


ChatGPT can search the net these days and process any live web page with a bit of help from web scraping, but there’s an even more interesting use case for combining large language models and scraping. By crawling a website and feeding its content to large language models, you enable a new level of interaction – it's like talking to the website directly.
This is true of documentation, knowledge bases, help articles, blogs, research, or any other content. It means an end to search boxes and trying to guess the terms that will lead you to the right page. And giving it the right data means that the LLM can give you an easily understandable, natural-language answer to any question about the content.
This functionality can be used to create a custom AI chatbot, feed and fine-tune any LLM, or generate personalized content on the fly that accurately reflects a brand tone. The ingested data can also be processed by the LLM to update or improve it.
Apify's mission is to make the web more programmable. A big part of that is getting better data for AI, so that's what we're doing. Check us out.
Using web data to talk to any website
Apify has an Apify Actor to make it easy to ingest content from any website. Website Content Crawler performs a deep crawl of a website and automatically removes headers, footers, menus, ads, and other noise from the web pages in order to return only text content that can be directly fed to the LLM.
It has a simple input configuration so that it can be easily integrated into customer-facing products. It scales gracefully and can be used for small sites as well as sites with millions of pages. The results can be retrieved using API in formats such as JSON or CSV, which can be fed directly to your LLM, vector database, or directly to ChatGPT.
Website Content Crawler has an integration for LangChain and an Apify Dataset Loader for LlamaIndex. So go ahead and try it out for your own website or build on it. Incorporate it into your custom AI chatbot, voice-based conversational AI, create apps on it, whatever you can imagine.
Here’s a step-by-step guide on how to use it.
How to extract web data for LLMs
Step 1. Get Website Content Crawler
Go to Apify Store and search for “Website Content Crawler” or check out the AI category.
Step 2. Enter the URL of the website you want to scrape
Website Content Crawler will run just fine on the default settings, so you can click Start if you want to take it for a quick test drive. The default example will crawl a single page from the Apify documentation.
Step 3. Configure input parameters to control the crawl
Website Content Crawler can do extremely deep crawls, so you will definitely want to set some limits to minimize your platform usage (every free Apify account comes with $5 of prepaid usage, which should be enough to test or scrape small websites).
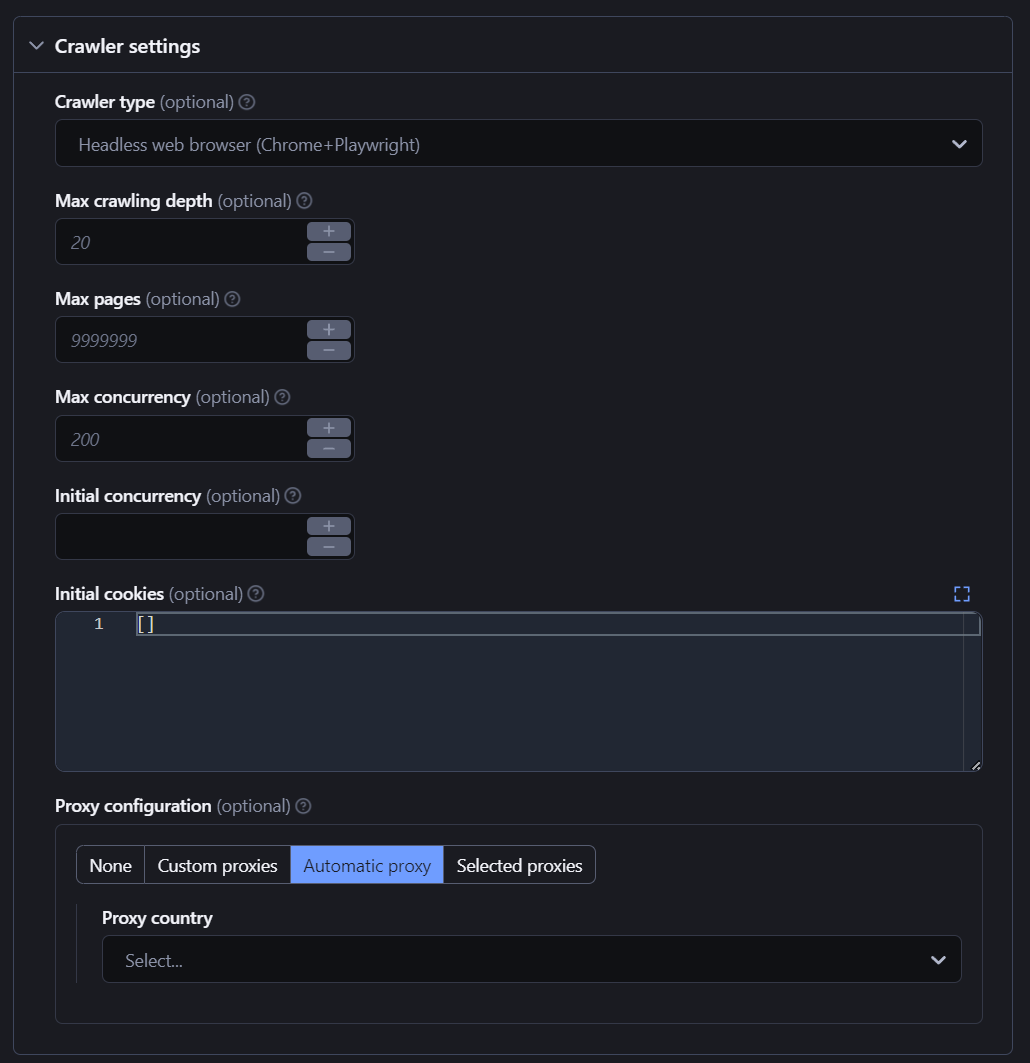
Each of these settings will adjust the crawler behavior. Here’s a quick overview of the main ones:
- Crawler type: a headless browser is great for modern websites that use a lot of JavaScript, but the crawl will be slower. Raw HTTP will be fast but might not work for every website, while raw HTTP client with JS execution is a hybrid approach that you can experiment with.
- Max crawling depth: tells the crawler the maximum number of links starting from the start URL that the crawler will recursively descend.
Check out the input parameters for a full description of all settings.
Once you’ve established sensible limits, you can go ahead and crawl any website. Try it on your own documentation or knowledge base.
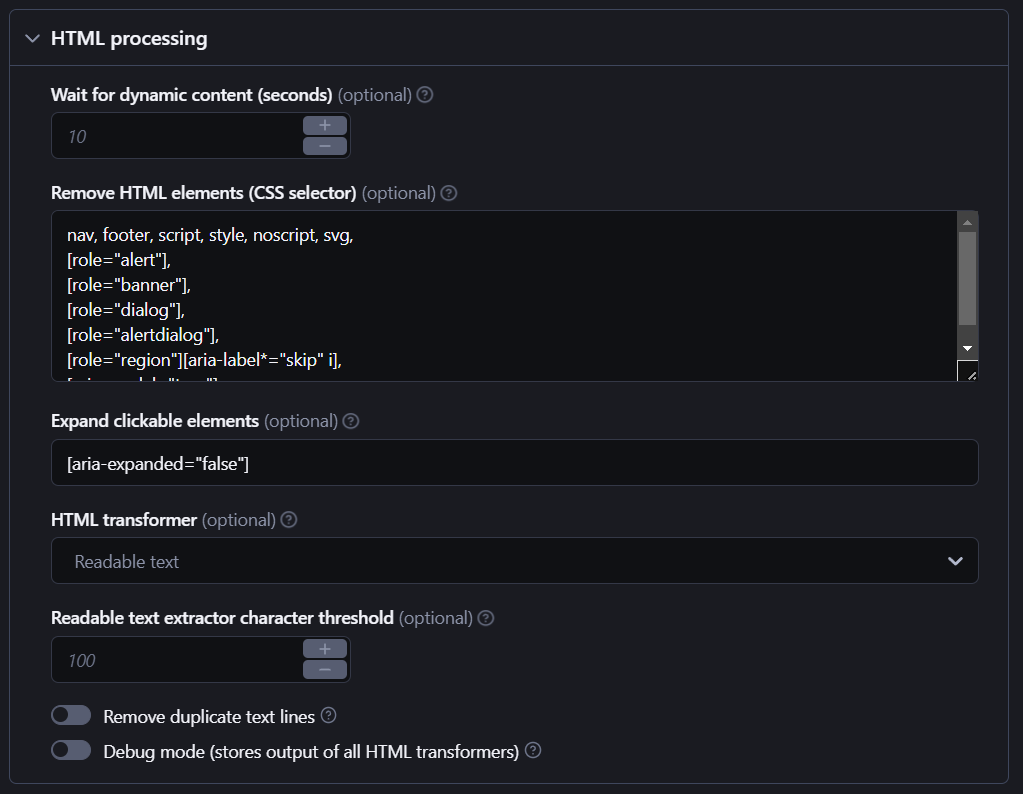
Step 4. Refine HTML processing and output settings
Website Content Crawler can be configured to output scraped content so that you don’t give your LLM unwanted content, such as headers, nav, and footers, and this is the default setting. You can customize the HTML elements you want to ignore.
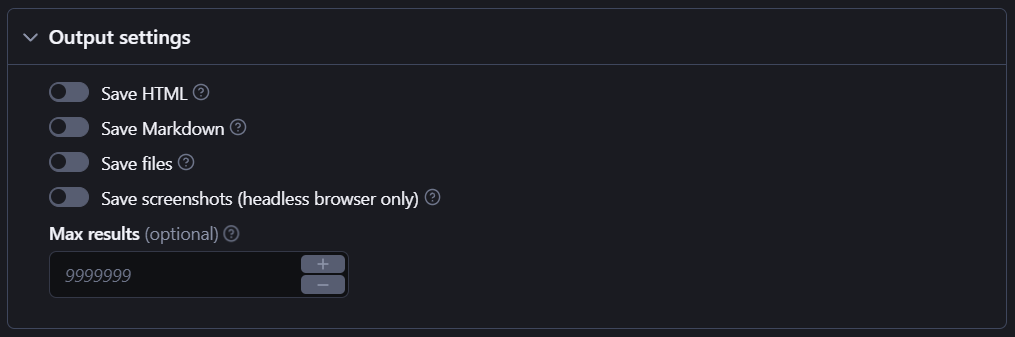
And there are plenty of output settings for you to experiment with, such as saving HTML or Markdown, screenshots, and so on.
Step 5. Feed the content to your LLM
Once the crawl is finished, you can export the scraped content in JSON, HTML, and a range of other formats, so choose whatever works for your LLM.
Here’s an extract from some of the scraped content from web scraping for beginners in JSON format:
{
"url": "https://docs.apify.com/academy/web-scraping-for-beginners",
"crawl": {
"loadedUrl": "https://docs.apify.com/academy/web-scraping-for-beginners",
"loadedTime": "2023-05-31T12:43:02.936Z",
"referrerUrl": "https://docs.apify.com/academy/web-scraping-for-beginners",
"depth": 0
},
"metadata": {
"canonicalUrl": "https://docs.apify.com/academy/web-scraping-for-beginners",
"title": "Web scraping for beginners | Apify Documentation",
"description": "Learn how to develop web scrapers with this comprehensive and practical course. Go from beginner to expert, all in one place.",
"author": null,
"keywords": null,
"languageCode": "en"
},
"screenshotUrl": null,
"text": "Web scraping for beginners\\nLearn how to develop web scrapers with this comprehensive and practical course. Go from beginner to expert, all in one place.\\nWelcome to Web scraping for beginners, a comprehensive, practical and long form web scraping course that will take you from an absolute beginner to a successful web scraper developer. If you're looking for a quick start, we recommend trying this tutorial instead.\\nThis course is made by Apify, the web scraping and automation platform, but we will use only open-source technologies throughout all academy lessons. This means that the skills you learn will be applicable to any scraping project, and you'll be able to run your scrapers on any computer. No Apify account needed.\\nIf you would like to learn about the Apify platform and how it can help you build, run and scale your web scraping and automation projects, see the Apify platform course, where we'll teach you all about Apify serverless infrastructure, proxies, API, scheduling, webhooks and much more.\\nWhy learn scraper development?\\nWith so many point-and-click tools and no-code software that can help you extract data from websites, what is the point of learning web scraper development? Contrary to what their marketing departments say, a point-and-click or no-code tool will never be as flexible, as powerful, or as optimized as a custom-built scraper.\\nAny software can do only what it was programmed to do. If you build your own scraper, it can do anything you want. And you can always quickly change it to do more, less, or the same, but faster or cheaper. The possibilities are endless once you know how scraping really works.\\nScraper development is a fun and challenging way to learn web development, web technologies, and understand the internet. You will reverse-engineer websites and understand how they work internally, what technologies they use and how they communicate with their servers. You will also master your chosen programming language and core programming concepts. When you truly understand web scraping, learning other technology like React or Next.js will be a piece of cake.\\nCourse Summary\\nWhen we set out to create the Academy, we wanted to build a complete guide to modern web scraping - a course that a beginner could use to create their first scraper, as well as a resource that professionals will continuously use to learn about advanced and niche web scraping techniques and technologies. All lessons include code examples and code-along exercises that you can use to immediately put your scraping skills into action.\\nThis is what you'll learn in the Web scraping for beginners course:\\nWeb scraping for beginners\\nBasics of data extraction\\nBasics of crawling\\nBest practices\\nRequirements\\nYou don't need to be a developer or a software engineer to complete this course, but basic programming knowledge is recommended. Don't be afraid, though. We explain everything in great detail in the course and provide external references that can help you level up your web scraping and web development skills. If you're new to programming, pay very close attention to the instructions and examples. A seemingly insignificant thing like using [] instead of () can make a lot of difference.\\nIf you don't already have basic programming knowledge and would like to be well-prepared for this course, we recommend taking a JavaScript course and learning about CSS Selectors.\\nAs you progress to the more advanced courses, the coding will get more challenging, but will still be manageable to a person with an intermediate level of programming skills.\\nIdeally, you should have at least a moderate understanding of the following concepts:\\nJavaScript + Node.js\\nIt is recommended to understand at least the fundamentals of JavaScript and be proficient with Node.js prior to starting this course. If you are not yet comfortable with asynchronous programming (with promises and async...await), loops (and the different types of loops in JavaScript), modularity, or working with external packages, we would recommend studying the following resources before coming back and continuing this section:\\nasync...await (YouTube)\\nJavaScript loops (MDN)\\nModularity in Node.js\\nGeneral web development\\nThroughout the next lessons, we will sometimes use certain technologies and terms related to the web without explaining them. This is because the knowledge of them will be assumed (unless we're showing something out of the ordinary).\\nHTML\\nHTTP protocol\\nDevTools\\njQuery or Cheerio\\nWe'll be using the Cheerio package a lot to parse data from HTML. This package provides a simple API using jQuery syntax to help traverse downloaded HTML within Node.js.\\nNext up\\nThe course begins with a small bit of theory and moves into some realistic and practical examples of extracting data from the most popular websites on the internet using your browser console. So let's get to it!\\nIf you already have experience with HTML, CSS, and browser DevTools, feel free to skip to the Basics of crawling section."
},
It really is that easy for you to talk to any website with GPT, Llama, Alpaca, or any other large language model. You can use Website Content Crawler for your own AI and web scraping projects or build upon it for your customers. Enhance the performance of your LLMs, create personalized content, develop custom chatbots, and improve existing content with summarization, proofreading, translation, or style changes.
Give your LLM a memory with LangChain
The LangChain framework is designed to simplify the creation of applications using large language models. LangChain acts as an abstraction layer that handles integration with APIs, cloud storage platforms, other large language models, and an extensive range of other services, enabling document analysis, custom AI chatbot creation, code analysis, and data manipulation.
Check out this guide on how to get started with LangChain and some more examples of how combining Website Content Crawler and LangChain can be used to easily create ChatGPT-like query interfaces for websites.
Internal Apify AI hackathon: how to create a custom AI chatbot
Apify is really excited about what LLMs can do, and last year we held an internal AI hackathon to do a couple of days of intense work on projects our devs found exciting. One of the most interesting results was how to create a custom AI chatbot with Python.
Get the latest updates and posts




