Reddit bills itself as “the front page of the internet”. That’s a bold claim, but it is definitely true for a significant number of internet users, with the latest figures for 2024 showing that it has over 1.2 billion monthly active users and over 100,000 active subreddit communities. But the main question here for us is: can we scrape data from Reddit?
We certainly can! Read on and follow this guide to find out how, or watch our short YouTube tutorial on scraping Reddit if you prefer video 📹🔴▶️
🤖 What is Reddit and what is it for?
reddit.com is a huge social sharing site composed of smaller communities called subreddits where any user can post links, stories, images, or videos to these subreddits. The post gets more or less coverage depending on how much engagement it has. You can treat it as a news aggregator by special interests.
Each subreddit also has moderators who make sure that the submissions are relevant to the topic of the subreddit, follow the rules, and aren’t just spam. This interactive Reddit map gives you some idea of the scope of Reddit interests.
🤔 What are the use cases for scraping Reddit?
Now that you know how many users are on Reddit and how diverse their interests are, you might be starting to think of how to collect and apply all that user-generated data. Here are a few ideas:
| Use case | Use case description |
|---|---|
| 👁 Topic awareness | Keep track of how your brand, product, or topic is being discussed across Reddit. Get a sample of Reddit comments to assess the range of opinions. |
| ❓ Customer engagement | Connect with your users and ensure their questions are answered quickly and effectively. |
| ✨ Trend monitoring | Watch for new trends, and attitudes, and avert potential PR disasters. Reddit often acts as an incubator for ideas, and how Redditors behave and think usually precedes mainstream channels by months or even years. |
| 📰 News monitoring | Keep ahead of potential profits or losses resulting from Reddit activity, like the GameStop stock price surge, and high-stakes subjects such as finance, politics, technology, and news in general. |
| 📹 Content aggregation | Aggregate data, posts, images, or videos from multiple subreddits and present them in new and interesting ways for your users. |
🕵️ What data can I get from Reddit?
Web scraping Reddit shouldn't be difficult; after all, it's all publicly accessible data.
| Data point | Data |
|---|---|
| Subreddits | Most popular posts, community details (URL, number of members, category, etc.) |
| Reddit posts | Redditor's username, post title, text, post comments, and the number of votes |
| Reddit comments | Time of the comments, points received, author usernames, original posts, and relevant URLs |
| User details | Comment history and recent posts |
| Data across Reddit | By specifying keywords or search URLs |
🗿 What's better for scraping Reddit data: an official Reddit API or a web scraper?
Reddit has its own API (application programming interface) designed to let developers interact with the Reddit website and its data directly. It’s a great resource and every dev interested in scraping Reddit should be familiar with what it offers. But there are a few reasons people prefer using a Reddit web scraper rather than the Reddit API:
- Reddit requires you to be authenticated to scrape the Reddit website with their API.
- Reddit requires developers to register to get a token and use the official API. While we can't say whether Reddit ever refuses to give someone a token, they might since they are not that much pro-scraping.
- Reddit has specific rules to follow for how one should use their API.
- The use of Reddit's API for commercial use requires special authorization.
- Free Reddit API use is granted only for accessibility-focused apps.
- Last but not least, with the new pricing Reddit API gets costly very quickly. Currently, Reddit API pricing starts from ¢24 per 1,000 requests. You can do the math for your app or service but as Apollo's CEO quickly figured out, his company (that heavily relied on Reddit's API) would have to pay Reddit $12,000 for 50 mln requests and $20 mln per year.
So, if you are wondering whether you can scrape Reddit without API, this tutorial is for you. The good news is: web scraping Reddit is not all that difficult, even if you've never extracted data from websites before. A Reddit crawler (or scraper) will do most of the work for you.
Even better news is: with a ready-made web scraping tool like Reddit Scraper, you will be able not only scrape Reddit data, but also download it, export it using an API or integrate it with other apps and platforms. But all in due time.
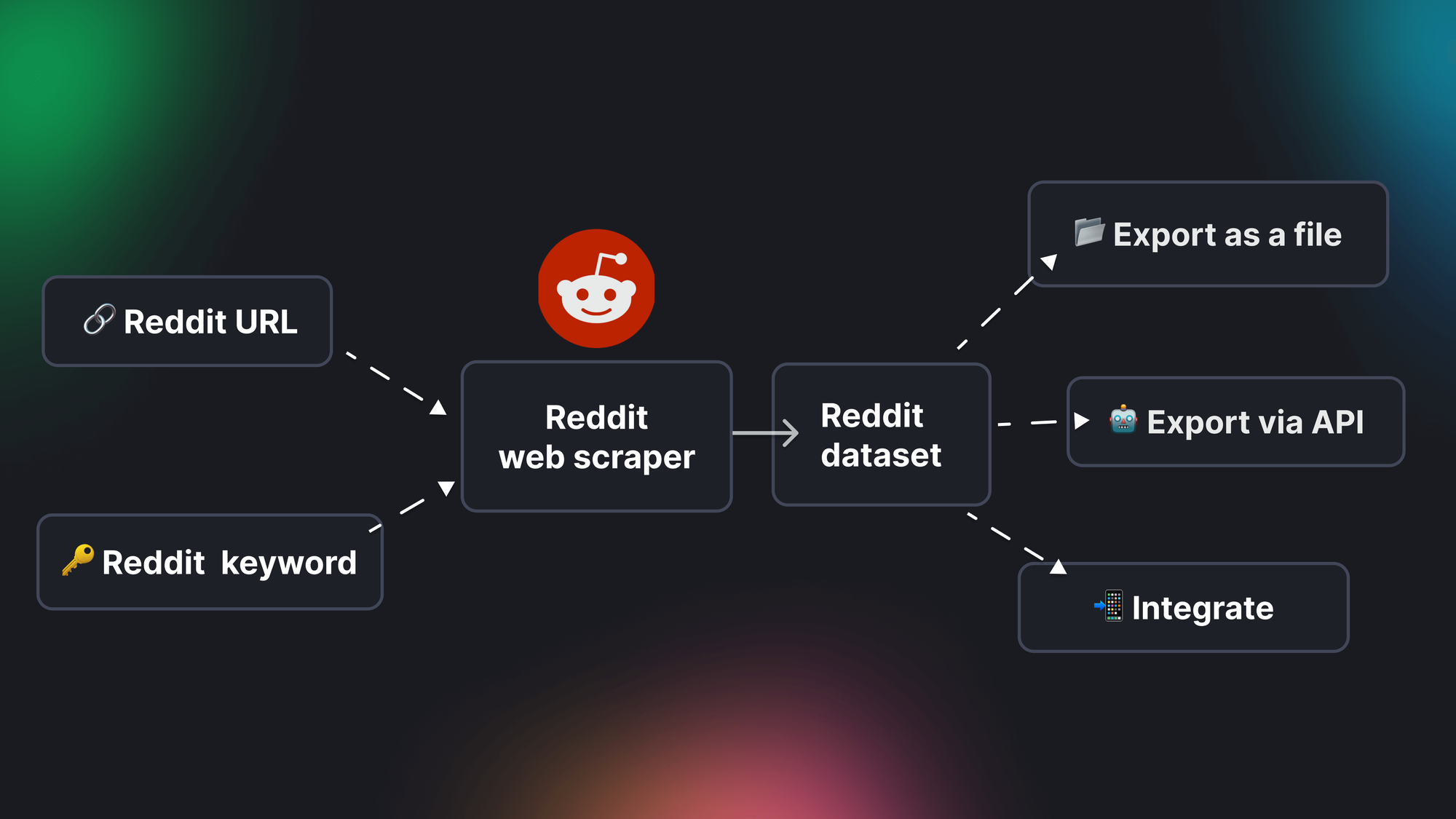
🥾 Step-by-step guide to scraping Reddit
Step 1. Go to Reddit Scraper
Click the Try for free button on the Reddit Scraper page.
You'll find yourself on a sign-up page. You can easily sign up or sign into your account by using your Gmail, another email, or GitHub account. After you create an account, you’ll be redirected to Apify Console — your workspace for web crawlers and other web automation tools like this Reddit crawler.
Step 2. Choose subreddit, Reddit profile, post, or keyword to scrape
Now you’re in your workspace, the first thing you need to do is to tell Reddit Scraper what data you want to get from Reddit. Choose your starting point:
- section 1 – URLs 🔗 of specific subreddits, separate posts, and profiles
- section 2 – keywords 🔑 across the whole Reddit website
🔗🤖 How to scrape Reddit posts from subreddits
Head over to Reddit and find subreddits you want to extract data from. Then copy their URLs and paste them into the Start URLs fields. You can add as many as you want.
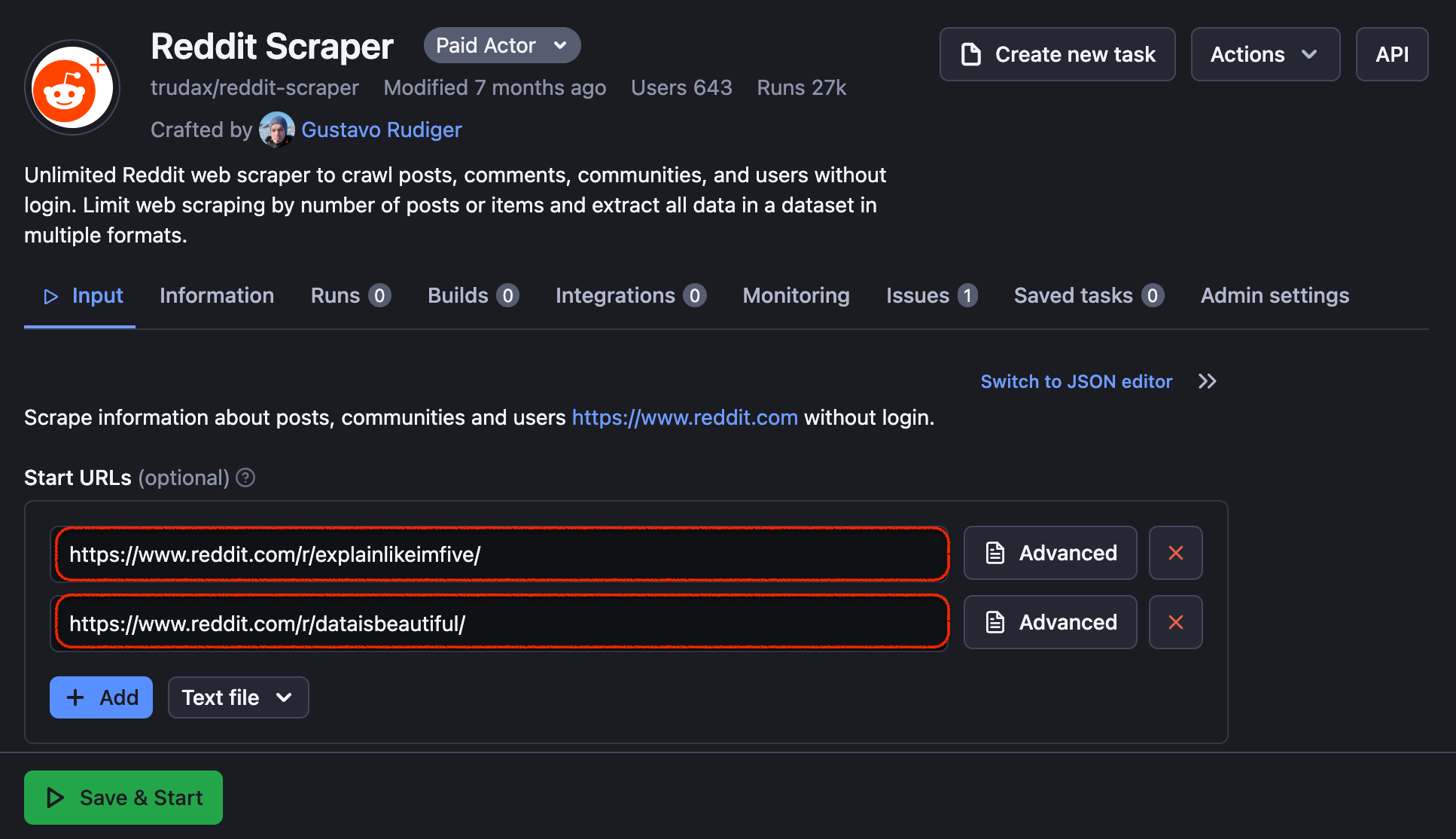
Copy-paste URLs of one or more subreddits that interest you. You will be able to scrape all posts as well as user pages. Subreddit data will include (for each scraped post of this subreddit):
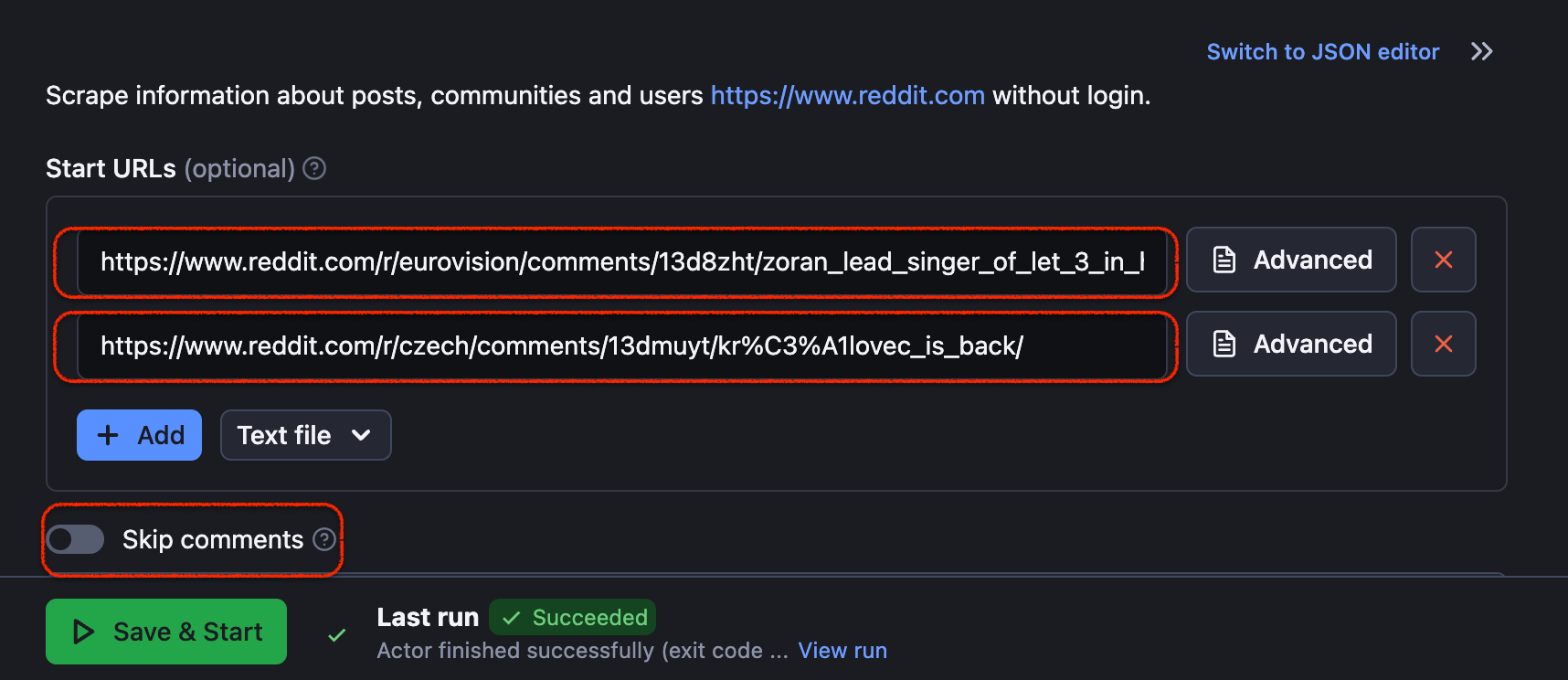
🔗💬 How to scrape Reddit comments from posts
Now, instead of subreddit URLs, pick specific posts on Reddit.
🔑🔍 How to scrape Reddit by search term
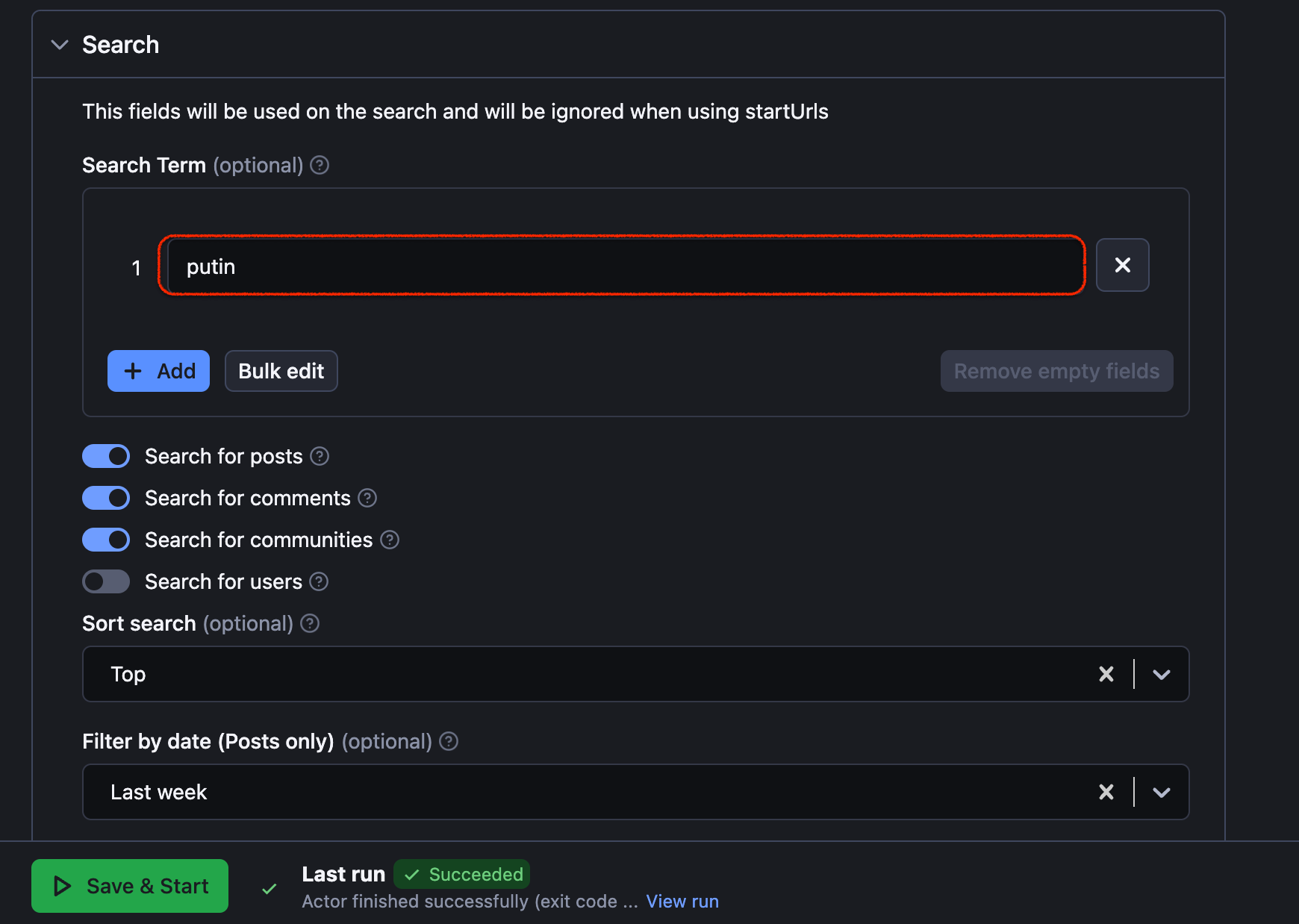
Alternatively, you can also scrape Reddit by a search term instead of pasting a URL. There is no need to go on Reddit for this, just type in the keyword in the Search field – one or more.
Then, pick what you are searching for: posts, comments, users or communities that contain this keyword. You can filter scraping results by date and decide how you want your search to be sorted when scraped: trending, novelty, amount of comments, etc.
✅ in each section, you can add as many URLs or keywords as you want using the Add+ button or by pasting a prepared list into Bulk edit field.
✅ you can fill in either the URL or Search section; they are mutually exclusive.
✅ you can set how many results you want in Limits field. You can set how many comments per post you want how many posts per page.
Step 3. Click Start ▶️
When you’re happy with how you’ve set up your scraping parameters, click the Start button. The Reddit crawler will start scraping, and you’ll see that it has a status of Running. It might take a few minutes to complete the scraping run, but you should soon see that the crawler has ☑️ Succeeded.
Step 4. Download your Reddit data
Now click on the Export results button or go to the Storage tab. Storage contains your scraped data in many formats, including HTML table, JSON, Excel, CSV, and XML. You can preview data using the 👁 Preview button, and download it in a format that suits your needs.
🔗🤖 Sample of scraped posts and comments from subreddits
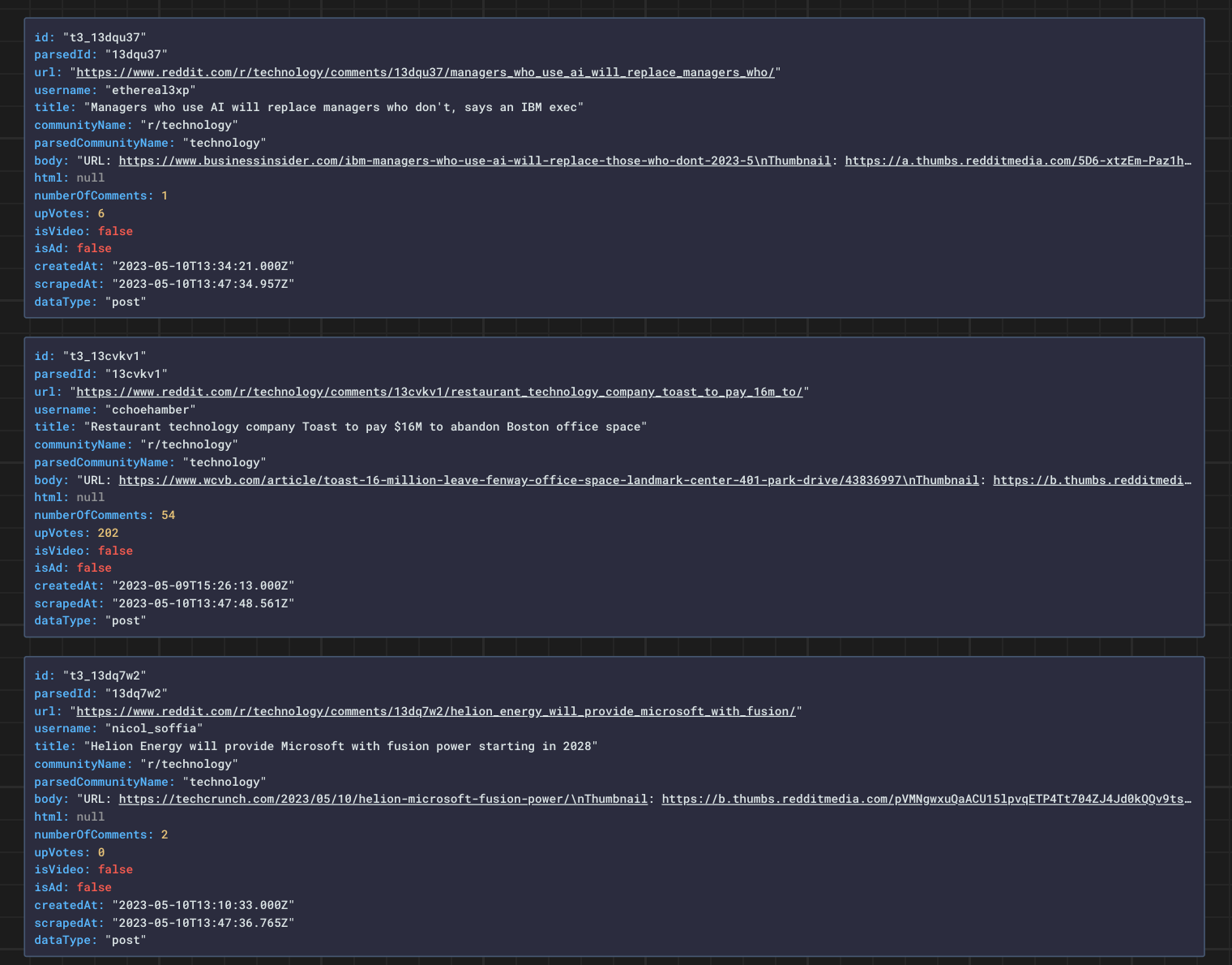
🔗💬 Sample of scraped comments from posts
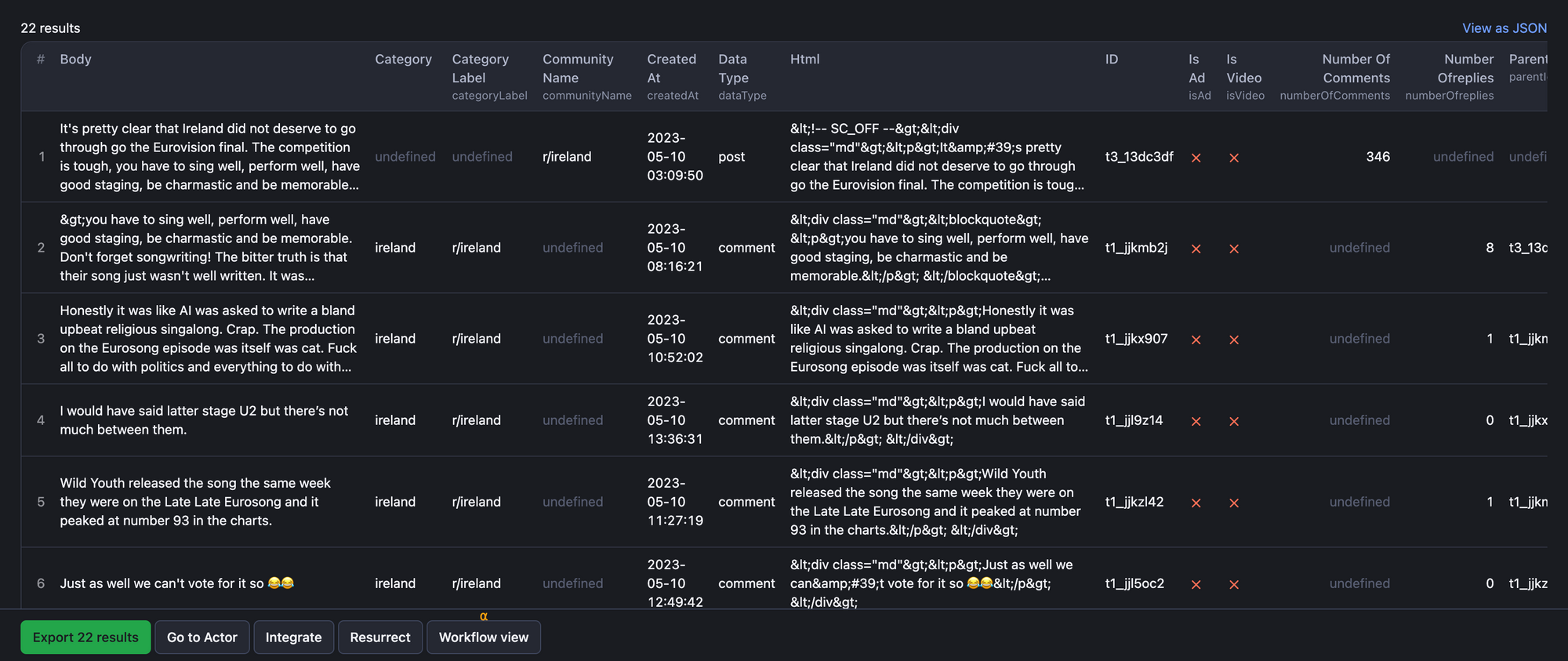
🔍🔑 Sample of scraped data by search term (comments, posts)
Step 5. Export Reddit data using an API
As an extra step, you can use the Apify API to manage, schedule, and run any Apify scraping tools, including this Reddit scraper. You can essentially turn this scraper into your own Reddit data API.
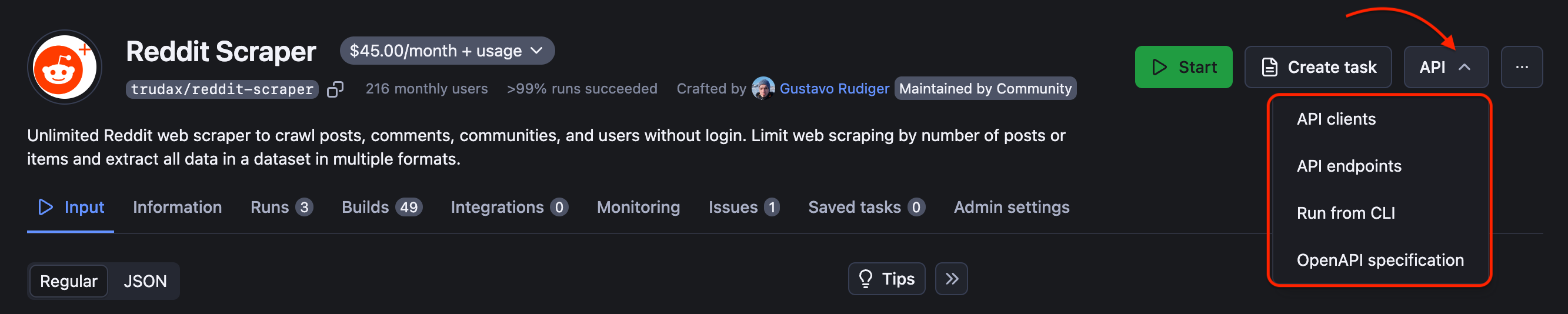
To access the API using Python, use the Python API apify-client package. Reddit JavaScript API is also available in Node.js. And you can also use API Endpoints directly.
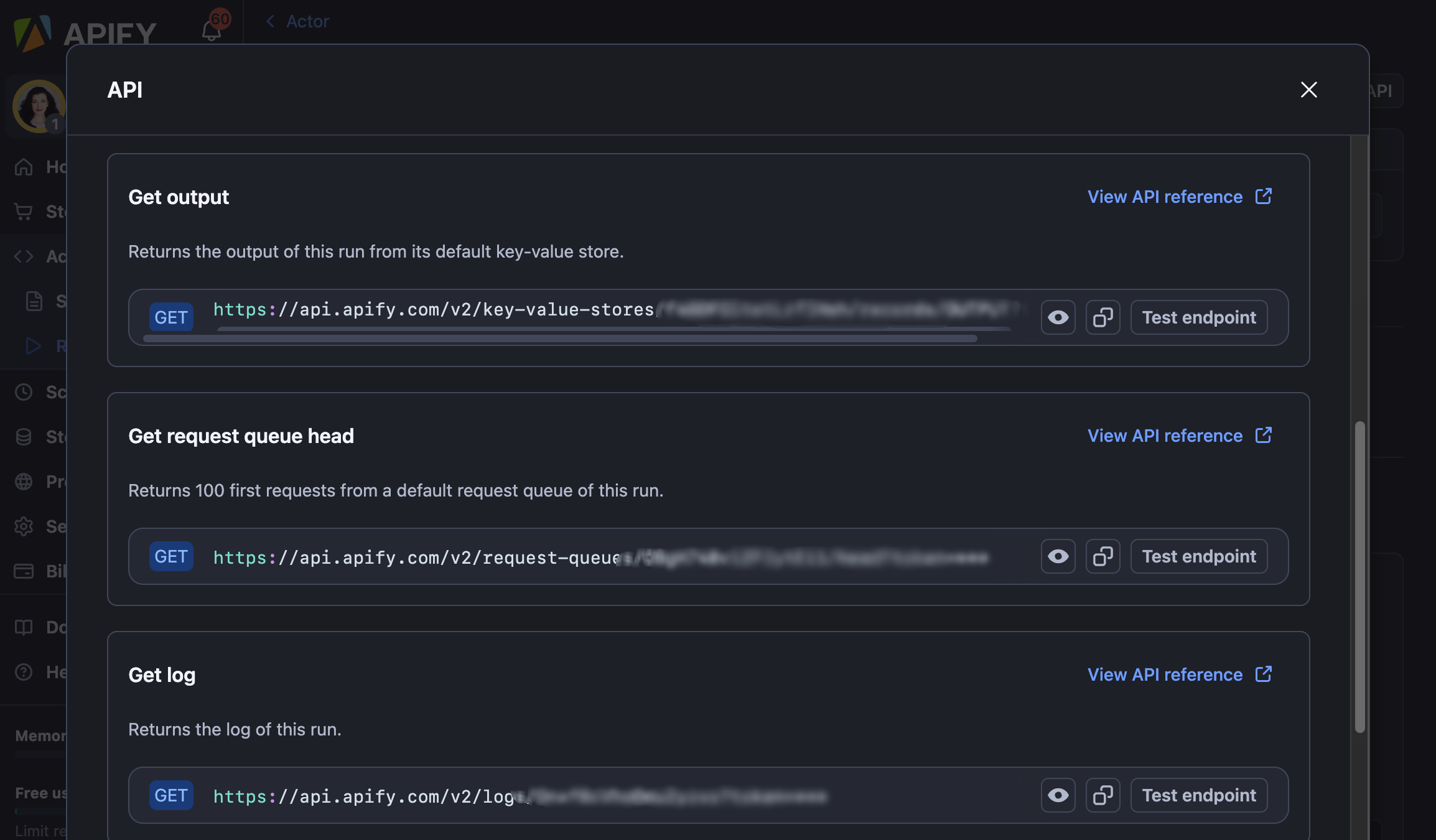
The API will enable you to access any datasets, monitor performance, fetch results, create and update versions, and more. For full details, see our API reference docs or click on the API tab for code examples. Here's a Reddit API example for handling scraped data and runs:
Now that you know how to scrape Reddit with our free Reddit web scraper, you can play around with the settings and see what kind of data you can get. And if you prefer following a video guide for scraping Reddit data, here's one for you which replicates the steps above:
❓ FAQ
⚖️ Is web scraping legal for Reddit?
Yes. Scraping Reddit is legal as long as you respect regulations such as the GDPR and the CCPA, which cover personal data protection. It’s also important to only scrape publicly available content that is not protected by copyright. You can get more info about the legality of web scraping in this in-depth blog post from our lawyers.
⛳️ Does Reddit allow web scraping?
In general, yes, but it doesn't encourage it. In 2023, Reddit has been expressing concerns about businesses using scraped Reddit data to feed generative AI tools and large-language models. Hence, the commitment to make the official Reddit API paid and less accessible for scraping.
🍪 Do I need to apply cookies to get behind login when scraping Reddit?
No. As of May 2024, Reddit keeps its data public and doesn’t apply the login wall.
🍃 Is there any way to scrape more recent Reddit data?
Reddit Scraper allows to pre-filter Reddit posts you want to scrape by date (by last hour, day, week, month, last year). For now, the Reddit crawler doesn't support configuring exact date range before scraping. You can message the developer behind this Reddit web scraper with your suggestion to add this option to the input. Or filter data from the output by date range that interests you, after the scraping has finished.
💰 Is Reddit API paid?
Starting from July 1st, 2023, Reddit API is free to use as long as you have OAuth registration and make less than 100 queries per minute per OAuth ID. Without registration, you are limited to 10 queries per minute. In spring 2023, Reddit announced plans to make Reddit API paid arguing this decision with increased use of Reddit data as training material for large language models such as OpenAI’s ChatGPT and GPT-4.
💸 Why did Reddit API become paid?
Following the example of Twitter, on July 1, 2023, Reddit has restricted free access to its API. What pushed them over the edge was the extensive use of Reddit’s user-generated content as training material for customized GPT-4 models and LLMs. While there are exceptions for free API usage for developers working on accessibility-focused apps, in general, Reddit data has become less accessible. This decision caused huge organized pushback from the Reddit community and culminated in what is now known as 2023 Reddit API controversy. As of May 2024, Reddit API pricing starts from ¢24 per 1,000 requests.
👷 This scraper doesn't do what I need it to do. Can I build a Python Reddit scraper of my own?
Yes, you can and Apify can host it in the cloud for you. You can create your own Python Reddit scraper (or crawler for any website for that matter) directly on the platform and keep production there. If you prefer Reddit scraping in Python from your computer and not cloud, alternatively, you can develop Reddit crawler locally and only push it to the Apify cloud during deployment.
🛡 Do you need proxies to scrape Reddit?
These days, absolutely. Subreddits are public to access and don’t require a login to allow you to fetch information. But you will still usually need some sort of proxy to be able to scrape Reddit successfully. Although you can still get some results with just datacenter proxies, our best bet is on residential proxies for all Reddit crawling. Luckily, our Free plan comes with a free trial of Apify Proxy, so that should help you get started.
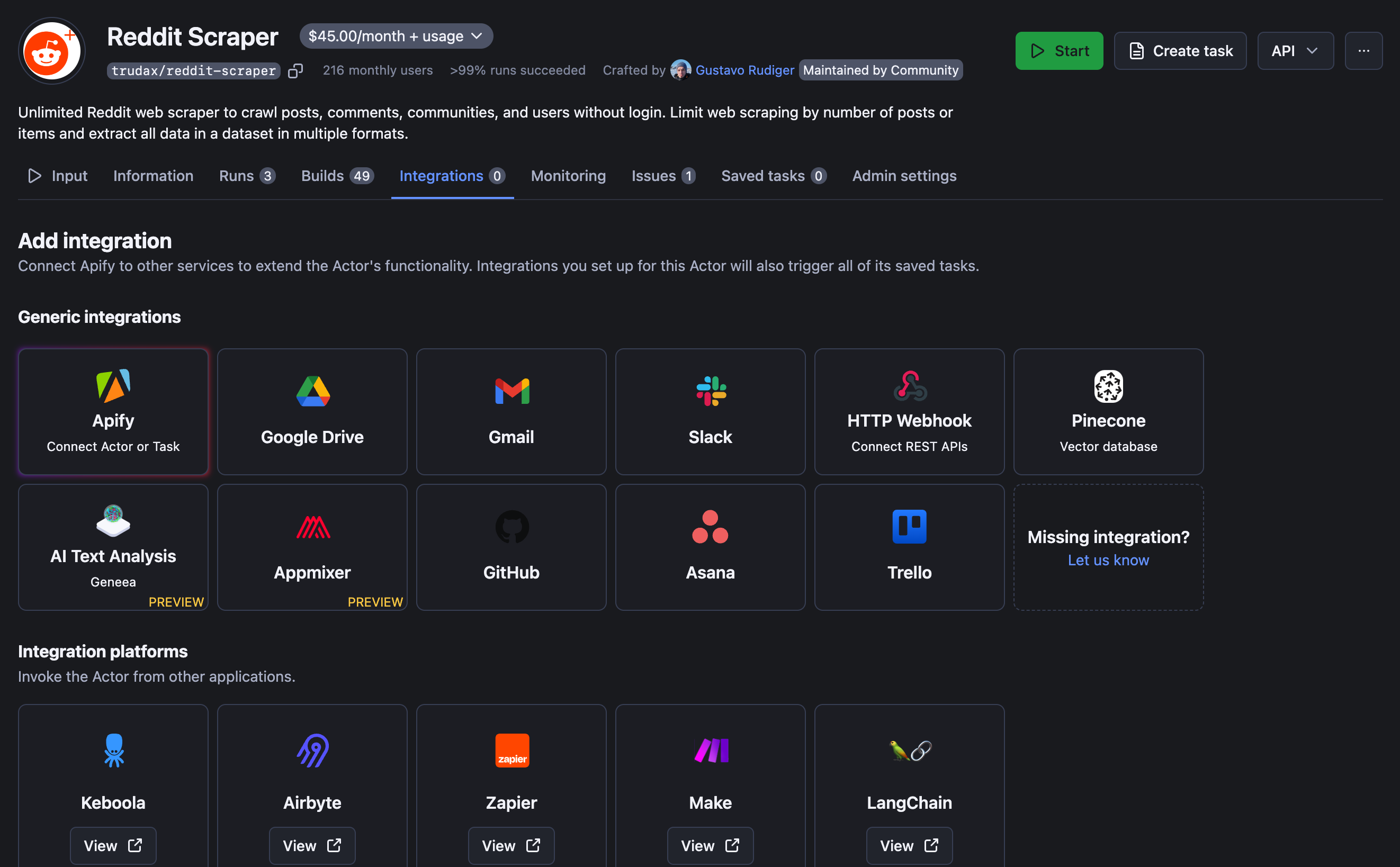
🤝 Can I integrate my Reddit data with other services?
Yes. Reddit Scraper can be connected with almost any cloud service or web app thanks to integrations on the Apify platform. You can integrate with LangChain, Make, Trello, Zapier, Slack, Airbyte, GitHub, Google Sheets, Google Drive, Asana, and more.
🤖 Can I use AI to scrape Reddit?
AI is currently unable to scrape websites directly, but it can help generate code for scraping Reddit if you prompt it with the target elements you want to scrape. Note that the code may not be functional, and website structure and design changes may impact the targeted elements and attributes.
💰 This Reddit scraper is too pricey for me. Are there any alternatives?
One of the good things about Apify Store is that there are new scrapers added all the time. It's a marketplace where anyone with passion for web automation can create and share their solutions. If the Reddit web scraper in this tutorial doesn't fit the bill for you, you can always try a few other Reddit crawlers, or create your own.