



Your favorite news aggregator can tell a lot about who you are. What's in your pinned tabs - Bored Panda 🐼, Rotten Tomatoes 🍅, or perhaps something more niche, like Morning News 🗞 or Techmeme 💻 for instance? Here's a quick recap of what online aggregators are all about, how they differ from one another, why you should create one, and how you can make it happen.
What is an aggregator site?
An aggregator site is a curated news site, which displays continuously updated content. As a rule, content on aggregator sites is collected automatically using tools like web scrapers, and goes through several levels of filtering and curation. Filtering and curation depend heavily on the topic of the aggregator site and curators' preferences in source authority.
What is an online aggregator?
An online aggregator or content aggregator is a tool that pulls fresh content from various web resources and publishes it on one website. Essentially, that website is the aggregator. You can look at it as a curated library of continuously updated content.
What is the reason behind the popularity of this website format? Well, that's easy. The internet is a skyscraper-like library, and not all its content might be interesting or relevant to you. If you're interested in a certain topic, a part of the world, a particular community, or a type of content, there's just not enough time to search through an endless catalog that's expanding as we speak. Content aggregators are not about creating more content; they are about deliberate and automatized content curation. That's why online aggregators are more comprehensive than digging through the world wide web to find content that matters to you.
Example of an online aggregator
Let's say you've found a new obsession with Greek mythology. You've googled enough to have a few dozen relevant links in your browser bookmarks that you regularly check on. Those could include podcasts, documentaries on YouTube, books in Barnes & Noble, Reddit discussions you follow, interesting TikTok profiles producing content on the subject, movie lists, websites to make travel reservations in Greece, relevant art exhibitions, museums, and ancient ruins you'd like to see one day.
At some point, you start asking yourself: instead of checking on these links once in a while, wouldn't it be great to have some portal that displays them all together on one page? So you choose a few priority resources, centralize them on the newly bought domain sysiphusnews.com and make sure they are updated automatically. Now you've got yourself a custom online aggregator that might become useful for you and other Greek mythology aficionados alike. With this website, you've supported your interest, helped form a new community around it, and saved yourself time by avoiding information overload.
What are the main types of online aggregators?
To answer this question, you need to ask yourself: what would be the easiest content to aggregate? There are no wrong answers here, and usually, the simplest ones are what we see online most often: news, reviews, current prices, and user-generated content from social media. The most common types of content aggregators are (with examples):
- News aggregators:
- General: Google News, Huffington Post, News 360.
- Viral and entertainment: Bored Panda, BuzzFeed, Cracked.
- Specific or niche: Techmeme, FiveThirtyEight.
- Review aggregators: Rotten Tomatoes, Capterra, Glassdoor.
- Travel industry aggregators: Booking.com, Tripadvisor.
- Social media aggregators such as Curator.io for pulling user-generated content from Instagram.
- Video content aggregators such as YouTube.
- Search engine results aggregators: a good example would be Dogpile. These ones collect the best search results from multiple search engines.
- Statistics aggregators for research, such as an aggregator to track Covid-19 statistics.
- Custom-made aggregators: real estate listings, availability updates, stock options pricing, etc.
As you can see, there's incredible diversity among aggregator websites, the reason for this being that they are highly customizable. Price comparison aggregators are another common example, bringing together product prices from multiple retailers so users can quickly compare costs, discounts, and availability in one place.
So no wonder the best aggregator websites usually happen to be the best-known. In fact, they are so ubiquitous you must have visited an aggregator already at least once in your life without knowing it wasn't a regular website.
Is it legal to aggregate content?
In short, yes. Unless the content you're extracting is of an illegal nature, there's nothing wrong with aggregating content. If you're interested in a more detailed answer, explore our piece on ethical web scraping.
How can I profit from building an online aggregator?
The pros of cherry-picking and displaying already-made content are not always self-evident. Here are just a few of them:
1. Content curation only
You don't need to create content for an online aggregator. You just have to collect and curate it. For landing page content, you can use an AI copywriter.
2. Low maintenance and convenience
Once you've set up a base for an aggregator (we'll show you how to do that in the last part), it automatically collects the content and keeps it up-to-date without much involvement from your side.
3. Flexible layouts
It's up to you how you organize content on your webpage. Which web resource should take the centerpiece, how interactive the aggregator should be, how much information to display, and how often to refresh it - these are just a few ways you can decide how to customize the layout. You can also streamline your design process by starting with ready-made website templates, saving time while maintaining a polished look.
4. Staying relevant
Relevancy is an unspoken online currency these days. Therefore a website presenting only the freshest news, prices, opinions, and discussions can gather a lot of engaged and appreciative readers. Review aggregators need both relevance and authenticity. Verified reviews help filter out fake feedback and strengthen trust.
5. Growing your own platform
Nurturing an audience, creating a community, encouraging interest, deepening expertise, and fostering loyalty are benefits of having an aggregator platform that brings value. If digital citizens can find, connect, and sense value in what you're cherry-picking for them, your aggregator is bound to become a great base for your own content platform.
There are also several reasons why online aggregators are so popular. Price comparison aggregators can be especially useful for e-commerce businesses looking to compare product demand, pricing trends, and competitive gaps before choosing what to sell online. Website visitors prefer an aggregator because it lets them zero in on the content that fits their personal reading style and interests. It saves them time, energy, and effort. Content creators use content aggregation to give visibility to their works and grow their audiences. Digital marketers get a chance to promote their products, discover new inspirations, and study demand and engagement.
 Theo Vasilis
Theo Vasilis
How to build an aggregator website?
It's not simple, but it's easier than you might think, even if you've never built an aggregator website before. You will need 4 things: a web scraper to extract data from news sites, storage for your dataset, an API connection, and a website for output. Here's how you can create a website aggregator in 10 simple steps:
Step 1. Choose the websites to feed your aggregator
It can be a news website, a social media platform, a trading platform - anything. For the sake of simplicity, we'll be making a news aggregator. In our Store, among many other data extraction tools, we also have a free tool to get data from news pages called Smart Article Extractor. It can scrape any news website, and you'll only have to set it up once. Afterward, the process of enriching your website will be automatic and will loop for as long as you want. So hit Try for free, and let's head over to the Apify platform.
Step 2. Define the data format
Usually, one piece of news content will consist of a title, article link, date, and (optionally) an image. Smart Article Extractor can deliver the news datasets in a format that's easy to feed to your aggregator. So you can consider this part done if you use our tool. Note that for convenience, it's important to stick to one output format for all scraped news websites (e.g., JSON).
Step 3. Scrape the news into a dataset
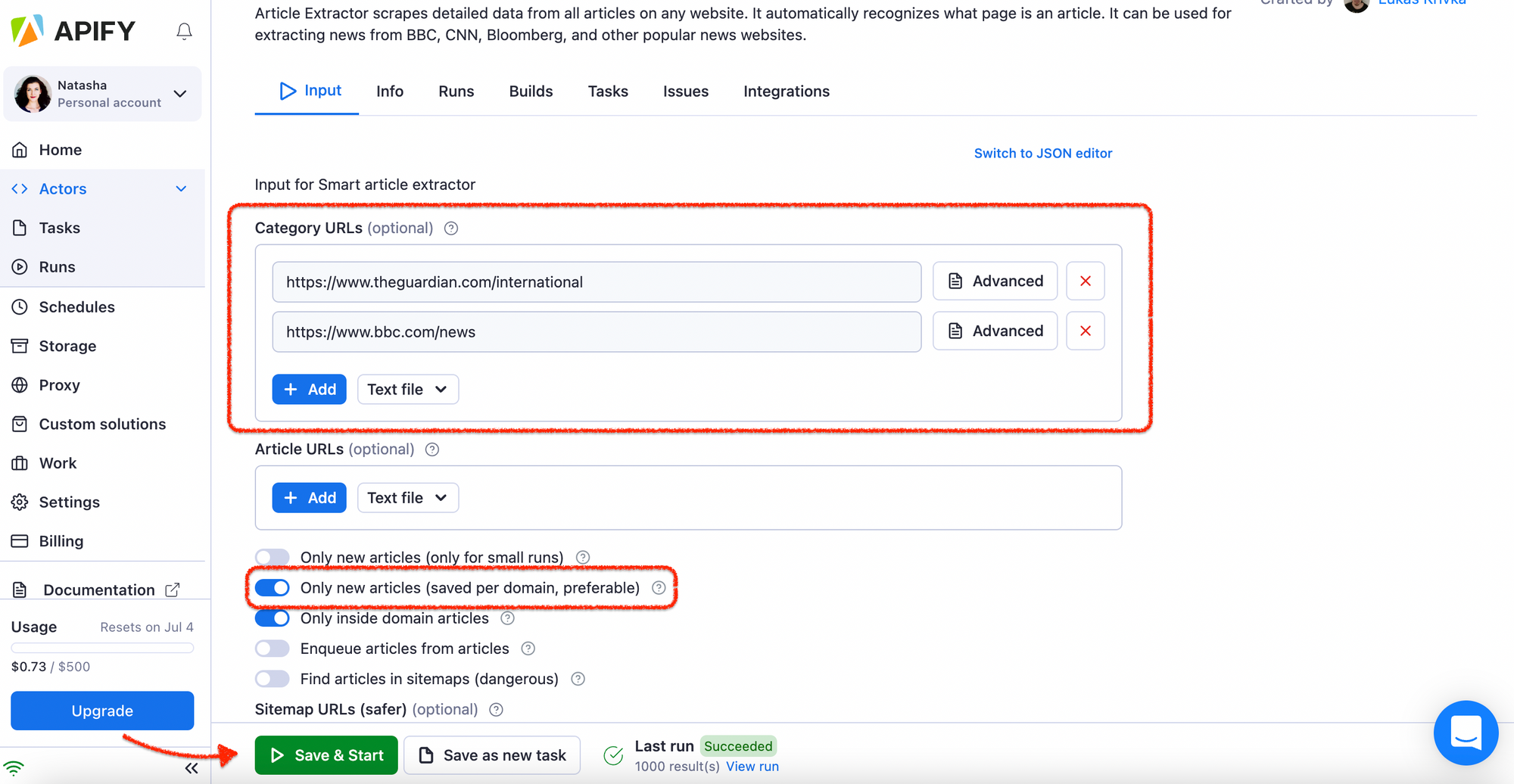
Open the Smart Article Extractor and fill up the fields with websites you want to populate your aggregator with, e.g., theguardian.com, bbc.com. Don't forget to have the toggle Only new articles (saved per domain) on and hit Save & Start. The rest of the fields are negligible for our case so don't worry about them.
Step 4. Have a single dataset for all scraped data
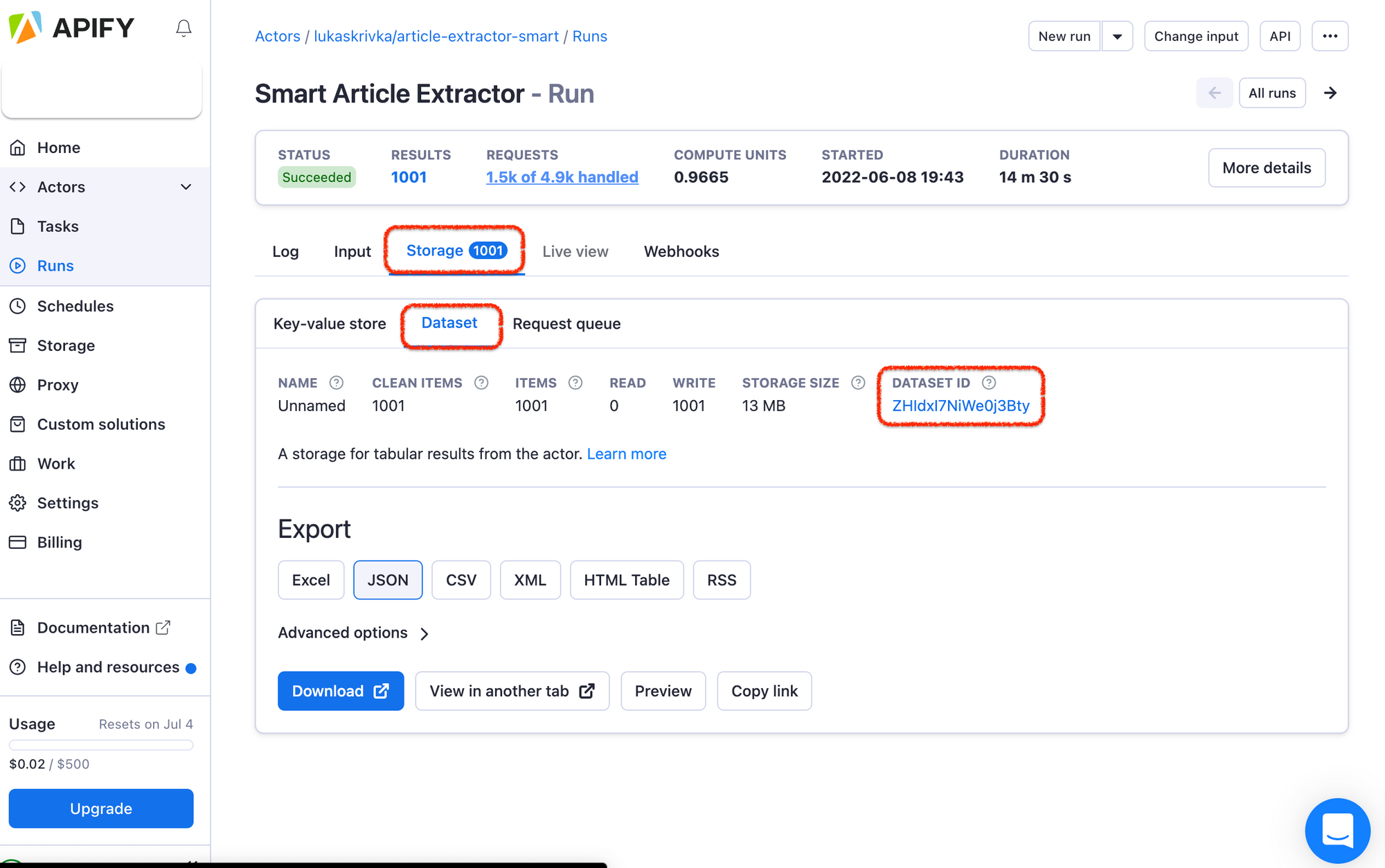
You can have many approaches to storing scraped news data. For instance, have separate datasets for The Guardian and BBC News. Or create a new dataset every time you scrape. But in our case, it's better to keep a single one and just gradually enrich it with more and more news. You don't have to worry about the size of your news dataset. Yes, it will be growing all the time, but the Apify platform can deal with large datasets without any issues. All you need to pay attention to is your dataset ID and remember where to find it.
Step 5. Decide where to store your dataset
It's convenient to have a centralized repository to store your dataset. Luckily, besides web scraping, the Apify platform where the Article Extractor is stored can also serve as simple storage for the time being. You can create bigger, separate storage or even a database later on, but for now, we'll rely on the Apify platform. No actions are taken on this step, just a little note that you don't have to download the dataset once you've got it.
Step 6. Give your dataset a name
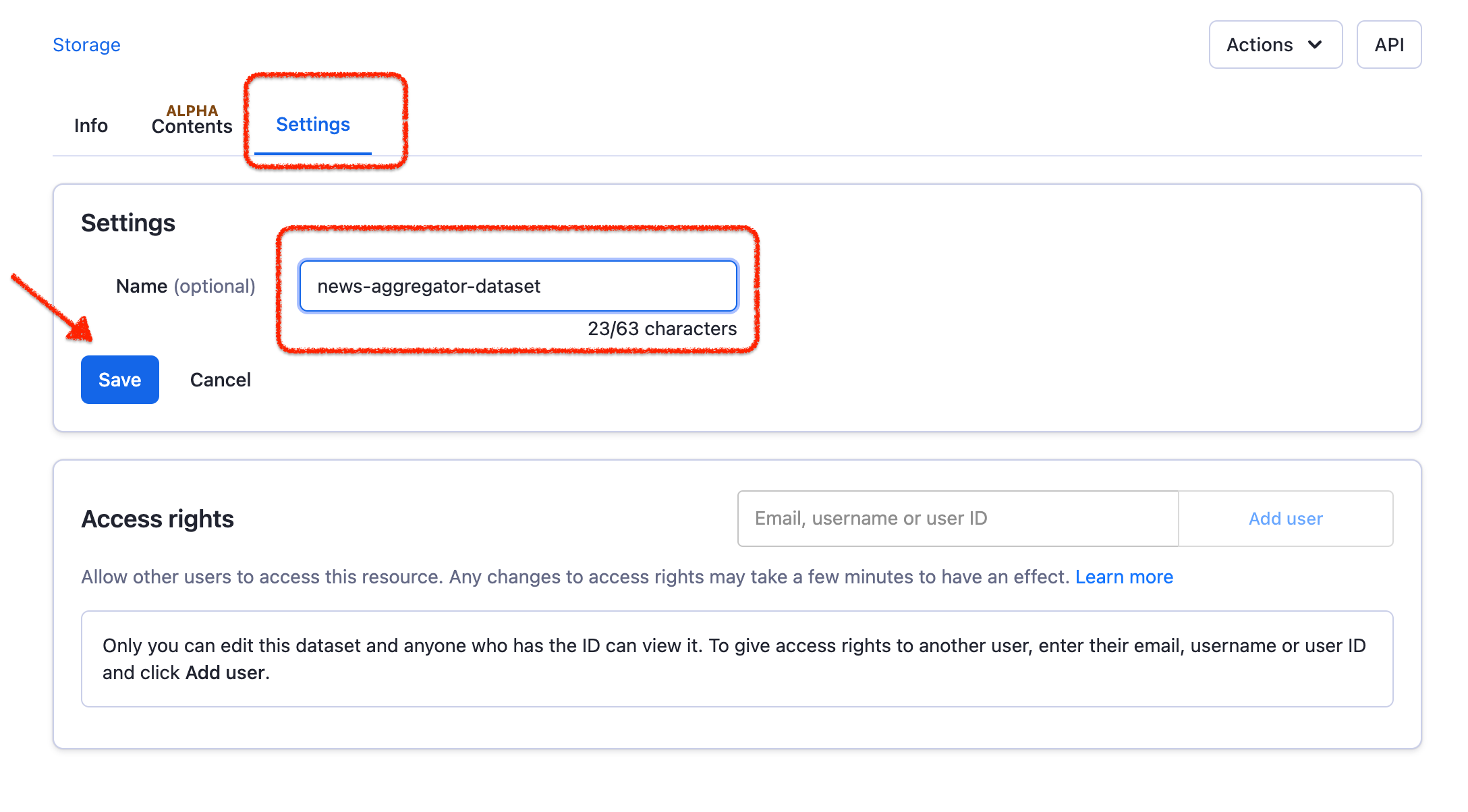
The dataset you've just created is a temporary one, it will get deleted after a few days. To keep it safe & sound on the platform, all you need to do is to give it a name. Click on your Dataset ID, then Settings, enter the new name, and hit the Save button.
Step 7. Make sure that the data stays in one place
Now that you've had your first go at scraping news and have a dataset on your hands, it's time for a few technicalities. You have to make sure that the next time the Smart Article Extractor scrapes the news, it adds the new results to the same dataset. To make this happen, you need a little helper called Dataset Appender. You will only set it up once and it needs only one thing: the name of your dataset.
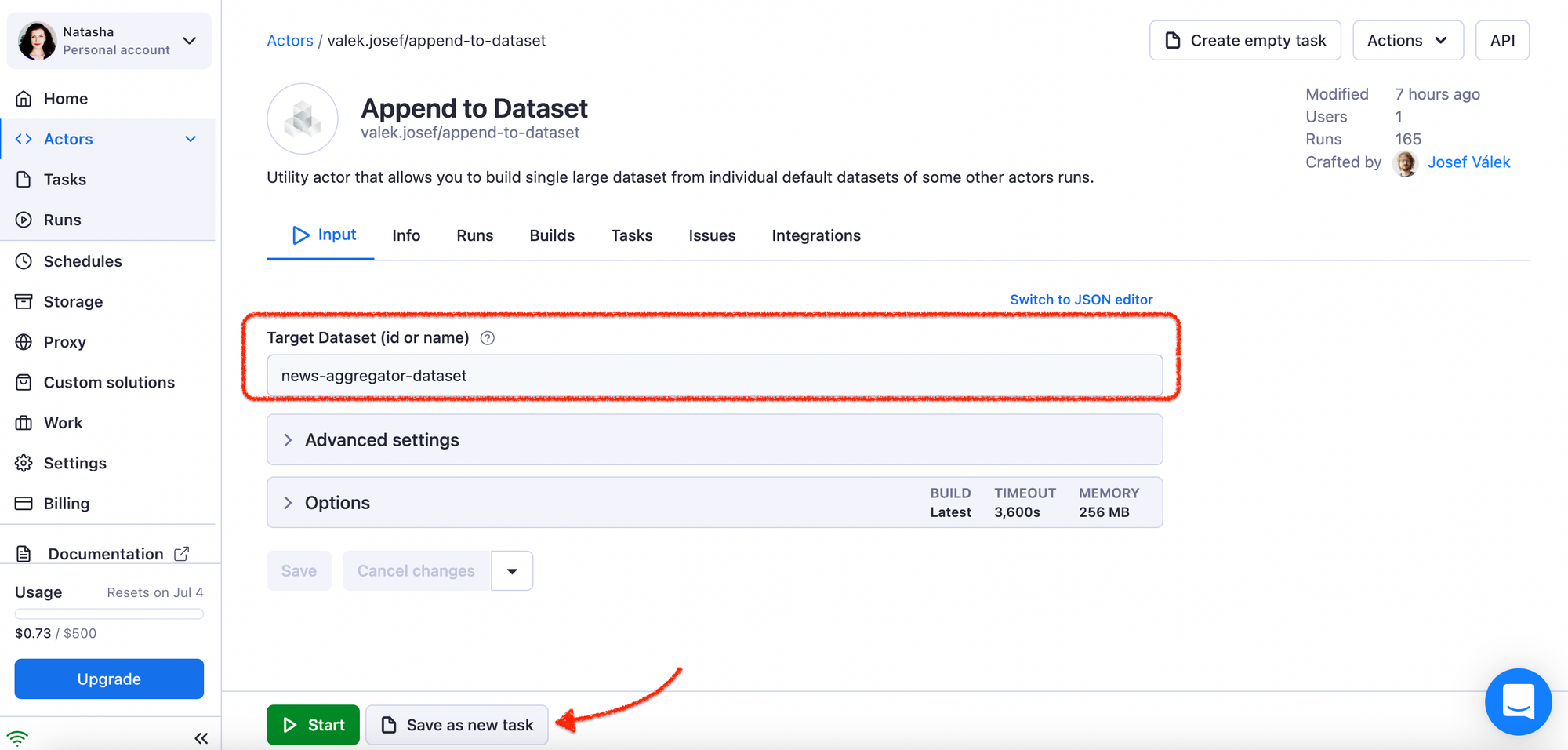
Now you have to connect the Appender to your Smart Article Extractor. You will do it via a webhook, which needs an API endpoint (Run task). But where do you get the endpoint?
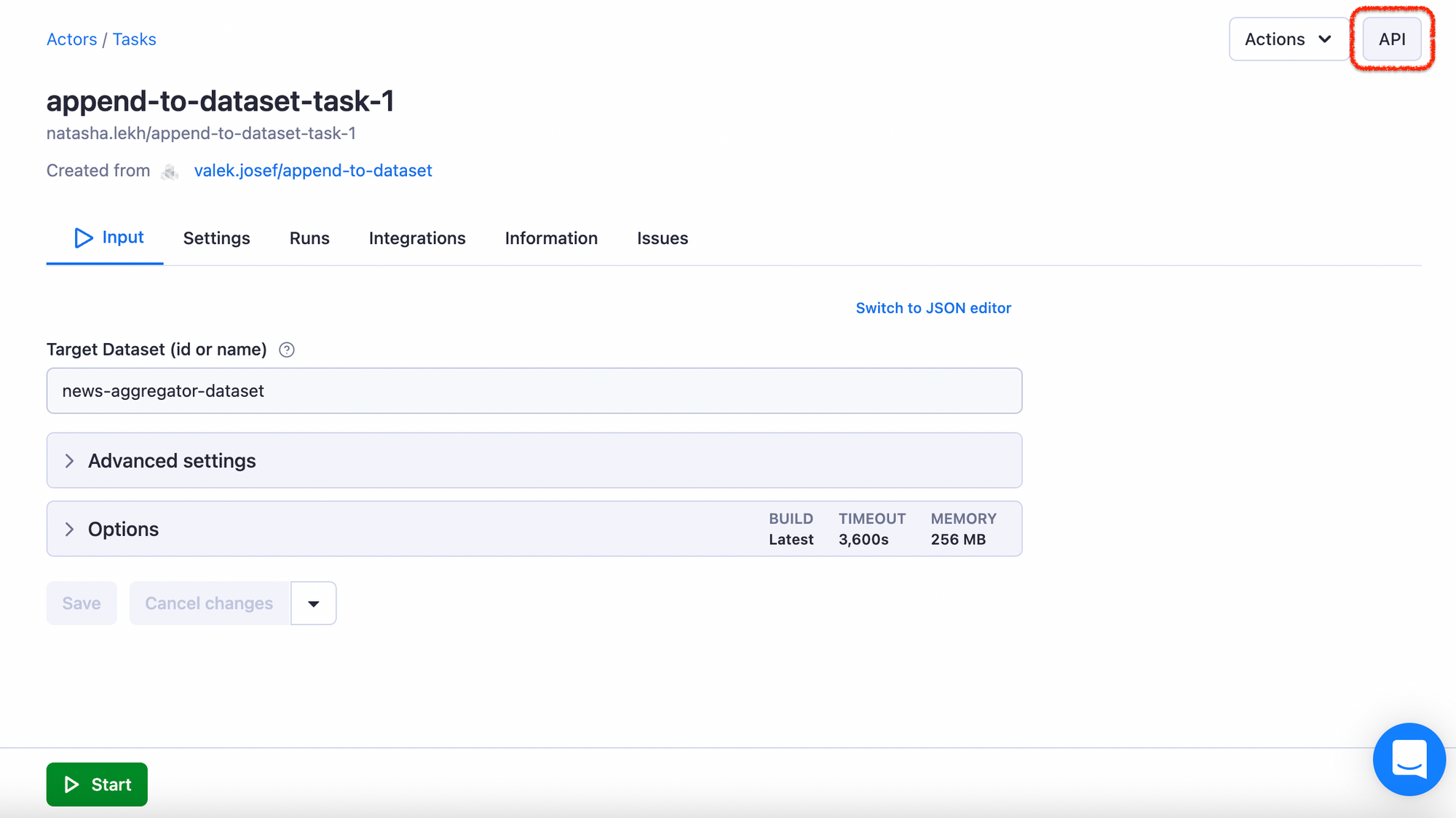
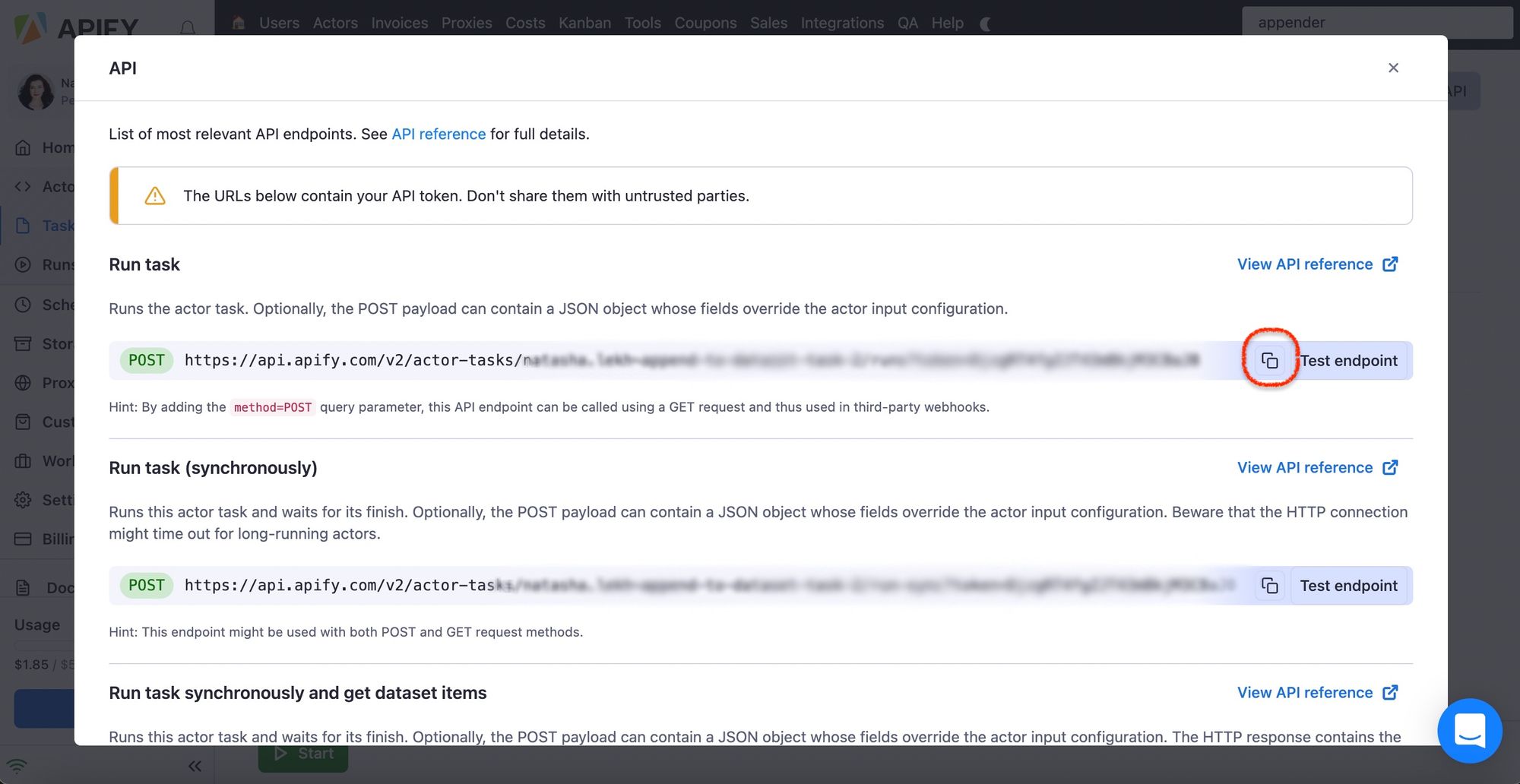
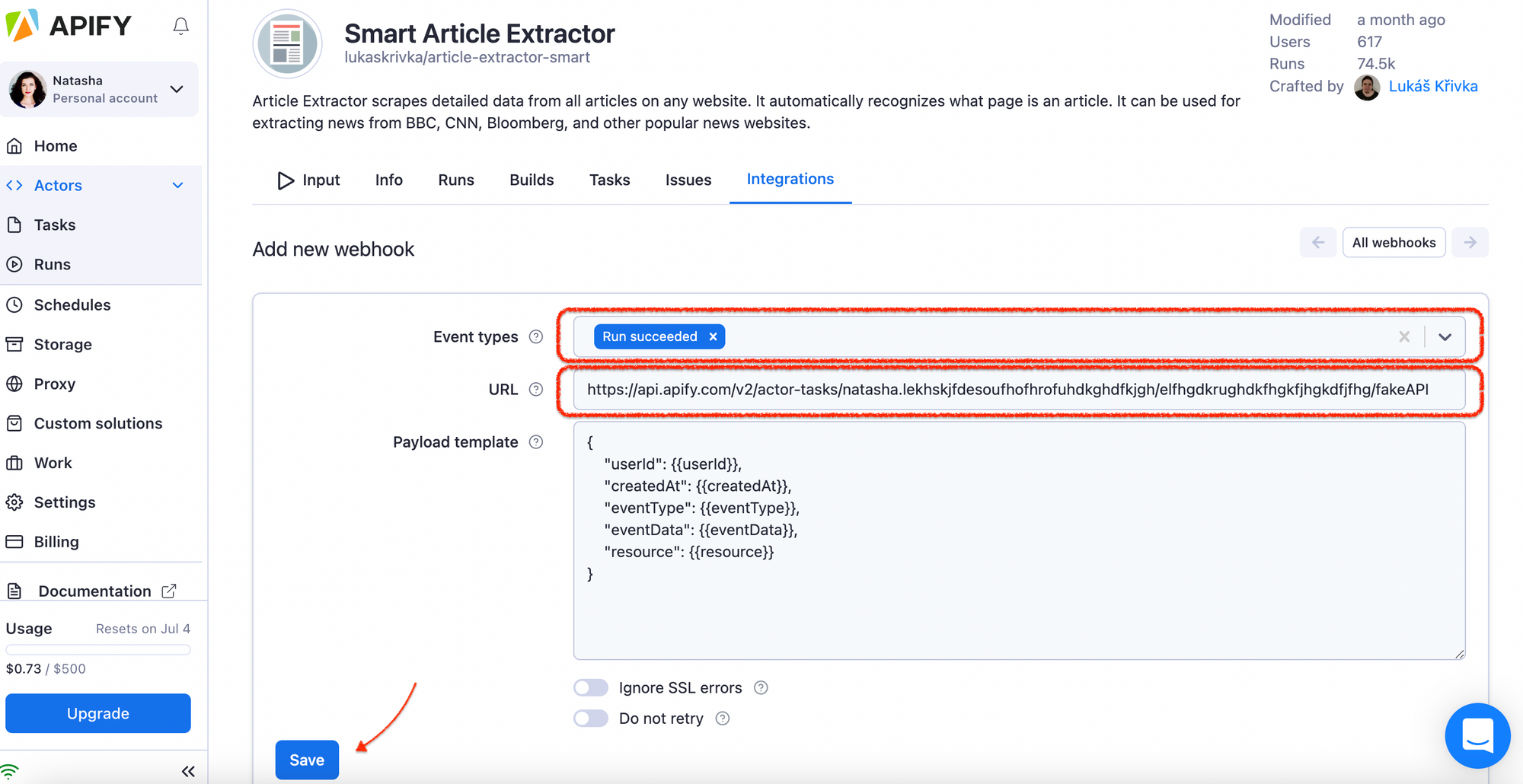
Step 7. Schedule the scraper
Forget about the Appender forever now; time to schedule your Article Extractor to run without your involvement. What will it be, every day, hour, a week? You can pick your scheduling settings in this tab.
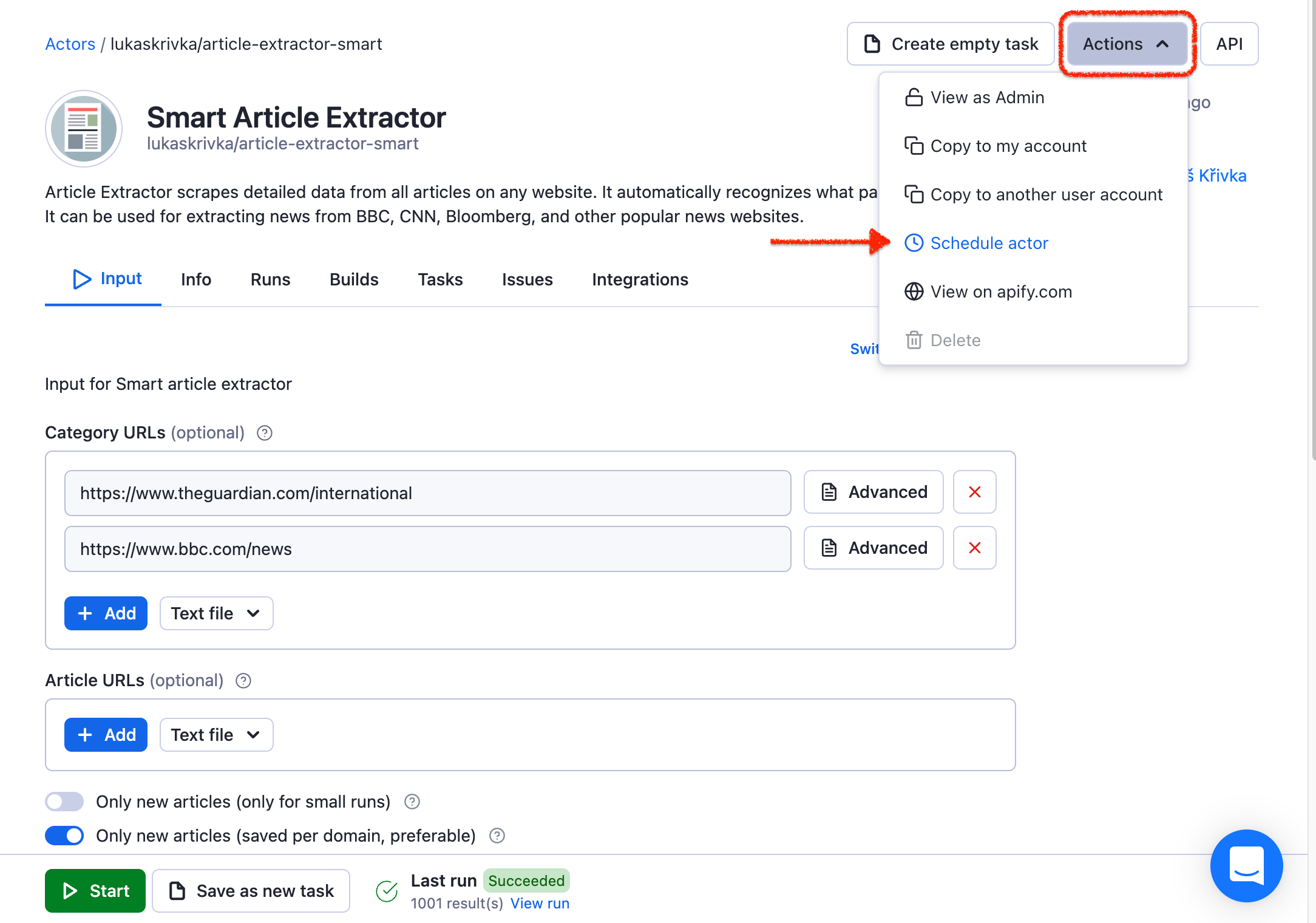
Step 8. Download the boilerplate web page
For that one, you'll have to head over to this GitHub repository. It contains the code for a simple website built from scratch, with no strong backend. Clone the code, install the dependencies of the code (npm install), and change the dataset ID in a specific file (all steps are described in the readme). This is how you will have an aggregator website run locally.
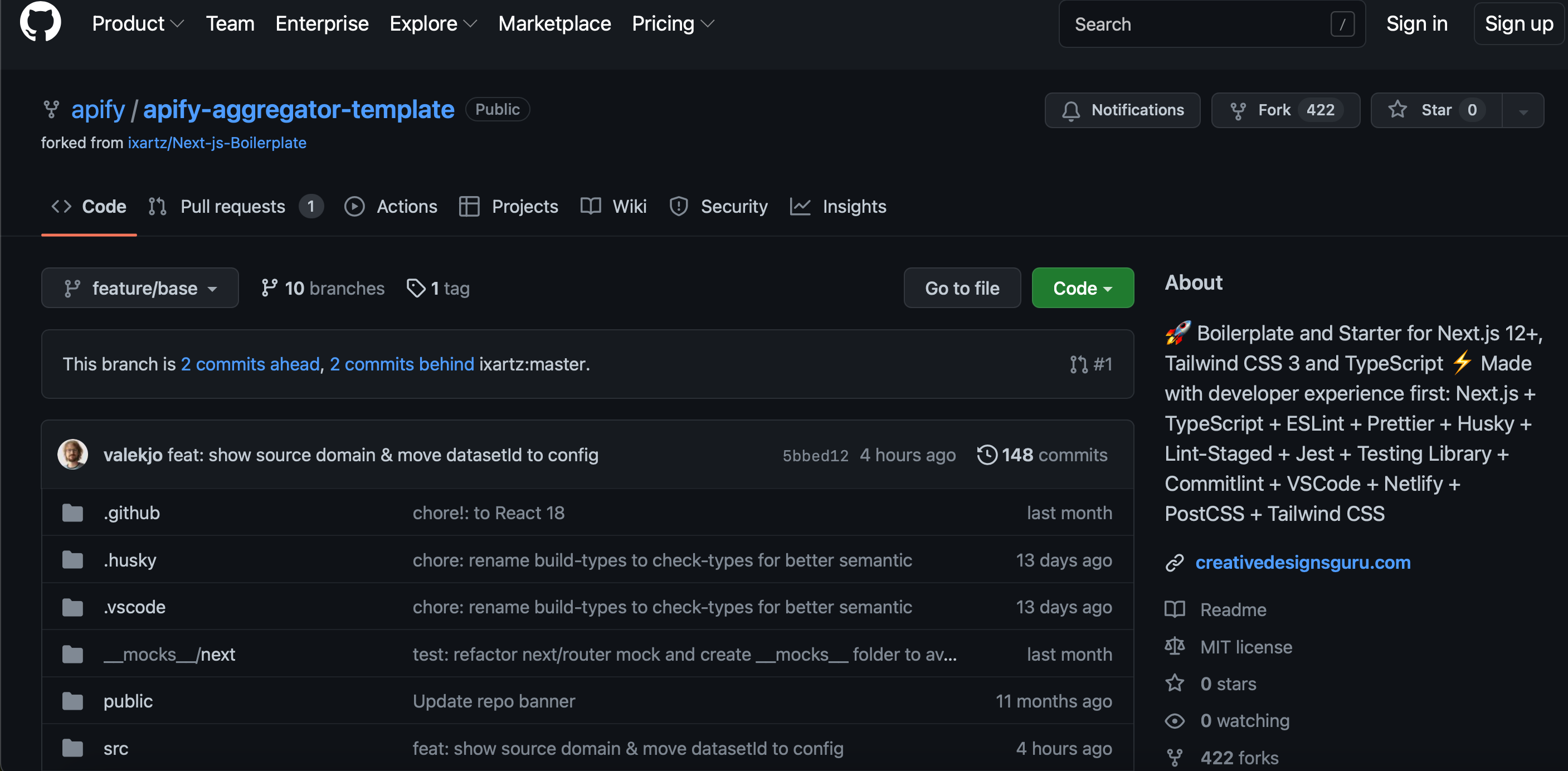
Step 9. Transfer the dataset onto your web page
This step is a part of the website boilerplate. The only thing you need to do here is to insert your dataset ID in the boilerplate. You will only have to insert it once, and as soon as you do this, your aggregator is basically set up and running!
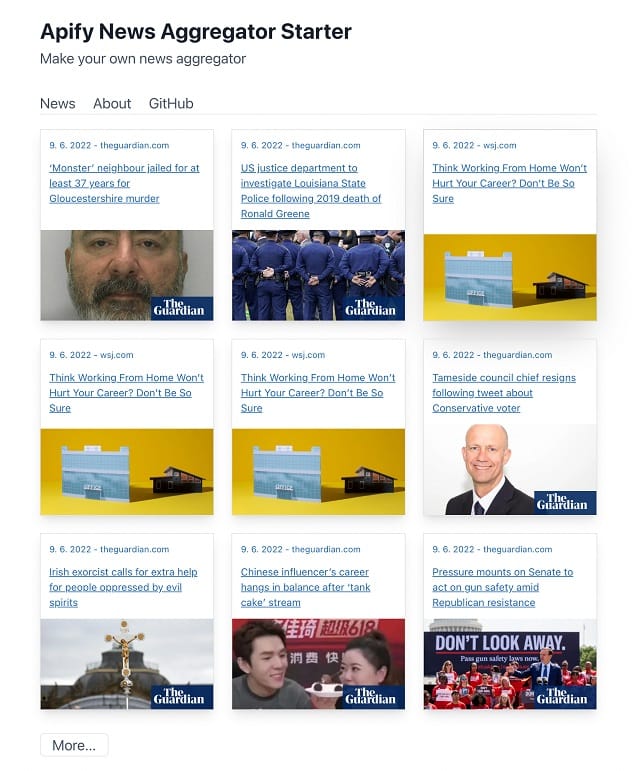
Step 10. No need to repeat all this
You can add new news sources to the Article Extractor or delete the ones you chose before, but the rest of the process should be automatic now. Every time the Smart Article Extractor scrapes the news from BBC and The Guardian, it will trigger the Dataset Appender to add the news to a common dataset and then push it to your aggregator website via an API. So this all depends on how often you've scheduled your Smart Article Extractor to run.
Here's an example of an online aggregator made a few years back. It's a real estate aggregator that was widely successful at the time. It was complex as it involved 2 crawlers, 20 website sources, and its own database to store datasets, but essentially, it was built following similar steps described above. It was scheduled to run every two days to scrape all real estate listings and keep the entire database up to date. And even that didn't take longer than 2 weeks to set up.
So fair winds and following seas in building your own aggregator! With just a few free automation tools and a platform for storage at your disposal, it should be an easy-to-launch project.




