Windows devices, no installation is required.
Python virtual environment
If you prefer working in a Python virtual environment, you can create a new one. To do this, run this command below:
pip3 install virtualenv
Create a folder, navigate to it, and initialize a virtual environment using this command:
python3 -m venv myenv
Then, activate the environment:
source myenv/bin/activate
# On Windows, use `myenv\Scripts\activate`
Install Selenium Wire within that environment using the command below:
pip3 install selenium-wire
This will install Selenium Wire together with Selenium (its main dependency).
Selenium Wire is compatible with Selenium v4.0.0+, so if you have an older Selenium version, upgrade it:
pip3 install --upgrade selenium
Using Selenium Wire
To use Selenium Wire, you have to replace selenium with seleniumwire when importing the webdriver.
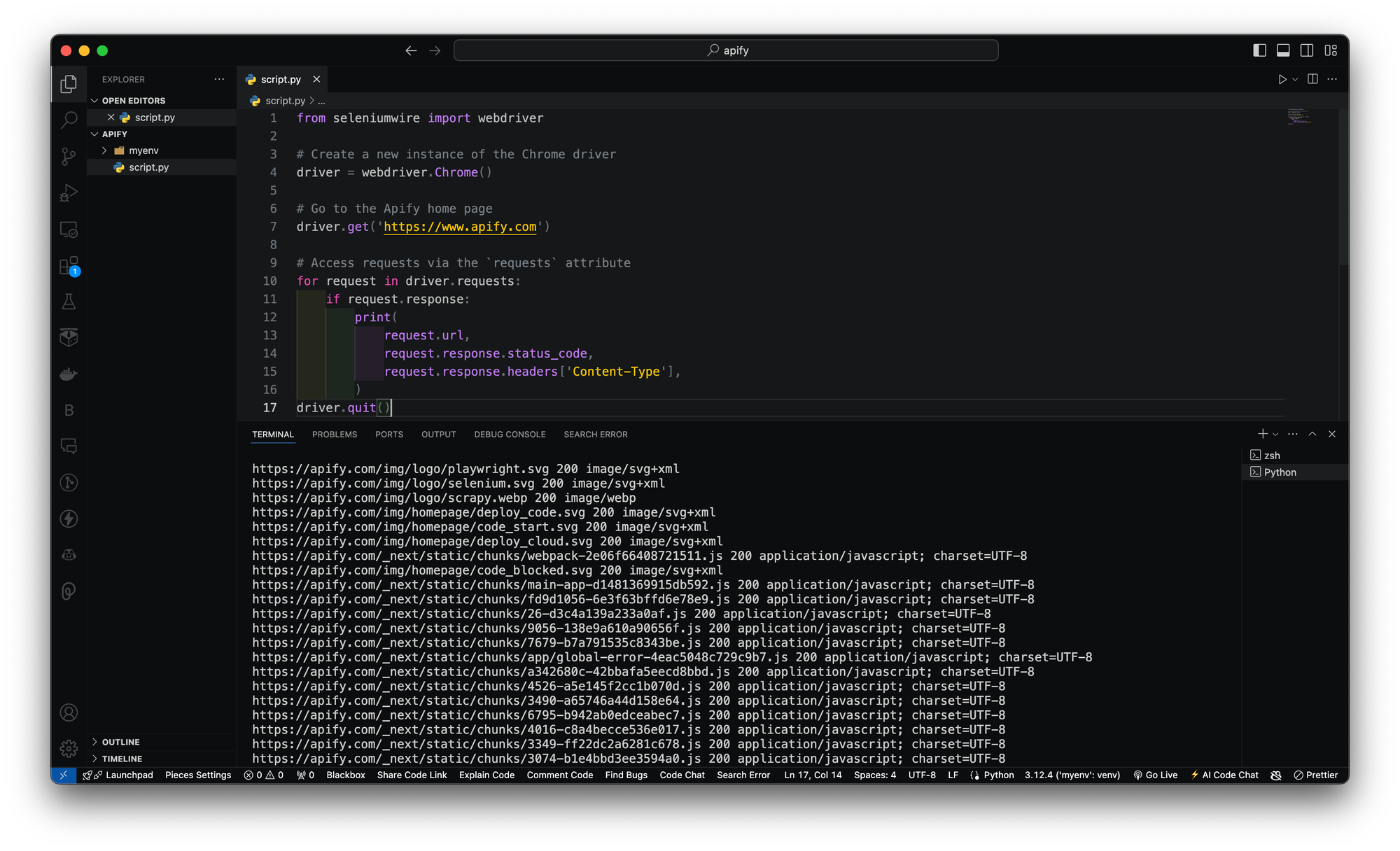
Note: From Selenium v4 and later, installing Webdriver is no longer required as it is now included by default.With just that, you can proceed as you would normally with Selenium. Now, create a file script.py with the code below:
# ./script.py
from seleniumwire import webdriver
# Create a new instance of the Chrome driver
driver = webdriver.Chrome()
# Go to the Apify home page
driver.get('https://www.apify.com')
Accessing requests via the requests attribute
Selenium Wire provides us with a request attribute that exposes the details of the HTTP requests made by the target web application.
In your script.py add the code:
# ./script.py
...
# Access requests via the `requests` attribute
for request in driver.requests:
if request.response:
print(
request.url,
request.response.status_code,
request.response.headers['Content-Type'],
)
driver.quit()
In the code blocks above, we request the Apify website and loop over all the network requests captured by Selenium Wire. All requests are then stored in the driver.request variable.
Output:
🛠 Note: You might likely run into some errors like these below:
Error 1: ModuleNotFoundError: No module named 'pkgresources’_
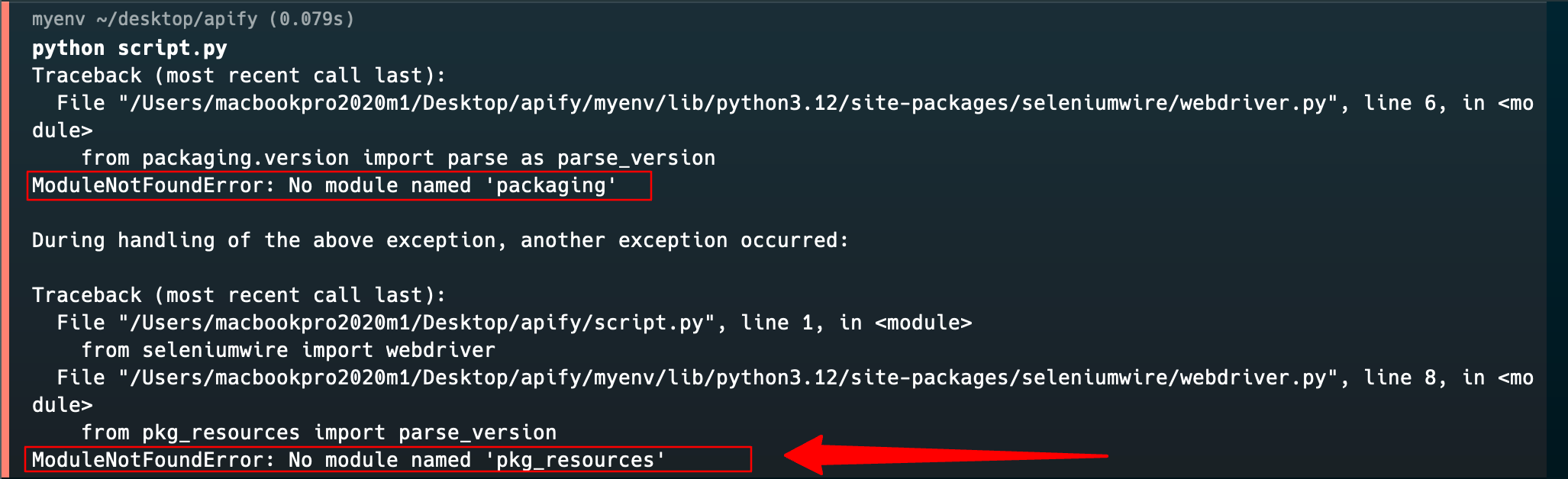
This error message shows that some modules, packaging and pkg_resources required by Selenium Wire are missing. These modules are part of the setuptools package, which seems not to be present in your Python virtual environment.
To resolve this error, install the required packages using pip.
pip3 install setuptools
You can go ahead to install the packaging package (if not included in setuptools):
pip3 install packaging
Error 2: ModuleNotFoundError: No module named 'blinker.saferef’_
You would most likely face this error, and at the time of writing this article, this error occurs because Selenium Wire depends on a Python package blinker, specifically the file blinker._saferef which is no longer available in the latest versions 1.8.0 and 1.8.1.
Hence, the solution to this is to directly install blinker < v1.8.0 into your project so that Selenium does not automatically download the latest blinker version.
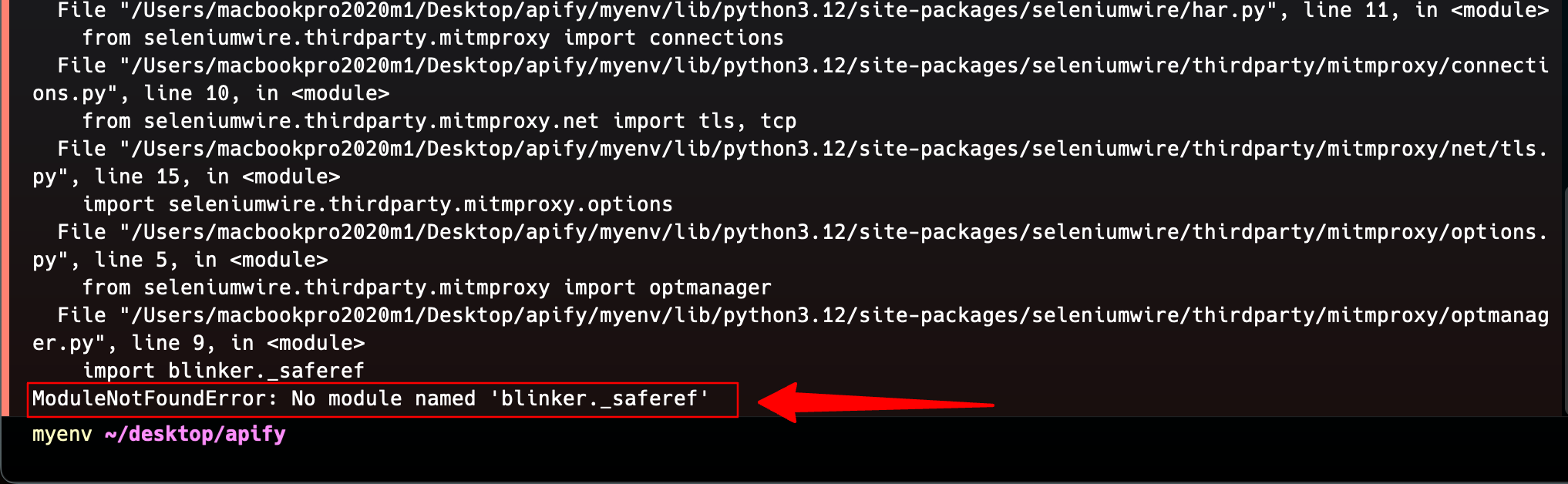
Simply run the code below:
pip3 install blinker==1.7.0
Filtering responses
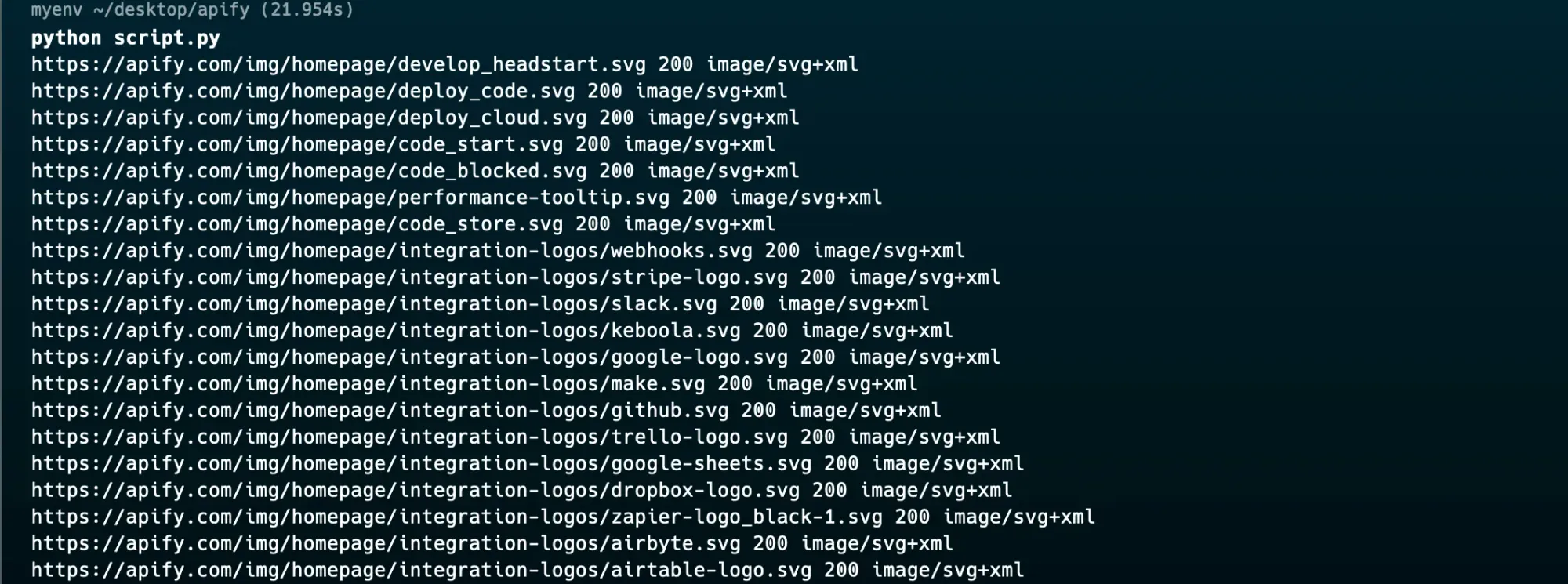
Now, depending on what you want to test, you can apply a filter for resources like assets (images), JavaScript bundles, CSS files, etc.
For example, you can filter for only images by modifying your script.py file as follows:
...
for request in driver.requests:
if "/img/homepage" in request.url:
if request.response:
print(
request.url,
request.response.status_code,
request.response.headers['Content-Type'],
)
driver.quit()
Here is the result:
Selenium Wire request and response objects
Selenium Wire provides two main objects: request and response. These objects contain properties and methods for inspecting and modifying the respective HTTP messages.
Attributes of the request object
| Attribute | Description |
|---|---|
body |
The request body in bytes. It will be empty (b'') if the request has no body. |
cert |
A dictionary containing server SSL certificate information. This will be empty for non-HTTPS requests. |
date |
The date when the request was made. |
headers |
A dictionary-like object of request headers. It is case-insensitive and allows duplicates. |
host |
The request host (e.g., www.apify.com). |
method |
The HTTP method (e.g., GET, POST). |
params |
A dictionary of request parameters. Parameters with multiple occurrences are stored as lists. |
path |
The request path. |
querystring |
The query string. |
response |
The response object associated with the request. There will be none if the request has no response. |
url |
The complete request URL |
ws_messages |
This is for WebSocket handshake requests (usually starting with wss://). It contains a list of WebSocket messages sent and received. |
Attributes of the response object
| Attribute | Description |
|---|---|
body |
This contains the response content as a byte string |
headers |
Stores response headers in a dictionary-like structure |
status_code |
Represents the numeric HTTP status code of the response |
reason |
Provides the text description associated with the status |
Intercepting the network requests and responses
In Selenium Wire, there are two available functions for interception:
driver.request_interceptor: For intercepting and modifying outgoing requests.driver.response_interceptor: For intercepting and altering incoming responses.
Let's dive into various use cases and see how to implement them.
1. Modifying request headers
The request_interceptor lets you modify the outgoing HTTP request, which can be useful for adding custom headers, changing user agents, or setting authentication tokens.
Here’s an example:
def interceptor(request):
del request.headers['Referer'] # Remember to delete the header first
request.headers['Referer'] = 'some_referer' # Spoof the referer
driver.request_interceptor = interceptor
driver.get(...)
# All requests will now use 'some_referer' for the referer
2. Modifying response headers
You can also modify response headers using Selenium Wire response_interceptor. Here's an example:
def interceptor(request, response):
if request.url == 'https://server.com/some/path':
response.headers['New-Header'] = 'Some Value'
## Set Response Interceptor
driver.response_interceptor = interceptor
## Make request --> responses from 'https://server.com/some/path' will now contain New-Header
driver.get('https://httpbin.org/headers')
3. Modifying request parameters
When handling complex scenarios, you might need to modify query (request) parameters or JSON payloads in requests on the fly.
Here is an example:
from seleniumwire import webdriver
from parsel import Selector
import json
driver = webdriver.Chrome()
# Define the request interceptor
def interceptor(request):
"""Modify parameters of outgoing requests"""
if request.url.startswith('https://api.example.com'):
# Parse existing query parameters
params = dict(request.params)
# Modify parameters
params['page'] = '2'
params['limit'] = '50'
# Add a new parameter
params['sort'] = 'desc'
# Update the request
request.params = params
driver.request_interceptor = interceptor
driver.get("https://httpbin.org/get")
# Extract response data
selector = Selector(driver.page_source)
response = json.loads(selector.xpath("//pre/text()").get())
print(json.dumps(response, indent=2))
driver.quit()
4. Adding basic authentication
When running your scripts on a site that requires authentication, you can use Selenium Wire to add authentication credentials which will automatically log in, thus preventing the signing page from popping up.
from seleniumwire import webdriver
import base64
options = {
'verify_ssl': False,
'suppress_connection_errors': True
}
driver = webdriver.Chrome(seleniumwire_options=options)
# Encode credentials
credentials = base64.b64encode(b'username:password').decode('ascii')
# Set up basic authentication
def add_basic_auth(request):
request.headers['Authorization'] = f'Basic {credentials}'
driver.request_interceptor = add_basic_auth
# Now all requests will include the Authorization header
driver.get('https://console.apify.com/sign-in')
Mocking response
If you want to test how your application behaves with different server responses without actually calling the server, you can use this method request.create_response() to send back custom replies to the browser.
...
def interceptor(request):
if request.url == 'https://apify.com':
request.create_response(
status_code=200,
headers={'Content-Type': 'text/html'}, # Optional headers dictionary
body='Hello World!' # Optional body
)
driver.request_interceptor = interceptor
driver.get(...)
# Requests to https://apify.com will have their responses mocked
Selenium Wire Chrome options
Selenium Wire also allows for further customization of the webdriver using some available Selenium Chrome options. These options can be passed as an argument to the seleniumwire_options parameter.
driver = webdriver.Chrome(
options=webdriver.ChromeOptions(...),
# seleniumwire options
seleniumwire_options={}
)
Here are some available options:
| Option | Description | Example usage |
|---|---|---|
addr |
This Sets the IP address or hostname for Selenium Wire to run on. Defaults to 127.0.0.1. | options = {'addr': '192.168.0.10'} |
auto_config |
Enables or disables automatic browser configuration for request capture. Enabled by default. | options = {'auto_config': True} |
ca_cert |
Specifies the path to a custom root (CA) certificate file. | options = {'ca_cert': '/path/to/ca_certificate.crt'} |
ca_key |
Provides the path to the private key associated with your custom root certificate. Must be used with ca_cert. |
options = {'ca_key': '/path/to/private_key.key'} |
disable_capture |
When set to True, request capture is turned off. It's set to False by default. | options = {'disable_capture': True} |
disable_encoding |
Instructs the server to send uncompressed data. Defaults to False. | options = {'disable_encoding': True} |
enable_har |
Activates HAR file generation for HTTP transactions when set to True. Defaults to False. | options = {'enable_har': True} |
exclude_hosts |
List of addresses to completely bypass Selenium Wire. | options = {'exclude_hosts': ['example.com']} |
ignore_http_methods |
Specifies HTTP methods to ignore. Defaults to ['OPTIONS']. |
options = {'ignore_http_methods': []} |
port |
Sets the port for Selenium Wire’s backend service. Usually auto-assigned. | options = {'port': 9999} |
proxy |
Configures an upstream proxy server. | options = {'proxy': {'http': ' |
request_storage |
Determines the storage type for requests. Defaults to disk storage. | options = {'request_storage': 'memory'} |
request_storage_base_dir |
Defines the base directory for storing requests and responses with disk storage. | options = {'request_storage_base_dir': '/custom/storage/dir'} |
request_storage_max_size |
Limits the number of requests stored in memory. No limit by default. | options = {'request_storage': 'memory', 'request_storage_max_size': 100} |
suppress_connection_errors |
Controls whether connection-related errors are suppressed. Defaults to True. | options = {'suppress_connection_errors': False} |
verify_ssl |
Verifies SSL certificates when set to True. Defaults to False to prevent issues with self-signed certificates. | options = {'verify_ssl': True} |
Optimizing by blocking requests
In most cases, when running automated tests or scraping a web page, you might need to stop some unneeded resources that might slow down the tests. One frequent example is large images that take too long to long. The request.abort() method from Selenium Wire comes in handy here. Also, you can choose to implement some blocking options which include:
Blocking by file extension using the .endswith() method
For example:
from seleniumwire import webdriver
# Create a new instance of the browser with Selenium Wire
driver = webdriver.Chrome()
# Define the request interception
def intercept_request(request):
if request.path.endswith(('.jpg', '.jpeg', '.png', '.gif', '.css', '.js')):
request.abort()
# Attach the interceptor to the driver
driver.request_interceptor = intercept_request
# Navigate to the desired URL
driver.get('http://apify.com')
# Perform your automated test actions here
...
driver.quit()
Blocking by specific domain
You can block resources from specific domains and run a check on the request URL against the domains you want to block.
For example:
from seleniumwire import webdriver
# Create a new instance of the browser with Selenium Wire
driver = webdriver.Chrome()
# Define the request interception
def intercept_request(request):
blocked_domains = ['example.com', 'anotherdomain.com']
if any(domain in request.url for domain in blocked_domains):
request.abort()
# Attach the interceptor to the driver
driver.request_interceptor = intercept_request
# Navigate to the desired URL
driver.get('http://apify.com')
# Perform your automated test actions here
...
driver.quit()
Blocking based on content type
Using this method, you check the Content-Type header in the response gotten.
For example:
from seleniumwire import webdriver
# Create a new instance of the browser with Selenium Wire
driver = webdriver.Chrome()
# Define the request interception
def intercept_request(request):
blocked_content_types = ['image/', 'video/', 'text/css', 'application/javascript']
# Allow the request to proceed and check the response headers
response = request.response
if response and any(content_type in response.headers['Content-Type'] for content_type in blocked_content_types):
request.abort()
# Attach the interceptor to the driver
driver.request_interceptor = intercept_request
# Navigate to the desired URL
driver.get('http://apify.com')
# Perform your automated test actions here
...
driver.quit()
Limit request capture
Selenium Wire redirects network traffic through an internal proxy server in the background. As these requests flow through the proxy, they are intercepted and captured.
While capturing every single request can slow down the process, selenium wire can be used to restrict what gets captured to improve performance.
Using driver.scopes
The driver.scopes attribute allows you to specify a list of regular expressions that match the URLs you want to capture. This should be set on the driver before making any requests. All available URLs will be captured when the list is empty by default.
from seleniumwire import webdriver
driver = webdriver.Chrome()
# define the driver score
driver.scopes = [
'.*apify.com.*'
]
driver.get("https://apify.com/store")
# only requests sent to the host "apify" will get captured
for request in driver.requests:
print(request)
driver.quit()
Using seleniumwire_options.disable_capture
With this option, you can completely turn off request capturing. The requests will still pass through Selenium Wire and any upstream proxy you have configured. Hence, it will not intercept or store any requests. Also, request interceptors will not execute.
options = {
'disable_capture': True
}
driver = webdriver.Chrome(seleniumwire_options=options)
Using seleniumwire_options.exclude_hosts
You can bypass Selenium Wire entirely for specific hosts. Requests made to these hosts will go from the browser to the server without involving Selenium Wire. If an upstream proxy is configured, these requests will bypass it as well.
options = {
'exclude_hosts': ['host1.com', 'host2.com']
}
driver = webdriver.Chrome(seleniumwire_options=options)
Preventing Selenium Wire from being blocked
Many websites today employ anti-scraping techniques to prevent web scrapers and other automation tools from accessing their websites. This can detect and block requests by Selenium Wire. Hence, to overcome this, you can use alternative approaches, namely; Proxies and an undetected ChromeDriver.
1. Using proxies
Selenium Wire supports the use of external proxy servers. You can configure a proxy by specifying the proxy option when creating a new instance of the desired capabilities:
from seleniumwire import webdriver
# Define the proxy options
proxy_options = {
'proxy': {
'http': 'http://your_proxy_host:your_proxy_port',
'https': 'https://your_proxy_host:your_proxy_port',
'no_proxy': 'localhost,127.0.0.1' # Bypass the proxy for local addresses
}
}
# Create a new instance of the Chrome driver with the proxy settings
driver = webdriver.Chrome(seleniumwire_options=proxy_options)
# Open a website
driver.get('https://example.com')
# Your scraping code here
# Close the browser
driver.quit()
With this configuration, Selenium wire routes your requests through the specified proxy server.
2. Using undetected ChromeDriver
Regular Selenium Webdriver often leaks information about how a request to a site is made, which could be used by anti-scraping software to detect whether an actual user or an automated browser/web scraper made it.
Selenium Undetected ChromeDriver is a modification of the official ChromeDriver, which makes the automating web pages undetectable by websites. It does this by modifying the browser's fingerprint, making it appear more like a regular user's browser.
Selenium wire easily integrates with undetected-chromedriver if it finds it in your environment.
First, install the undetected-chromedriver package:
pip3 install undetected-chromedriver
Import and use it in your script as follows:
import undetected_chromedriver.v2 as uc
from seleniumwire import webdriver
# Configure Selenium Wire with undetected ChromeDriver
options = uc.ChromeOptions()
driver = uc.Chrome(options=options)
# Now you can navigate to the website
driver.get('http://apify.com')
# Remember to close the driver after use
driver.quit()
Some key APIs offered by Selenium Wire and their unique functionalities:
| API | Functionality |
|---|---|
request.headers |
Grants access to the HTTP request headers, allowing for inspection and modification. |
response.headers |
Provides access to the HTTP response headers, enabling detailed examination. |
request.method |
Identifies the HTTP method (e.g., GET, POST) used in the request. |
response.status_code |
Fetches the status code (e.g., 200, 404) returned in the HTTP response. |
request.body |
Allows retrieval and manipulation of the body content in the HTTP request. |
response.reason_phrase |
Retrieves the reason phrase (e.g., "OK", "Not Found") associated with the response status. |
request.url |
Accesses the URL of the HTTP request, facilitating URL-specific actions. |
response.body |
Enables access to the body content of the HTTP response for analysis or modification. |
response.content_type |
Determines the content type (e.g., "text/html", "application/json") of the HTTP response. |
request.querystring |
Extracts query parameters from the URL, useful for tests involving parameterized requests. |
Drawbacks of Selenium Wire
- Scalability issues: Selenium Wire might not be favourable for all scenarios of large-scale testing involving a lot of network traffic, as this might quickly lead to bottlenecks or other issues.
- Dependency on Selenium WebDriver: Since Selenium Wire relies on the Selenium WebDriver, any existing limitations or issues will also affect the functionality of Selenium Wire.
- While Selenium Wire provides network inspection and interception capabilities when compared to other dedicated network analysis tools like Wireshark and Charles Proxy, it falls behind.
Network control with Selenium Wire
With the capabilities discussed above, testers can now take complete control of their automation tests to improve test coverage and reliability. Head over to the Selenium Wire official docs to learn more.
Learn all about web scraping with Selenium with Python in our complete guide for 2024.