AI Programming Web automation and RPA What is AI web scraping? And do you really need it? Theo Vasilis May 2, 2025
Programming Scraping libraries and frameworks IMPIT: browser impersonation made simple Jindřich Bär Mar 20, 2025
Python Tutorial Programming How to scrape a website (ultimate guide for 2025) Antonello Zanini Mar 19, 2025
Tutorial Web automation and RPA Programming How to make an animated scrolling GIF of any web page David Barton Feb 18, 2025
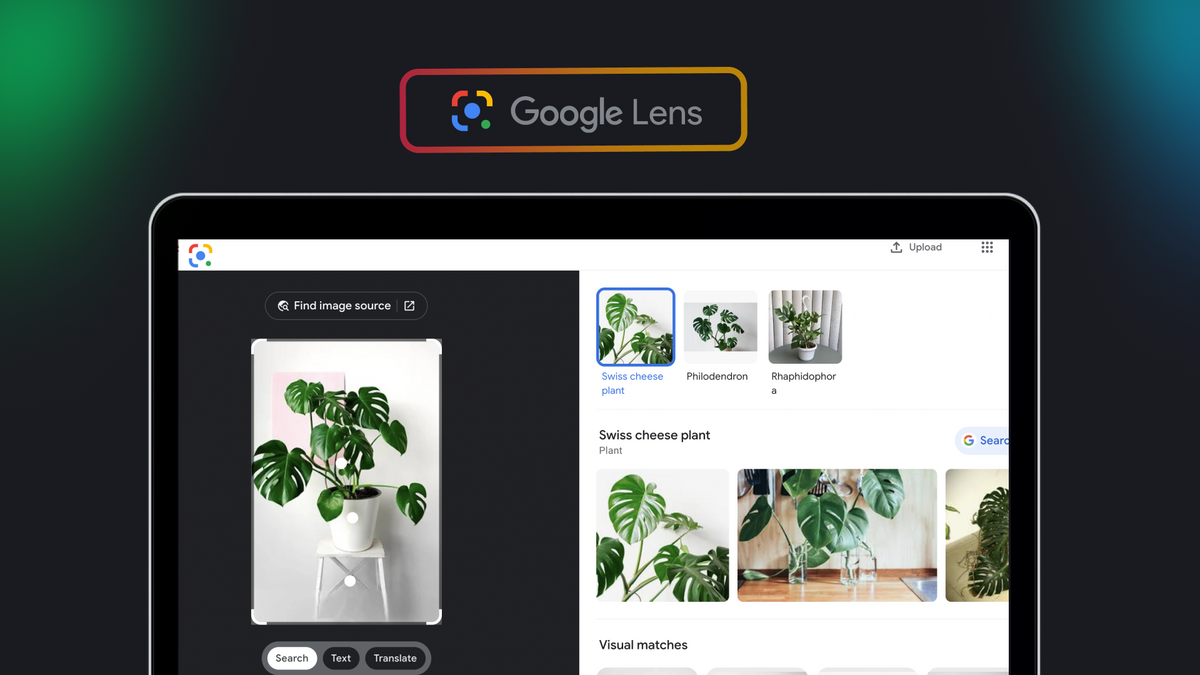
Google Tutorial Programming How to use Google Lens API to extract image data and find matching images Natasha Lekh Nov 15, 2024