



You might not face any issues when using your freshly made scraper to crawl smaller or less established websites. But when you try web scraping on websites with greater traffic, dynamically loading pages with JavaScript, or even Google, you start running into issues.
Your scraper might work a few times, only to later on have your requests blocked, receive authorization errors such as 403, or 1020 from Cloudflare, or even get your IP blocked and blacklisted. How to avoid these issues when scraping? Here are 21 technical and common-sense tips on how to crawl a website without getting blocked.

1. Respect the robots
First of all, always check robots.txt file before you start scraping to see the allowed and disallowed URLs. Every website has a robots.txt file; it contains the rules of behavior for bots and a list of all pages that are allowed to be visited by bots. If certain URLs are marked as off-limits, your crawler is not supposed to scrape them to avoid breaking copyright laws and getting blocked. Checking robots.txt is also a good rule of thumb to avoid getting trapped in honeypots and honeynets and also getting immediately blacklisted.
Here's how a good web crawler should work: first check the robots.txt file to learn the rules of behaving on the websites. Then, visit pages and follow all allowed links to find all available content. Finally, line up website URLs to scrape later. By following these steps and respecting robots.txt, you can scrape responsibly. However, it's important to note that while good bots adhere to these rules, bad bots may ignore them, as robots.txt rules are not legally enforceable.
2. Configure a real user agent
Browser headers tell websites all kinds of details about your browser and history. And humans tend to use browsers way more often than scrapers do. So perhaps the Number 1 rule to avoid being blocked while web scraping, is to imitate the way real users browse by setting up your HTTP headers correctly. This is because most websites use the right headers’ stack as proof that the visitor is human.
Making sure these headers match, especially the one called User-Agent, will help your scraper blend in smoothly without raising any red flags. The reason why user agent header one is so important is because it indicates the browser, device, and operating system of the user — and because it often gets outdated (see tip 3). If your other headers don't align with user agent, or if your user agent is outdated, this could raise suspicion from the website.
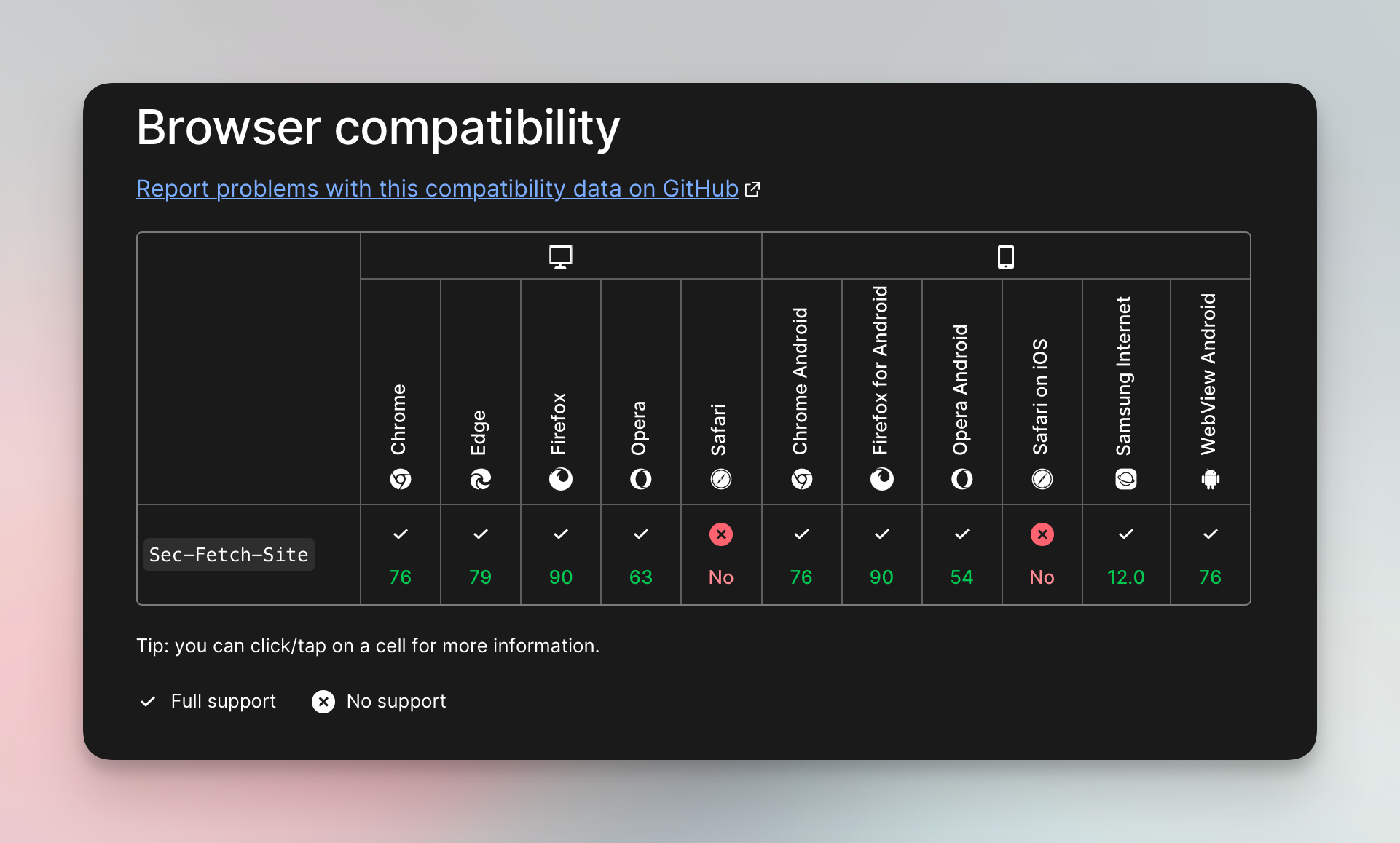
Maintaining consistency among headers will ensure that your crawler behaves like a genuine user reducing the risk of detection and blocking. To do this easily, you can use tools like Got Scraping, which automatically creates and manages these matching headers for you.
3. Update your request headers
By keeping your headers current, you ensure they match those of real users, reducing the likelihood of being flagged. For example, an outdated header might include a user agent like Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36, which corresponds to an old version of Google Chrome and could raise suspicion. Therefore, regularly updating your request headers is essential for successful and uninterrupted web scraping.
4. Set a Referer
In addition to the user agent, another important HTTP header to consider when scraping is the Referer (yes, with one “r”, it’s an ages old bug). This header indicates the URL of the website that led to the current page, providing valuable context for the server. For example, if you're scraping data from amazon.de, having a Referer header matching google.de suggests an organic visit, which can help your scraper appear more genuine.
To further enhance authenticity and avoid detection, you can match the entire Referer URL with a proxy from the corresponding country, such as Germany. Alternatively, common Referers from social media platforms like Facebook or Twitter can also be used to simulate organic traffic and reduce the risk of being blocked. Incorporating the Referer header into your scraping strategy adds an extra layer of realism which will help your scraper navigate websites smoothly and minimize the chances of detection.
5. Use a proxy server
Another challenge with scraping websites is hitting request limits. These limits, originally meant to stop DDoS attacks, also stop web scraping attempts. So to get you covered against those limits, you will need to use a reliable proxy service. Switching proxies for each request will help your crawler act more like a human user, making it less likely to get blocked.
When picking a proxy provider, you'll have to consider how good their anti-blocking is and how much you can spend. Cheaper data center proxies might get blocked more, while mobile or residential ones cost more but are stealthier. Specialist providers like IPRoyal, Bright Data, and Smartproxy each focus on different price/quality tradeoffs across these proxy types. Whichever you choose, make sure to switch proxies automatically to stay safe. Also, good practice is to match the proxy location to the website you're scraping and avoid using IPs that are following in order, or else ⬇️.
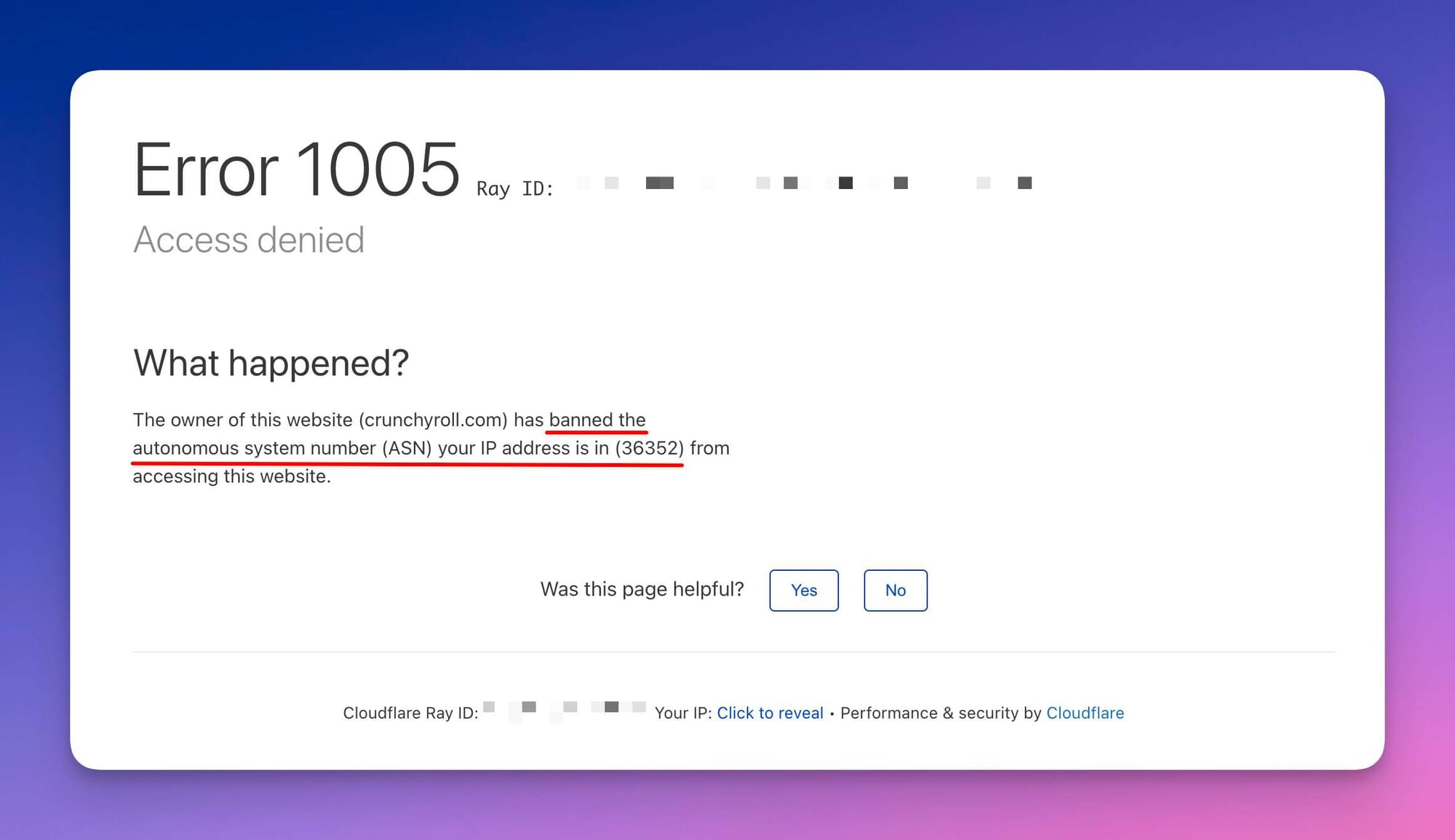
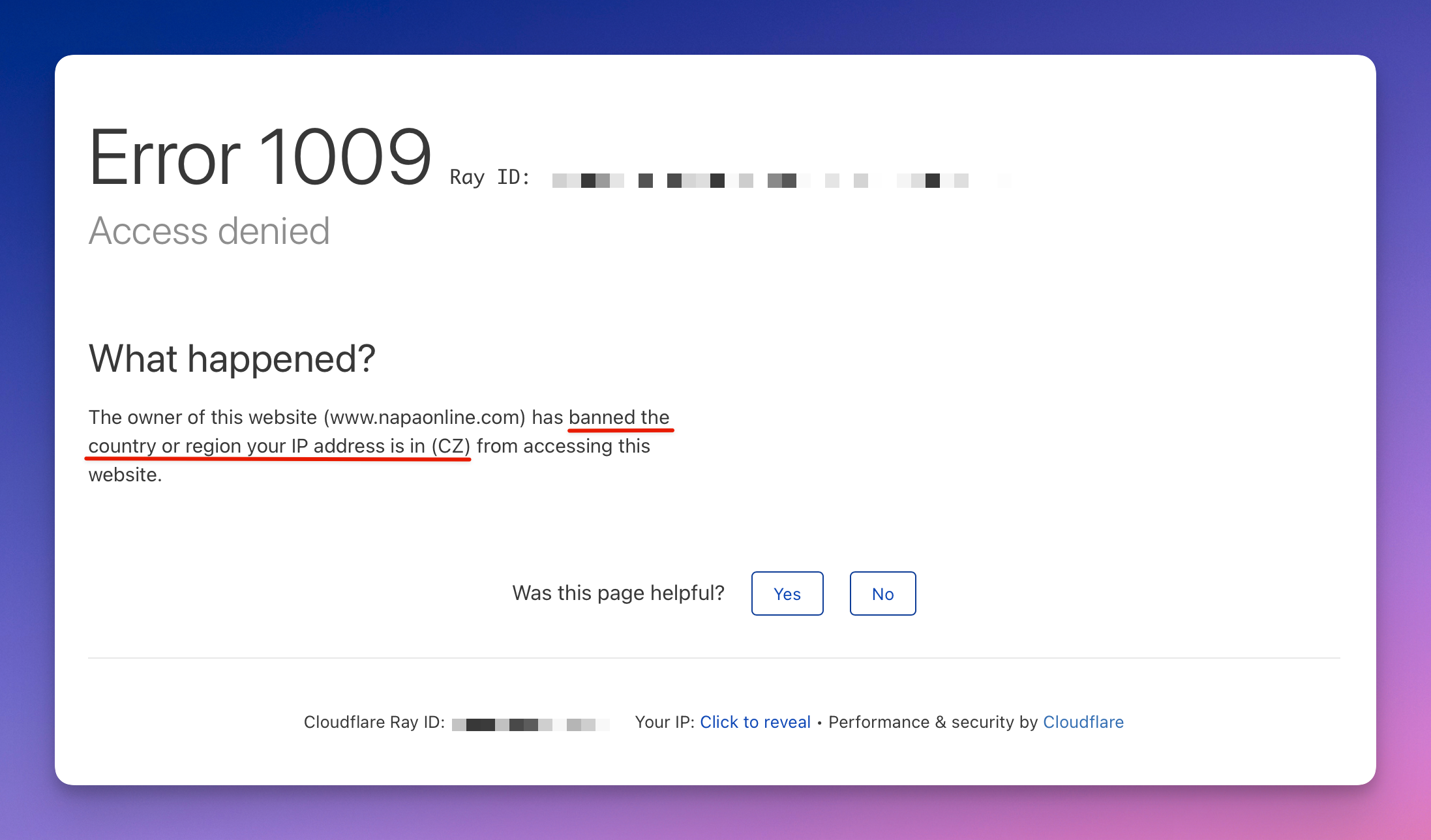
Error 1005: getting banned because of using an IP address in a sequence or range Error 1009: getting banned because of proxy location choice
6. Rotate your IPs
It's important not only to have proxies but also to rotate your proxies efficiently. Web scrapers with proxy rotation or hiding ip with a vpn help you switch the IP addresses they use to access websites. This makes each request seem like it's coming from a different user. Using proxy rotation reduces the chance of blocking by making the scraper look more human-like. Instead of looking like one user accessing a thousand pages, it looks like a hundred users accessing 10 pages.
Here's an example of adding an authenticated proxy to the popular JavaScript HTTP client with over 20 million weekly downloads, Got:
import got from 'got';
import { HttpProxyAgent } from 'hpagent';
const response = await got('https://example.com', {
agent: {
http: new HttpProxyAgent({
proxy: `http://country-US,groups-RESIDENTIAL:p455w0rd@proxy.apify.com:8000`
})
},
});
7. Use IPs sessions
Using data center or even residential proxies can help you switch locations with the speed of light but their repetitive usage can only get you this far. To avoid getting your crawler blocked, you have to make your interactions with the website appear more human. And from the POV of a website, a regular human cannot appear from 5 different locations within the last 20 minutes. So what is the solution here? That's where IP sessions come in. IP sessions let you reuse the same IP address for a while before switching to a new one, making your requests seem more natural.
Managing IP sessions means controlling how often IPs change, spreading requests evenly, and dealing with limits and blacklisting. You can use tools like Crawlee library to handle your IP sessions without much hassle.
8. Generate fingerprints
Some anti-blocking systems are so sophisticated they analyze not only HTTP headers but also in-browser JavaScript environment. So if there is a mismatch between your headers and parameters in your JavaScript environment (Web APIs). you might get blocked.
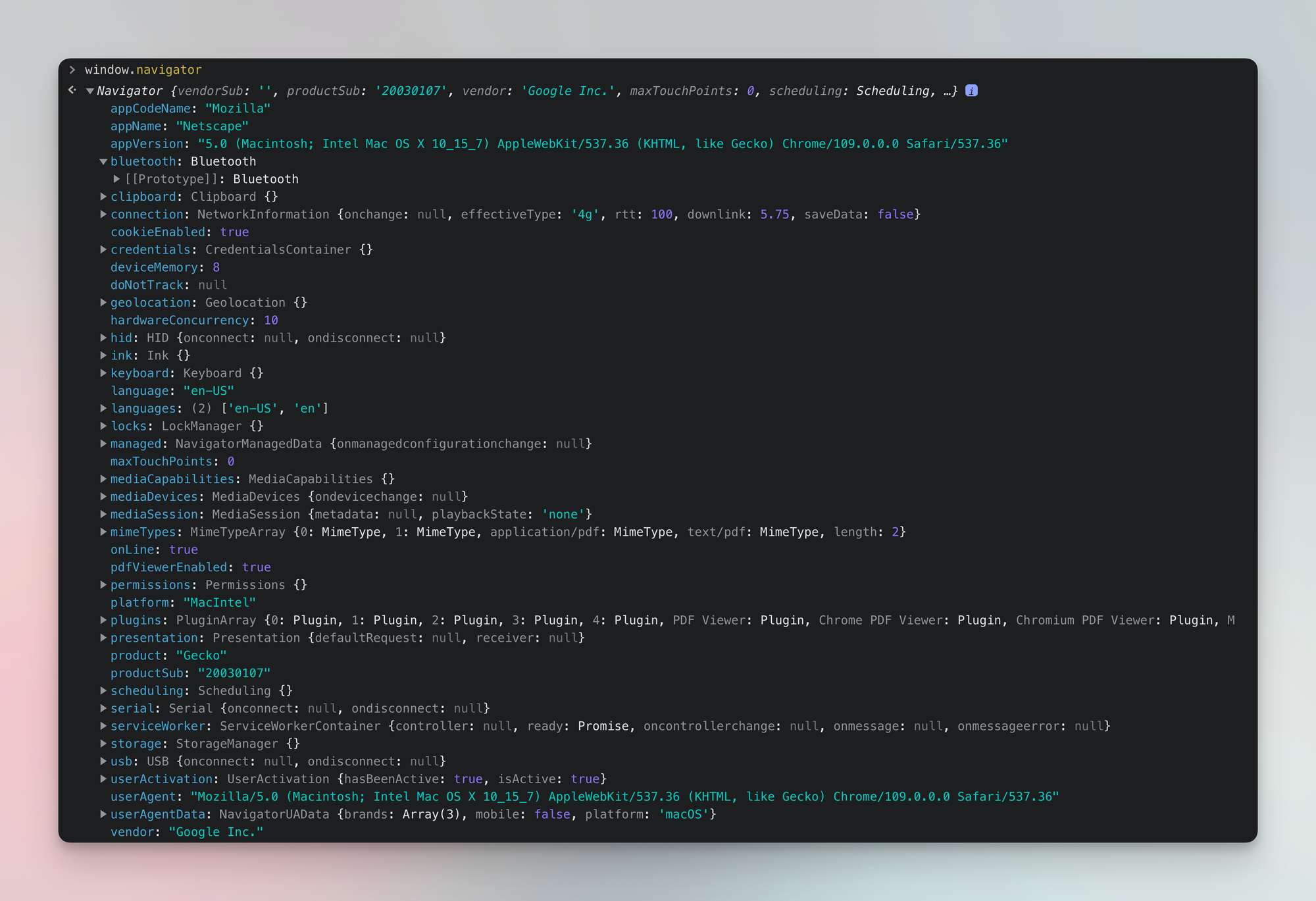
One way to fight this is to use unique browser fingerprints using JavaScript tools like fingerprinting suite. The suite consists of a fingerprint generator and fingerprint injector. The generator will build a browser signature based on factors like OS, device, and screen size, while the injector will discreetly add these parameters to the browser, thus creating a realistic human-like fingerprint. Libraries like Crawlee are built to simplify this process by automating fingerprint generation and injection.
import { PlaywrightCrawler } from 'crawlee';
const crawler = new PlaywrightCrawler({
browserPoolOptions: {
useFingerprints: true, // this is the default
fingerprintOptions: {
fingerprintGeneratorOptions: {
browsers: [{ name: 'edge', minVersion: 96 }],
devices: ['desktop'],
operatingSystems: ['windows'],
},
},
},
requestHandler: async ({ page }) => {
// use the human-like Playwright page
}
});
One more tip: when you’re using good fingerprints and still can’t pass the website’s anti-bot checks, try to limit the fingerprint generation to the OS of the device you’re running your scraper on. It might sound counterintuitive, but sometimes admitting that you’re running on Linux is the best thing you can do to pass.
9. Use CAPTCHA solvers
CAPTCHAs, these days powered by Google's ReCaptcha or alternatives like hCaptcha, aim to tell humans apart from bots. If your web scraper is getting a CAPTCHA, it usually means it's been noticed with suspicious behavior. So the first rule is before using a solver to bypass the CAPTCHA, you should evaluate whether you've done everything in your power to make your scraper appear as human-like as possible. This includes adjusting factors like browser fingerprints, proxies, and headers.
If CAPTCHA challenges persist, automated CAPTCHA solvers offer a solution, quickly bypassing these obstacles through API calls or human intervention, although this raises ethical and user experience concerns. So the conclusion here is: do everything in your power not to come across a CAPTCHA, try to modify your scraper’s behavior if you do, and worst case — use an automated CAPTCHA solver to get over it.
10. Use a headless browser
When attempting to scrape websites protected by Cloudflare, you may encounter various errors such as Error 1020 or Error 1015, indicating access denial or rate limiting. Cloudflare employs browser challenges that traditional HTTP clients struggle to overcome, resulting in blocked requests.
To effectively bypass Cloudflare's defenses, the most reliable solution is to utilize a headless browser like Puppeteer or Playwright. Headless browsers can execute JavaScript and ensure seamless browser-like behavior and eliminate the risk of detection based on headers. Tools like Crawlee simplify this process by injecting human-like fingerprints into Puppeteer or Playwright instances, making them virtually indistinguishable from genuine users.
11. Avoid the honeypots
Honeypots, commonly used to defend websites against spammers and malware, can also be used to ensnare web scrapers. How? Well, honeypots (or honeynets) are basically traps that exploit bots by hiding links within HTML code. These links are invisible to humans but detectable by bots like your web scraper: a common example is an invisible CSS style or hidden pagination.
The repercussions of interacting with a honeypot can be quite dramatic: honeypot traps often integrate tracking systems that can identify scraping attempts. So they will either make future access more challenging or just straight out blacklist your scraper. In many cases, even changing your IP address won’t help you.
To avoid honeypots when scraping, it's sometimes enough to do thorough research on HTTP information and write a function to avoid them. Here’s an example of a function that detects some of the more trivial honeypot links:
function filterLinks() {
const links = Array.from(document.querySelectorAll('a[href]'));
console.log(`Found ${links.length} links on the page.`);
const validLinks = links.filter((link) => {
const linkCss = window.getComputedStyle(link);
const isDisplayed = linkCss.getPropertyValue('display') !== 'none';
const isVisible = linkCss.getPropertyValue('visibility') !== 'hidden';
if (isDisplayed && isVisible) return link;
});
console.log(`Found ${links.length - validLinks.length} honeypot links.`);
}
But sometimes the clue might be hidden straight in front of your nose, in robots.txt file. So paying attention to the robots.txt can help you identify potential honeypot setups as well.
12. Crawl during off-peak hours
Might be a no-brainer, but crawling websites during off-peak hours reduces the strain on website servers. Unlike regular users who skim content, scrapers move through pages quickly, potentially causing high server loads. Crawling during low-traffic times, like late at night, helps prevent service slowdowns and ensures smoother website performance, unbothered by scraper's activity.
The ideal crawling time depends on each website's specific circumstances, but targeting off-peak hours, such as just after midnight, is generally a good practice to start with.
13. Adhere to ethical scraping standards and GDPR
When extracting data online, it's important to follow ethical rules and obey laws like GDPR and CCPA. These regulations protect personal information, which includes a wide range of data about individuals. Even if data is publicly available, scraping it may still require careful consideration.
So to scrape responsibly, you need to understand the laws that apply to your scraping activities, especially if you're collecting personal data — even if it’s public. By prioritizing ethical practices, you can comply with regulations, avoid legal issues, and apply web scraping techniques responsibly. This video is a good place to start:
14. Be on the lookout for content changes
Websites frequently undergo updates, modifications, or redesigns that can break existing scrapers. A move of a single button or a frame can or obscuring content can break your whole house of cards. If you want your web scraper to last, it's important to anticipate website changes to ensure you can adapt your scraper accordingly.
You can use automated monitoring tools, version control systems like Git, website change detection APIs or even specialized page comparison libraries to track changes on websites. As an extra safety measure, you can integrate robust error handling and logging mechanisms within your scraper code.
15. Stop repeated failed attempts
Connected with the tip above, if you don't react fast enough to the website changes, your scraper will keep making attempts to scrape it. Too many failed attempts may get the attention of the anti-scraping systems. So one more reason to get alerted on time and adjust your scraper when you notice these errors.
16. Avoid scraping images when possible
Unlike text-based data which is so versatile it can be fed to LLM, images require more storage space and bandwidth to download and process, which can significantly slow down your scraping process. Additionally, extracting meaningful information from images can be challenging and often requires complex image processing techniques, making it less efficient compared to scraping text-based content. Unless absolutely necessary, it's better to focus on scraping text-based data for better efficiency and compliance.
17. Using Google Cloud functions
Google Cloud Functions are serverless execution environments that automatically run code in response to events. They can be triggered by various events like HTTP requests, Pub/Sub messages, or Cloud Storage events.
For crawling, Cloud Functions automate tasks like triggering web scraping when specific events occur, such as file uploads or scheduled intervals. This trick will make your scraping attempts more efficient without having to manage servers.
18. Cache out
As a backup option for gathering data, consider using Google cache especially if it doesn't change frequently. Just add http://webcache.googleusercontent.com/search?q=cache: before the URL you want to scrape. This last resort approach can be handy for extracting information from challenging websites, especially those that aren't updated regularly.
19. Avoid JavaScript
Might be a bit counter-intuitive coming from a company that's been traditionally on the JavaScript side of things, but even we admit that scrapers based on JavaScript (like those using Puppeteer or Selenium) can be quite resource-intensive. That's mainly because, unlike HTTP request-based scrapers, JavaScript crawlers usually run a full browser or a browser-like environment to execute the code on the webpage. And that's heavy.
But more importantly, since crawlers based on JavaScript mimic real user behavior more closely, the websites that employ anti-scraping measures are more geared towards detecting them.
20. Change up the crawling pattern
This is more of a general common-sense tip. By changing up when and how often your scraper makes HTTP requests to the website, and the order it does them in, your crawler can act more like a human user (less predictably and less efficiently) and reduce the chances of getting blocked or blacklisted.
Also, by switching up the IP addresses and user agents your scraper uses, you can stay anonymous and avoid detection. Changing how your scraper crawls also helps it handle website changes and server limits better, making sure it keeps working well over time. So, using different crawling strategies is key for successful and long-lasting web scraping.
21. Use APIs to your advantage
Last but not least, you can always take the easy way out: the unofficial APIs. These can cover the infrastructure part of data extraction. Headers, proxies, fingerprints, right timing, ... With ready-made scrapers, you can focus on extracting valuable data instead of dealing with those technical complexities. These tools save time and effort by providing pre-built solutions for scraping popular websites like Google Maps, TikTok, Indeed, and more. With APIs, you can access diverse data sources without creating scraping scripts from scratch. They handle common challenges like CAPTCHA solving and IP rotation, making scraping more efficient.




