


Compared to Google’s position-based system, there’s no real notion of ranking in ChatGPT. Unlike search engines with stable “10 blue links” structures, AI models generate textual responses that can vary across time, runs, and contexts, even when you send the same prompt.
To actually track appearance in ChatGPT responses, you need a system that captures patterns across repeated interactions. This article presents a practical framework for monitoring, analyzing, and iteratively improving content based on observed citation behavior in AI-generated responses.
Why ChatGPT's "ranking" isn’t like Google's ranking
Google Search results are list-based. Pages compete for positions in a search engine results page (SERP), typically from position one to ten.
While rankings fluctuate, the system is predictable enough for SEO tools to track positions, compare competitors, and measure visibility over time.
ChatGPT works differently. Instead of returning a fixed list of links, it generates textual answers using a mix of retrieved sources, learned patterns, and contextual reasoning.
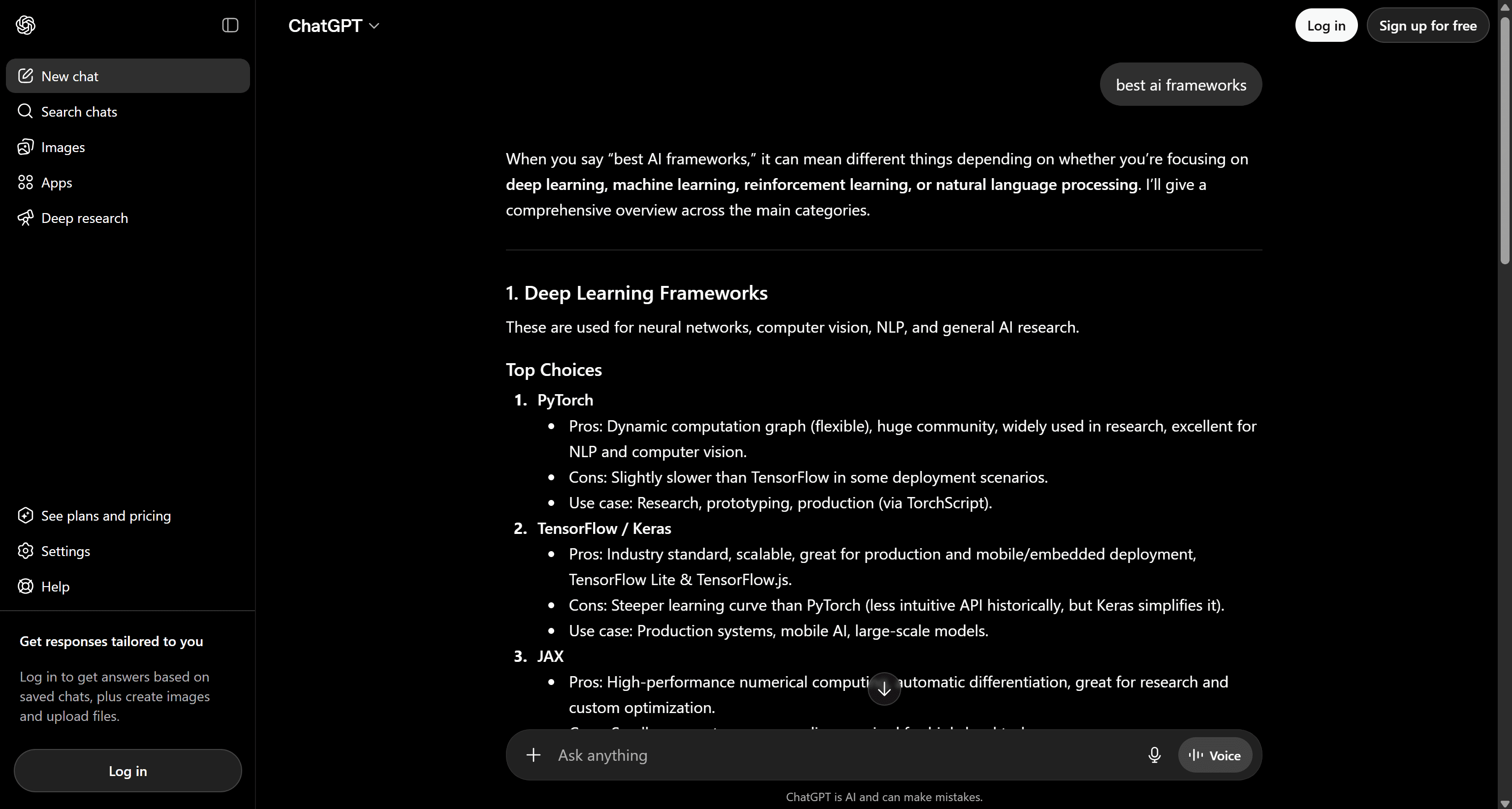
There are no fixed positions in ChatGPT replies (or most other AI systems such as Gemini, Claude, or Perplexity). As a result, success is more about increasing the likelihood of appearing in responses for target prompts rather than “ranking well”.
Shifting from ranking to AI visibility
Within a fresh session with specific language settings and from a particular location, the same Google search query tends to return the same ranked results. Identical prompts in ChatGPT produce different results due to the inherent probabilistic nature of LLMs.
You can’t directly control the AI results. Due to its variability, content optimization for ChatGPT must be based on observed behavior across multiple runs, prompts, and time windows. You need to look for patterns in what consistently gets retrieved, selected, and cited, then iterate based on those signals.
The end goal is to influence the signals that increase the probability of your content being included in AI-generated answers. This breaks visibility into three layers:
- Whether your content is found by ChatGPT search tools or is already present in the model's knowledge
- Whether it is selected among competing sources during answer generation
- Whether it is ultimately cited or referenced in the final response
How to operationalize ChatGPT visibility tracking
Tracking appearance in ChatGPT responses requires a repeatable workflow that queries AI with a defined set of prompts to observe how outputs change across runs. This lets you measure:
- Which sources appear regularly in answers
- Which competitors dominate citations for specific prompts
- How responses vary across repeated executions of the same query
This way, you’re not treating ChatGPT as a static ranking system like Google. Instead, the workflow treats it as a probabilistic engine where what matters is the distribution of outputs across time.
Important: A fundamental aspect of this approach is controlling whether ChatGPT uses the built-in web search tools or not.
When ChatGPT search is disabled, you can observe visibility based purely on model knowledge. When it’s enabled, you can observe how retrieval influences results. That includes which sources get fetched, which are ignored, and which ultimately make it into the final answer.
By comparing both modes, you can separate what the model “knows” (knowledge-based inclusion) from what the system can fetch and select (retrieval-based inclusion).
Required building blocks
To operationalize ChatGPT visibility tracking, you need a system that can run prompts at scale, collect outputs, and connect them to other AI and web data signals for analysis. Such a workflow requires:
- A data collection layer that can programmatically retrieve outputs from AI tools and search engines, as well as crawl and scrape websites.
- Integration with AI models to aggregate and analyze the collected data, generating insights into AI visibility.
- A workflow orchestration layer to simplify implementation and execution.
This is where Apify comes in. Apify is the largest marketplace of tools for AI. It provides thousands of ready-made tools, called Actors, to automate your business.
Understanding how to rank in ChatGPT via a visibility tracking workflow
Here, you’ll get a high-level view of building a visibility tracking workflow that explains how to “rank” in ChatGPT. This consists of a series of steps, where the output of one step becomes the input of the next.
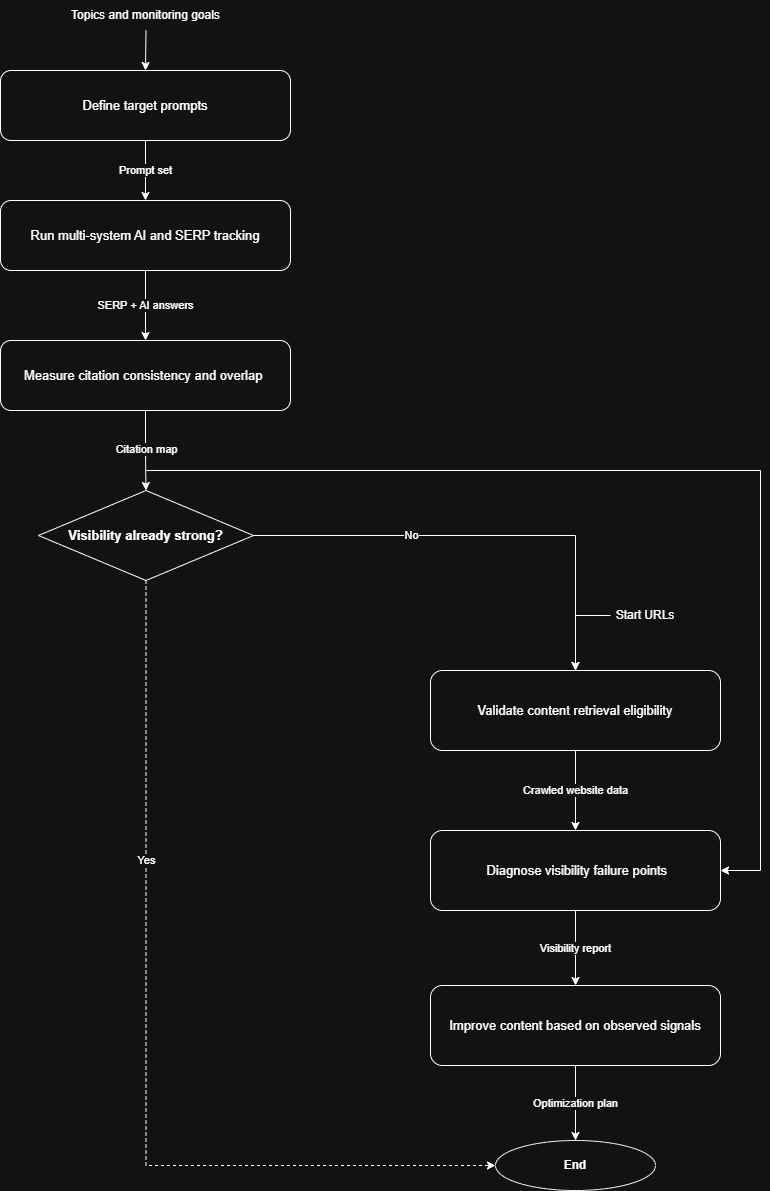
1. Define target prompts
Build a structured set of prompts that reflect how users actually search for information in ChatGPT. You can start by identifying high-value queries your target audience is likely to use, such as “best X tools for Y” or “how to do Z.” Then, group these prompts into clusters to capture different intent variations and angles for the same topic.
Input: Topics, monitoring scenarios, ranking objectives, and potentially even traditional SEO keywords.
Output: A rich prompt set you can use for repeatable testing and tracking across runs.
2. Run multi-system AI and SERP tracking
Use Google Search Results Scraper to run the identified prompt set across Google SERP, Google AI Mode, Perplexity, ChatGPT, Copilot, and Gemini. The goal is to gain a cross-platform view of how different AI and search engines interpret and answer the same queries.
For example, start by adding the prompt set generated in the previous step as input to Google Search Results Scraper:
Then, enable the AI visibility add-ons for Google AI Mode, Gemini, Perplexity AI, ChatGPT, and Copilot:
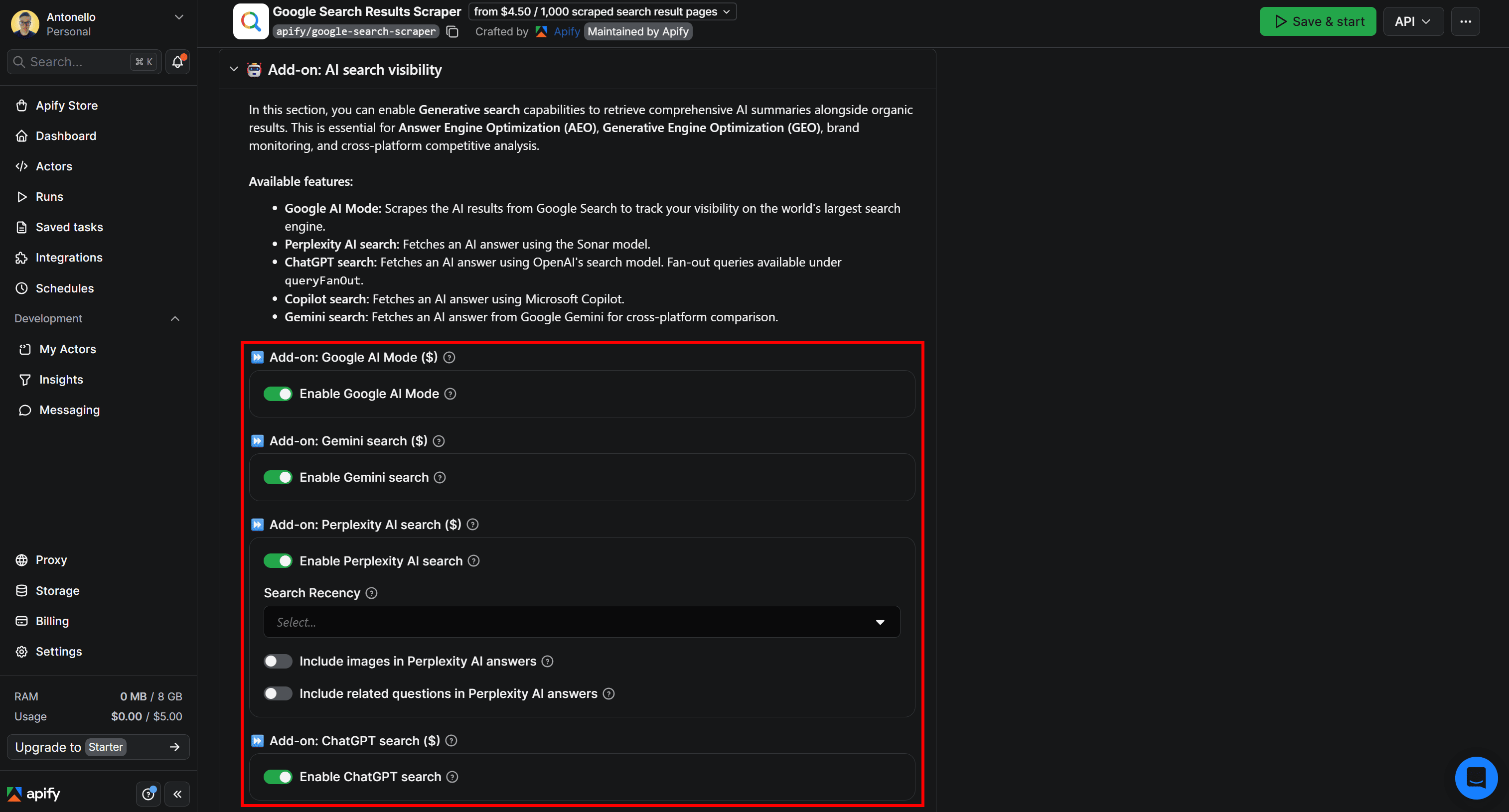
Execute the task by clicking Save & Start. The output will be a structured dataset containing Google SERP data together with the responses from the configured AI platforms:
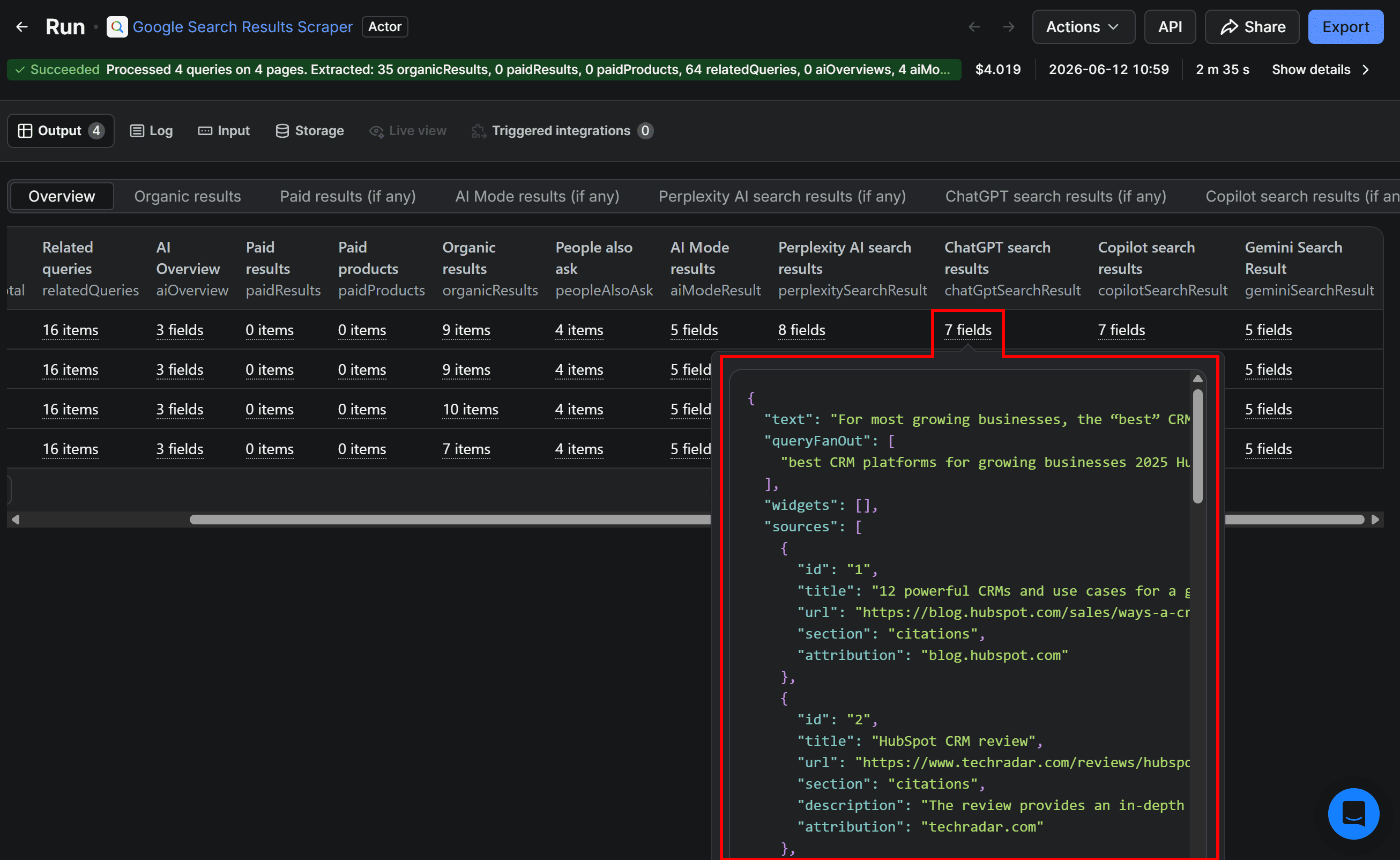
In detail, each AI-related field contains a JSON structure with the generated response text along with additional metadata, such as retrieved sources, citation links, query fan-out, and other platform-specific signals.
Note: You can get started with this (and the following Actors) even on Apify’s free plan, which provides $5 of credit to spend on Actor runs.
The resulting dataset is central to the entire process, as it allows you to identify shared citation sources across systems, domains that appear consistently, and narrative convergence patterns. It also reveals visibility gaps, where competitors or specific domains dominate some prompts while remaining absent from others.
Output: A cross-platform dataset containing SERP results and AI-generated answers across search engines and AI chat platforms.
3. Measure citation consistency and overlap
Feed the scraped dataset into an AI model to transform SERP results and AI-generated answers into a structured citation analysis report.
The idea is to let an LLM measure mention frequency, citation consistency, and visibility patterns across AI platforms to identify which domains, brands, or solutions appear most often and which pages repeatedly influence responses.
Note that a single citation may reflect noise or randomness, while repeated mentions across multiple prompts and AI systems are a much stronger signal of authority and influence.
Important: If your brand/solution already appears consistently and with the desired tone across target prompts, the workflow can end here.
Output: A structured citation frequency map tracking mentions, citations, visibility, sentiment, and tone across AI systems.
4. Validate content retrieval eligibility
If your content doesn’t appear in ChatGPT responses, you need to evaluate whether your website is structurally suitable for AI retrieval.
Rely on the Website Content Crawler Actor to simulate a full crawl of your site while extracting page content for further analysis. The objective is to check whether your site's content is crawlable, properly structured, and suitable for AI systems to retrieve and understand.
This Actor allows you to configure options such as which paths to follow, the rendering and retrieval mode, whether to respect robots.txt and llms.txt, concurrency settings, maximum number of pages, crawl depth, and the output format for scraped pages (HTML, Markdown, etc.).
Paste your start URL, configure the settings, and launch the crawling task:
New pages will start appearing as the crawler discovers and accesses them in the configured output format (Markdown in this example):
Input: A start URL to begin the crawling process on your website.
Output: A structured dataset containing crawled pages for further analysis (ideally in an LLM-friendly format like Markdown).
5. Diagnose visibility failure points
Combine the citation frequency map with the crawled website data to identify where visibility breaks down. Classify pages into:
- Not discoverable or retrievable (e.g., missing from crawled results compared to your sitemap or CMS page list).
- Not retrieved by the search tools called by ChatGPT (or other AI platforms).
- Retrieved but discarded during final citation selection.
This distinction is critical to turn answer engine optimization AEO/GEO performance issues into concrete, actionable diagnostics. If a page gets retrieved but never cited, the issue may not be discoverability but competitiveness, relevance, or content quality compared to competing sources.
Input: Citation frequency map + crawled website dataset.
Output: A visibility diagnostic report highlighting retrieval, discoverability, and citation failure points.
6. Improve content based on observed signals
Use the diagnostic insights gathered previously to improve pages based on actual retrieval and citation patterns rather than assumptions. At this stage, the workflow fills content gaps revealed by competitor citations and recurring AI references.
When competitors consistently appear in citations, you can use Web Scraper to scrape their content and analyze it to understand what information, structure, or signals make them more competitive.
Keep in mind that ChatGPT's visibility changes over time, so content should evolve iteratively based on new citation and retrieval data.
Output: An updated, evidence-based content strategy and a prioritized optimization plan to improve visibility in ChatGPT.
From ideation to implementation
You can implement the ChatGPT ranking tracking workflow using automation tools like n8n, Make, or Zapier. Alternatively, you can build a custom pipeline by connecting each component through APIs.
Note that Apify Actors can be invoked via API and are also available in n8n, Zapier, and Make through official integrations. This allows you to plug them directly into your workflow solution.
The implemented system should then rely on scheduled runs that repeatedly execute AI queries over time. This makes it possible to detect shifts in mentions, citations, and changes in competitor dominance.
Conclusion
You now know that “How to rank in ChatGPT?” isn’t the right framing. Appearance in AI responses depends on citation probability rather than a predefined ranking system.
A reliable approach to optimizing ChatGPT mention performance is via a tracking-first feedback loop that continuously measures how and when content appears across specific prompts. This reveals patterns in mentions and citations, giving you evidence-based insights for improvement.
Apify plays a pivotal role as the infrastructure layer behind this approach, enabling scalable scraping, crawling, and data collection workflows that power solid visibility analysis across AI-driven interfaces.
FAQ
Why can’t you directly rank in ChatGPT like Google?
You can't rank directly in ChatGPT because it doesn't use a fixed ranking system. Appearance in generated answers depends on citations, entity clarity, and contextual relevance, not a stable position or traditional SEO-style rankings.
What is the difference between ranking in vanilla ChatGPT and ChatGPT with search enabled?
Vanilla ChatGPT relies on learned training data and internal patterns, so visibility comes from embedded knowledge associations. ChatGPT with search enabled adds real-time web retrieval, meaning mentions can also depend on retrieved sources.
How to track rankings in ChatGPT?
You can’t track rankings in ChatGPT in a direct way. What you can do instead is take a practical approach based on observed behavior by running repeated prompts over time and logging outputs. By combining ChatGPT responses with other SERP and AI output signals, you can identify which domains appear repeatedly and how citation patterns evolve across runs.
Why is tracking important for ChatGPT SEO?
Tracking is essential because ChatGPT outputs are non-deterministic, so single observations are unreliable. By analyzing multiple outputs over time, you can uncover citation patterns and determine whether content is missing from retrieval, underperforming, or being filtered out during search retrieval.
How can Apify help with ChatGPT visibility?
Apify supports ChatGPT visibility by automating crawling and tracking workflows across SERPs, AI outputs, and website structures. This allows analysis of citation gaps, brand monitoring, and content optimization based on real intelligence signals rather than assumptions about how content is found and cited by AI systems.




