Life at Apify Thought leadership Complete ownership, boring technology, and how we build engineering culture at Apify Marek Trunkát Jan 27, 2026
Apify updates Web automation and RPA Law and compliance Effective SOC 2 compliance for engineers Marek Trunkát Feb 24, 2025
Apify updates Developer community 2024 in Apify engineering: struggles, technology choices, and growth Marek Trunkát Jan 14, 2025
Tutorial Web automation and RPA Programming How to create an RSS feed from a website (step-by-step guide) Marek Trunkát Jul 8, 2024
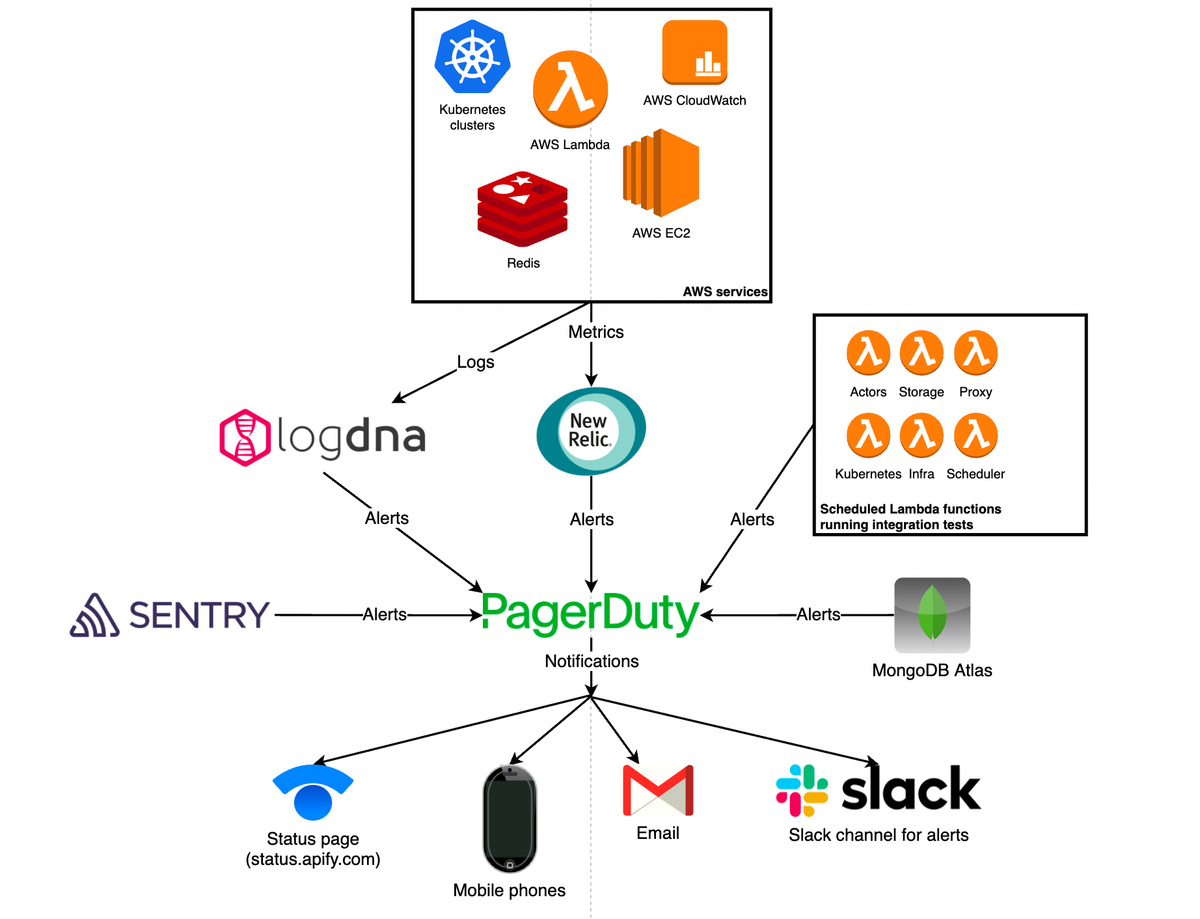
Monitoring and data quality Apify updates How we monitor infrastructure that processes 1 petabyte of data every month Marek Trunkát Feb 21, 2022