


What is emotion detection in AI?
Emotion detection using multinomial logistic regression is a method of predicting emotions from input features in machine learning. Teaching machines this skill is challenging. They need practice with diverse examples to predict emotions accurately due to their complexity.
Emotion detection from text is crucial in natural language processing. It serves various purposes, from analyzing sentiment to understanding customer feedback.
A significant application of emotion detection is recommendation systems. By comprehending user emotions through their feedback, we can suggest similar items to users. This enhances user experience and personalization, making recommendations more relevant and aligned with user preferences.
In order to train machines to detect emotions indeed requires labeled data for training purposes. In this tutorial, we'll utilize reviews from the IMDb website to train our model. IMDb is an online website containing comprehensive details regarding films, television programs, actors, and individuals within the entertainment industry. It's a popular source for film details, ratings, reviews, and other related content.
What is multinomial logistic regression?
Multinomial logistic regression is a statistical method in the field of AI used for classification to solve multiclass possible outcome problems. Here's an example:
Imagine you're working at a wildlife research center; your task is to classify animals into three categories: Birds, Mammals, and Reptiles, based on their characteristics. Data is collected on various animals, including two independent variables: body temperature , and number of legs. These variables serve as the basis for classifying animals into the three categories.
The classification problem revolves around predicting whether an animal belongs to the Birds, Mammals, or Reptiles category, depending on its body temperature and the number of legs. Multinomial logistic regression is helpful because it allows us to group animals into different categories based on their traits.
In this tutorial, however, we're going to do something quite different. We'll delve deep into multinomial logistic regression using real-world IMDb movie data that we'll collect by developing a web scraping tool to extract reviews.
Web scraping IMDb for multinomial linguistic regression
Extract IMBb movie reviews
Step 1: Data collection
We must install the following packages that facilitate web scraping IMDb data.
pip install beautifulsoup4 selenium webdriver-manager pandas nltk
Next, we need to import several libraries into our Python file.
import csv # Handles CSV file operations for reading and writing.
import time # Manages delays and waits for specific conditions.
import numpy as np # Supports numerical computations.
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium import webdriver # Automates web interactions and testing
from webdriver_manager.chrome import ChromeDriverManager # Facilitate Chrome WebDriver download and management.
from selenium.webdriver.common.by import By #Locates HTML elements on web pages.
from selenium.webdriver.chrome.service import Service # Facilitate Chrome WebDriver download and management.
In this article, we'll focus on scraping user reviews for the movie Captain Marvel from the IMDb website. Once the environment is configured, it's important to identify where the desired reviews are situated on the IMDb website for scraping. To accomplish this, right-click on the page and choose the inspect element to examine the IMDb review page structure.
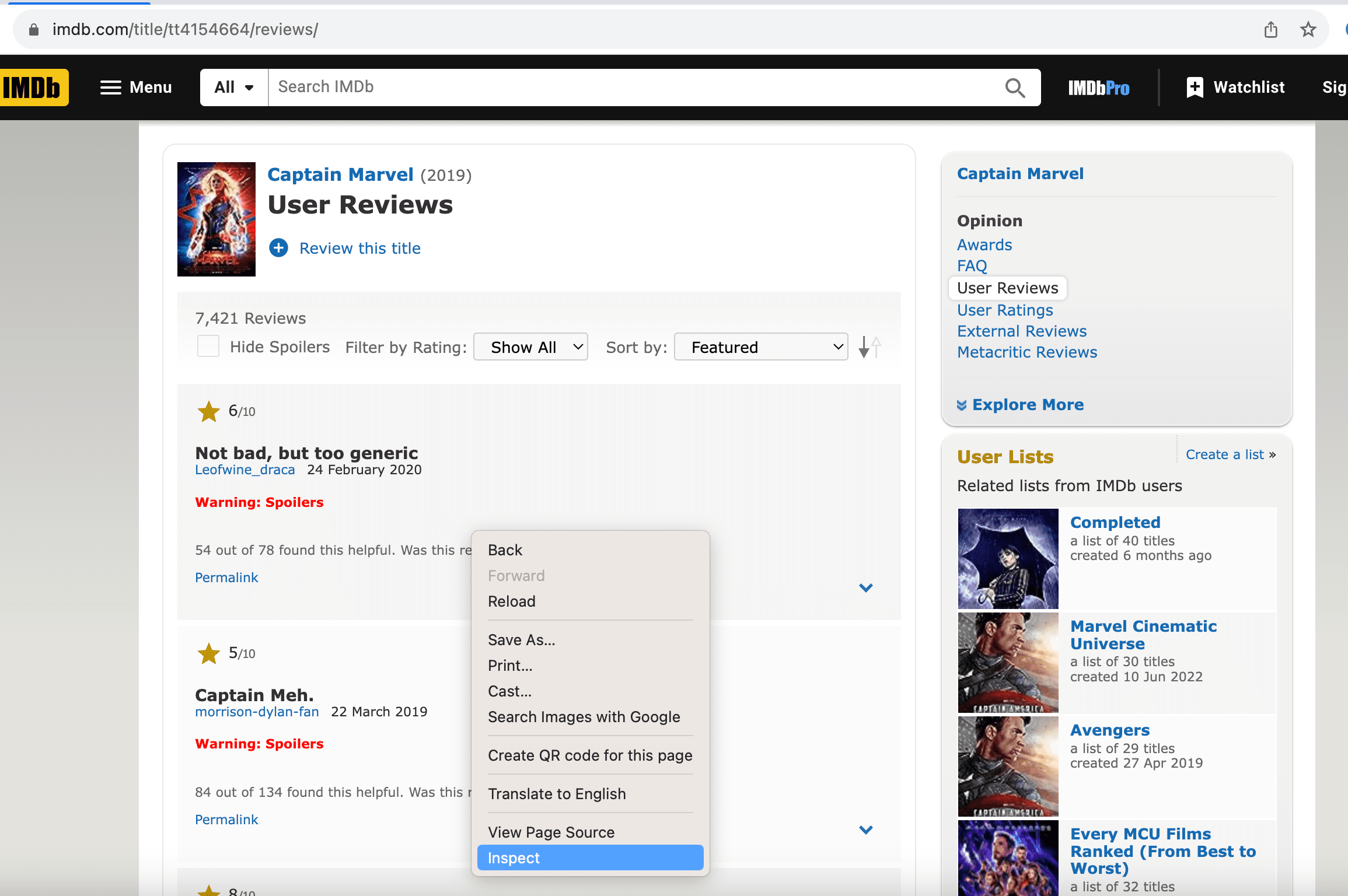
Inspect element opens your browser’s developer tools, letting you examine a webpage's HTML and CSS code. This page shows that all user reviews are consistently present in the <div> element having "text show-more__control" class.
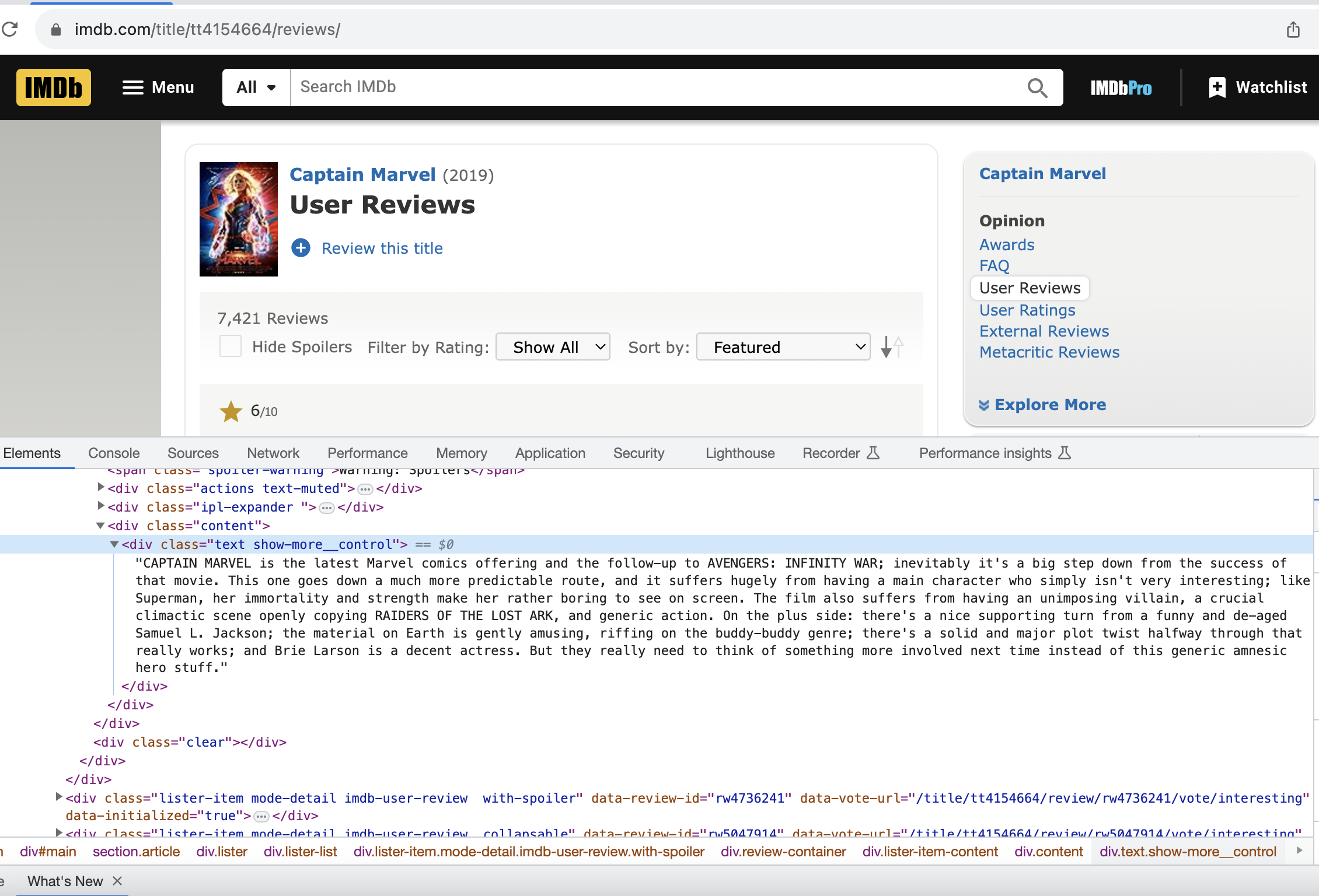
Not all user reviews on the IMDb user review page are displayed immediately. You need to click the "Load More" button to reveal additional reviews. You can locate the "Load More" button at the page's lower section. On inspecting the page, you'll notice that the ID load-more-trigger identifies this button. With this ID, you can employ a Python script to programmatically automate the process of clicking this button.
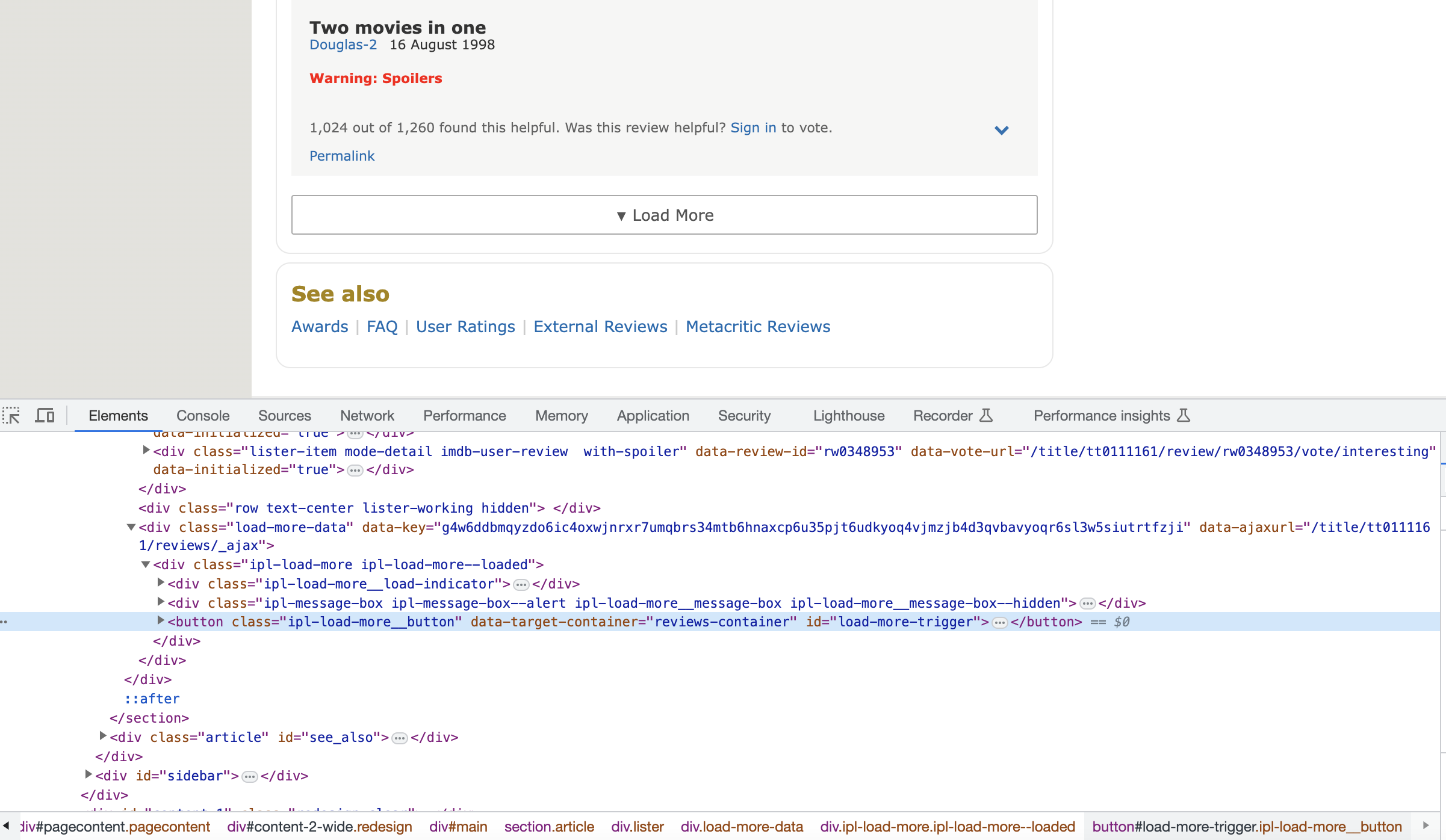
1) repeatedly clicking a button to load all reviews,
2) extracting reviews and ratings from the HTML (a potentially time-consuming task), and finally,
3) saving the extracted data to a file.
Executing this process can be quite time-consuming, so running the code requires patience.
Below is the full code for extracting reviews from the IMDb website:
# Import libraries
import csv
import time
import numpy as np
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# Declare some variables
small_delay = 5
review_button_exists = True
csv_file_path = 'imdb_user_reviews.csv'
imdb_movie_link = "https://www.imdb.com/title/tt4154664/reviews/"
# Install chrome driver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
driver.get(imdb_movie_link)
# Load all the reviews of the movie by clicking the button
while review_button_exists:
try:
load_more_reviews = WebDriverWait(driver, small_delay).until(EC.element_to_be_clickable((By.ID, 'load-more-trigger')))
load_more_reviews.click()
time.sleep(2)
except:
review_button_exists = False
all_movie_reviews = WebDriverWait(driver,small_delay).until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="lister-item-content"]')))
all_reviews = []
# Extract IMDB reviews and rating
for review in all_movie_reviews:
try:
imdb_rating = review.find_element(By.XPATH,'.//div[@class="ipl-ratings-bar"]').text
imdb_rating = imdb_rating.replace("/10", "")
except:
imdb_rating = np.nan
try:
review = review.find_element(By.XPATH,'.//div[@class="text show-more__control"]').text
except:
review = review.find_element(By.XPATH,'.//div[@class="content"]').text
full_review = {
"Rating" : imdb_rating,
"Review" : review
}
all_reviews.append(full_review)
# Write the reviews and rating in csv file
with open(csv_file_path, mode='w', newline='', encoding='utf-8') as file:
writer = csv.DictWriter(file, fieldnames=["Rating", "Review"])
writer.writeheader()
for full in all_reviews:
writer.writerow(full)
driver.quit()
In the above, we extracted reviews and ratings from the IMDb website using selenium and XPath and saved them in imdb_user_reviews.csv.
Labeling techniques
At this stage, the dataset is unlabeled, but we need labeled data for the machine learning algorithm. There are several ways to label a dataset, depending on the nature of the data and the goals of your analysis. Here are some common approaches:
- Manual labeling: Assign labels to data points manually.
- Rule-based labeling: Use predefined rules or criteria for assigning labels to data.
- Domain expert labeling: Involve domain experts with deep knowledge of the subject matter to label the data.
- Active learning: Combine manual labeling with machine learning.
- Weak supervision: Generates noisy labels using rules or domain knowledge to be iteratively refined and improved through various techniques.
Labeling the dataset
The dataset extracted from the IMDb website comprises 6,374 reviews. We'll employ a combination of weak supervision and manual labeling techniques for assigning labels. In the weak supervision phase, we create two rules based on the rating:
Rule 1: Assign the Happy emotion to reviews with a rating greater than 8.
Rule 2: Assign the Angry emotion to reviews with a rating less than 4.
The remaining reviews remain unlabeled. Subsequently, we perform manual labeling by reading and assigning Happy and Angry labels to the reviews.
Step 2: Data preprocessing
The data extracted from the IMDb website requires preprocessing due to irrelevant elements such as HTML tags, stop words, null values, duplicate reviews, special characters, and stop words.
Importing the dataset
import pandas as pd
url = "./imdb_user_reviews.csv"
imdb_data=pd.read_csv(url)
imdb_data.head()
# Output
# Rating Reviews Emotion
# 0 8.0 I had low expectations going to see this movie... Happy
# 1 9.0 Movie was really well done, been collecting co... Happy
# 2 9.0 Great movie. You don't need a strong villain. ... Happy
# 3 9.0 After finally discovering who she is Vers/ Car... Happy
# 4 9.0 I am not one to usually write reviews, but I f... Happy
Dataset descriptive statistics
imdb_data.info()
# Output
# Data columns (total 3 columns):
# # Column Non-Null Count Dtype
# --- ------ -------------- -----
# 0 Rating 6269 float64
# 1 Reviews 6374 object
# 2 Emotion 6374 object
From these statistics, it's evident that the movie has a total of 6,374 reviews, each associated with specific emotions (Happy, Angry).
Let's calculate the frequency of emotions within the dataset.
imdb_data['Emotion'].value_counts()
# Output
# Happy 3903
# Angry 2471
The provided output indicates that 3,903 users were happy after watching this movie, while 2,471 users were angry.
Identifying and removing duplicate reviews
Our dataset may contain duplicate reviews. To ensure effective machine training, it's crucial that we identify and eliminate these duplicate entries from the dataset.
num_duplicates = imdb_data.duplicated().sum() #identify duplicates
print('Duplicate reviews = {}'.format(num_duplicates))
# Duplicate reviews = 7
# Removing Duplicate reviews
review = imdb_data['Reviews']
duplicated_review = imdb_data[review.isin(review[review.duplicated()])].sort_values("Reviews")
duplicated_review.head()
imdb_data.drop_duplicates(inplace = True)
Dataset cleaning
The dataset we scraped includes a substantial amount of irrelevant content, such as stopwords, HTML tags, emoticons, parentheses, and special characters. Our objective is to eliminate these elements from the dataset.
import nltk
import re
from bs4 import BeautifulSoup
from nltk.corpus import stopwords
from nltk.tokenize import ToktokTokenizer
stopWords = set(stopwords.words('english'))
tokenizer=ToktokTokenizer()
listOfStopword=nltk.corpus.stopwords.words('english')
# Printing the set of English stopwords
print(stopWords)
# Function to remove square brackets and their contents
def removeSquareBrackets(htmlText):
return re.sub(r'\\[[^]]*\\]', '', htmlText)
# Function to remove special characters (with an option to remove digits)
def removeSpecialCharacters(htmlText, removeDigits=True):
specialCharacterPattern = r'[^a-zA-Z0-9\\s]'
cleanedText = re.sub(specialCharacterPattern, '', htmlText)
return cleanedText
# Function to remove HTML tags from text
def removeHtmlTags(htmlText):
htmlFreeWord = BeautifulSoup(htmlText, "html.parser")
return htmlFreeWord.get_text()
# Text stemming using Porter Stemmer
def performTextStemming(htmlText):
ps = nltk.porter.PorterStemmer()
stemmedText = ' '.join([ps.stem(word) for word in htmlText.split()])
return stemmedText
# Function to remove stopwords
def removeStopwords(htmlText, isLowerCase=False):
wordTokens = tokenizer.tokenize(htmlText)
wordTokens = [token.strip() for token in wordTokens]
if isLowerCase:
token_filterization = [token for token in wordTokens if token not in listOfStopword]
else:
token_filterization = [token for token in wordTokens if token.lower() not in listOfStopword]
textAfterRemovingStopWord = ' '.join(token_filterization)
return textAfterRemovingStopWord
# Function to remove emoticons
def removeEmoticons(text):
emoticonPattern = r'(:-?[\\)\\(DPO])|(;\\'-?[\\)\\(DPO])'
textWithoutEmoticons = re.sub(emoticonPattern, '', text)
return textWithoutEmoticons
# Function for data cleaning
def performDataCleaning(text):
text = removeHtmlTags(text)
text = removeSquareBrackets(text)
text = removeSpecialCharacters(text)
text = performTextStemming(text)
text = removeStopwords(text)
text = removeEmoticons(text)
return text
# Applying data cleaning function to the 'Reviews' column in the 'imdbData' DataFrame
imdb_data['Reviews'] = imdb_data['Reviews'].apply(performDataCleaning)
Step 3: Dataset modeling
At this point, our dataset has been thoroughly cleaned and is prepared for the modeling phase. In this phase, we split the data into testing and training. We have partitioned the dataset, allocating 80% for training and 20% for testing, with a random division facilitated by the random_state = 42.
from sklearn.model_selection import train_test_split
reviews = imdb_data['Reviews']
emotion = imdb_data['Emotion']
review_training_set, review_testing_set, emotion_training_set, emotion_testing_set = train_test_split(reviews, emotion, test_size=0.2, random_state=42)
print(review_training_set.shape,emotion_training_set.shape)
print(review_testing_set.shape,emotion_testing_set.shape)
# Output
# (5099,) (5099,)
# (1275,) (1275,)
Step 4: Model training
In order to train the model, we need to convert the train and test dataset into Bag of Words and TF-IDF. Both approaches convert text datasets into numerical vectors.
Bag of Words model (BOW)
Bag of Words is a way to represent a text by counting the frequency of each word in it without considering the word order. It’s called a bagbecause it's like throwing all the words into a bag. You only care about what words are in the bag and how many times each word appears, not their arrangement.
from sklearn.feature_extraction.text import CountVectorizer
#Bag of words vectorizer
vector_for_bag_of_word=CountVectorizer(min_df=0.0,max_df=1.0,binary=False,ngram_range=(1,3))
# Train reviews transformation
train_reviews_bag_of_word_vector=vector_for_bag_of_word.fit_transform(review_training_set)
# Test reviews transformation
test_reviews_bag_of_word_vector=vector_for_bag_of_word.transform(review_testing_set)
print('train_reviews_bag_of_word_vector:',train_reviews_bag_of_word_vector.shape)
print('test_reviews_bag_of_word_vector:',test_reviews_bag_of_word_vector.shape)
#output
# train_reviews_bag_of_word_vector: (5093, 407268)
# test_reviews_bag_of_word_vector: (1274, 407268)
Term Frequency-Inverse Document Frequency(TF-IDF)
Term Frequency means how often a word appears in the document, and Inverse Document Frequency indicates whether the word is rare or common across all the documents. TF-IDF is therefore a method of determining the importance of a word in a document relative to an entire collection of documents. In this context, we refer to each review as a document.
from sklearn.feature_extraction.text import TfidfVectorizer
#Tfidf vectorizer
tfidf_vector=TfidfVectorizer(min_df=0.0,max_df=1.0,use_idf=True,ngram_range=(1,3))
#train reviews transformation
train_reviews_tfidf_vector=tfidf_vector.fit_transform(review_training_set)
#test reviews transformation
test_reviews_tfidf_vector=tfidf_vector.transform(review_testing_set)
print('Tfidf_train:',train_reviews_tfidf_vector.shape)
print('Tfidf_test:',test_reviews_tfidf_vector.shape)
# Output
# train_reviews_tfidf_vector: (5093, 407268)
# test_reviews_bag_of_word_vector: (1274, 407268)
Dataset modelling
Let's detect word mentions and test our dataset.
from sklearn.linear_model import LogisticRegression
#Setting up the model
multinomial=LogisticRegression(C=15, penalty='l2',solver='newton-cg',multi_class='multinomial', max_iter=10000)
#Training the model using Bag of words features.
multinomial_bow=multinomial.fit(train_reviews_bag_of_word_vector,emotion_training_set)
print(multinomial_bow)
#Predicting the model for Bag of words.
multinomial_bow_predict=multinomial.predict(test_reviews_bag_of_word_vector)
print(multinomial_bow_predict)
#Training the model using TF-IDF features.
multinomial_tfidf=multinomial.fit(train_reviews_tfidf_vector,emotion_training_set)
print(multinomial_tfidf)
#Predicting the model for tfidf features
multinomial_tfidf_predict=multinomial.predict(test_reviews_tfidf_vector)
print(multinomial_tfidf_predict)
Multinomial logistic regression parameters
Let's delve into a detailed examination of the parameters employed in multinomial logistic regression.
1. multi_class: Specifies the strategy for handling multiclass problems. Common options include:
'ovr'(One-vs-Rest): Treats each class as binary and builds a separate binary classification model for each class.'multinomial': Applies multinomial logistic regression, which directly models all classes together.'auto': Automatically selects either'ovr'or 'multinomial' based on the nature of the problem.
2. solver: Selects the algorithm used to optimize the logistic regression model. Common options include:
'newton-cg': Newton-Conjugate Gradient algorithm.'lbfgs': Limited-memory Broyden-Fletcher-Goldfarb-Shanno algorithm.'liblinear': Library for large linear classification (works well for small datasets).'sag': Stochastic Average Gradient Descent.'saga': Improved version of 'sag' with L1 regularization support.
3. C: The 'C' parameter represents the inverse of regularization strength.
- Smaller
'C'values mean stronger regularization, preventing overfitting. - Larger
'C'values allow the model to closely fit the training data.
4. penalty: Specifies the type of regularization to apply:
'l1': L1 regularization (Lasso) encourages sparsity.'l2': L2 regularization (Ridge) controls the size of coefficients.'elasticnet': Elastic-Net regularization - a combination of L1 and L2.
5. max_iter: Determines the solver's maximum iterations to reach a solution. Increase it if convergence isn't achieved within the default limit.
Step 5: Evaluate model performance
We use accuracy as a performance parameter. Accuracy is a metric that measures the overall correctness of a predictive model. It represents the ratio of correctly predicted instances to the total number of instances in the dataset. In mathematical terms, accuracy is calculated as:
$$ \text{Accuracy} = \frac{\text{Number of Correct Predictions}}{\text{Total Number of Predictions}} \times 100 $$
Accuracy score for Bag of Words:
from sklearn.metrics import accuracy_score
multinomial_bow_score=accuracy_score(emotion_testing_set,multinomial_bow_predict)
print("multinomial_bow_score :",multinomial_bow_score)
# multinomial_bow_score : 0.8618524332810047
Accuracy score for TF-IDF:
from sklearn.metrics import accuracy_score
multinomial_tfidf_score=accuracy_score(emotion_testing_set,multinomial_tfidf_predict)
print("multinomial_tfidf_score :",multinomial_tfidf_score)
# multinomial_tfidf_score : 0.8712715855572999
In terms of percentage, Bag of Words achieves an accuracy rate of 86%, while TF-IDF achieves a slightly higher accuracy of 87%.
There are many other factors that can improve the performance of the model, such as:
- High-quality data
- Model selection
- Regularization
- Handling missing data:
- Domain knowledge
- Error analysis
The effectiveness of these factors can vary depending on the specific problem and dataset, so it's essential to experiment and iterate to achieve the best results.
Summary
- We began with data collection by web scraping IMDb movie reviews and ratings.
- We then applied weak supervision and manual labeling techniques to assign labels to the data.
- After labeling, we performed data cleaning to remove irrelevant information.
- We then split the dataset into two categories: training and testing.
- After that, we transformed the dataset into vectors using Bag of Words and TF-IDF methods.
- Finally, we employed multinomial logistic regression on these vectors, fitting the model and assessing its performance using the accuracy metric.

Extract text content from the web to feed your vector databases and fine-tune or train large language models.




