


If you're familiar with server-side development frameworks like Express for Node.js, then you've probably already heard about middleware. In Express, middleware is used for intercepting and manipulating the request-response cycle, enriching the functionality of server-side applications.
Similarly, in Scrapy, middleware brings the versatility and customisability required for complex web scraping projects.
In essence, middleware offers you the ability to tailor and improve your spiders to fit different scraping scenarios, opening up opportunities for modifying requests, efficiently managing responses, and adding new functionalities to your spiders.
In the following sections, we'll distinguish between the two primary types of Scrapy middleware: spider middleware and downloader middleware. We'll explore the process of developing custom middleware and showcase the flexibility that it brings to Scrapy projects.

The role of middleware in Scrapy's architecture
Middleware in Scrapy is a set of hooks and mechanisms that allow you to inject custom functionality or modify the default behavior of Scrapy components.
Essentially, middleware acts as an intermediary layer in the Scrapy architecture, influencing both the requests sent to and the responses received from a website. To illustrate that, take a look at the diagram below, which details the data flow within the Scrapy architecture:
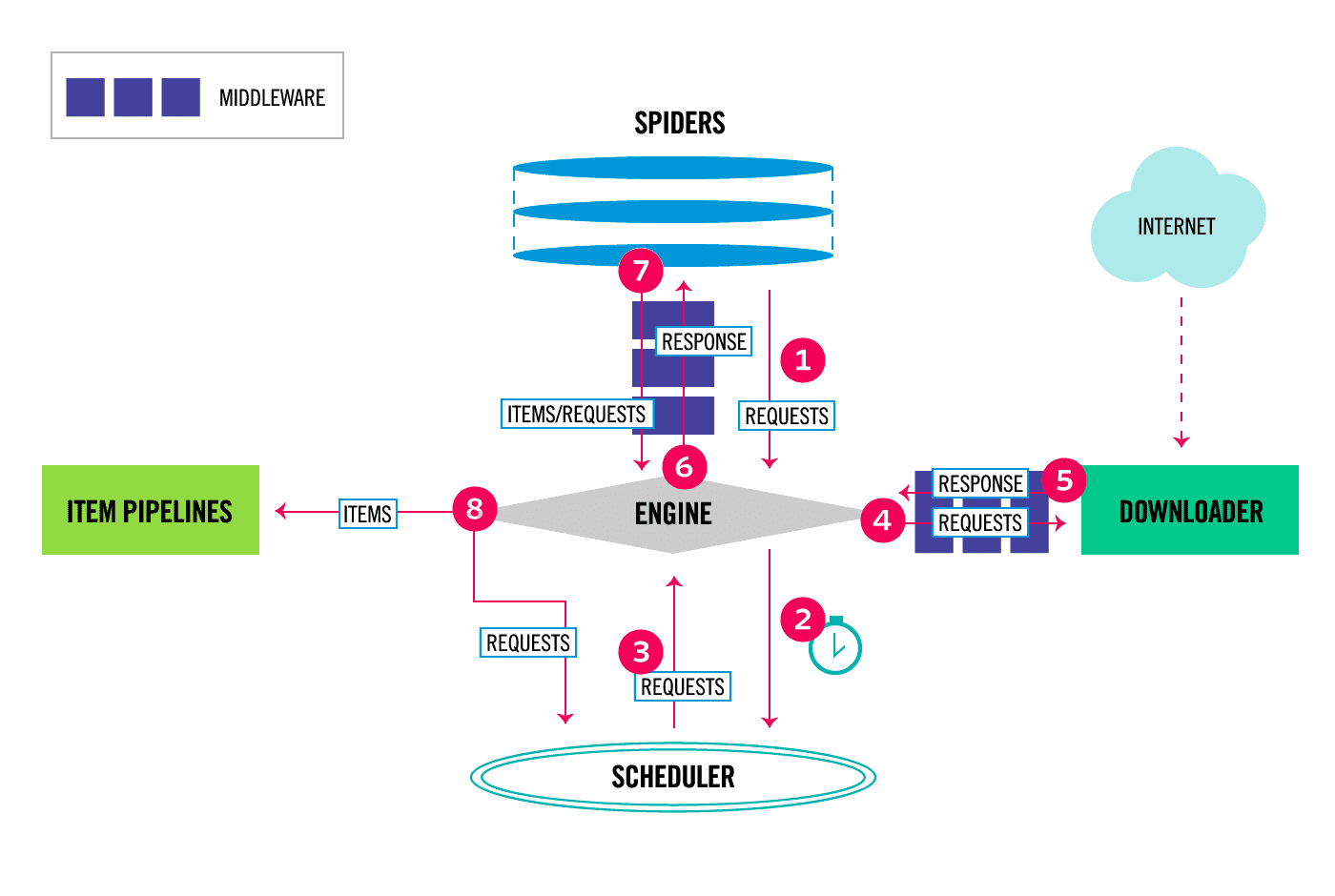
Note that middleware components in Scrapy are executed sequentially, following a defined order. This sequence is important as it can affect how requests and responses are processed.
Based on the diagram, we can see that middleware plays a role in the data flow both between the engine and the spiders and between the engine and the downloader. Each piece of middleware can modify, drop, or pass the requests or responses to the next component in the chain, offering a high degree of control over the data flow in a Scrapy project.
This brings us to the two distinct types of Scrapy middleware: spider middleware and downloader middleware.
Spider middleware vs. downloader middleware
1. Spider middleware
- Purpose: Spider middleware is used to process the responses received from web requests and the requests generated from spiders.
- Functionality: It allows for the manipulation of responses and requests before they reach the spider or after they are generated by the spider. For example, you could use spider middleware to filter out responses based on certain criteria or to add additional metadata to requests.
2. Downloader middleware
- Purpose: This type of middleware is involved in processing requests before they are sent to the server and responses after they are received from the server but before they are processed by the spider.
- Functionality: Downloader middleware is ideal for tasks like setting request headers, handling retries, managing cookies, or even handling redirects in a custom way.
Having established a basic understanding of middleware's role in the Scrapy architecture, we'll next see how to develop and implement custom spider and downloader middleware to enhance the capabilities of Scrapy spiders.
Setting up the environment
Before we get into the specifics of creating and using middleware in Scrapy, it's important to ensure that you have the necessary environment set up. In this section, we'll set up a basic Scrapy project, which will serve as our platform for demonstrating middleware usage.
Create and activate a virtual environment
Assuming that you have the latest version of Python already installed on your machine, go to the directory where you want your Scrapy project to be. Then, run the following command to create a virtual environment:
- On Windows:
python -m venv venv
- On macOS/Linux:
python3 -m venv venv
This command creates a directory named venv in your project directory. This directory will contain the Python executable files and a copy of the pip library.
Activate the virtual environment
To start using this environment, you need to activate it. The activation command differs based on your operating system:
- On Windows:
venv\\Scripts\\activate - On macOS/Linux:
source venv/bin/activate
After activation, your command line will usually show the name of your virtual environment; in this case, (venv), indicating that the virtual environment is active.
Creating a Scrapy project
Install Scrapy
pip install scrapy
Create a new project
To create a Scrapy project, use the command below and replace projectname with your desired project name, for example scrapymiddleware. This command creates a new directory with the basic structure of a Scrapy project.
scrapy startproject projectname
Creating a Spider
Inside the spiders directory, we can create a basic spider to test our setup. A spider in Scrapy is a class that defines how a certain site (or a group of sites) will be scraped.
For the purpose of this article, we'll create a simple spider to crawl all articles on the Apify blog homepage and return the article’s title.
scrapy genspider blog blog.apify.com
After the spider is created, feel free to replace the generated placeholder code with the code below:
import scrapy
class BlogSpider(scrapy.Spider):
name = "blog"
allowed_domains = ["blog.apify.com"]
start_urls = ["https://blog.apify.com"]
def parse(self, response):
# Iterate over each article on the homepage
for article in response.css('article'):
blog_url = article.css('h2 a::attr(href)').get()
if blog_url:
# For each blog URL crawled, call parse_blog to extract title and author
yield response.follow(blog_url, self.parse_blog)
article_number = 0
def parse_blog(self, response):
self.article_number += 1
# Extract the title and author from the blog page
yield {
'article': self.article_number,
'title': response.css('h1::text').get().strip(),
}
To run the spider and output the scraped data in JSON format, run the command below:
scrapy crawl blog -o output.json
Now that the setup is complete and our new spider is ready, we can begin utilizing middleware to augment its capabilities.
Creating custom spider middleware
The spider middleware in Scrapy can process the input (responses) to spiders and the output (requests and items) from spiders, offering a versatile way to manipulate data.
Defining a middleware Class
Start by creating a Python class within the middlewares.py file in your Scrapy project. You can define methods like process_spider_input, process_spider_output, and process_spider_exception to handle responses, results, and exceptions, respectively.
def process_spider_exception(self, response, exception, spider):
# Called when a spider or process_spider_input() method
# (from other spider middleware) raises an exception.
# Should return either None or an iterable of Request or item objects.
pass
Implementing middleware logic
Imagine you want to filter out responses that contain a specific keyword in the body of the response. This can be particularly useful if you're scraping a site and want to ignore pages that contain certain irrelevant or sensitive information.
We can implement this logic by defining a process_spider_input middleware that checks if the filter_keyword is present in the response.text (the body of the HTTP response). If the keyword is found, the response is logged and excluded from further processing by returning None. If the keyword is not found, the response is returned as is, allowing the spider to continue processing it.
from scrapy.exceptions import IgnoreRequest
def process_spider_input(self, response, spider):
filter_keyword = "Apify as a data cloud platform for AI" # Replace with the keyword you want to exclude
if filter_keyword in response.text:
spider.logger.info(f"Filtered response containing '{filter_keyword}': {response.url}")
# Correctly raise IgnoreRequest to stop processing this response
raise IgnoreRequest(f"Response contains the filtered keyword: {filter_keyword}")
else:
spider.logger.info(f"Response does not contain the filtered keyword: {filter_keyword}")Activating the middleware
To activate a newly defined middleware in Scrapy, it's necessary to update the SPIDER_MIDDLEWARES setting in the settings.py file of your project. The following code snippet, which you may find already included in settings.py, needs to be uncommented to enable your custom middleware:
SPIDER_MIDDLEWARES = {
"scrapymiddleware.middlewares.ScrapymiddlewareSpiderMiddleware": 543,
}
By uncommenting and appropriately modifying this section, you can activate your middleware and ensure it's applied in subsequent runs of your Scrapy spider. The priority (543 in this case) determines when this middleware is applied in relation to others.
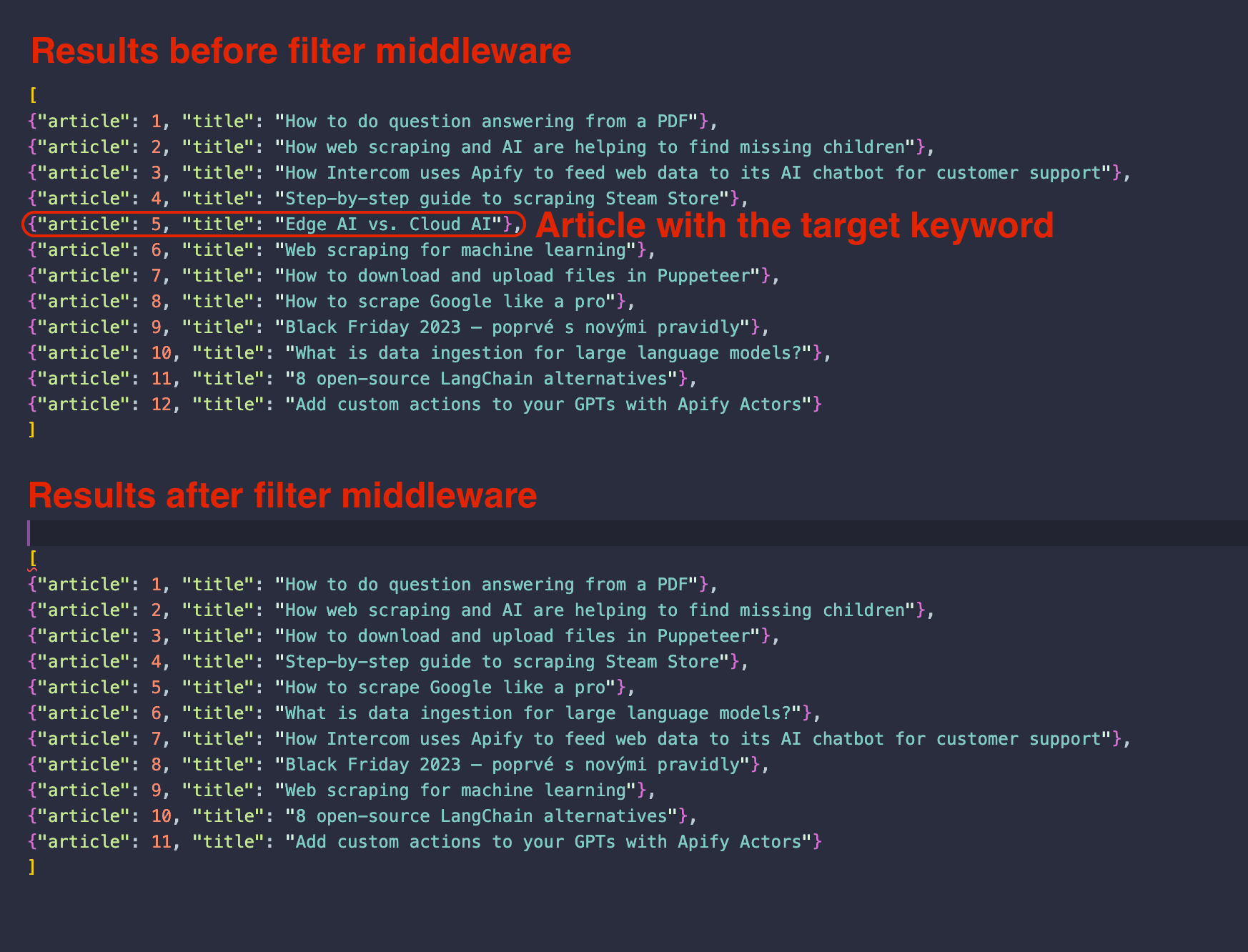
Running the spider with the newly implemented filter middleware will result in retrieving 11 articles, compared to the 12 articles obtained without the middleware. This confirms the effective operation of our custom filter middleware.
Downloader middleware: customizing the request-response cycle
Downloader middleware in Scrapy plays a central role in customizing the request-response cycle, offering the means to incorporate custom functionality or alterations in both outgoing requests and incoming responses from the web server.
To better understand what it means, here are a few situations where setting up a custom downloader middleware can help:
- Modifying outgoing requests: This includes setting custom headers, adding cookies, or changing the request method.
- Processing incoming responses: We can use it to handle HTTP status codes, modify response content, or even handle redirects in a specific manner.
- Handling request failures: This includes retrying failed requests or handling specific exceptions.
Creating a custom downloader middleware
Two of the most common ways to use downloader middleware are to modify request headers using the process_request method, and handling retries or response modifications using the process_response method.
To exemplify this, let’s create a custom downloader middleware for setting a User-Agent header on each request. Like with our spider middleware example we should create a Python class in the middlewares.py file.
def process_request(self, request, spider):
user_agent = "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36"
request.headers.setdefault('User-Agent', user_agent)
return None
In this example, a User-Agent string representing a specific version of Chrome on macOS is set as the default for requests. This is particularly useful for websites that might block or alter content for requests that appear to come from non-standard browsers or automated scraping tools.
Essentially, setting an appropriate User-Agent makes your requests appear more human-like. This is a fundamental technique in web scraping to minimize the likelihood of your bots being blocked.
Activating downloader middleware
We have now to uncomment the DOWNLOADER_MIDDLEWARES setting in our settings.py which should be right below SPIDER_MIDDLEWARES:
DOWNLOADER_MIDDLEWARES = {
'myproject.middlewares.CustomHeaderMiddleware': 543,
}
The order in which the middleware is applied is controlled by the assigned integer (543), similar to spider middleware.
And that’s it. Now, each request sent by your scraper will contain the appropriate User-Agent we set using our custom downloader middleware.
Learn more about web scraping with Scrapy
While middleware is a powerful feature of Scrapy that allows us to customize and enhance your spiders, they're not the only reason Scrapy is one of the most powerful and complete frameworks for web scraping in Python.
Check out our article on using Scrapy for web scraping to continue learning more about the many features of this popular Python framework.





