



Hi, we're Apify, a full-stack web scraping and browser automation platform. This article about integrating Google search into AI apps was inspired by our work on getting better data for AI.
Does ChatGPT really have access to the internet?
You've probably heard that ChatGPT can browse the internet, not least because OpenAI announced it in September 2023:
ChatGPT can now browse the internet to provide you with current and authoritative information, complete with direct links to sources. It is no longer limited to data before September 2021. pic.twitter.com/pyj8a9HWkB
— OpenAI (@OpenAI) September 27, 2023
Incidentally, that announcement is already outdated, as ChatGPT's knowledge cut-off date was very recently extended to April 2023:
BREAKING 🚨
— Shahaf (@shahaf_dan) October 27, 2023
OpenAI has updated ChatGPT’s knowledge cutoff to April 2023!
Even though the premature AGI has access to real time information through Bing, its non-Bing agent now has updated knowledge up to 6 months ago! pic.twitter.com/4LeTiejaL2
The cut-off date aside, does GPT-4 really have access to the internet? It would be more accurate to say that it supports a 'browse with Bing' feature (for those willing to part with $20 per month).
This is significant for two reasons:
1. Bing vs. Google
A research paper long ago demonstrated that there are differences between Google and Bing in terms of performance.
Overall, Google did a better job for single-word searches, and Bing was more precise for searches with multiple words, whether simple or complex. But Bing didn't show as many relevant results as Google.

2. GPT-4 doesn't really have access to the internet
The mention of a browser, regardless of whether it's Bing or another web browser, suggests that GPT-4 has access to current information, which is not entirely accurate. Such functionality isn't actually part of the AI model's architecture. In other words, the Bing search integration is a feature of the ChatGPT application, not the GPT model itself.
Why does this matter?
Because when building our own app (using the OpenAI API or accessing GPT models), we don’t get the search integration automatically (the models still can't access the internet).
So the question is, is it possible to create an internet-access-enabled AI app? Yes, it is! And we're going to show you how to do it.
Function calling to the rescue!
LLMs are only text-in-text-out tools - they cannot control any other tools directly.
Let’s imagine we want to create an AI app that calculates the prices of products on a website in different currencies. Without access to external tools, the answer will look something like this:
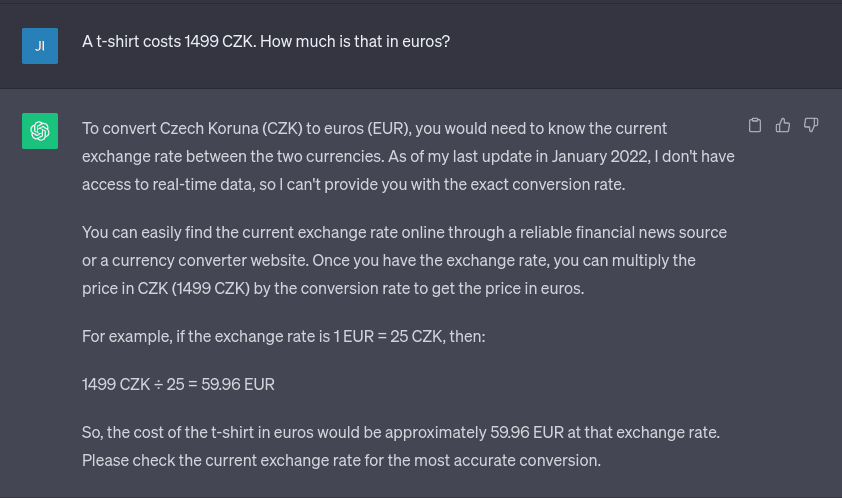
While the above example is from GPT-3.5, GPT-4 would behave the same way, as the model wouldn't have current exchange rates unless it accesses the internet.
Some GPT models, though (specifically gpt-4-0613 and gpt-3.5-turbo-0613) are trained to understand “function declarations”. We can specify different functions in the input of those models to perform certain tasks.
For our currency example, we can tell the model it can use a currency_converter function by passing the following parameters:
{
"model": "gpt-3.5-turbo-0613",
"messages": [
{
"role": "user",
"content": "A t-shirt costs 1499 Czech Crowns. How much is that is US Dollars?"
}
],
"functions": [
{
"name": "currency_converter",
"description": "Calculate live currency and foreign exchange rates using this tool.",
"parameters": {
"type": "object",
"properties": {
"fromCurrency": {
"type": "string",
"description": "The source currency code (eg. USD)",
"enum": ["USD", "EUR", "CZK"]
},
"toCurrency": {
"type": "string",
"description": "The target currency code (eg. USD)",
"enum": ["USD", "EUR", "CZK"]
},
"value": {
"type": "number",
"description": "The amount of money in the source currency."
}
},
"required": ["fromCurrency", "toCurrency", "value"]
}
}
]
}Aside from the regular messages field with the user prompt, we're passing an array of functions which have a name, a short description (to tell the LLM when to use this tool), and a JSON schema of parameters (so the LLM knows what format to generate the parameters in).
In this example, we tell the LLM that we have a function (currency_converter) it can use if needed. This function can convert currencies (and takes three parameters - fromCurrency, toCurrency and value).
Called with these parameters, the model returns the following response:
{
"id": "id-of-the-response",
"object": "chat.completion",
"created": 1698758802,
"model": "gpt-3.5-turbo-0613",
"choices": [
{
"index": 0,
"message": {
"role": "assistant",
"content": null,
"function_call": {
"name": "currency_converter",
"arguments": "{\n \"fromCurrency\": \"CZK\",\n \"toCurrency\": \"USD\",\n \"value\": 1499\n}"
}
},
"finish_reason": "function_call"
}
],
"usage": {
"prompt_tokens": 131,
"completion_tokens": 34,
"total_tokens": 165
}
}The function_call part of the response shows that the model indeed wants to call the specified currency_converter function with the arguments specified in the “arguments” field.
If you want to run the function and pass the result to an LLM in another API call, you might like to check out an example in OpenAI’s documentation).
This was just a simple example of custom functions, but it doesn't really do them justice. They can do anything from web scraping (aka data extraction) to RPA.
How to enhance LLMs with Apify and Langchain
So far, we’ve only talked about how to interface the LLMs with the functions, but what do we do now?
Using Apify's Google Search Results Scraper and the Langchain library, we can enhance our LLM apps with the power of web scraping.
While Langchain provides support for full-fledged function calling, we’ll be fine with a simplified version of it called Tools.
As with function calling, so too with Tools, you need to define a Tool by specifying a name and providing a short description. The difference is that Langchain tools only accept one string as a parameter. You also have to specify the implementation of the function. Consider the following example:
import { initializeAgentExecutorWithOptions } from "langchain/agents";
import { ChatOpenAI } from "langchain/chat_models/openai";
import { DynamicTool } from "langchain/tools";
import { ApifyClient } from 'apify-client';
(async () => {
const tools = [
new DynamicTool({
name: "google-scraper",
description:
"Call this to retrieve information about a subject. Parameter is a search query (string).",
func: async (query) => {
const client = new ApifyClient();
const input = {
"queries": query,
"maxPagesPerQuery": 1,
"resultsPerPage": 10,
};
const run = await client.actor("apify/google-search-scraper").call(input);
const { items } = await client.dataset(run.defaultDatasetId).listItems();
return JSON.stringify(items);
},
}),
];
const executor = await initializeAgentExecutorWithOptions(
tools,
new ChatOpenAI({
modelName: "gpt-3.5-turbo-16k",
temperature: 0,
}),
{
agentType: "openai-functions",
}
);
const result = await executor.run("How much did the Barbie movie make?");
console.log(result);
})();There's a chance you’ll hit the context length limit with this approach. To fix it, you can lower the number of resultsPerPage in the Apify Actor call, filter out unused fields from the result before returning it from the Tool function or do some additional indexing on the data and retrieve only the relevant parts in the Tool function.
So, there you have it: a complete example of an internet-access-enabled AI app that uses Google Search Scraper and LangChain. But why stop here?

Learn how to use Google Search Scraper to add custom actions to your GPTs.
Learn more
If you want to find out more about improving LLMs, using LangChain with scraped data, and storing and indexing data with vector databases, we leave you with the famous words of Augustine of Hippo: “Take up and read!”
Stuff about LLMs
- How to use GPT Scraper to let ChatGPT access the internet
- How to collect data for LLMs
- How to build a custom AI chatbot
- What is retrieval-augmented generation, and why use it for chatbots?
- How to improve AI models with web scraping and data augmentation




