Hi, we're Apify, a full-stack web scraping and browser automation platform. This article about QA from PDFs was inspired by our work on getting better data for AI.
Apify + LangChain = QA from PDFs
Question answering is often used to create conversational client applications, such as custom AI chatbots. In many cases, web content is all you need. But sometimes, the information required for the AI model in question is contained in PDF documents (legal information, HR documents, and other papers that are more likely to be in PDF files than on a web page). "This way, you can chat with PDF and get it to answer your questions."
That's why we're going to show you how to collect content from PDF files, split the text into parts to feed an AI model, and create a QA system that can extract answers from the collected PDF docs.
For this, you'll need two things: Apify (for the data extraction and chunking) and LangChain (to create the QA system).
Scraping and chunking texts in PDFs
The tool we'll use to scrape and chunk PDF files is Apify's PDF Text Extractor. Like all the other web scrapers and automation tools in Apify Store, you can run PDF Text Extractor via:
- Web UI
- Apify API
- Apify CLI
If you're new to Apify, using the UI is the easiest way to test it out, so that's the method we're going to use in this tutorial.
To use this tool and follow along, go to PDF Text Extractor in Apify Store and click the Try for free button.

You'll need an Apify account. If you don't have one, you'll be prompted to sign up when you click that button.
Otherwise, you'll be taken straight to Apify Console (which is basically your dashboard), and you'll see the UI that we're about to walk you through.
1. PDF URLs
To demonstrate, we'll extract the URL provided in the default setting:
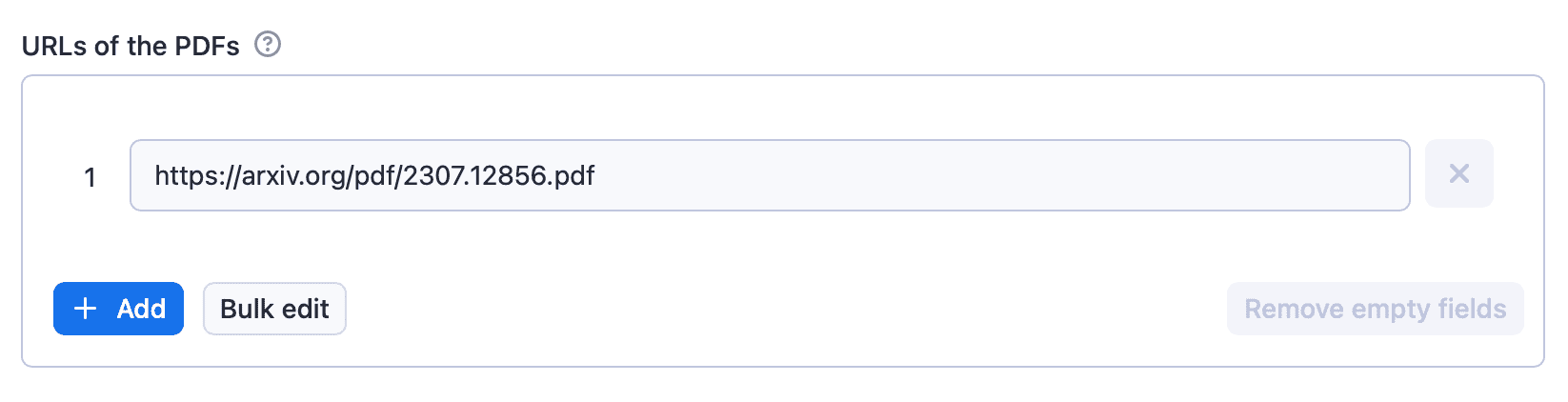
You can use the + Add button to add other URLs to the list, as well. These will be added to the crawler queue, and the extractor will process them one by one.
2. Perform chunking
Large language models have limited memory and a fixed content window, which means that they can only process a certain amount of text at a time, such as when figuring out how to edit a PDF file in Word. That's why PDF Text Extractor offers a chunking option. Chunking means splitting long text into smaller parts so they can be fed to an LLM one at a time.
The default setting has the perform chunking option disabled. To demonstrate the difference, we'll later show you the final dataset with chunking disabled and enabled.

Below Perform chunking is the Chunk size. This is the number of characters, not tokens. It's set to 1,000 by default. Generally, the context window of an LLM is 4,000 tokens. So 1,000 characters should be sufficient in most cases.
The Chunk overlap option refers to the character overlap between text chunks adjacent to each other. Imagine splitting text into two parts. A part of the text will be at the end of the first chunk but also at the beginning. This overlap option is there because it's otherwise difficult to determine the precise point to do the split.
These are the only settings that matter for our demo, so we'll click Start to execute the code and begin the run.
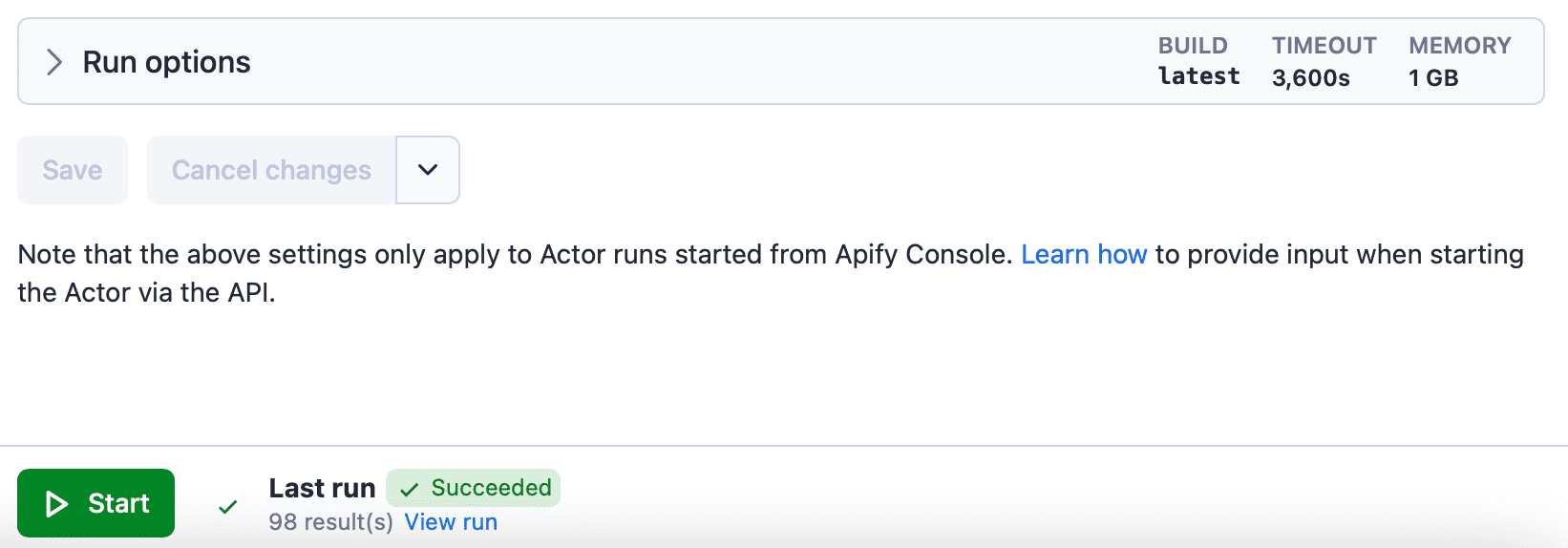
When we ran the extractor with chunking disabled, we got 27 results (that is 27 pages). Each dataset item is a page.
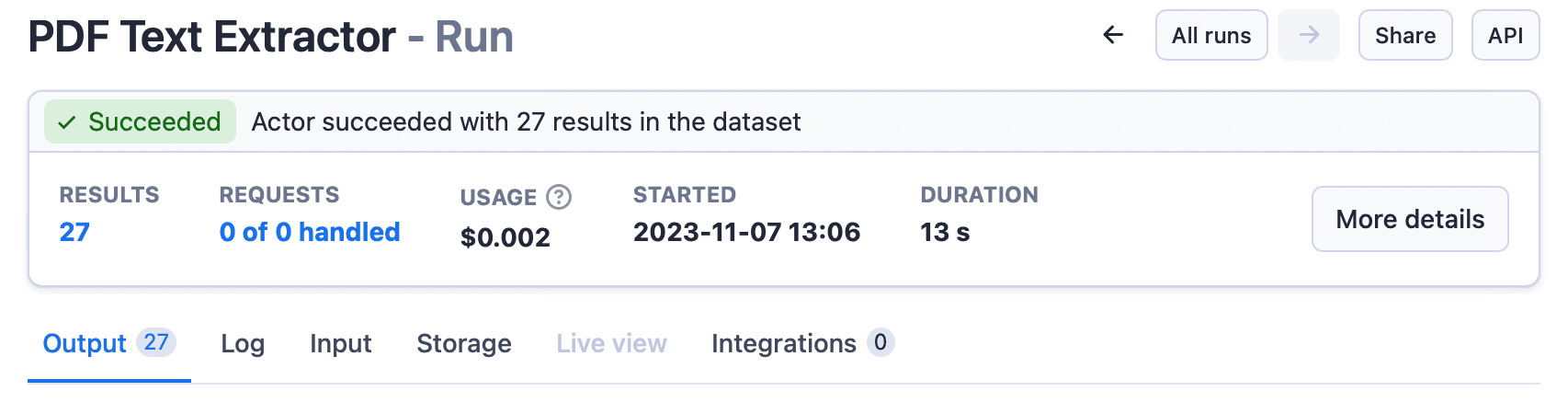
If you click on the Output tab, you can see a preview of the dataset, which includes url (the files from which the text was extracted), index (the order in which text from the file was extracted), and the text from the PDF.

When we ran the extractor with chunking enabled, we got 98 results, as the text had been split.
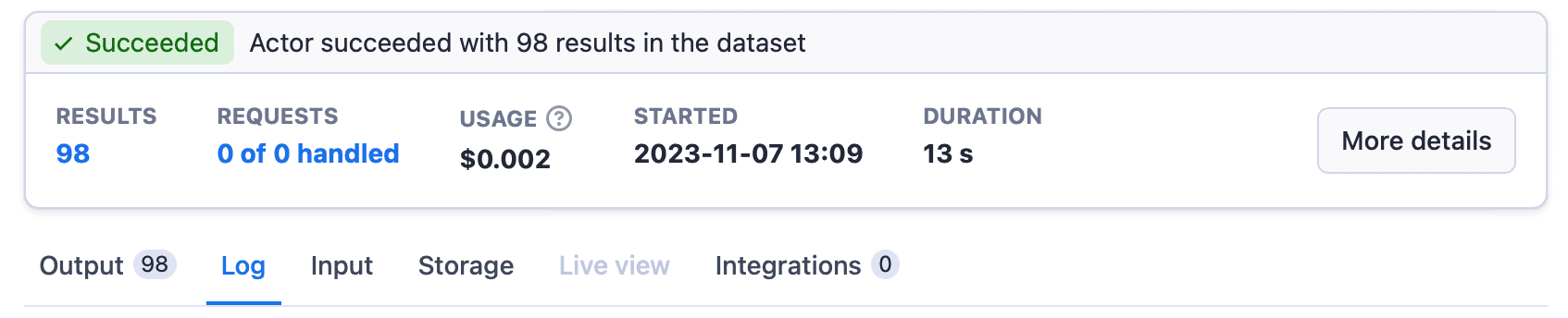
Here's the chunked dataset:
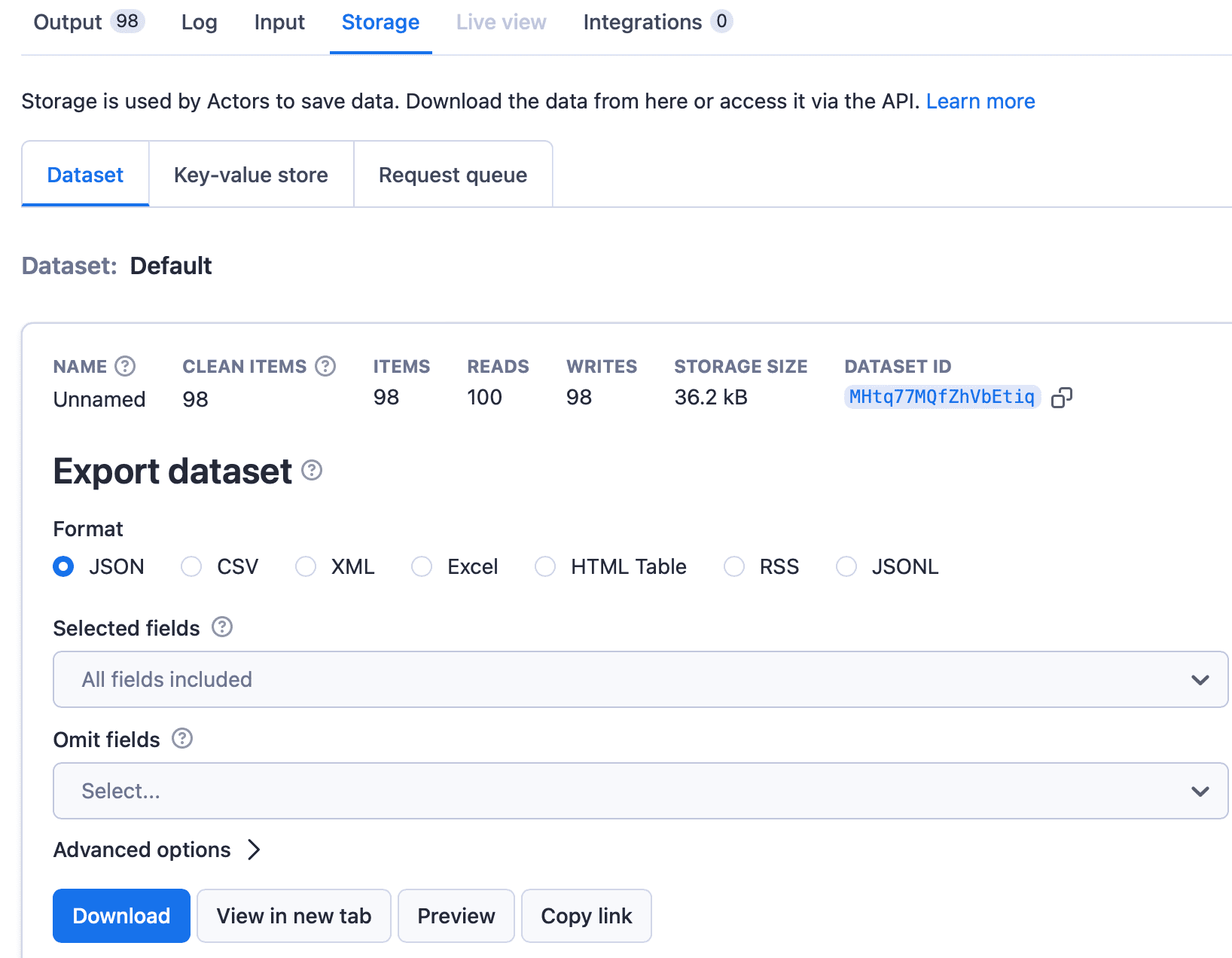
We've provided the datasets in JSON format, but you can choose from other formats by going to the Storage tab.
Question answering using PDF Text Extractor with LangChain
In the last part of this blog post, we’re going to use PDF Text Extractor combined with LangChain to ask questions about the content of a PDF file. We’ll use Python as the programming language of choice.
First, let’s install the required packages:
pip install apify-client chromadb langchain openai python-dotenv tiktokenNext, let’s create a .env file for API keys:
OPENAI_API_KEY=your_api_key
APIFY_API_TOKEN=your_api_keyLastly, we'll create a main.py file that will use the PDF Text Extractor to retrieve text from a PDF file and then perform question answering over it.
The process is quite simple:
- We use the Apify integration in LangChain to run the PDF Text Extractor with our specified parameters (the PDF URL refers to the WebAgent paper from the AI lab DeepMind)
- We store all the text from the PDF in a vector store (Chroma in our case)
- We can now perform QA using our defined queries
Here's the Python implementation:
from langchain.document_loaders.base import Document
from langchain.indexes import VectorstoreIndexCreator
from langchain.utilities import ApifyWrapper
from dotenv import load_dotenv
# Load environment variables from a .env file
load_dotenv()
if __name__ == "__main__":
# Use the Apify integration to run the extractor
apify = ApifyWrapper()
loader = apify.call_actor(
actor_id="jirimoravcik/pdf-text-extractor",
run_input={"urls": ["https://arxiv.org/pdf/2307.12856.pdf"], "chunk_size": 1000},
dataset_mapping_function=lambda item: Document(
page_content=item["text"], metadata={"source": item["url"]}
),
)
# Create a vector index and store all the text from the PDF
index = VectorstoreIndexCreator().from_loaders([loader])
# Ask some questions about the PDF
query = "What is the WebAgent? Who is behind its creation?"
result = index.query_with_sources(query)
print(result["answer"])
print('Sources:', result["sources"])We simply run the code:
python main.pyAnd here's the output for our query:
WebAgent is an LLM-driven agent that learns from self-experience to complete tasks on real websites following natural language instructions. It was created by Izzeddin Gur, Hiroki Furuta, Austin Huang, Mustafa Safdari, Yutaka Matsuo, Douglas Eck, and Aleksandra Faust from Google DeepMind and The University of Tokyo.
Sources: https://arxiv.org/pdf/2307.12856.pdfBefore you go
We've shown you how to utilize Apify and LangChain to do QA from a PDF, but if you want to learn more about scraping web data for AI, we have more helpful content for you below.