


In this guide, you’ll learn in detail how to parse XML files in Python. Here, we’ll focus on the ElementTree API, a built-in, simple, lightweight XML processor for parsing XML. Additionally, we’ll explore extracting and parsing data from XML files using Beautiful Soup and LXML.
Understanding XML
Let's first understand XML, its structure, and how an XML parser functions to process and read data from XML files.
What is XML?
Extensible Markup Language (XML) is a markup language similar to HTML, but it is primarily used to store, transport, and exchange data rather than solely for creating web pages. XML provides the flexibility to define custom tags to describe data in a specific manner.
Structure of XML
XML uses markup symbols to provide more information about any data. Other data processing applications use this information to process structured data more efficiently.
Markup symbols, called tags in XML, are crucial in defining data. For example, to represent data for a library of books, you can create tags such as <book>, <title>, <author>, or <genre>. Here's an XML content snippet for a book library:
bookstore_data.xml:
<?xml version="1.0" encoding="UTF-8" ?>
<library country="USA" language="English" owner="Apify">
<book format="hardcover" language="English" availability_in_store="true">
<title>Harry Potter and the Sorcerer's Stone</title>
<author>J. K. Rowling</author>
<genre>Fantasy</genre>
<publication_year>1997</publication_year>
<isbn>978-0439708180</isbn>
<price>19.99</price>
<payment>
<cod>no</cod>
<refund>yes</refund>
</payment>
</book>
<book format="paperback" language="English" availability_in_store="true">
<title>To Kill a Mockingbird</title>
<author>Harper Lee</author>
<genre>Classic</genre>
<publication_year>1960</publication_year>
<isbn>978-0061120084</isbn>
<price>14.99</price>
<payment>
<cod>yes</cod>
<refund>no</refund>
</payment>
</book>
<book format="ebook" language="English" availability_in_store="false">
<title>The Great Gatsby</title>
<author>F. Scott Fitzgerald</author>
<genre>Classic</genre>
<publication_year>1925</publication_year>
<isbn>978-0743273565</isbn>
<price>12.99</price>
<payment>
<cod>no</cod>
<refund>yes</refund>
</payment>
</book>
</library>
The XML data represents information about three books in a library. Here's a structural breakdown:
- Root element: The root element, <library>, is the topmost level element that contains all other elements.
- Child element: The <book> tag is a child element that represents details about a specific book. The <book> tag also have childs such as <title>, <author>, <genre>, <publication_year>, <ISBN>, <price>, and <payment_options>.
Here's a hierarchical tree view of the XML file to help you understand it clearly.
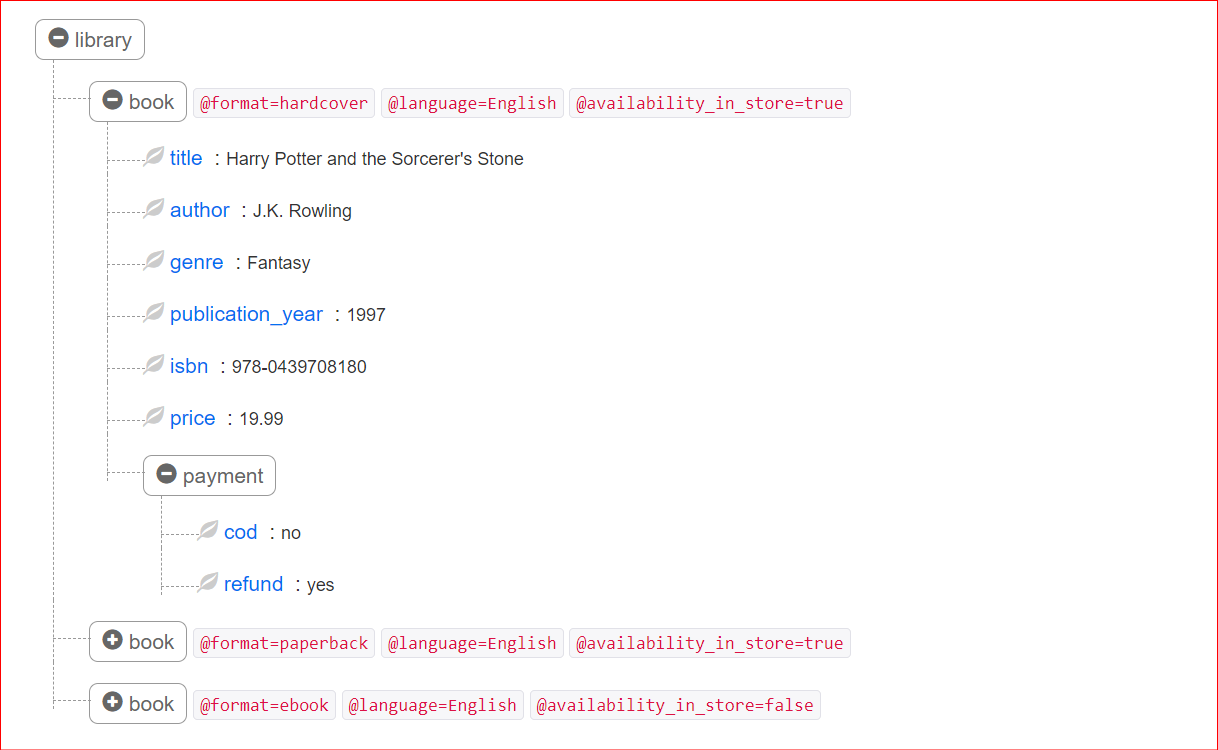
What is an XML Parser?
An Extensible Markup Language (XML) parser is a software program that processes XML documents to extract the data contained within. During XML parsing, the XML data is separated into individual components, and these components are analyzed and classified.
XML parsers also check the syntax and rules of an XML document against a specific XML schema to ensure its validity. If validation or syntax errors exist, XML parsers will not accept a file for processing. For example, the XML parser will generate errors if any of the following conditions occur:
- Attribute values lack quotation marks
- A closing tag or end tag is missing
- A schema condition has not been met
How to parse XML in Python with ElementTree
The ElementTree API is a widely used built-in lightweight, feature-rich module for parsing and manipulating XML documents. This module creates a tree-like structure to store data in a hierarchical format, which is the most natural representation of data.
There are two ways to parse XML data using the ElementTree module. The first way involves using the parse() function, and the second way involves using the fromstring() function. The parse() function is used for parsing XML data supplied as a file, while the fromstring() function is used to parse XML data supplied as a string within triple quotes.
Since we’ve created an XML file with some book data, we’ll use the parse() function to parse the XML data. However, we’ll also show you how to use the fromstring() function to parse XML data stored in a string format.
Note that the best practice is to store XML data in a file and then use the file path in your program to parse the data. This approach is more efficient and avoids potential memory issues when dealing with large XML datasets.
Root tag name
Let's begin by importing the required module and calling the parse() function. After that, we'll extract the root node using the getroot() method. In our case, the root element is library. Also, if you make a slight change and print the list(root), then all the child elements of the root tag will be printed. For example, here, we have three "book" elements (the child of the "library" root tag).
import xml.etree.ElementTree as ET
tree = ET.parse("bookstore_data.xml")
root = tree.getroot()
print(root) # <Element 'library' at 0x000001F71946E040>
print(root.tag) # library
print(list(root)) # [<Element 'book' at 0x00000296683DE0E0>, <Element 'book' at 0x00000296683DE450>, <Element 'book' at 0x00000296683DE7C0>]
With the fromstring() function, the root element is directly accessible, so you don’t need the getroot() method.
import xml.etree.ElementTree as ET
xml_data = """
<library country="USA" language="English" owner="Apify">
<book format="hardcover" language="English" availability_in_store="true">
<title>Harry Potter and the Sorcerer's Stone</title>
<author>J.K. Rowling</author>
<genre>Fantasy</genre>
<publication_year>1997</publication_year>
<isbn>978-0439708180</isbn>
<price>19.99</price>
<payment>
<cod>no</cod>
<refund>yes</refund>
</payment>
</book>
</library>
"""
root = ET.fromstring(xml_data)
print(root) # <Element 'library' at 0x000002AC5FB8DA90>
print(root.tag) # library
The root tag ‘library’ is extracted.
Root attributes
To retrieve attributes of the root tag, use the attrib method. Our XML file contains three attributes within the root tag. In the following code, you can extract all attributes and also a specific one.
import xml.etree.ElementTree as ET
tree = ET.parse("bookstore_data.xml")
root = tree.getroot()
# get all attributes
attributes = root.attrib
print(attributes) # {'country': 'USA', 'language': 'English', 'owner': 'Apify'}
# extract a particular attribute
owner = attributes.get("owner")
print(owner) # Apify
owner = attributes.get("country")
print(owner) # USA
owner = attributes.get("language")
print(owner) # English
Root child nodes
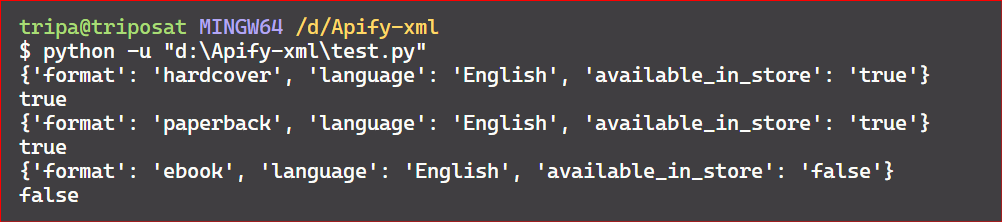
Let’s iterate over the child nodes of the root and retrieve their attributes. In this case, the findall() method is used to locate all matching elements with a 'book' tag. You can also extract the value of a specific attribute, as shown in the following code, where we extract the value of the 'available_in_store' tag.
import xml.etree.ElementTree as ET
tree = ET.parse("bookstore_data.xml")
root = tree.getroot()
# iterate over child nodes
for book in root.findall("book"):
# get all attributes of a node
attributes = book.attrib
print(attributes)
# get a particular attribute
avail = attributes.get("available_in_store")
print(avail)
Here’s the code output:
If you want to access all the first child tags of the root, you can use a simple for loop and iterate over it. Remember to run the loop on root[0] since root[0] represents the first child of the root node.
import xml.etree.ElementTree as ET
tree = ET.parse("bookstore_data.xml")
root = tree.getroot()
for t in root[0]:
print(t.tag)
Here’s the code output:

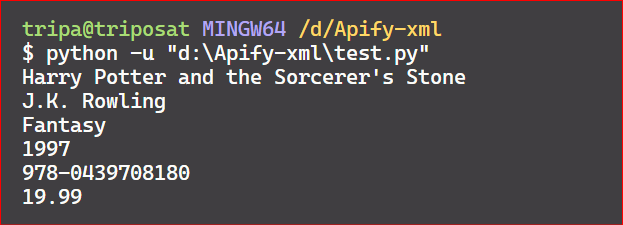
Now, if you make a slight change in the above code and print t.text instead of t.tags, you’ll obtain all the values of the first child tags.
import xml.etree.ElementTree as ET
tree = ET.parse("bookstore_data.xml")
root = tree.getroot()
for t in root[0]:
print(t.text)
Here’s the code output:
To access the elements of a specific node, use the findall() and find() methods. In the following code, we’re accessing the elements of the 'book' child node. In this case, we’re extracting all the text of the elements <title>, <author>, <genre>, and <isbn>. You can add more tags to extract more results.
import xml.etree.ElementTree as ET
tree = ET.parse("bookstore_data.xml")
root = tree.getroot()
# Iterate over all child nodes
for book in root.findall("book"):
title = book.find("title").text
author = book.find("author").text
genre = book.find("genre").text
isbn = book.find("isbn").text
print("Title: ", title, "| Author:", author, "| Genre:", genre, "| ISBN:", isbn)
Here’s the code output:

If you want to access all the elements of a node without knowing their tag names, you can use the findall() and find() methods. In the following code, we’re accessing all the elements of the 'book' tag.
import xml.etree.ElementTree as ET
tree = ET.parse("bookstore_data.xml")
root = tree.getroot()
for book in root.findall("book"):
for element in book:
ele_tag = element.tag
ele_val = book.find(ele_tag).text
print(ele_tag, " : ", ele_val)
Here’s the code output:
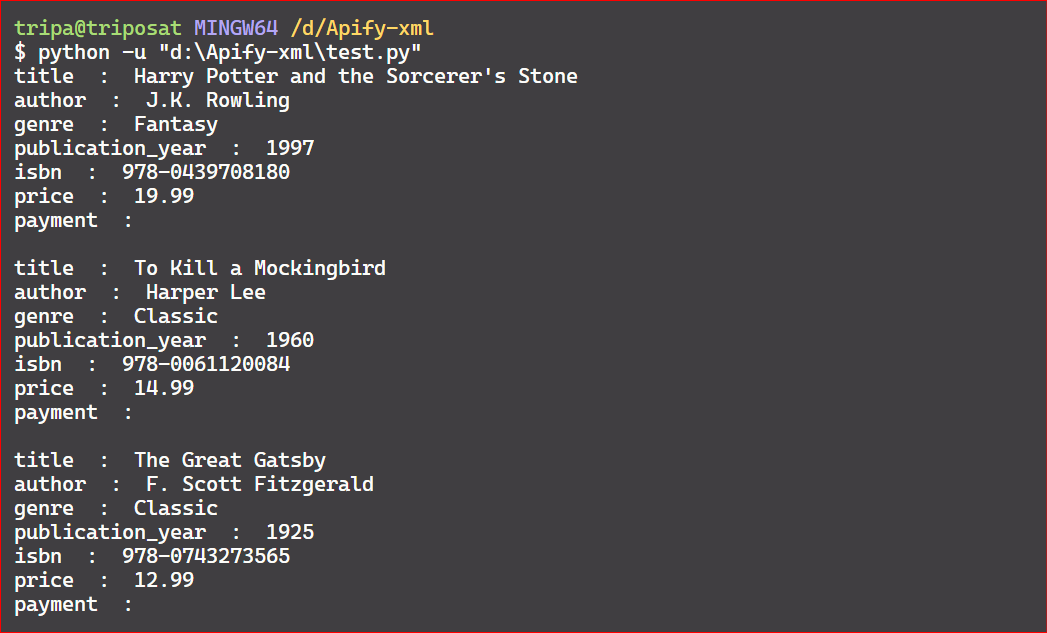
We’ve extracted all the elements of the 'book' tags. However, you may notice that the payment option is empty. This is because the payment element also has child elements.
<payment>
<cod>no</cod>
<refund>yes</refund>
</payment>
To handle the child elements of the payment tag, make a slight change. In the following code, we demonstrate how to extract the COD status. Similarly, you can extract the refund status.
import xml.etree.ElementTree as ET
tree = ET.parse("bookstore_data.xml")
root = tree.getroot()
for book in root.findall("book"):
for element in book:
ele_tag = element.tag
if ele_tag == "payment":
ele_val = book.find("payment/cod").text.strip("'")
else:
ele_val = book.find(ele_tag).text
print(ele_tag, ' : ', ele_val,)
Here’s the code output:
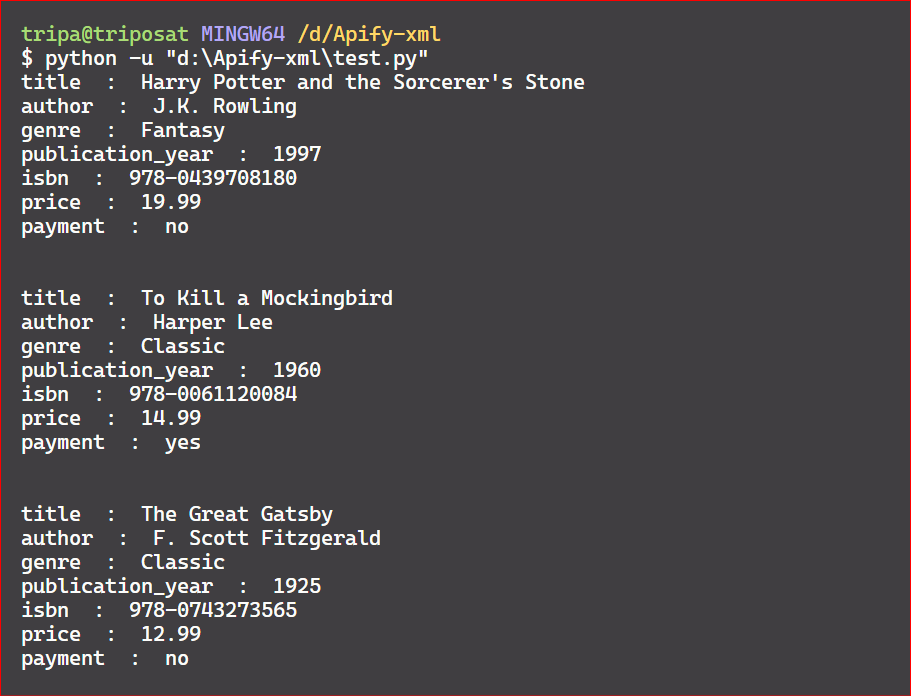
If you want to find any element of interest in the entire tree without using the find() or findall() methods, you can use the iter() function. In the following code, we show how to find 'author' in the entire tree with just a couple of lines of code.
The root.iter("author") returns an iterator that yields all elements with the specified tag name ("author" in this case).
import xml.etree.ElementTree as ET
tree = ET.parse("bookstore_data.xml")
root = tree.getroot()
for auth in root.iter("author"):
print(auth.text)
Here’s the code output:
Modify XML files
The elements of the XML file can be manipulated, allowing you to modify or delete elements, sub-elements, and attributes from your XML file.
The following code updates all prices, sets the COD status of the second book to 'no', and updates the refund status of the second book to 'eligible'. Additionally, it sets the attribute 'updated=yes' wherever changes have been made.
The .//price is an XPath expression used in the findall method to locate all elements named "price" in the XML document.
import csv
import xml.etree.ElementTree as ET
# Parse the XML file
tree = ET.parse("bookstore_data.xml")
root = tree.getroot()
for price_element in root.findall(".//price"):
current_price = float(price_element.text)
new_price = current_price + 2
price_element.text = "{:.2f}".format(new_price)
price_element.set("updated", "yes")
second_book_cod = root.find("./book[2]/payment/cod")
second_book_cod.text = "no"
second_book_cod.set("updated", "yes")
third_book_refund = root.find("./book[2]/payment/refund")
third_book_refund.text = "eligible"
third_book_refund.set("updated", "yes")
# Save the modified XML to a new file
tree.write("updated_bookstore_data.xml")
print("XML file has been successfully updated.")
Here’s the code output:
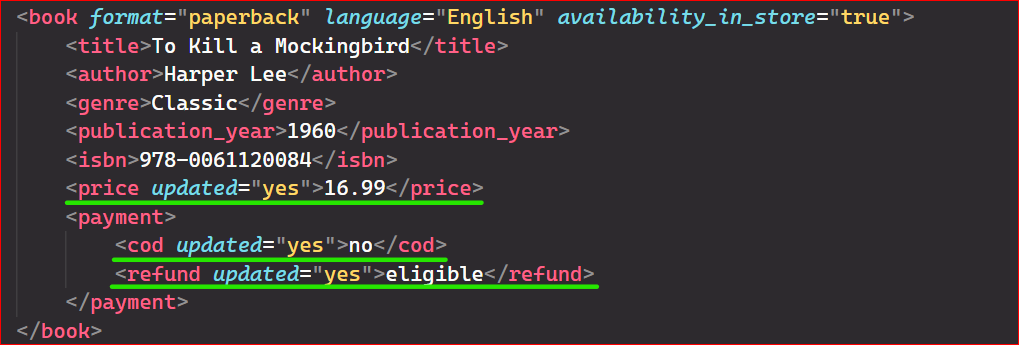
As shown in the above output, the price, COD, and refund have been updated with the 'updated' attribute set to 'yes’.
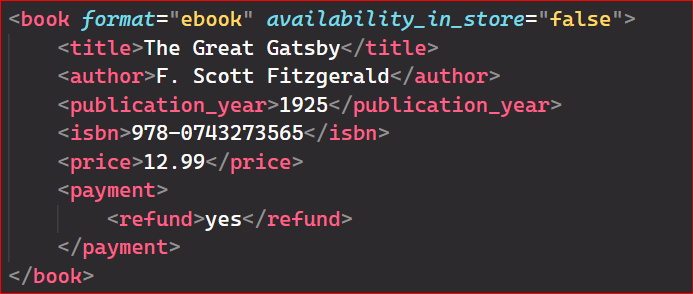
To remove unnecessary attributes or sub-elements, you can use the pop() and remove() methods. Use the pop() method to delete attributes and the remove() method to delete sub-elements. In the following code, we remove the language attribute of the third book using the pop() method and delete the <code> and <genre> elements of the third book using the remove() method:
import xml.etree.ElementTree as ET
tree = ET.parse("bookstore_data.xml")
root = tree.getroot()
third_book = root.find("./book[3]")
third_book.attrib.pop("language", None)
third_book.find("payment").remove(third_book.find("payment/cod"))
third_book.remove(third_book.find("genre"))
tree.write("updated_bookstore_data.xml")
print("XML file has been successfully updated.")
Here’s the code output:
Now, if you want to delete the entire book element, including all of its sub-elements and attributes, use the remove() method. In the following code, the first book element will be completely deleted.
import xml.etree.ElementTree as ET
tree = ET.parse("bookstore_data.xml")
root = tree.getroot()
first_book = root.find("./book")
root.remove(first_book)
tree.write("updated_bookstore_data.xml")
print("XML file has been successfully updated.")
Save data to CSV
After performing all the necessary operations on the XML data, it's time to save the changes to a CSV file. A CSV file is a plain text file that uses commas to separate values. It stores tabular data in plain text that you can then open in Excel or Google Sheets.
The script first imports the csv module for reading and writing CSV files. It then uses csv.writer to create a new CSV file named "output.csv" and opens it in write mode. After opening the file, the script uses the writerow method to write the header row containing column names: "Title", "Author", "Genre", "Publication Year", "ISBN", "Price", "COD", and "Refund".
The script iterates through each <book> element in the XML file and extracts data using the find() method. For each book, this extracted data is then written to the CSV file using the writerow method.
import csv
import xml.etree.ElementTree as ET
# Parse the XML file
tree = ET.parse("bookstore_data.xml")
root = tree.getroot()
# Create a CSV file and write a header
csv_file = open("output.csv", "w", newline="")
csv_writer = csv.writer(csv_file)
csv_writer.writerow(
["Title", "Author", "Genre", "Publication Year", "ISBN", "Price", "COD", "Refund"]
)
# Iterate through each book element
for book in root.findall("book"):
title = book.find("title").text
author = book.find("author").text
genre = book.find("genre").text
publication_year = book.find("publication_year").text
isbn = book.find("isbn").text
price = book.find("price").text
cod = book.find("payment/cod").text
refund = book.find("payment/refund").text
# Write data to CSV file
csv_writer.writerow(
[title, author, genre, publication_year, isbn, price, cod, refund]
)
# Close the CSV file
csv_file.close()
print("Data has been successfully written to output.csv.")
Here’s the CSV output:

Parsing RSS feed
Websites typically use RSS feeds to publish frequently updated content, including blog posts, news headlines, episodes of audio or video series, and podcasts. An RSS feed is an XML file that contains a summary of updates from a website.
The New York Times RSS feed provides a concise summary of daily news updates, including links to news releases, article images, and descriptions of news items. NYT RSS feeds offer a convenient way to access news content without the need to scrape websites. Many websites use RSS feeds to keep users and applications informed of their latest content, eliminating the need for scraping.
Here's a snapshot of The New York Times RSS feed. You can access various RSS feeds from The New York Times by following this link.
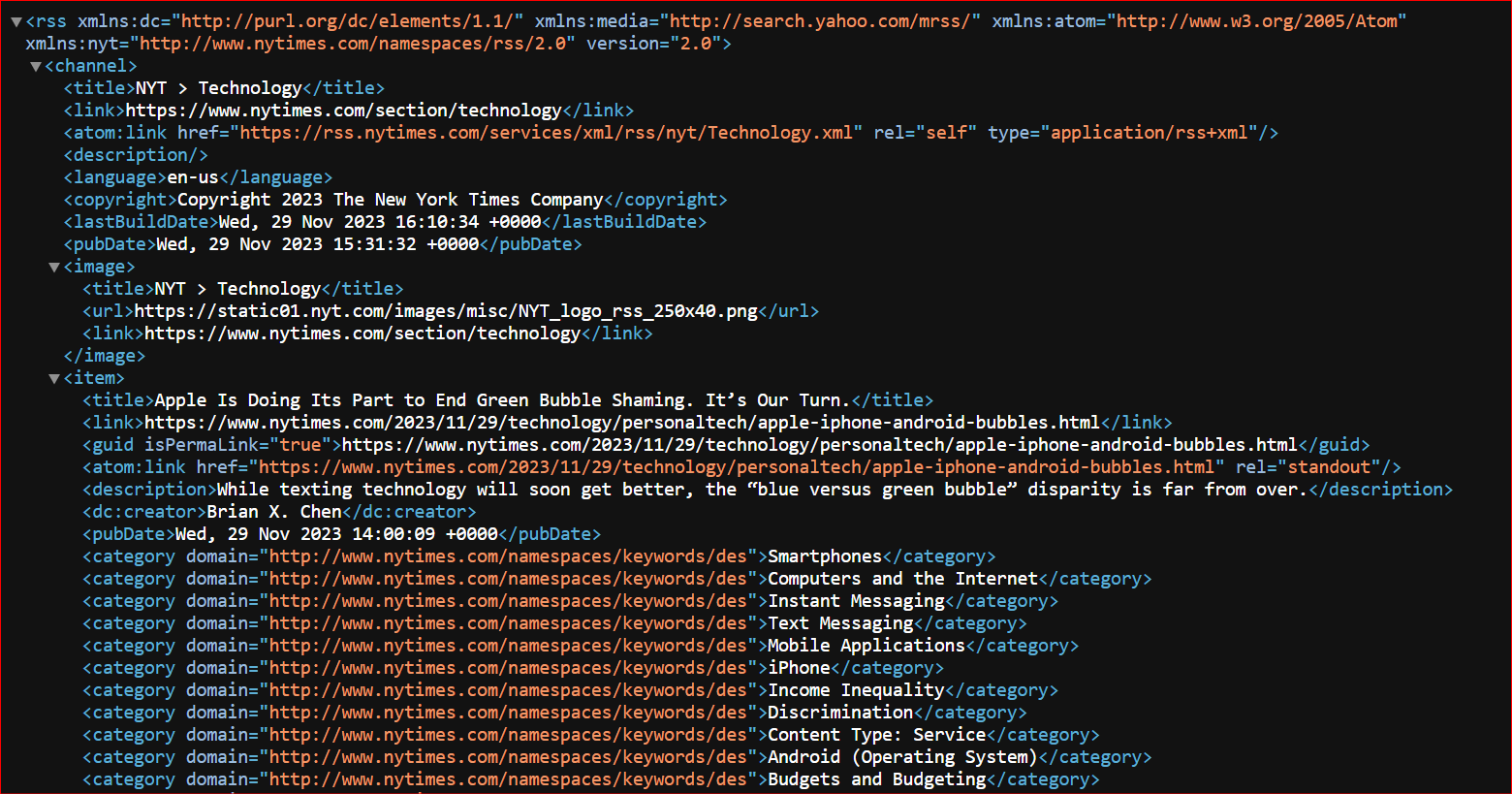
In this scenario, we’ll use the Technology RSS feed (or XML file). Let's first look at the process of parsing the live RSS feed.
- Fetch the RSS feed: Begin by loading the RSS file from the specified URL and saving it as an XML file.
- Extract relevant tags: Identify and extract the crucial tags within the
<item>node. - Parse and save data: Parse the data from the identified tags and store the processed information in a CSV file.
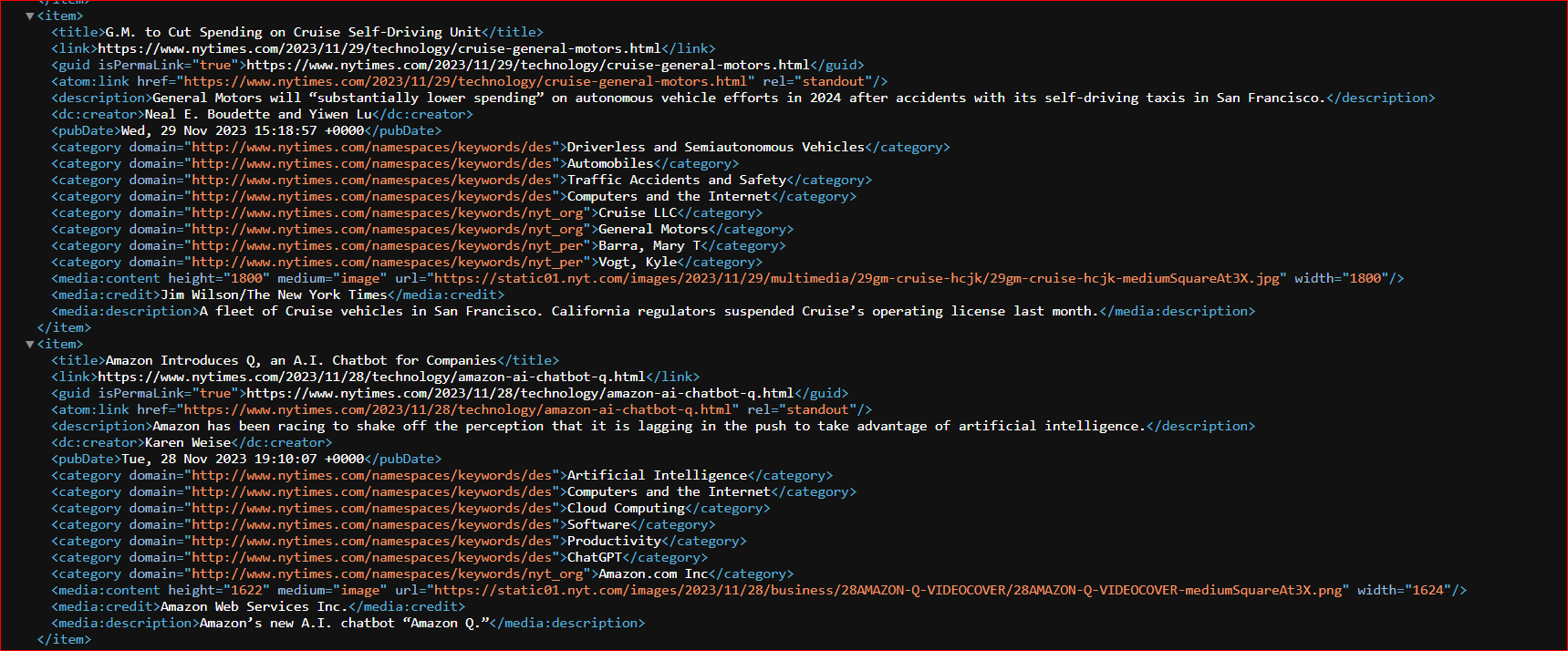
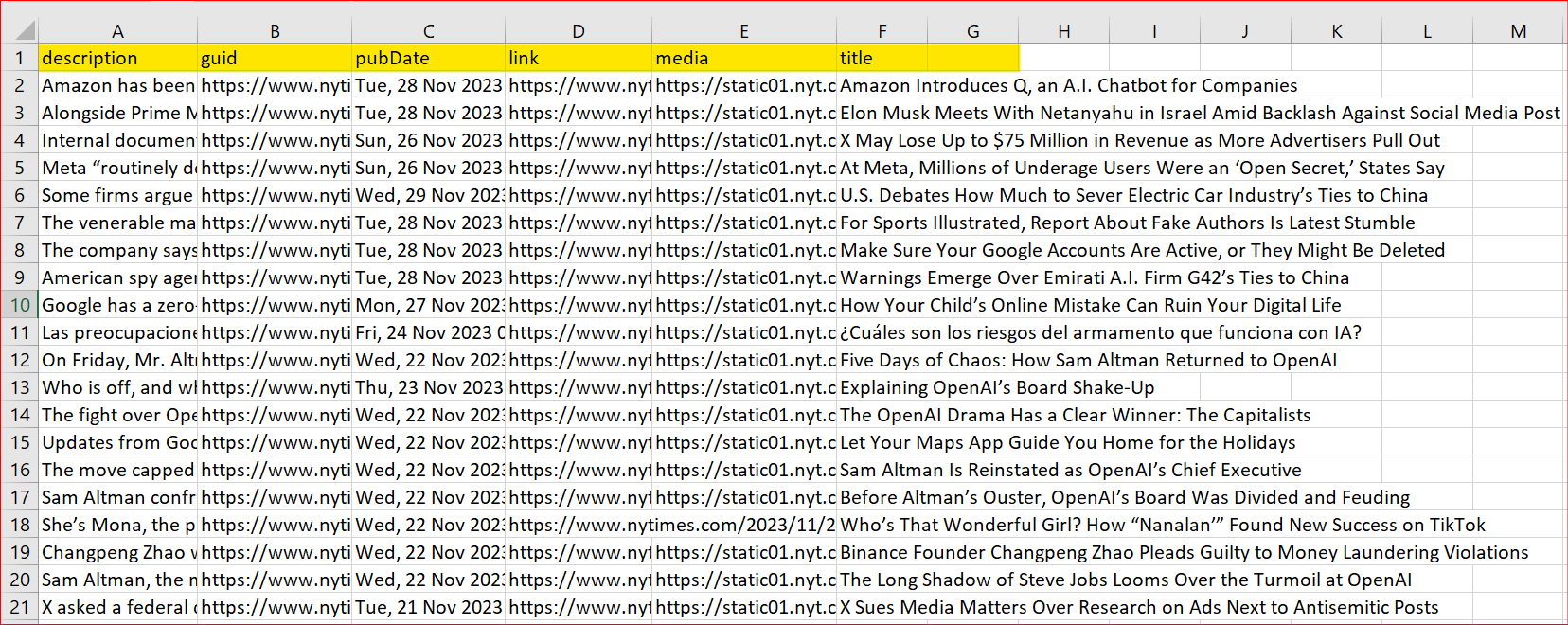
The <item> node contains the primary information, including title, GUID (Globally Unique Identifier), description, publication date, and media link. We'll process and extract this valuable data and store it in the XML file for further utilization. Refer to the following images, showing the RSS feed and how the data is parsed and saved in the CSV file. After parsing XML data, it’s often necessary to store the structured information in a database for further querying or analysis. For relational databases like MySQL, using MySQL tools can simplify data import and management.
RSS feed:
Parsed RSS feed:
Let's look more closely at the code behind parsing the RSS feed.
The code is straightforward and closely resembles the previous examples. First, we use the requests module to extract the XML content of the New York Times RSS feed. Subsequently, we store this XML data in a file. Next, we extract all the relevant tags. Finally, we run a for loop to extract data from the ./item node.
Note that we’ll have to handle namespace tags separately, as they get expanded to their original values when parsed. Here, we’ve got a tag with <media:content>, don't we? But this is not the tag. As mentioned earlier, it gets expanded to its original value when parsed, and the original looks like this: {<http://search.yahoo.com/mrss/>}content.

To handle the above namespace, we’ll begin by adding a tag with any name to our collection of tags. For example, in this case, we could add a 'media' tag. Once this tag enters the if loop, we’ll proceed with the following steps:
if tag == "media":
element = item.find("{<http://search.yahoo.com/mrss/>}content")
value = element.attrib["url"] if element is not None else ""
The child.attrib works like a dictionary containing all attributes related to an element. In this context, we’re specifically interested in the url attribute of the media:content namespace tag. Therefore, we’ll first extract the URL attribute using the attrib method.
Here’s the complete code:
import csv
import requests
import xml.etree.ElementTree as ET
def load_rss():
# URL of RSS feed
url = "https://rss.nytimes.com/services/xml/rss/nyt/Technology.xml"
# Creating HTTP response object from the given URL
resp = requests.get(url)
# Saving the XML file
with open("techfeed.xml", "wb") as f:
f.write(resp.content)
def extract_tags(element):
tags = set()
for child in element:
if "/" not in child.tag:
tags.add(child.tag)
tags.remove("category")
tags.add("media")
return tags
def extract_data(item, tags):
data = []
for tag in tags:
if tag == "media":
element = item.find("{http://search.yahoo.com/mrss/}content")
value = element.attrib["url"] if element is not None else ""
else:
element = item.find(tag)
value = element.text if element is not None else ""
data.append(value)
return data
def extract_and_save_data(xml_file_path, csv_file_path):
# Load the XML file
tree = ET.parse(xml_file_path)
root = tree.getroot()
# Extract all unique tags within 'item' elements from the XML file
item_tags = extract_tags(root.find(".//item"))
# Create a CSV file for storing the extracted data
with open(csv_file_path, "w", newline="") as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(item_tags)
# Extract data from each 'item' in the XML file
for item in root.findall(".//item"):
data = extract_data(item, item_tags)
# Write the extracted data to the CSV file
csvwriter.writerow(data)
print(f"Data extracted and saved to {csv_file_path}")
def main():
load_rss()
xml_file_path = "techfeed.xml"
csv_file_path = "output.csv"
extract_and_save_data(xml_file_path, csv_file_path)
if __name__ == "__main__":
main()
Great, you've parsed the RSS feed and stored the data in a CSV file. Now, this data can be leveraged to gain valuable insights.
How to parse XML in Python with Beautiful Soup
You have learned and implemented parsing XML with the built-in library ElementTree. Now, take a look at parsing XML with third-party libraries Beautiful Soup and LXML. Beautiful Soup is one of the most widely used libraries for web scraping and parsing.
LXML is the most feature-rich and easy-to-use library for processing XML and HTML in the Python language. lxml is faster than html.parser and html5lib due to its binding to C libraries.
If you need a powerful parser with many features, lxml is an excellent choice, especially for large datasets or complex tasks. If you're working with simple HTML documents and prefer a parser that is part of the standard library, html.parser is sufficient. However, it's less powerful and struggles with poorly formatted HTML.
If you specifically need to parse HTML5 documents, html5lib is a good option as it handles messy HTML with accuracy.
To begin using these libraries, first install them using the following command:
pip install lxml beautifulsoup4
We’ll be using the bookstore_data.xml file that we created in the above sections. Now let's import the Beautiful Soup library and read the content of the XML file, storing it in a variable called soup so we can begin parsing.
from bs4 import BeautifulSoup
with open('bookstore_data.xml', 'r') as f:
xml_data = f.read()
soup = BeautifulSoup(xml_data, features = 'xml')
lxml. When importing BeautifulSoup, LXML is automatically integrated; you don’t need to import it separately. However, it isn't installed as part of BeautifulSoup, so we have to install it.Also, you might be thinking, why didn’t we include the features='lxml'? Because if you run the code with features='lxml', the compiler will throw an error, which indicates that you should install lxml and use features='xml' to parse the XML document.

Root node
The soup variable has the parsed contents of our XML file. We can use this variable and the methods attached to it to retrieve the XML information with Python code. Let’s start by finding the name of the root node of the XML file.
from bs4 import BeautifulSoup
with open("bookstore_data.xml", "r") as f:
xml_data = f.read()
soup = BeautifulSoup(xml_data, features="xml")
root = soup.find()
print(root.name) # library
Root attributes
To retrieve attributes of the root tag, use the attrs method. Our XML file contains three attributes within the root tag. In the following code, you can extract all attributes and also a specific one.
from bs4 import BeautifulSoup
with open("bookstore_data.xml", "r") as f:
xml_data = f.read()
soup = BeautifulSoup(xml_data, features="xml")
root = soup.find()
root_attributes = root.attrs
print(root_attributes) # {'country': 'USA', 'language': 'English', 'owner': 'Apify'}
# extract a particular attribute
owner = root_attributes.get("owner")
print(owner) # Apify
owner = root_attributes.get("country")
print(owner) # USA
owner = root_attributes.get("language")
print(owner) # English
Root child nodes
Let’s iterate over the child nodes of the root and retrieve their attributes. In this case, the find_all() method is used to locate all matching elements with a 'book' tag. You can also extract the value of a specific attribute, as shown in the following code, where we extract the value of the 'format' tag.
from bs4 import BeautifulSoup
with open("bookstore_data.xml", "r") as f:
xml_data = f.read()
soup = BeautifulSoup(xml_data, features="xml")
root = soup.find()
book = root.find_all("book")
for elements in book:
attributes = elements.attrs
print(attributes)
formt = attributes.get("format")
print(formt)
Here’s the code output:
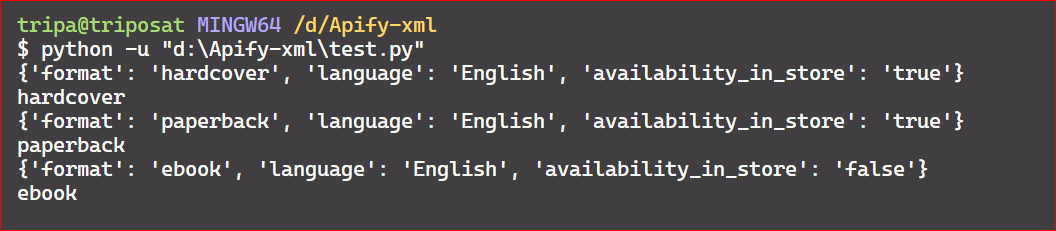
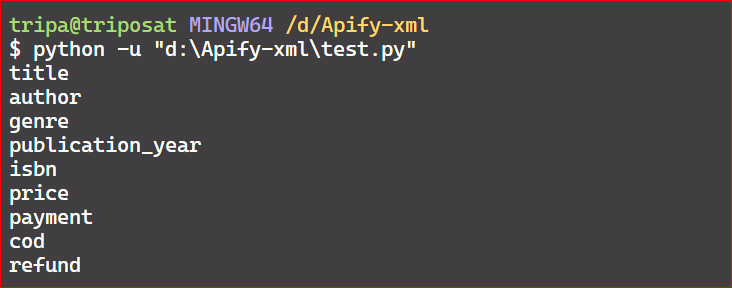
If you want to access all the first child tags of the root, you can use a simple for loop and iterate over it.
from bs4 import BeautifulSoup
with open("bookstore_data.xml", "r") as f:
xml_data = f.read()
soup = BeautifulSoup(xml_data, features="xml")
root = soup.find()
first_child = root.find("book")
for tag in first_child.find_all():
print(tag.name)
Here’s the code output:
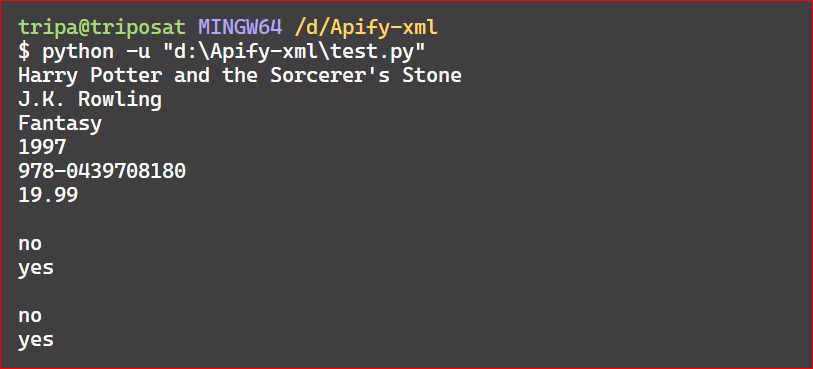
Now, if you make a slight change in the above code and print tag.text instead of tag.name, you’ll obtain all the values of the first child tags.
from bs4 import BeautifulSoup
with open("bookstore_data.xml", "r") as f:
xml_data = f.read()
soup = BeautifulSoup(xml_data, features="xml")
root = soup.find()
first_child = root.find("book")
for tag in first_child.find_all():
print(tag.text)
Here’s the code output:
To access the elements of a specific node, use the find_all() and find() methods. In the following code, we’re accessing the elements of the 'book' child node. In this case, we’re extracting all the text of the elements <title>, <author>, <genre>, and <isbn>. You can add more tags to extract more results.
from bs4 import BeautifulSoup
with open("bookstore_data.xml", "r") as f:
xml_data = f.read()
soup = BeautifulSoup(xml_data, features="xml")
root = soup.find_all("book")
for book in root:
title = book.find("title").text
author = book.find("author").text
genre = book.find("genre").text
isbn = book.find("isbn").text
print("Title: ", title, "| Author:", author, "| Genre:", genre, "| ISBN:", isbn)
Here’s the code output:

Parsing RSS feed
Here, we’ll once again parse the New York Times RSS feed. Previously, we parsed it using ElementTree, but now we’re using Beautiful Soup and LXML. Everything is similar to the previous example.
One important thing to note is that here we’re using item.find("media:content") to extract the media URL, and it’s working. However, in the previous ElementTree example, you had to pass the expanded tag like this: item.find("{<http://search.yahoo.com/mrss/>}content").
In Beautiful Soup, the actual tag is easily understood, but in ElementTree, the tag gets expanded when parsed, so you have to pass the expanded tag.
Here’s the complete code:
import csv
import requests
from bs4 import BeautifulSoup
def load_rss():
# URL of RSS feed
url = "https://rss.nytimes.com/services/xml/rss/nyt/Technology.xml"
# Creating HTTP response object from the given URL
resp = requests.get(url)
# Saving the XML file
with open("techfeed.xml", "wb") as f:
f.write(resp.content)
def extract_data(item, tags):
data = []
for tag in tags:
if tag == "media":
element = item.find("media:content")
value = element["url"] if element is not None else ""
else:
element = item.find(tag)
value = element.text if element is not None else ""
data.append(value)
return data
def extract_and_save_data(xml_file_path, csv_file_path):
# Load the XML file
with open(xml_file_path, "r", encoding="utf-8") as f:
soup = BeautifulSoup(f, "xml")
# Extract all unique tags within 'item' elements from the XML file
item_tags = ["pubDate", "description", "media", "title", "guid"]
# Create a CSV file for storing the extracted data
with open(csv_file_path, "w", newline="", encoding="utf-8") as csvfile:
csvwriter = csv.writer(csvfile)
csvwriter.writerow(item_tags)
# Extract data from each 'item' in the XML file
for item in soup.find_all("item"):
data = extract_data(item, item_tags)
# Write the extracted data to the CSV file
csvwriter.writerow(data)
print(f"Data extracted and saved to {csv_file_path}")
def main():
load_rss()
xml_file_path = "techfeed.xml"
csv_file_path = "output.csv"
extract_and_save_data(xml_file_path, csv_file_path)
if __name__ == "__main__":
main()
Quick recap on XML parsing with Python
In this guide, we've discussed XML parsing using Python in detail. We explored XML parsing using two methods: ElementTree APIs and Beautiful Soup. We took a look at XML structure, how to modify XML files, and save the data to a CSV file. Finally, we discussed parsing RSS feeds, which is a great way to summarize all the learning and apply it in practical scenarios.
What to learn next?
Learn about parsing data with Beautiful Soup and Requests for web scraping projects. This comprehensive tutorial shows you how to extract data at scale for machine learning, data analysis, research, and more using the Beautiful Soup Python library.
Or you might like to read about how to parse HTML in Python with PyQuery or Beautiful Soup
If you're interested in alternatives to Beautiful Soup, read Beautiful Soup vs. Scrapy for web scraping, or if you want to explore other Python libraries, you can read a more comprehensive guide to Python for web scraping.





