


What is Python caching?
Caching in Python is an optimization technique that stores frequently accessed data in a temporary location called a cache for faster retrieval. This significantly improves application performance and reduces the load on primary data sources.
This tutorial aims to give you a solid understanding of Python caching for storing web data. We'll show you how to do caching with:
- Dictionaries
- Decorators, and
- External caching services
Implementing Python cache
Imagine you're building a newsreader app that gathers news from various sources. When you launch the app, it downloads the news content from the server and displays it.
Now, consider what happens if you navigate between a couple of articles. The app will fetch the content from the server again each time unless you cache it. This constant retrieval puts unnecessary pressure on the server hosting the news.
A smarter approach is to store the content locally after downloading each article. Then, the next time you open the same article, the app can retrieve it from the local copy instead of contacting the server again.
There are several other examples where users must make multiple identical requests to the server. However, by effectively using Python caching, they can optimize application performance and memory usage.
Python caching using a dictionary
You can create a cache using a Python dictionary because reading data from a dictionary is fast (O(1) time).
In the newsreader example, you can check whether the content is already in your cache instead of fetching data directly from the server every time. If it is, you can retrieve it from the cache instead of returning it to the server. You can use the article's URL as the key and its content as the value in the cache.
Here's an example of how this caching technique might be implemented. We've defined a global dictionary to serve as the cache, along with two functions:
- get_content_from_server: This function fetches data from the server only if it's not already in the cache.
- get_content: This function first checks for the data in the cache. If it's found, the cached data is retrieved and returned. If not, the function calls
get_content_from_serverto fetch the data from the server. The fetched data is then stored in the cache for future use and returned.
import requests
import time
# A simple cache dictionary to store fetched content for reuse
cache = {}
# Function to fetch content from the server using the provided URL
def get_content_from_server(url):
print("Fetching content from server...")
response = requests.get(url)
return response.text
# Function to get content, checking the cache first before fetching from the server
def get_content(url):
print("Getting content...")
if url not in cache:
# If not in the cache, fetch content from the server and store it in the cache
cache[url] = get_content_from_server(url)
return cache[url]
# Main block of code
if __name__ == "__main__":
# First Pass
print("1st Pass:")
start = time.time()
get_content("<https://books.toscrape.com/>")
print("Total time: ", time.time() - start)
# Second Pass
print("\\\\n2nd Pass:")
start = time.time()
get_content("<https://books.toscrape.com/>")
print("Total time: ", time.time() - start)
And here’s the output:
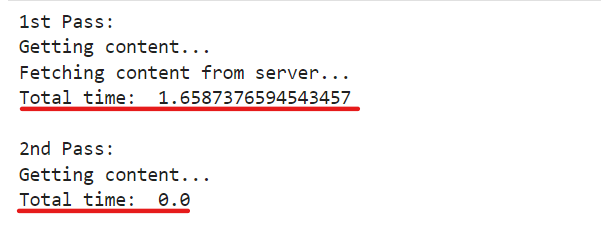
Notice that "Getting content..." is printed twice, while "Fetching content from server..." is printed only once.
You'll also observe a significant difference in time.
This occurs because, after initially accessing the article, its URL and content are stored in the cache dictionary, which naturally takes time.
The second time, since the item is already in the cache, the code doesn't need to fetch it from the server again, resulting in a much faster retrieval.
Python caching using a manual decorator
In Python, a decorator is a function that takes another function as an argument and returns a modified function. This allows you to alter the behavior of the original function without directly changing its source code.
One common use case for decorators is implementing caching in recursive functions. Recursive functions often call themselves with the same input values, leading to redundant calculations.
Let's begin by creating a function that takes a URL as input, sends a request to that URL, and subsequently returns the response text.
import requests
def fetch_html_data(url):
response = requests.get(url)
return response.text
Let's memoize this function using Python decorator.
def memoize(func):
cache = {}
def inner_cached(*args):
if args in cache:
return cache[args]
else:
result = func(*args)
cache[args] = result
return result
return inner_cached
@memoize
def fetch_html_data_cached(url):
response = requests.get(url)
return response.text
We define a memoize decorator that creates a cache dictionary to store the results of previous function calls. By adding @memoize above the fetch_html_data_cached function, we ensure that it makes only a single network request for each distinct URL and then stores the response in the cache for subsequent requests.
Here's how the inner_cached function, which is part of the memoize decorator, works:
- It first determines whether the current input arguments have already been cached.
- If a cached result exists for the given arguments, it is immediately returned, avoiding redundant network calls.
- If no cached result is found, the code calls the original
fetch_html_data_cachedfunction to fetch the data from the network. - The retrieved response is then stored in the cache before being returned.
import time
import requests
# Function to retrieve HTML content from a given URL
def fetch_html_data(url):
# Send a GET request to the specified URL and return the response text
response = requests.get(url)
return response.text
# Memoization decorator to cache function results
def memoize(func):
cache = {}
# Inner function to store and retrieve data from the cache
def inner_cached(*args):
if args in cache:
return cache[args]
else:
result = func(*args)
cache[args] = result
return result
return inner_cached
# Memoized function to retrieve HTML content with caching
@memoize
def fetch_html_data_cached(url):
# Send a GET request to the specified URL and return the response text
response = requests.get(url)
return response.text
# Make 10 requests using the normal function
start_time = time.time()
for _ in range(10):
fetch_html_data("<https://books.toscrape.com/>")
print("Time taken (normal function):", time.time() - start_time)
# Make 10 requests using the memoized function
start_time = time.time()
for _ in range(10):
fetch_html_data_cached("<https://books.toscrape.com>")
print("Time taken (memoized function):", time.time() - start_time)
Here’s the output:

We're making 10 requests to both functions, and the time difference increases significantly. What happens if we make hundreds of requests? That would create a huge time difference. This is how Python caching saves us.
➡️ Choose strategies that align with your application's data access patterns. Give priority to frequently accessed, static data.
➡️ Use efficient data structures like hash tables for fast access and insertion. Avoid O(n) operations that slow down as data size increases.
➡️ In addition, ensure that cached data is invalidated when the source changes so that data integrity is maintained.
Python caching using third-party library cachetools
Cachetools is a Python module that provides various memoizing collections and decorators, including variants of the Python Standard Library's @lru_cache function decorator, such as LFUCache, TTLCache, and RRCache.
To use the cachetools module, first install it using pip:
$ pip install cachetools
Cachetools provides five main functions:
- cached
- LRUCache
- TTLCache
- LFUCache
- RRCache
In Python, the cached function serves as a decorator. It accepts a cache object as an argument, and this object manages the storage and retrieval of cached data.
from cachetools import cached, LRUCache
import time
import requests
# API endpoint for fetching TODOs
endpoint = "<https://jsonplaceholder.typicode.com/todos/>"
@cached(cache={}))
def fetch_data(id):
start_time = time.time()
# Requesting different IDs
response = requests.get(endpoint + f"{id}")
print("\\\\nFetching data, time taken: ", time.time() - start_time)
# Checking if the response status code is 200 (OK) before extracting the title
return response.json().get("title") if response.status_code == 200 else None
# Example calls to fetch_data with different IDs
print(fetch_data(1)) # Fetching and caching data for ID 1
print(fetch_data(2)) # Fetching and caching data for ID 2
print(fetch_data(3)) # Fetching and caching data for ID 3
# Repeating some calls to demonstrate caching behavior
print(fetch_data(1)) # Retrieving cached data for ID 1
print(fetch_data(2)) # Retrieving cached data for ID 2
print(fetch_data(3)) # Retrieving cached data for ID 3
Here, the cache={} argument initializes the cache as an empty dictionary to store subsequent results.
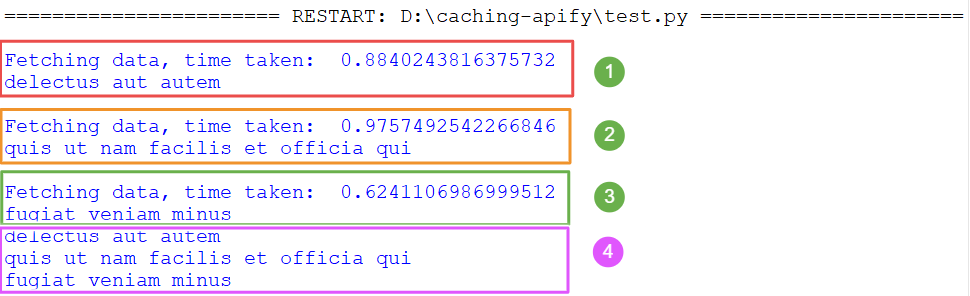
Have you observed something in the above image? You're right—in point 4, all the data is fetched from the cache. For IDs 1, 2, and 3, fetch_data functions execute and print the message "fetching data, time taken." However, when we try to retrieve the data for the same IDs again, it's fetched from the cache this time, so no message is printed.
The LRUCache decorator is used within the cached decorator. It accepts a parameter named "maxsize" and prioritizes the removal of the least recently used items to create space when needed.
from cachetools import cached, LRUCache
import time
import requests
# API endpoint for fetching TODOs
endpoint = "<https://jsonplaceholder.typicode.com/todos/>"
# Using the LRUCache decorator function with a maximum cache size of 3
@cached(cache=LRUCache(maxsize=3))
def fetch_data(id):
start_time = time.time()
# Requesting different IDs
response = requests.get(endpoint + f"{id}")
print(f"\\\\nFetching data for ID {id}, time taken: ", time.time() - start_time)
# Checking if the response status code is 200 (OK) before extracting the title
return response.json().get("title") if response.status_code == 200 else None
# Example calls to fetch_data with different IDs
print(fetch_data(1)) # Fetching and caching data for ID 1
print(fetch_data(2)) # Fetching and caching data for ID 2
print(fetch_data(3)) # Fetching and caching data for ID 3
# Repeating some calls to demonstrate caching behavior
print(fetch_data(1)) # Retrieving cached data for ID 1
print(fetch_data(2)) # Retrieving cached data for ID 2
print(fetch_data(4)) # Fetching and caching data for a new ID (4)
print(fetch_data(3)) # Fetching and caching data for ID 3
Here’s the output:
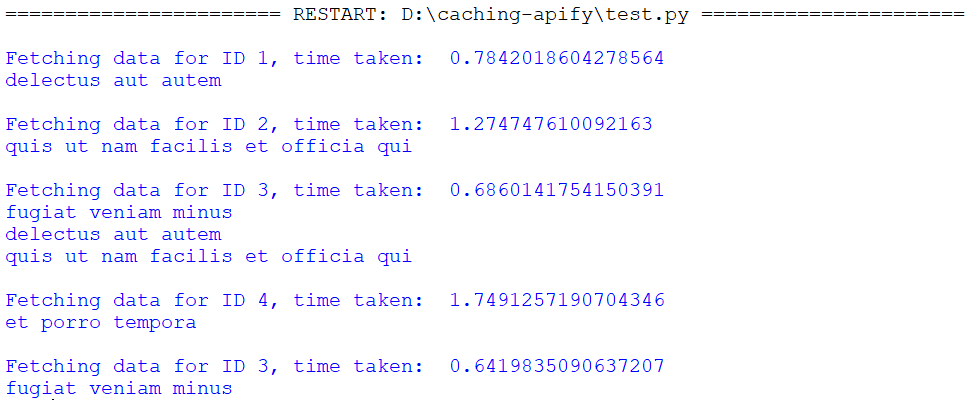
TTL, or “Time to Live”, takes two parameters: “maxsize” and “TTL”. The use of “maxsize” is the same as LRUCache, and the TTL states how long the cache for the function will be stored in the system's cache memory.
from cachetools import cached, TTLCache
import time
import requests
endpoint = "<https://jsonplaceholder.typicode.com/todos/>"
@cached(cache=TTLCache(maxsize=3, ttl=20))
def fetch_data(id):
start_time = time.time()
response = requests.get(endpoint + f"{id}")
time.sleep(id)
print(f"\\\\nFetching data for ID {id}, time taken: ", time.time() - start_time)
return response.json().get("title") if response.status_code == 200 else None
print(fetch_data(1))
print(fetch_data(2))
print(fetch_data(3))
print("\\\\nI'm waiting...")
time.sleep(18)
print(fetch_data(1))
print(fetch_data(2))
print(fetch_data(3))
Here’s the output:
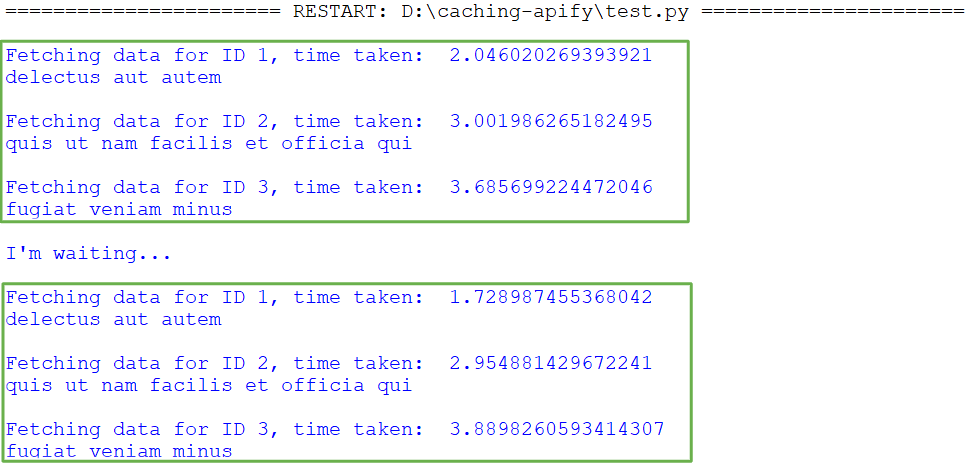
In the code above, the TTL (Time to Live) is set to 20 seconds, which means data will remain in the cache for 20 seconds before being cleared.
For IDs 1, 2, and 3, the execution initially involves a 6-second wait (1+2+3 seconds). Following this execution, there's an additional 18-second wait, totaling 24 seconds (18+6). Since 24 seconds exceeds the TTL of 20 seconds, the cache entries for IDs 1, 2, and 3 are cleared.
Consequently, when subsequent calls are made for IDs 1, 2, and 3, the data will be fetched from the server again, as it's no longer available in the cache.
LFU (Least Frequently Used) cache is a caching technique that tracks how often items are accessed. It discards the least frequently used items to make space when necessary. LFU cache takes one parameter: maxsize, which specifies the maximum number of items it can hold.
from cachetools import cached, LFUCache
import time
import requests
# API endpoint for fetching TODOs
endpoint = <https://jsonplaceholder.typicode.com/todos/>"
# Using the LFUCache decorator function with a maximum cache size of 3
@cached(cache=LFUCache(maxsize=3))
def fetch_data(id):
start_time = time.time()
# Requesting different IDs
response = requests.get(endpoint + f"{id}")
print("\\\\nFetching data, time taken: ", time.time() - start_time)
# Checking if the response status code is 200 (OK) before extracting the title
return response.json().get("title") if response.status_code == 200 else None
# Example calls to fetch_data with different IDs
print(fetch_data(1)) # Fetching and caching data for ID 1
print(fetch_data(2)) # Fetching and caching data for ID 2
print(fetch_data(3)) # Fetching and caching data for ID 3
# Repeating some calls to demonstrate caching behavior
print(fetch_data(1)) # Retrieving cached data for ID 1
print(fetch_data(3)) # Retrieving cached data for ID 3
print(fetch_data(4)) # Fetching and caching data for a new ID (4)
print(fetch_data(2)) # Fetching and caching data for ID 2
Here’s the output:
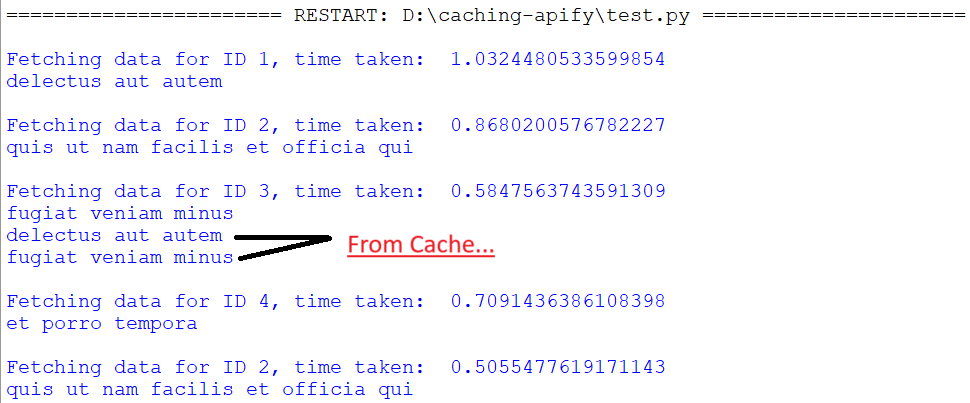
This class randomly selects items and discards them to make space when necessary. By default, it uses the random.choice() function to select items from the list of cache keys. The class accepts one parameter, maxsize, which specifies the maximum cache size, similar to the LRUCache class.
from cachetools import cached, RRCache
import time
import requests
# API endpoint for fetching TODOs
endpoint = "<https://jsonplaceholder.typicode.com/todos/>"
# Using the RRCache decorator function with a maximum cache size of 3
@cached(cache=RRCache(maxsize=2))
def fetch_data(id):
start_time = time.time()
# Requesting different IDs
response = requests.get(endpoint + f"{id}")
print(f"\\\\nFetching data for ID {id}, time taken: ", time.time() - start_time)
# Checking if the response status code is 200 (OK) before extracting the title
return response.json().get("title") if response.status_code == 200 else None
print(fetch_data(3))
print(fetch_data(2))
print(fetch_data(3))
print(fetch_data(1))
print(fetch_data(3))
print(fetch_data(2))
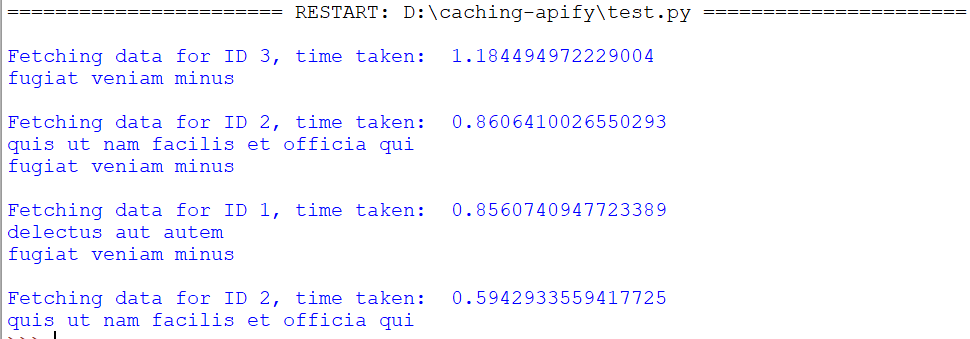
Here’s the output:
Python caching using Redis
Multiple external in-memory cache services like Memcached, and Redis can be integrated with Python to cache the data. These external caches are extremely powerful and offer a wide variety of features. These external caches take care of all the complications of creating and maintaining the cache.
Redis is an in-memory data store that can be used as a caching engine. Since it keeps data in RAM, Redis delivers it very quickly. Memcached is another popular in-memory caching system. Both are significantly faster than traditional databases and in-memory caching libraries.
They are designed for high-speed data access and efficient handling of large request volumes, making them suitable for improving the speed and scalability of web applications. Many people agree that Redis is superior to Memcached in most circumstances.
$ pip install redis
In this section, we'll explore how to implement caching with Python and Redis. To interact with Redis from Python, you'll first need to install redis-py, the Python client library that provides a user-friendly API for communicating with Redis servers. redis-py is a well-established and robust library that enables you to interact directly with Redis through Python function calls.
The two fundamental commands for interacting with Redis are SET (or SETEX) and GET:
SETis used to assign a value to a key. You can optionally specify an expiration time using theEXargument.GETis used to retrieve the value associated with a given key.
docker run -d --name redis-stack -p 6379:6379 -p 8001:8001 redis/redis-stack:latest
Here’s the code:
# Import necessary libraries
import requests
import redis # for using Redis as a cache
import time
# Initialize a Redis client connecting to localhost and default port 6379
redis_client = redis.StrictRedis(host="localhost", port=6379, decode_responses=True)
# Function to get data from an API with caching in Redis
def get_api_data(api_url):
# Check if data is already cached in Redis
cached_data = redis_client.get(api_url)
if cached_data:
print(f"Data for {api_url} found in cache!")
return cached_data
else:
try:
# Request the API
response = requests.get(api_url)
# Check for any HTTP errors in the response
response.raise_for_status()
# Cache the API response in Redis with a timeout of 10 seconds
redis_client.setex(api_url, 10, response.text)
print(f"Data for {api_url} fetched from API and cached!")
return response.text
# Handle request exceptions, if any
except requests.RequestException as e:
print(f"Error fetching data from {api_url}: {e}")
return None
# List of API endpoints to be fetched
api_endpoints = [
"<https://jsonplaceholder.typicode.com/todos/1>",
"<https://jsonplaceholder.typicode.com/posts/2>",
"<https://jsonplaceholder.typicode.com/users/3>",
"<https://jsonplaceholder.typicode.com/todos/1>",
"<https://jsonplaceholder.typicode.com/posts/2>",
"<https://jsonplaceholder.typicode.com/users/3>",
]
# Loop through the API endpoints, fetching and caching data with a 2-second delay
for endpoint in api_endpoints:
time.sleep(2)
data = get_api_data(endpoint)
In the code above, we have a couple of URLs from which to fetch data. We'll make a call for each URL with a sleep time of 2 seconds between calls. The function get_api_data first checks for the data of the URL in the Redis cache using the GET command. If it's there, it pulls it from the cache. If it's not, it fetches the data from the server and saves it to the Redis cache using the SETEX command with an expiration time of 10 seconds.
Here’s the output:

The above output shows that the data is successfully fetched and saved to the cache. Subsequent attempts to access data for the same URL result in retrieval from the Redis cache, as expected.
Now, let's consider what happens if we change the expiration time to 5 seconds and rerun the code. In this case, each time a request is made, the data will be fetched from the server instead of the cache. This occurs because:
- When a URL is accessed for the first time, the data is retrieved from the server and stored in the cache with an expiration time of 5 seconds.
- After 5 seconds, the cached data expires and is automatically cleared from the cache.
- If another request is made for the same URL, the cache is empty, so the data will be fetched again from the server.
Impact of caching on application performance and memory usage
Caching stores frequently accessed data in a faster location, such as RAM. This eliminates the need for frequent trips back to the source (database, server, etc.) for every request. That reduces the workload on backend systems, resulting in faster loading times, and smoother responsiveness.
Here's an example.
Below, we've defined two functions: fibonacci() and fibonacci_cache(). The first function does not use caching, while the second one does. The fibonacci() function works fine, but it's computationally expensive because it recalculates values of n multiple times.
On the other hand, fibonacci_cache() stores the results of calculations using the LRU eviction policy, preventing redundant computations in the recursive process.
import time
from functools import lru_cache
def fibonacci(n):
if n < 2:
return n
return fibonacci(n - 1) + fibonacci(n - 2)
@lru_cache(maxsize=16)
def fibonacci_cache(n):
if n < 2:
return n
return fibonacci_cache(n - 1) + fibonacci_cache(n - 2)
if __name__ == "__main__":
print("Time taken, without cache: ")
start = time.time()
fibonacci(40)
print(time.time() - start)
print("\\\\nTime taken, with cache: ")
start = time.time()
fibonacci_cache(40)
print(time.time() - start)
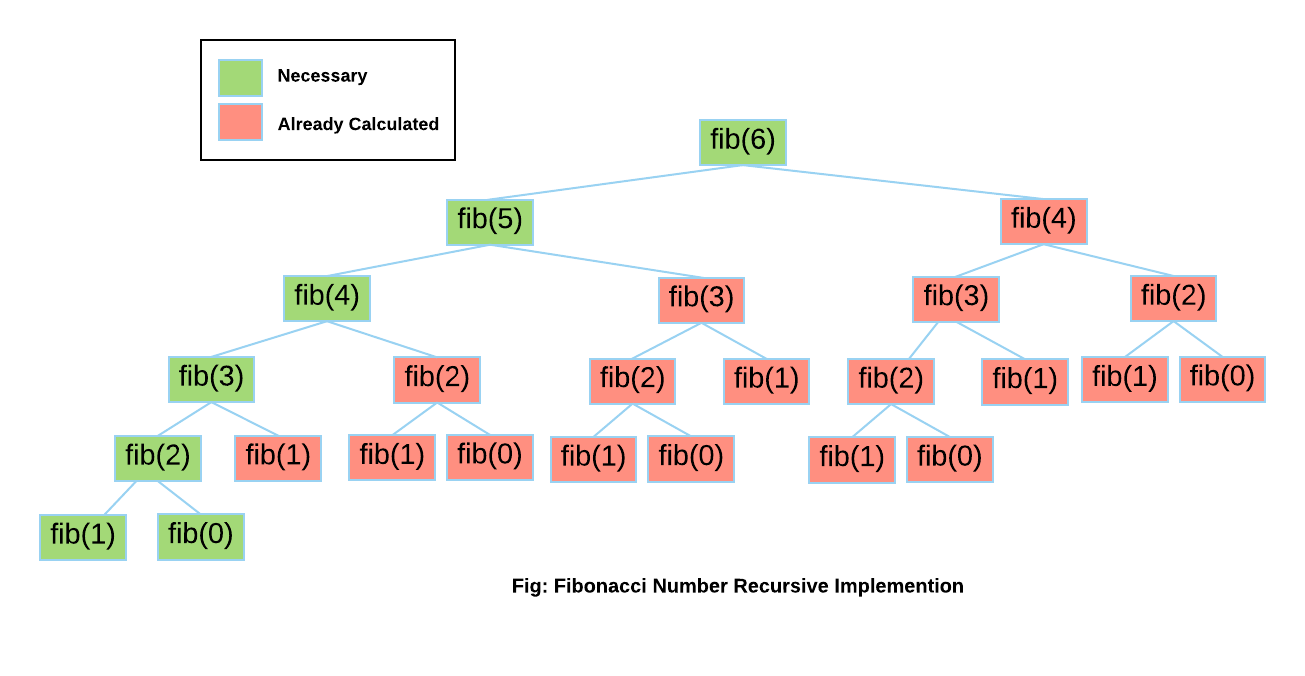
Let's take a look at the visuals to understand how the fibonacci() function computes the results. Notice the high number of redundant calculations (highlighted in red) needed to calculate Fibonacci(6). These repeated calls significantly increase the computation time.
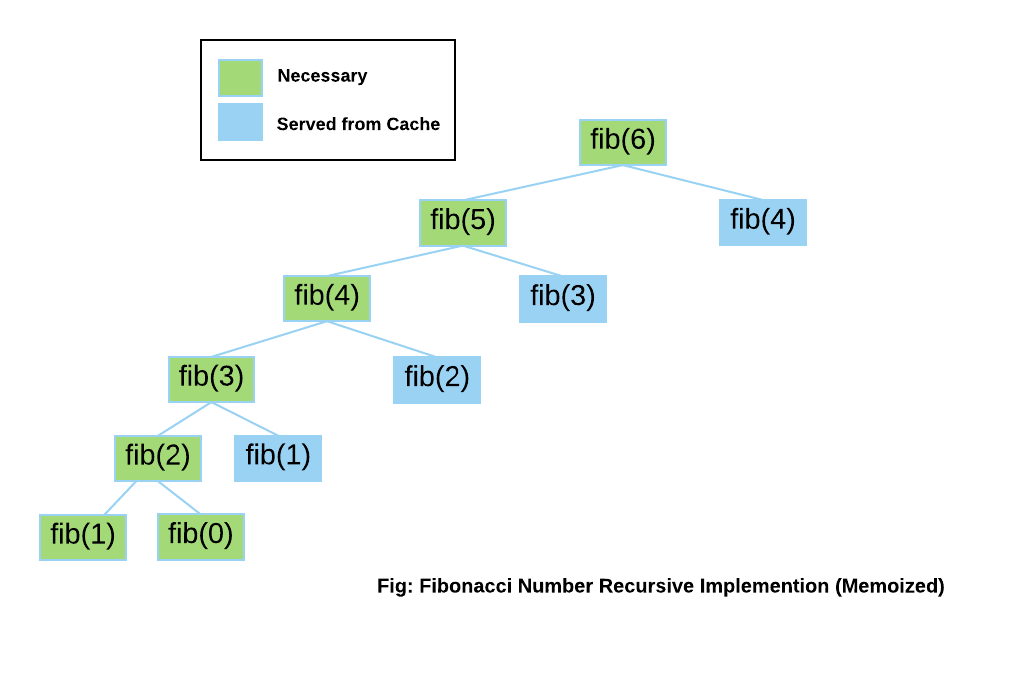
To optimize performance, we're using the @lru_cache decorator from the functools module. This decorator implements a cache based on the Least Recently Used (LRU) strategy, automatically discarding data that hasn't been accessed recently. From this point, any previously calculated data will be efficiently retrieved from the cache rather than being recalculated.
Here's the output for Fibonacci(40), showcasing the significant difference in execution time with and without caching:

Rules and best practices for caching
1. Identify performance bottlenecks
Within an application, certain functions naturally take longer to execute than others. This can be due to heavy calculations, processing, or repeated retrieval of the same data from slow sources such as databases or external APIs. These functions are considered performance bottlenecks and can significantly impact overall application speed.
To optimize performance through caching, it's essential to identify these bottlenecks first. Developers can pinpoint bottleneck functions in two primary ways:
- Manually examine the code to evaluate the execution time of individual lines within each function.
- Use Python profilers to measure the execution time of individual functions automatically.
import requests
def fetch_content(url):
response = requests.get(url)
return response.text
if __name__ == "__main__":
fetch_content("<https://books.toscrape.com/>")
fetch_content("<https://books.toscrape.com/>")
fetch_content("<https://books.toscrape.com/>")
However, if the data being fetched is updated frequently, caching becomes ineffective as it may result in providing outdated information to the application. Therefore, it's crucial to determine when to invalidate the cache and retrieve fresh data.
2. Ensure caching provides a significant performance boost
Ensure that retrieving data from the newly introduced cache is faster than executing the original function directly. In this example, the fetch_content() function has a cache that stores the URL as the key and the content as the value.
import requests
cache = {}
def fetch_content(url):
if url not in cache:
cache[url] = requests.get(url).text
return cache[url]
if __name__ == "__main__":
fetch_content("<https://books.toscrape.com/>")
fetch_content("<https://books.toscrape.com/>")
fetch_content("<https://books.toscrape.com/>")
If the time required to check the cache and retrieve content is similar to the time needed to make a direct request, implementing caching may not yield significant performance benefits. As a developer, it's crucial to ensure that caching measurably improves application performance.
3. Manage the memory footprint of the application
Developers should carefully manage the amount of main memory used by their applications. This is known as the application's memory footprint.
Python caches data in the main memory. Using a larger cache or storing unnecessary information can increase the memory footprint. Developers should be mindful of the cache's data structures and store only essential information.
Consider the following example:
Suppose there is a college alumni portal that displays information about its graduates. Each alumnus has various details stored in the database, such as ID, name, email address, physical address, and phone number.
However, the dashboard displays only the names of the alumni. Therefore, when building the application, it's more efficient to cache only the alumni names rather than their entire information.
First, we'll store only the names in the cache and calculate the total size. We'll then store the complete alumni information in a separate data structure, named cache_optimized. Finally, we'll use a total_size function to calculate the size of each cache to compare their memory footprints.
from sys import getsizeof
from itertools import chain
import requests
cache = {}
cache_optimized = {}
url = "<https://jsonplaceholder.typicode.com/users/>"
# Store only the name of the Alumni
def get_content(id):
if id not in cache:
cache[id] = requests.get(f"{url}+{id}").json()
return cache[id]
# Store all the information about the Alumni
def get_content_optimized(id):
if id not in cache_optimized:
cache_optimized[id] = requests.get(f"{url}+{id}").json().get("name")
return cache_optimized[id]
# ...
# Source of Code: <https://code.activestate.com/recipes/577504/>
def total_size(o, handlers={}):
def dict_handler(d):
return chain.from_iterable(d.items())
all_handlers = {dict: dict_handler}
all_handlers.update(handlers)
seen = set()
default_size = getsizeof(0)
def sizeof(o):
if id(o) in seen:
return 0
seen.add(id(o))
s = getsizeof(o, default_size)
for typ, handler in all_handlers.items():
if isinstance(o, typ):
s += sum(map(sizeof, handler(o)))
break
return s
return sizeof(o)
# ...
if __name__ == "__main__":
get_content(1)
get_content_optimized(1)
print("Size of Cache: " + str(total_size(cache)) + " Bytes")
print("Size of Optimized Cache: " + str(total_size(cache_optimized)) + " Bytes")
Here’s the output:

As we see, unnecessary cached information increases memory footprint.
Python caching use cases
We've explored various approaches to implementing Python caching. Let's now code a simple real-world application that uses this concept.
In this application, users will only need to enter their ID to retrieve all of their associated information. The application will fetch this information from the URL (https://jsonplaceholder.typicode.com/users/), which contains data for multiple users.
To prevent redundant server calls and potential performance degradation, we'll implement caching and store user data in a JSON file called users.json.
The application will follow these steps:
- On receiving a user request, the application first searches for the requested information within the
users.jsoncache file. - If the data is found in the cache and not expired, it's retrieved and displayed to the user immediately. This eliminates the need to make an external server call.
- If the information isn't present in the cache, the application fetches all of the user's information from the specified URL.
- The retrieved information is then saved to the
users.jsoncache file with the expiration time for future use and returned to the user.
import json
import requests
from datetime import datetime, timedelta
class UserData:
def __init__(self, data_url: str, cache_filename: str, ttl_seconds: int):
self.data_url = data_url
self.cache_filename = cache_filename
self.ttl_seconds = ttl_seconds
def fetch_data(self, user_id: int):
local_data = self.read_local_data()
if local_data and isinstance(local_data, dict):
user_data_list = local_data.get("data", [])
user_data = next(
(ud for ud in user_data_list if ud.get("id") == user_id), None)
if user_data and self.is_data_valid(local_data):
print("Data found in cache, fetching...")
return user_data
print("\\nFetching new JSON data from the server...")
try:
response = requests.get(self.data_url)
response.raise_for_status()
json_data = response.json()
expiration_time = datetime.now() + timedelta(seconds=self.ttl_seconds)
data_with_ttl = {"data": json_data,
"expiration_time": expiration_time.isoformat()}
with open(self.cache_filename, "w") as file:
json.dump(data_with_ttl, file, indent=2)
user_data = next(
(ud for ud in json_data if ud.get("id") == user_id), None)
if user_data:
return user_data
except (requests.RequestException, json.JSONDecodeError) as e:
print(f"Error fetching data: {e}")
return "Data not found, try again!"
def read_local_data(self):
try:
with open(self.cache_filename, "r") as file:
data_with_ttl = json.load(file)
return data_with_ttl
except (FileNotFoundError, json.JSONDecodeError):
return None
def is_data_valid(self, data_with_ttl):
expiration_time_str = data_with_ttl.get("expiration_time")
if expiration_time_str:
expiration_time = datetime.fromisoformat(expiration_time_str)
return datetime.now() < expiration_time
return False
if __name__ == "__main__":
user_id = input("Enter ID: ")
data_url = "<https://jsonplaceholder.typicode.com/users/>"
cache_filename = "users.json"
ttl_seconds = 60
data_fetcher = UserData(data_url, cache_filename, ttl_seconds)
fetched_data = data_fetcher.fetch_data(int(user_id))
print(f"\\nData Fetched for ID ({user_id}): {fetched_data}")
Here’s the output:
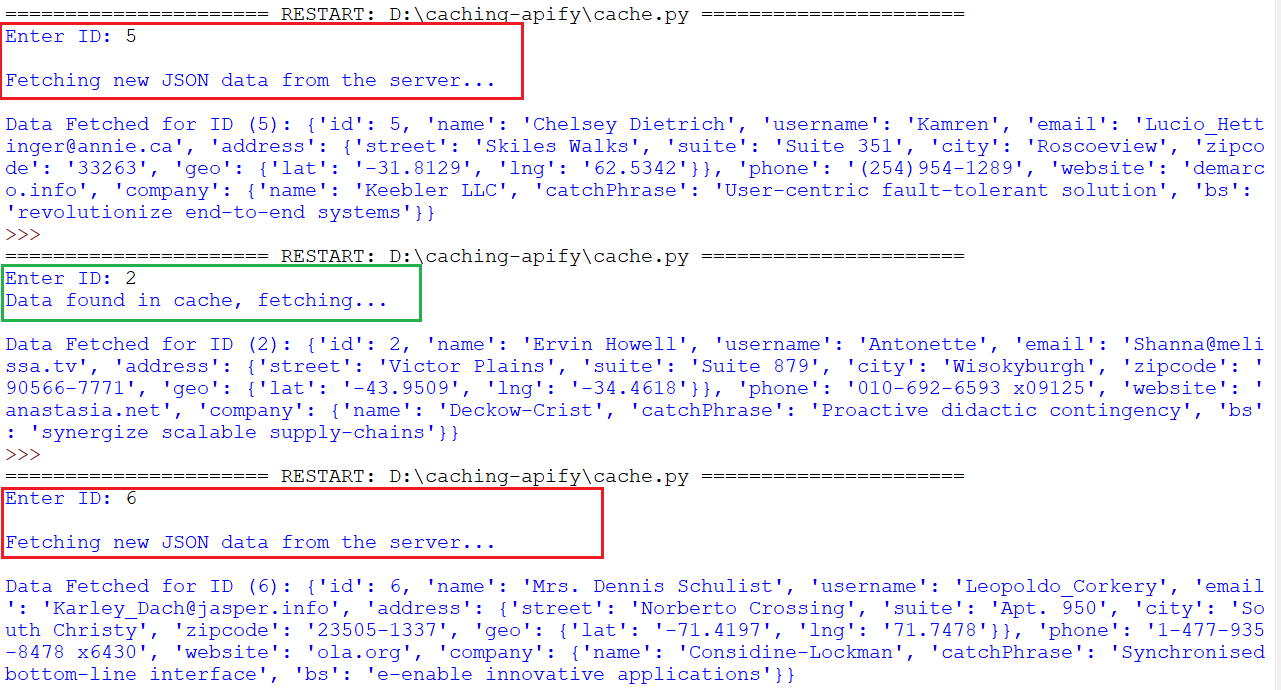
In the scenario described above, searching for an ID for the first time fetches the information from the server and stores it in the cache. This information has an expiration time of 60 seconds, as defined in our code by setting the TTL to 60 seconds. Subsequent searches for other IDs first check the cache. If the data for the requested ID is present and hasn't expired, it's retrieved from the cache (significantly faster than fetching from the server). If the data is expired or doesn't exist in the cache, it's fetched from the server.
Using Python caching for web crawling and scraping
To effectively demonstrate how caching can be integrated into web crawling and scraping tasks, we'll explore examples using two popular Python libraries: Requests for synchronous operations and HTTPX for asynchronous operations. These examples will highlight the implementation of caching mechanisms that can optimize your Python web scraping processes by reducing the need to re-fetch data, thus saving time and decreasing server load.
Separating the crawling and scraping steps
By separating the crawling and scraping steps with Requests and HTTPX, you don't have to recrawl when making changes to the scraper and rerunning it on historical data. So, let's look at how you can move the crawling step into a separate function and using a caching mechanism, the requests-cache library.
We'll use Requests for synchronous crawling and HTTPX for asynchronous crawling.
Requests without caching
pip install requests==2.31.0import requests
def get_html_content(url: str, timeout: int = 10) -> str:
response = requests.get(url, timeout=timeout)
return str(response.text)
def main() -> None:
html_content = get_html_content('https://news.ycombinator.com')
print(html_content[:1000])
if __name__ == '__main__':
main()HTTPX without caching
pip install httpx==0.27.0import asyncio
import httpx
async def get_html_content(url: str, timeout: int = 10) -> str:
async with httpx.AsyncClient(timeout=timeout) as client:
response = await client.get(url)
return str(response.text)
async def main() -> None:
html_content = await get_html_content('https://news.ycombinator.com')
print(html_content[:1000])
if __name__ == '__main__':
asyncio.run(main())Requests with caching using requests-cache
pip install requests-cache==1.2.0import requests
import requests_cache
requests_cache.install_cache('my_requests_cache', expire_after=3600) # Cache expires after 1 hour
def get_html_content(url: str, timeout: int = 10) -> str:
response = requests.get(url, timeout=timeout)
return str(response.text)
def main() -> None:
html_content = get_html_content('https://news.ycombinator.com')
print(html_content[:1000])
if __name__ == '__main__':
main()Now when you rerun the script, it will use the cache value and not fetch the website again (if it was downloaded earlier), even if you made changes in the script.
The above example utilized the third-party requests-cache library, which uses the SQlite database. Now, let's do the same thing with HTTPX using the third party diskcache library.
HTTPX with caching using diskcache
pip install diskcache==5.6.3import asyncio
import httpx
from diskcache import Cache
cache = Cache('my_httpx_cache') # Create a persistent cache on disk
async def get_html_content(url: str, timeout: int = 10) -> str:
# Check if the URL is already in the cache
if url in cache:
print(f'Using cached content for {url}')
return str(cache[url])
print(f'Making a new request for {url}')
# If not in the cache, make a new request and store in the cache
async with httpx.AsyncClient(timeout=timeout) as client:
response = await client.get(url)
html = str(response.text)
cache[url] = html
return html
async def main() -> None:
html_content = await get_html_content('https://news.ycombinator.com')
print(html_content[:1000])
if __name__ == '__main__':
asyncio.run(main())Alternatively, you could use the Hishel library.
Python cache recap
Python offers several effective caching mechanisms to help you speed up your code:
- Create simple caches using Python dictionaries, allowing for O(1) time access to cached values.
- Use the
cachetoolsmodule, which includes variants of the Python Standard Library's@lru_cachefunction decorator, such as LFUCache, TTLCache, and RRCache. - Consider external caching services like Memcached or Redis for more advanced features and flexibility.





