


Scrapy is a fast and powerful Python web scraping framework that can be used to efficiently crawl websites and extract their data. But for websites that heavily rely on JavaScript for rendering their content, you need to combine it with a tool that can handle it. Hence, Playwright.
Playwright is an open-source automation library that is a great tool for end-to-end testing and can also perform other tasks, such as web scraping.
By combining Scrapy's web crawling capabilities with Playwright's browser interaction, you can conveniently carry out complex web scraping tasks.
This tutorial will walk you through setting up Scrapy-Playwright and help you understand its basic commands and advanced features.
Provides a simple framework for parallel crawling of web pages using headless Chromium, Firefox and Webkit browsers with Playwright. The URLs to crawl are fed either from a static list of URLs or from a dynamic queue of URLs, enabling recursive crawling of websites.
Setting up Scrapy with Playwright
Before creating a scraping task, you need to set up your working environment.
Ensure you have Python installed on your computer. Run python --version or python3 --version to confirm.
Choose your desired directory (desktop, document, or downloads), create a folder scrapy-python for the project, and change your directory into it.
The command below creates the folder and changes your working directory into the folder.
# Create the project directory
mkdir scrapy-python
# Change to newly created directory
cd scrapy-pythonCreate a separate Python environment for your project using Virtualenv: python3 -m venv myenv and source myenv/bin/activate to activate the virtual environment.
Install Scrapy (pip install scrapy), Playwright (pip install playwright), and the browser binaries using playwright install.
Initialize a Scrapy Project: scrapy startproject apify_sp. Change your directory to the newly created folder using cd apify_spider.
Install scrapy-playwright. This library bridges the gap between Scrapy and Playwright. Install it using pip install scrapy-playwright.
python 3 doesn't work for you while running the commands in the terminal/cmd, replace it with python. If you encounter other installation errors, look up the error on the GitHub issues pages of Scrapy, Playwright, and Scrapy-Playwright for similar issues and possible solutions.
Open the project in your desired code editor, navigate to settings.py and add the configuration below.
TWISTED_REACTOR = "twisted.internet.asyncioreactor.AsyncioSelectorReactor"
DOWNLOAD_HANDLERS = {
'http': 'scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler',
'https': 'scrapy_playwright.handler.ScrapyPlaywrightDownloadHandler',
}
TWISTED_REACTOR configures Scrapy to use a specific event loop provided by Twisted (an event-driven networking engine) that is compatible with Python’s asynchronous I/O framework, asyncio. Meanwhile, the DOWNLOAD_HANDLERS settings tell Scrapy to use Playwright’s download handler for both HTTP and HTTPS requests.
These settings are essential for making sure that both asynchronous operations from Playwright and Scrapy's architecture work together effectively.
How to use Scrapy Playwright
After setting up your project, you need to test if it's perfectly set up. Below is a basic script that tests your project setup.
To create this script, open the spiders folder, create a file called event.py, and paste the code below into it.
To run the script, open your terminal or command prompt. Navigate to the directory where scrapy.cfg is.
If you're following this article's project structure, you should be in the scrapy-playwright/apify_sp directory.
Run scrapy crawl clickable -o output.json. This will run the script and save the result in a file output.json .
from scrapy import Spider, Request
from scrapy_playwright.page import PageMethod
class EventsSpider(Spider):
"""Handle page events and extract the first clickable link."""
name = 'clickable'
def start_requests(self):
yield Request(
url='https://apify.com/store',
meta={
"playwright": True,
# Include the page object in the response
"playwright_include_page": True,
"playwright_page_methods": [
# Wait for the search input to be loaded
PageMethod("wait_for_selector", 'input[data-test="actor-store-search"]'),
PageMethod("fill", 'input[data-test="actor-store-search"]', 'tiktok'),
PageMethod("click", 'input[data-test="actor-store-search"] + svg'),
# Wait 1 second for the next page to load
PageMethod("wait_for_timeout", 1000),
],
},
callback=self.parse
)
async def parse(self, response, **kwargs):
# Use the Playwright page object included in the response
page = response.meta['playwright_page']
# Find all Actor Cards on the page
actor_cards = await page.query_selector_all('a[data-test="actor-card"]')
actor_data = []
# Get data from to the first five Actors
for actor_card in actor_cards[:5]:
url = await actor_card.get_attribute('href')
actor_name_element = await actor_card.query_selector('div.ActorStoreItem-title h3')
actor_name = await actor_name_element.inner_text()
actor_data.append(
{
"url": url,
"actor_name": actor_name
}
)
yield {'actors_data': actor_data}
# Close the page
await page.close()This script starts by visiting https://apify.com/store, where it waits for the search input to show up, types in "tiktok," and clicks the search button. After a quick pause to let the page load any new content, it grabs the URLs and names of the first five resulting Actors it finds and yields the extracted data as a Python dictionary.
Even though some of the syntax looks familiar if you’ve used the Playwright API before, scrapy-playwright tweaks things a bit to fit nicely within the Scrapy framework. So next, we’ll break down each part into smaller, more manageable pieces to help understand what is happening in each section of the code.
1. Navigating to a URL
from scrapy import Spider, Request
class SimpleSpider(Spider):
name = 'clickable'
def start_requests(self):
yield Request(
url='https://apify.com/store',
meta={
"playwright": True,
},
callback=self.parse
)
async def parse(self, response):
# Handle the response after interacting with the page
passThe example above is a simplified version of what we did in the main code. Here, we’re just accessing the target website using scrapy_playwright. Notice the meta parameter with the option "playwright": True in the Request. This tells Scrapy that we want to use Playwright to load the page.
2. Typing text into an input field
from scrapy import Spider, Request
from scrapy_playwright.page import PageMethod
class EventsSpider(Spider):
name = 'clickable'
def start_requests(self):
yield Request(
url='https://apify.com/store',
meta={
"playwright": True,
# Include the page object in the response
"playwright_include_page": True,
"playwright_page_methods": [
# Wait for the search input to be loaded
PageMethod("wait_for_selector", 'input[data-test="actor-store-search"]'),
# Type some text in the input and click the search button
PageMethod("fill", 'input[data-test="actor-store-search"]', 'tiktok'),
PageMethod("click", 'input[data-test="actor-store-search"] + svg'),
# Wait 2 seconds for the next page to load
PageMethod("wait_for_timeout", 2000),
],
},
callback=self.parse
)
async def parse(self, response):
# Handle the response after interacting with the page
passContinuing from the previous example, this code takes things a step further by actually interacting with the page. It’s set up to visit https://apify.com/store, wait for the search input to appear, type “tiktok” into the search bar, and then click the search button.
A key part of making all this work is the PageMethod. In the context of scrapy-playwright, PageMethod allows you to define specific actions that Playwright will perform on the page. In this example, we use PageMethod to wait for the search input to load (wait_for_selector), fill in the input field with “tiktok” (fill), and then click the search button (click). We also add a brief delay (wait_for_timeout) to ensure the page has enough time to load the results.

3. Extracting text from an element
# rest of the code
async def parse(self, response, **kwargs):
# Use the Playwright page object included in the response
page = response.meta['playwright_page']
# Find all Actor Cards on the page
actor_cards = await page.query_selector_all('a[data-test="actor-card"]')
actor_data = []
# Get data from to the first five Actors
for actor_card in actor_cards[:5]:
url = await actor_card.get_attribute('href')
actor_name_element = await actor_card.query_selector('div.ActorStoreItem-title h3')
actor_name = await actor_name_element.inner_text()
actor_data.append(
{
"url": url,
"actor_name": actor_name
}
)
yield {'actors_data': actor_data}
# Close the page
await page.close()When using scrapy-playwright, you’ll often want to extract text from an element within the parse method. You can easily do this by using a variation of page.query_selector("<selector>") that best fits your needs.
In our parse method, we start by grabbing the Playwright page object from response.meta['playwright_page']. This page object is super important because it lets us interact directly with the fully rendered page.
Next, we use page.query_selector_all() to find all the <a> tags that match 'a[data-test="actor-card"]'. These tags are the links to different Actor pages on the site. We loop through the first five of these links, using get_attribute('href') to pull the URL from each one and store it in a list called link_urls.
Finally, we yield an actors_data dictionary with the first five Actor URLs and names. You can save the data to a JSON file by adding -o output.json to your crawl command, like this: scrapy crawl clickable -o output.json.
4. Taking a screenshot
from scrapy import Spider, Request
from scrapy_playwright.page import PageMethod
class EventsSpider(Spider):
"""Handle page events and extract the first clickable link."""
name = 'clickable'
def start_requests(self):
yield Request(
url='https://apify.com/store',
meta={
"playwright": True,
# Include the page object in the response
"playwright_include_page": True,
"playwright_page_methods": [
# Wait for the search input to be loaded
PageMethod("wait_for_selector", 'input[data-test="actor-store-search"]'),
PageMethod("fill", 'input[data-test="actor-store-search"]', 'tiktok'),
PageMethod("click", 'input[data-test="actor-store-search"] + svg'),
# Wait 1 second for the next page to load
PageMethod("wait_for_timeout", 1000),
# Take a screenshot
PageMethod("screenshot", path="apify_store_screenshot.png", full_page=False),
],
},
callback=self.parse
)
async def parse(self, response, **kwargs):
# Data extraction logic...
passAs you can see from the code above, taking a screenshot with scrapy-playwright is pretty simple. You just use PageMethod as before, but this time with the "screenshot" option, specifying the path where you want to save the screenshot. You can also decide whether to capture the entire page or just a portion of it. Below you can see the screenshot generated by the script:
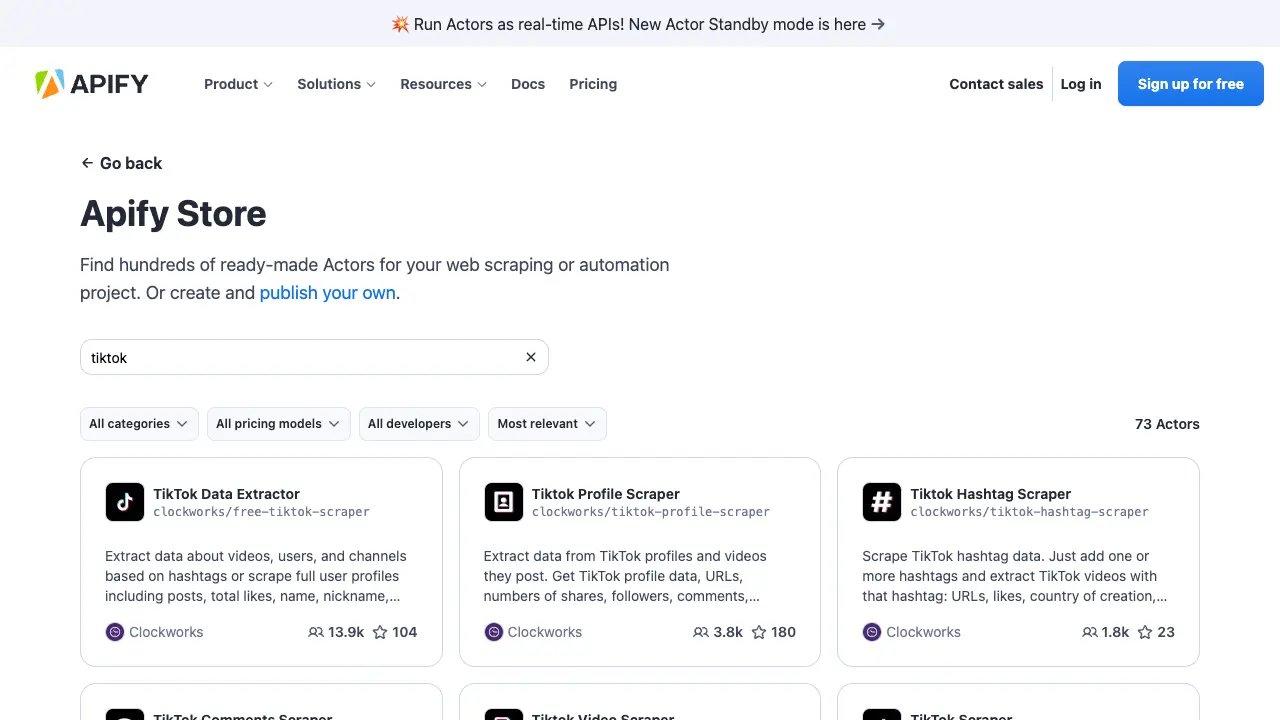
5. Handling JavaScript-rendered sites with Playwright
One of the main reasons to use scrapy-playwright is to scrape data from dynamic websites since Scrapy alone can’t render JavaScript.
If you’re using Playwright to load a dynamic webpage, it means you can scrape the data from it. To do this with scrapy-playwright, simply pass the meta dictionary to your Request and set "playwright": True, as shown in the code below.
from scrapy import Spider, Request
class SimpleSpider(Spider):
name = 'dynamic'
def start_requests(self):
yield Request(
url='https://phones.mintmobile.com/',
meta={
"playwright": True,
},
callback=self.parse
)
async def parse(self, response):
# Handle the response after interacting with the page
pass6. Waiting for dynamic content
When scraping JavaScript-rendered content, it’s important to wait for the dynamic elements to load before grabbing the data.
With scrapy-playwright, this is easy to do. Just add the "playwright_page_methods" array to your Request, and use PageMethod to tell Playwright what to wait for — like using "wait_for_selector" with the element’s selector. This way, Playwright waits until the content is fully loaded before scraping, as shown in the example below.
from scrapy import Spider, Request
from scrapy_playwright.page import PageMethod
class EventsSpider(Spider):
name = 'dynamic'
def start_requests(self):
yield Request(
url='https://phones.mintmobile.com/',
meta={
"playwright": True,
# Include the page object in the response
"playwright_include_page": True,
"playwright_page_methods": [
# Wait for the search input to be loaded
PageMethod("wait_for_selector", 'div[data-product-category="Phones"]'),
],
},
callback=self.parse
)
async def parse(self, response):
# Handle the response after interacting with the page
pass7. Scrolling down infinite scroll pages
To handle infinite scrolling, we need to evaluate the scroll height and create a loop that keeps scrolling until we reach the bottom of the page and can’t scroll any further.
Since scrapy-playwright’s PageMethod doesn’t support loops, we’ll need to use some native Playwright syntax and implement the scrolling logic directly in the parse function of our scraper. The example below shows how to scroll through Nike’s shoe collection until all the shoes are loaded.
from scrapy import Spider, Request
class EventsSpider(Spider):
"""Handle page events and extract the first clickable link."""
name = 'nike'
def start_requests(self):
yield Request(
url='https://www.nike.com/w/',
meta={
"playwright": True,
# Include the page object in the response
"playwright_include_page": True,
},
callback=self.parse
)
async def parse(self, response, **kwargs):
# Use the Playwright page object included in the response
page = response.meta['playwright_page']
# Scroll the page to load more content
previous_height = await page.evaluate("document.body.scrollHeight")
while True:
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await page.wait_for_timeout(1000) # Wait for 2 seconds for new content to load
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == previous_height:
break
previous_height = new_height
# Close the page
await page.close()
8. Scraping multiple pages
When scraping data from websites with multiple pages, the goal is to automate the process of navigating through each page and extracting the relevant data.
With scrapy-playwright, you can easily interact with elements like "next" buttons to navigate from one page to the next. While this is just one technique for paginating through websites, it’s surprisingly effective in a wide range of scenarios despite its simplicity, as shown in the example below.
from scrapy import Spider, Request
class EventsSpider(Spider):
name = 'pages'
def start_requests(self):
yield Request(
url='https://apify.com/store/categories/ai',
meta={
"playwright": True,
# Include the page object in the response
"playwright_include_page": True,
},
callback=self.parse
)
async def parse(self, response):
page = response.meta["playwright_page"]
# Scrape the current page
async for item in self.scrape_page(page):
yield item
# Handle pagination
while True:
next_button = await page.query_selector('button[data-test="page-next-button"]')
if next_button:
is_disabled = await next_button.get_attribute('disabled')
if is_disabled:
break
await next_button.click()
await page.wait_for_timeout(2000) # Wait for 2 seconds for the next page to load
async for item in self.scrape_page(page):
yield item
else:
break
# Close the page to ensure resources are released
await page.close()
async def scrape_page(self, page):
# Extract data from the current page
actors = await page.query_selector_all('a[data-test="actor-card"]')
for actor in actors:
actor_name = await (await actor.query_selector('div.ActorStoreItem-title h3')).inner_text()
actor_description = await (await actor.query_selector('p.ActorStoreItem-desc')).inner_text()
developer_name = await (await actor.query_selector('p.ActorStoreItem-user-fullname')).inner_text()
print(actor_name, actor_description, developer_name)
yield {
'name': actor_name,
'description': actor_description,
'developer': developer_name,
}The script starts by loading the initial page with Playwright enabled, ensuring the content fully renders. The parse function then scrapes data from the current page and checks for a “next” button. If the button is present and clickable, the script clicks it, waits for the next page to load, and continues scraping. This loop repeats until there are no more pages left, ensuring that you extract data from all pages.
9. Managing Playwright sessions and concurrency in Scrapy
Managing sessions and concurrency is important when handling multi-page websites or when scraping at scale. Playwright sessions should be handled carefully to avoid resource leakage and ensure that each browser instance is properly closed after use.
To manage concurrency, you can control the number of Playwright instances that Scrapy runs simultaneously by setting CONCURRENT_REQUESTS in your Scrapy settings settings.py. This setting determines how many requests Scrapy will handle at once, allowing you to adjust the load based on your system’s capability.
In addition to CONCURRENT_REQUESTS, you can also set PLAYWRIGHT_MAX_PAGES_PER_CONTEXT to limit the number of concurrent Playwright pages.
# Adjust this number based on your system's capability
CONCURRENT_REQUESTS = 8
# Set the maximum number of concurrent Playwright pages
PLAYWRIGHT_MAX_PAGES_PER_CONTEXT = 4Each request with playwright set to True in its meta opens a new browser instance, which can be resource-intensive.
It is also essential to properly close each Playwright page and browser session to free up resources. This can be done in the spider’s parse method or in dedicated middleware.
async def parse(self, response, **kwargs):
page = response.meta['playwright_page']
# Perform scraping tasks here
await page.close()10. Running Playwright in headless mode
By default, scrapy-playwright runs Playwright in headless mode, so you won’t see your script as it executes. If you want to watch the script in action, you can change that by adding the following configuration to settings.py:
PLAYWRIGHT_LAUNCH_OPTIONS = {
"headless": False
}11. Automating form submissions
Playwright can mimic user interactions like filling out forms and clicking buttons, making it possible to perform tasks like logging into a website and extracting data afterward.
In the example below, we use scrapy-playwright’s PageMethod to access a test website with a login form, fill in the credentials, and then take a screenshot after logging in to show that the automation worked.
from scrapy import Spider, Request
from scrapy_playwright.page import PageMethod
class EventsSpider(Spider):
name = 'form'
def start_requests(self):
yield Request(
url='https://practicetestautomation.com/practice-test-login/',
meta={
"playwright": True,
"playwright_include_page": True,
"playwright_page_methods": [
# Fill the username and password fields and click the submit button
PageMethod("fill", 'input#username', "student"),
PageMethod("fill", 'input#password', "Password123"),
PageMethod("click", 'button#submit'),
PageMethod("wait_for_selector", 'h1.post-title'),
PageMethod("screenshot", path="login.png", full_page=False),
],
},
callback=self.parse
)
async def parse(self, response):
pass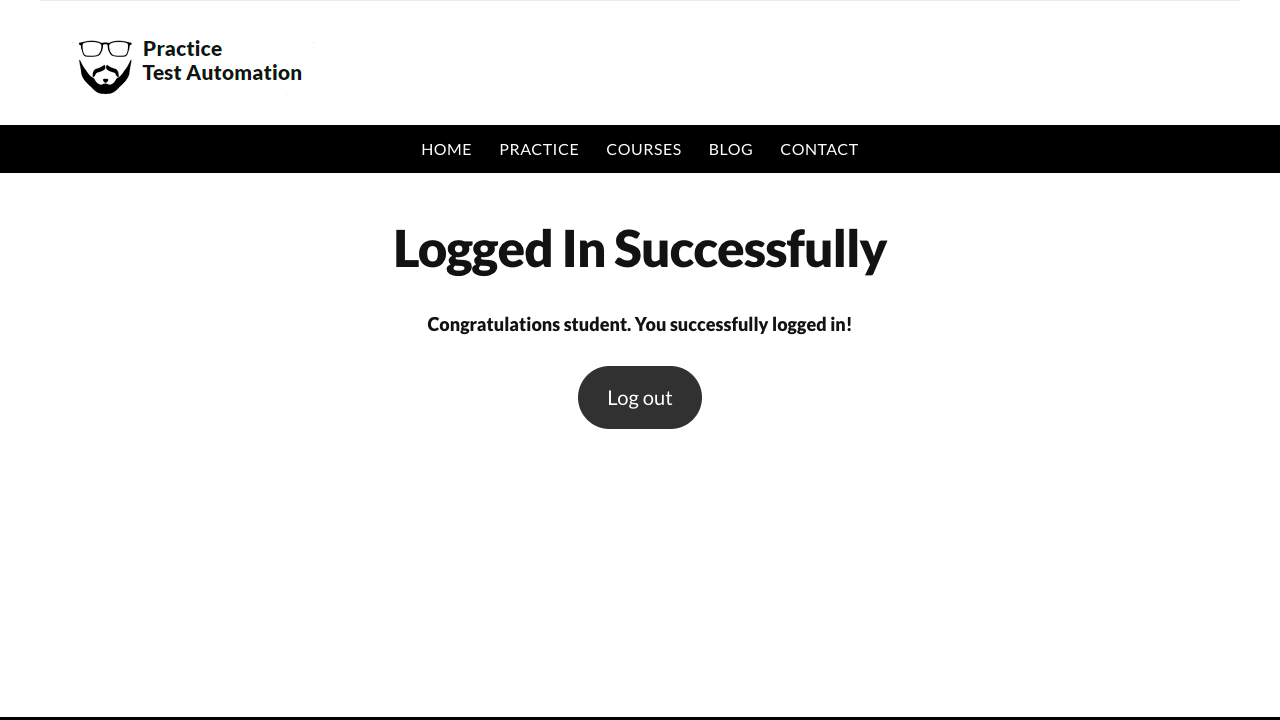
12. Capturing AJAX data
AJAX (Asynchronous JavaScript and XML) is a widely used technique that allows webpages to update specific parts without reloading the entire page by fetching data dynamically from the server. For example, that’s how social media sites load new content as you scroll, without needing to reload the entire page.
Capturing AJAX data can make your web scraping process much more efficient. Often, AJAX requests retrieve data in a well-structured format like JSON, meaning you might not need to scrape the HTML at all.
By directly accessing AJAX data from the server’s API, you can avoid the complexity of parsing HTML and work with organized, reliable data that's less prone to changes in the website's structure. In the example below, we access the Nike website, which uses AJAX to load new data as you scroll. Instead of scraping the data from the page, we'll capture the AJAX data from the server.
from scrapy import Spider, Request
class EventsSpider(Spider):
name = 'nike'
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
self.captured_ajax_data = []
def start_requests(self):
yield Request(
url='https://www.nike.com/w/jordan-shoes-37eefzy7ok',
meta={
"playwright": True,
"playwright_include_page": True,
},
callback=self.parse
)
async def parse(self, response):
page = response.meta["playwright_page"]
# Function to handle AJAX requests
async def handle_route(route):
request = route.request
if "api.nike.com" in request.url:
# Continue the request and get the response
await route.continue_()
response = await request.response()
if response:
# Capture the AJAX data
ajax_data = await response.body()
self.captured_ajax_data.append(ajax_data)
else:
self.logger.warning(f"No response for request: {request.url}")
else:
await route.continue_()
# Intercept all network requests
await page.route("**/*", handle_route)
# Function to scroll the page and load more data
async def scroll_page():
previous_height = await page.evaluate("document.body.scrollHeight")
while True:
await page.evaluate("window.scrollTo(0, document.body.scrollHeight)")
await page.wait_for_timeout(1000) # Wait for 1 second
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == previous_height:
break
previous_height = new_height
# Scroll the page to load more data
await scroll_page()
# Close the page
await page.close()
# Yield the captured AJAX data
for ajax_data in self.captured_ajax_data:
yield {'ajax_data': ajax_data.decode('utf-8')} # Decode bytes to stringThis spider starts by loading the Nike webpage using Playwright, which allows us to interact with the page and capture dynamic content.
Within the parse method, we define a handle_route function that intercepts all network requests made by the page. If an AJAX request is detected (in this case, requests to api.nike.com), the response data is captured and stored in self.captured_ajax_data.
The script then scrolls the page to trigger more AJAX requests, ensuring all dynamic content is loaded. After scrolling is complete, the captured AJAX data is yielded as the output of the spider, decoded from bytes to a readable string format.
You can get the full AJAX data output in JSON by running the command scrapy crawl nike -o nike_data.json .
How to use proxies with Scrapy Playwright
Using proxies with scrapy-playwright is quite easy. Simply pass the dictionary playwright_context_kwargs with your proxy configuration.
from scrapy import Spider, Request
class EventsSpider(Spider):
name = 'proxy'
def start_requests(self):
yield Request(
url='https://httpbin.org/get',
meta={
"playwright": True,
"playwright_include_page": True,
"playwright_context_kwargs": {
"proxy": {
"server": "http://your-proxy-server:port",
"username": "your-username",
"password": "your-password",
}
},
},
callback=self.parse
)
async def parse(self, response):
passConclusion: Scrapy Playwright great for dynamic content
Overall, scrapy-playwright is a great addition to the Scrapy ecosystem, especially for websites that rely on JavaScript to load content.
While vanilla Scrapy works well for static pages, it can’t deal with dynamic content. scrapy-playwright solves this by incorporating Playwright's capabilities to simulate user interactions and capture fully rendered pages. This allows us handle complex tasks like capturing AJAX data, loading content from infinite scroll pages, and managing login forms.




