Zillow is one of the most popular real-estate property trading websites due to its vast coverage, verified information, and user-friendliness. So, if you need to extract updated information on real estate properties, using Zillow.com would be the best option.
In this tutorial, you’ll learn how to scrape the Zillow website with 2 different approaches: creating a web scraper using Python from scratch and using easy-to-use APIs to access Zillow's data. This tutorial requires no prior experience in web scraping, and as long as you follow the steps, you can build a web scraper for Zillow.
How to scrape Zillow in Python
You can follow the following steps to scrape Zillow using Python:
- Set up your environment
- Understand Zillow’s web structure
- Write the scraper code
- Deploy on Apify
1. Setting up your environment
Here’s what you'll need to scrape the Zillow website:
- Python 3.5+: Make sure you have installed Python 3.5 or higher and set up the environment.
- Install required libraries: Run the command below on the terminal to install the required libraries—
httpx,lxml,pandas, andrequests.
pip install requests httpx pandas lxml
2. Understanding Zillow’s web structure
Before scraping any website, especially dynamic ones like Zillow, it’s important to understand the web structure.
For easier extraction, you can filter the listings based on location. Example: https://www.zillow.com/new-york-ny/
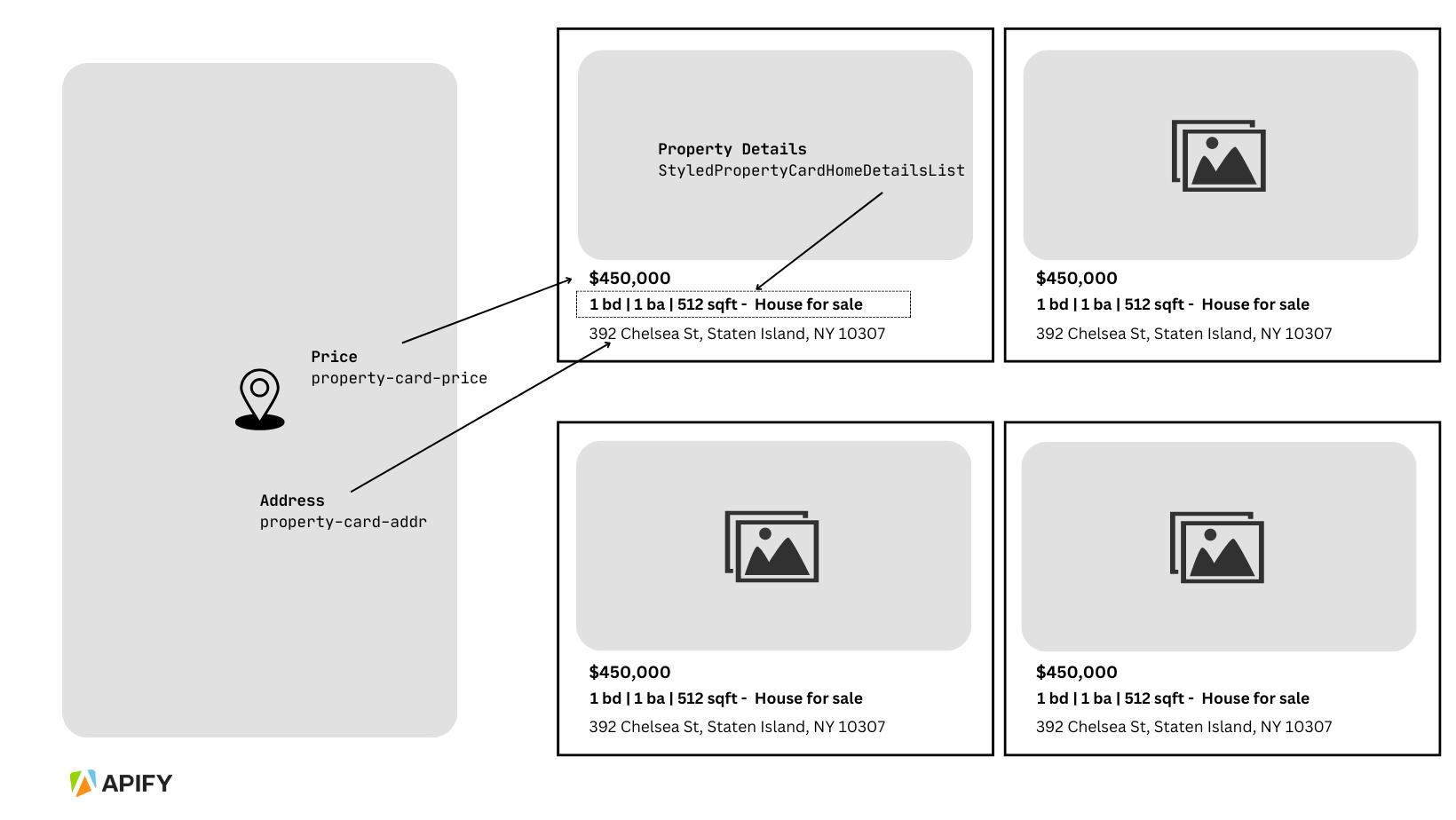
Fortunately, the Zillow website allows a simple structure as follows:
- Property Price is within a
spanelement, with thedata-testattribute of"property-card-price". - Property details, such as the number of bedrooms, baths, and square feet, are within one unordered list (
<ul>) element with the classStyledPropertyCardHomeDetailsList-c11n-8-105-0__sc-1j0som5-0 ldtVy. Each detail is a list item (<li>) containing bold text and an abbreviation. Please note that since all the above important information is in one element, you’ll have to split them to extract them into separate columns in the dataset. - The address or location of the property is also within a
spanelement, with the data-test attribute ofproperty-card-addr.
Get Zillow data faster
3. Write the scraper code
Now that you have an understanding of how the Zillow website is structured, you can continue writing the Python code.
You can begin by importing the installed libraries, and then writing a function to fetch the HTML content of Zillow property listings. Zillow uses pagination, so you’ll have to pass the page URL dynamically to get multiple pages.
# Importing the libraries
import httpx
from lxml import html
import pandas as pd
import asyncio
async def fetch_properties(url, headers):
async with httpx.AsyncClient() as client:
response = await client.get(url, headers=headers)
if response.status_code != 200:
print(f"Failed to fetch the HTML content. Status code: {response.status_code}")
return []
# Parsing the response content using lxml
tree = html.fromstring(response.content)
properties = []
# Using XPath to select property cards
property_cards = tree.xpath('//li[contains(@class, "ListItem-c11n-8-105-0")]')
for card in property_cards:
obj = {}
try:
# Address
obj["Address"] = card.xpath('.//a/address/text()')[0].strip()
except IndexError:
obj["Address"] = None
try:
# Price
obj["Price"] = card.xpath('.//span[@data-test="property-card-price"]/text()')[0].strip()
except IndexError:
obj["Price"] = None
# Extracting and splitting Bds, Baths, and Sqft data
try:
details = card.xpath('.//ul[contains(@class, "StyledPropertyCardHomeDetailsList-c11n-8-105-0__sc-1j0som5-0")]')
if details:
details_list = details[0].xpath('.//li/b/text()')
obj["Bds"] = details_list[0].strip() if len(details_list) > 0 else None
obj["Baths"] = details_list[1].strip() if len(details_list) > 1 else None
obj["Sqft"] = details_list[2].strip() if len(details_list) > 2 else None
else:
obj["Bds"] = obj["Baths"] = obj["Sqft"] = None
except IndexError:
obj["Bds"] = obj["Baths"] = obj["Sqft"] = None
properties.append(obj)
return properties
The above fetch_properties function handles sending HTTP requests (to URLs using the headers that will be declared in the next function) and parsing the HTML response to extract property details using the relevant classes and attributes.
It also separates the <ul> list of property details of bedrooms, baths, and square footage into three separate items.
However, the above code isn’t executable yet. To be able to do so, you’ll have to write the next part of the code declaring variables and scraping process.
async def main():
base_url = "<https://www.zillow.com/new-york-ny/>"
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"upgrade-insecure-requests": "1"
}
all_properties = []
page_number = 1
properties_to_collect = 20
# You can change this value to the min. number of listings needed
while True:
url = f"{base_url}?page={page_number}"
print(f"Fetching page {page_number}...")
properties = await fetch_properties(url, headers)
if not properties: # If properties is empty, break the loop
print("No more properties found or unable to fetch page.")
break
valid_properties = [p for p in properties if
p["Address"] and p["Price"] and p["Bds"] and p["Baths"] and p["Sqft"]]
all_properties.extend(valid_properties)
# Exit if enough properties are collected
if len(all_properties) >= properties_to_collect:
break
page_number += 1
await asyncio.sleep(2)
# Converting to DataFrame and saving to CSV
df = pd.DataFrame(all_properties)
df.to_csv('zillow_properties.csv', index=False)
print(f"Successfully scraped {len(all_properties)} properties and saved to 'zillow_properties.csv'.")
# Running the script
if __name__ == "__main__":
asyncio.run(main())
The main function starts by defining a base URL (https://www.zillow.com/new-york-ny/) and HTTP headers to simulate a real browser request. It continues scraping pages until 20 valid listings are gathered, with a short delay between requests to avoid overwhelming the server.
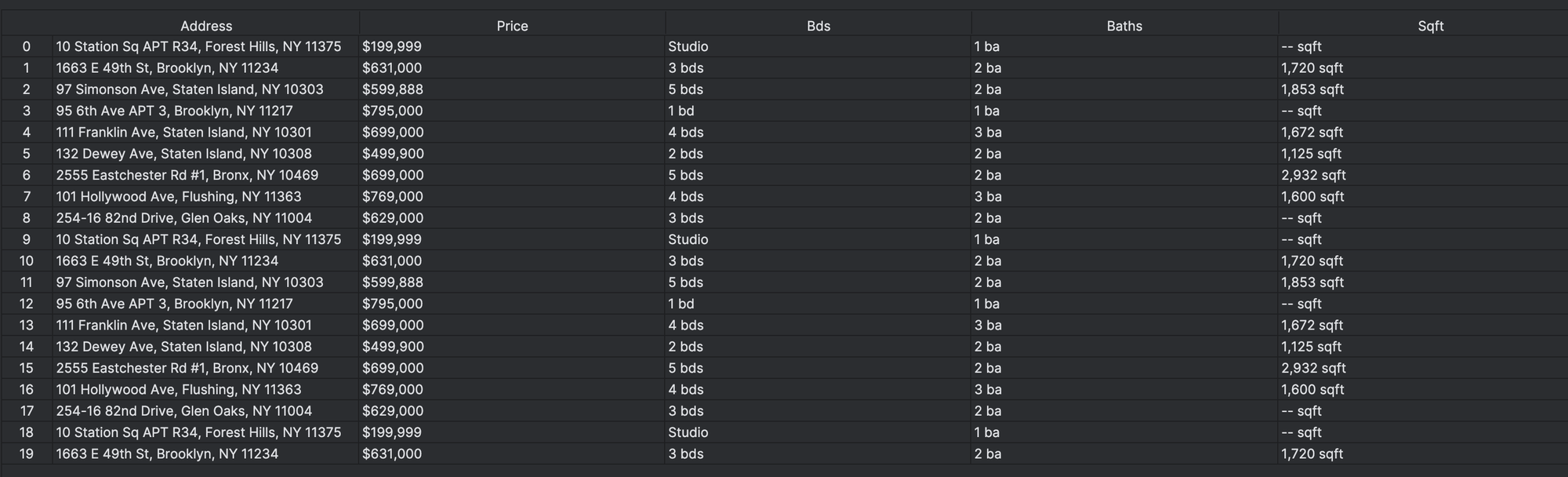
Once run, it will result in a data frame and a CSV file like this:
4. Deploying to Apify
There are several reasons for deploying your scraper code to a platform like Apify. In this specific case, deploying code to Apify helps you automate the data extraction process efficiently by regulating data collection and it also offers a convenient way to store and download your data, in various formats.
To deploy your code to Apify, follow these steps:
#1. Create an account on Apify
When you sign up for a free account, you get immediate access to all the features of the Apify platform and $5 worth of credit every month. There's no time limit on the free plan.
- First, install Apify CLI using NPM or Homebrew in your terminal:
- Create a new directory for your Actor.
mkdir my-zillow-scraper
cd my-zillow-scraper
- Then create a new Actor by typing below:
apify create my-zillow-actor
- Select “Python” as the language for the Actor.

- For the template, choose “Empty Python Project”.

The above command creates a boilerplate Actor with main.py (found in my-zillow-actor folder > src) and other required files with it so that you would not have to set up the Actor from scratch, manually.
#3. Edit main.py
Note that you would have to make some changes to the previous script to make it Apify-friendly. Such changes are:
- Removing or replacing
printstatements with logging to handle output properly in the Apify environment. - Using Apify's
requestQueueandkeyValueStore - Adapting for Apify Input and Output
- Removing direct file operations like
df.to_csv
You can find the modified script on GitHub.
#4. Edit requirements.txt
The file requirements.txt file contains the dependencies required for the Actor to run.
apify
lxml
httpx
#5. Deploy to Apify
- Type
apify loginon your terminal to log in via browser or manually. - Once logged in, enter
apify pushto deploy the Actor on Apify.
To run the deployed Actor, go to Apify Console > Actors > Your Actor. Then click the “Start” button**,** and the Actor will start to build and run.
apify run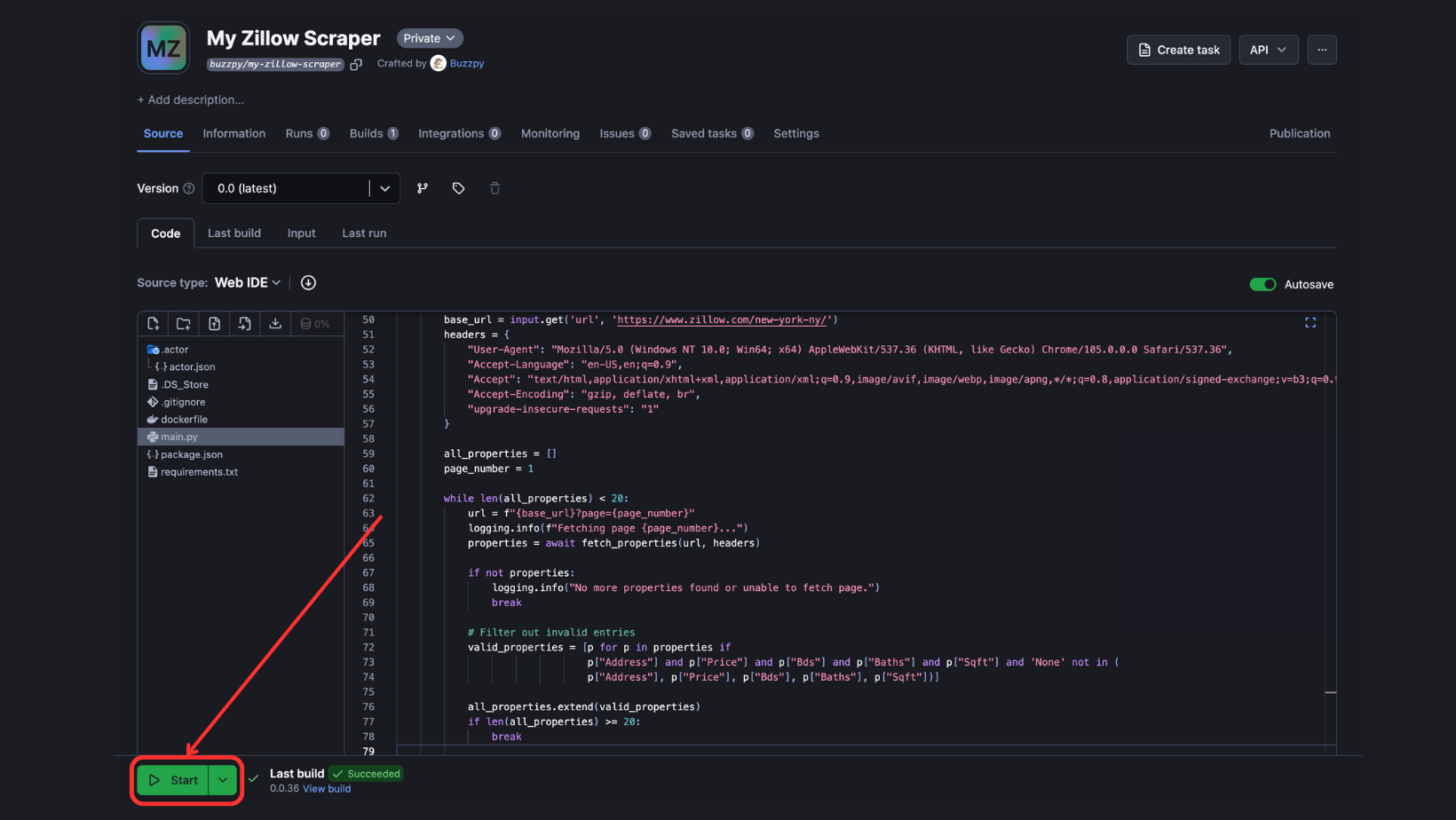
To view and download output, click “Export Output”.
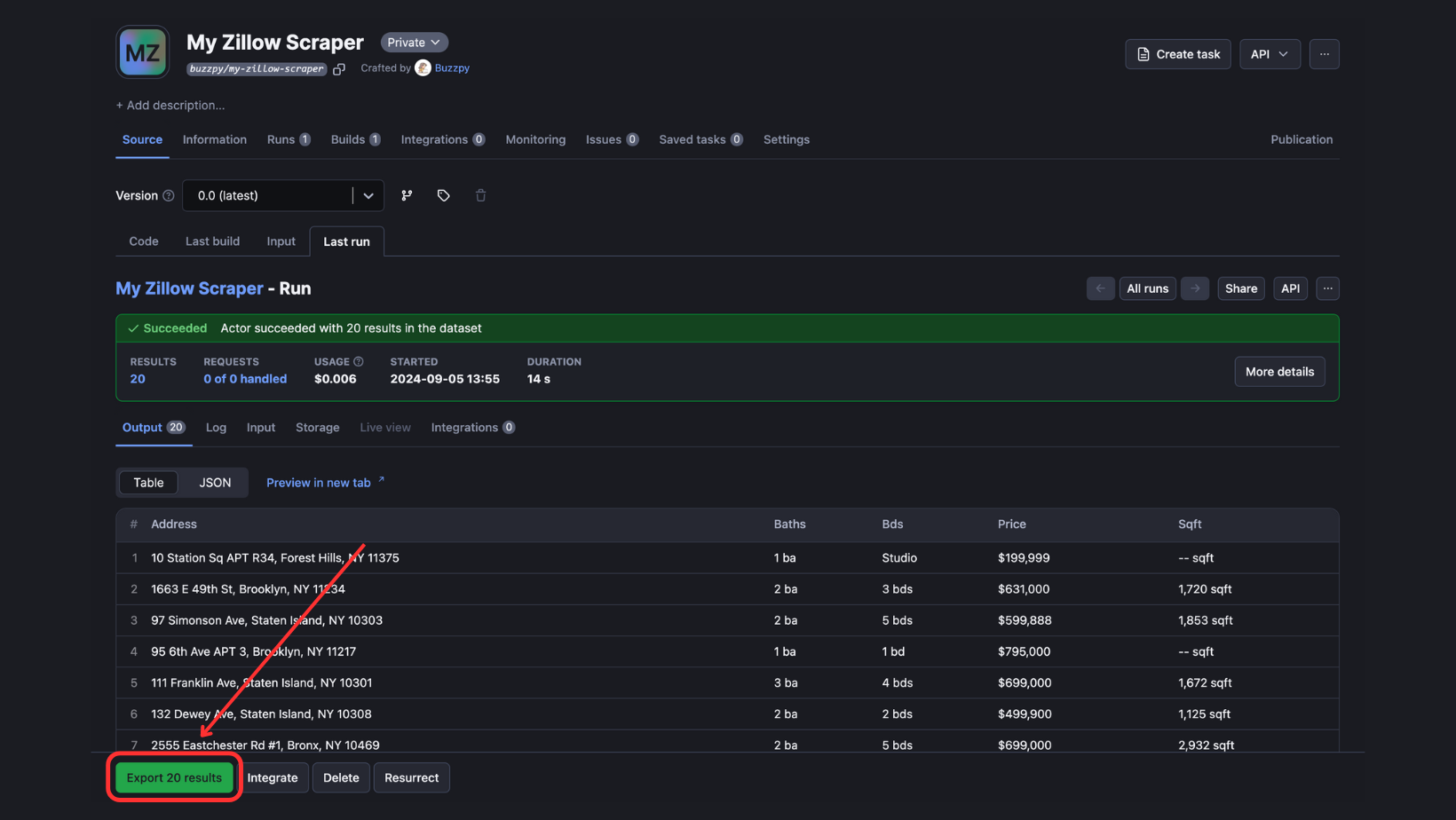
According to your needs, you can select/omit sections, and download the data in different formats such as CSV, JSON, Excel, etc.
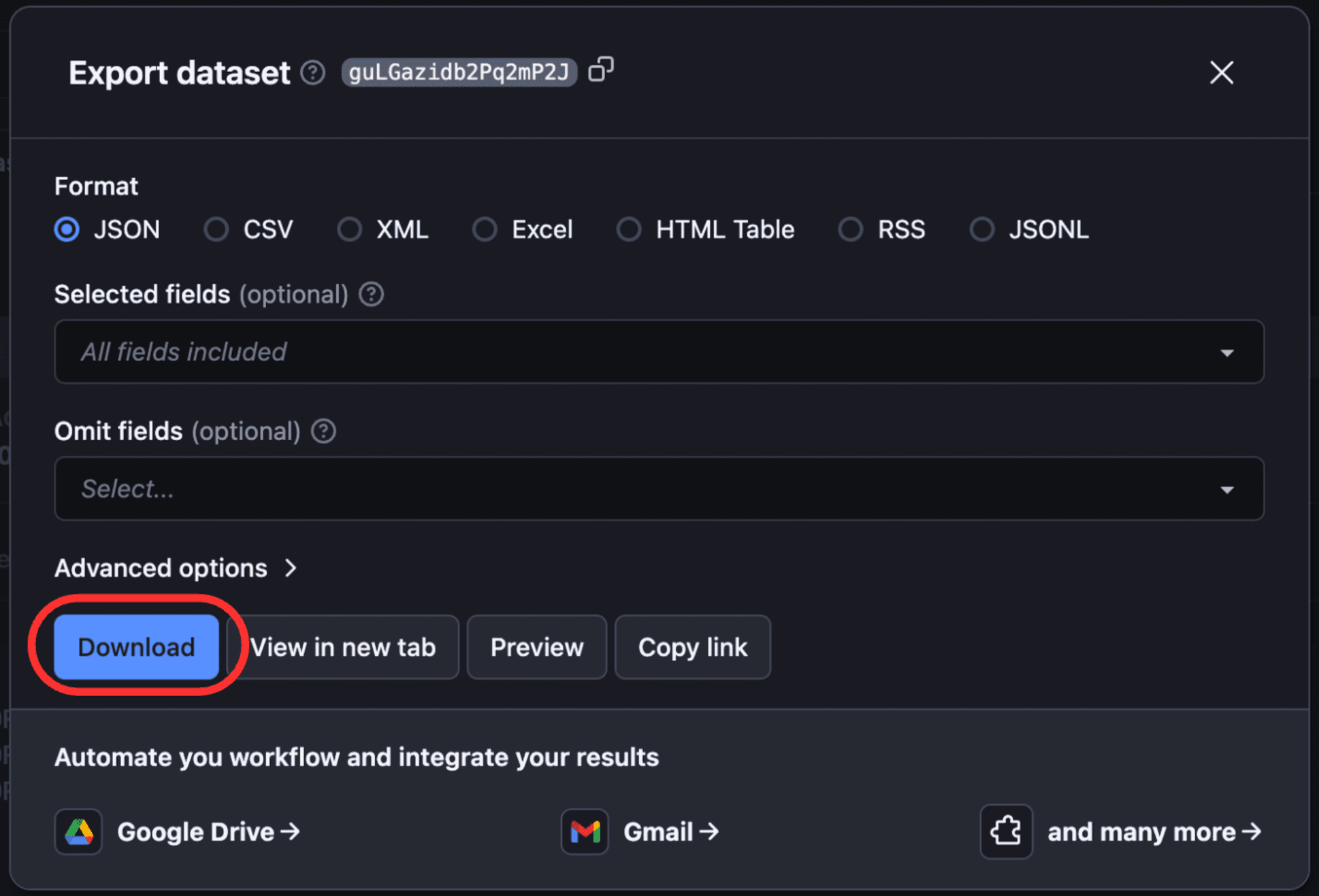
And that’s all! You have successfully built and deployed a Zillow web scraper on Apify.
How to use your Zillow scraper with the Python Apify SDK
Here’s how you can use the Apify Zillow scraping Actor easily using the Python Apify SDK.
You can find your API token in Apify Console > Settings > Integrations.
- Install
apify-clientSDK (unless already done).
pip install apify-client
- Import Apify SDK and initialize the client.
from apify_client import ApifyClient
client = ApifyClient('YOUR_API_TOKEN')
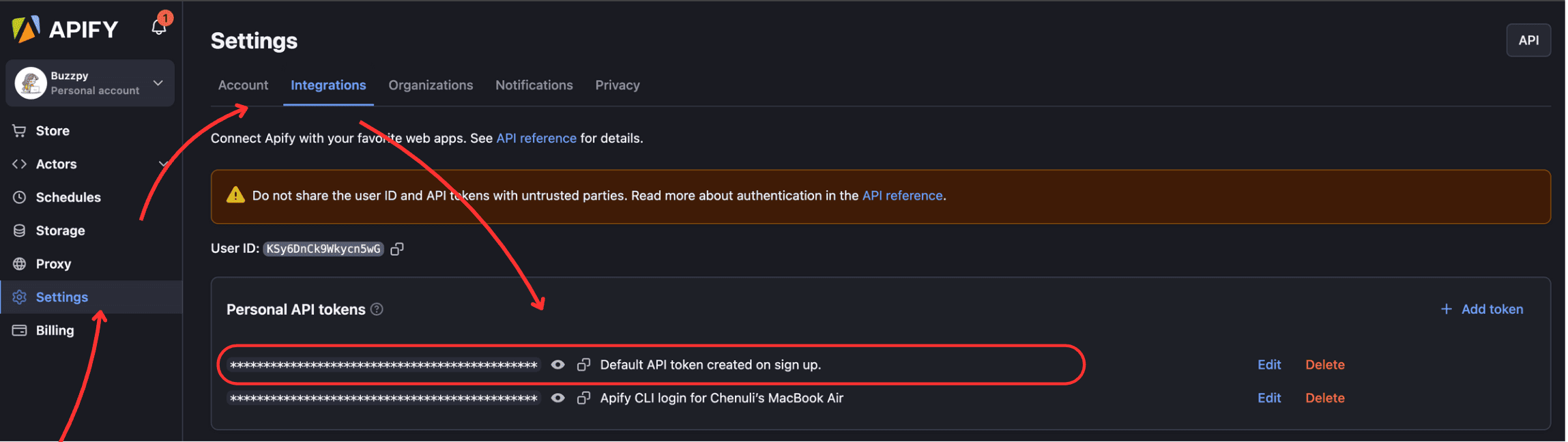
- Give the Actor input and create a new run for the Actor.
# Preparing the Actor input with max results set to 100
run_input = {
"searchUrls": [
{
# Feel free to change the target URL
"url": "<https://www.zillow.com/homes/for_sale/?searchQueryState=%7B%22isMapVisible%22%3Atrue%2C%22mapBounds%22%3A%7B%22west%22%3A-124.61572460426518%2C%22east%22%3A-120.37225536598393%2C%22south%22%3A36.71199595991113%2C%22north%22%3A38.74934086729303%7D%2C%22filterState%22%3A%7B%22sort%22%3A%7B%22value%22%3A%22days%22%7D%2C%22ah%22%3A%7B%22value%22%3Atrue%7D%7D%2C%22isListVisible%22%3Atrue%2C%22customRegionId%22%3A%227d43965436X1-CRmxlqyi837u11_1fi65c%22%7D>"
}
],
"maxResults": 100 # Limit to 100 results
}
- Run the Actor and print the results
# Run the Actor and wait for it to finish
run = client.actor("maxcopell/zillow-scraper").call(run_input=run_input)
# Fetch and print Actor results from the run's dataset (if there are any)
print("💾 Check your data here: <https://console.apify.com/storage/datasets/>" + run["defaultDatasetId"])
for item in client.dataset(run["defaultDatasetId"]).iterate_items():
print(item)
When run, the above code would scrape Zillow listings in the URL given and display the output as below:
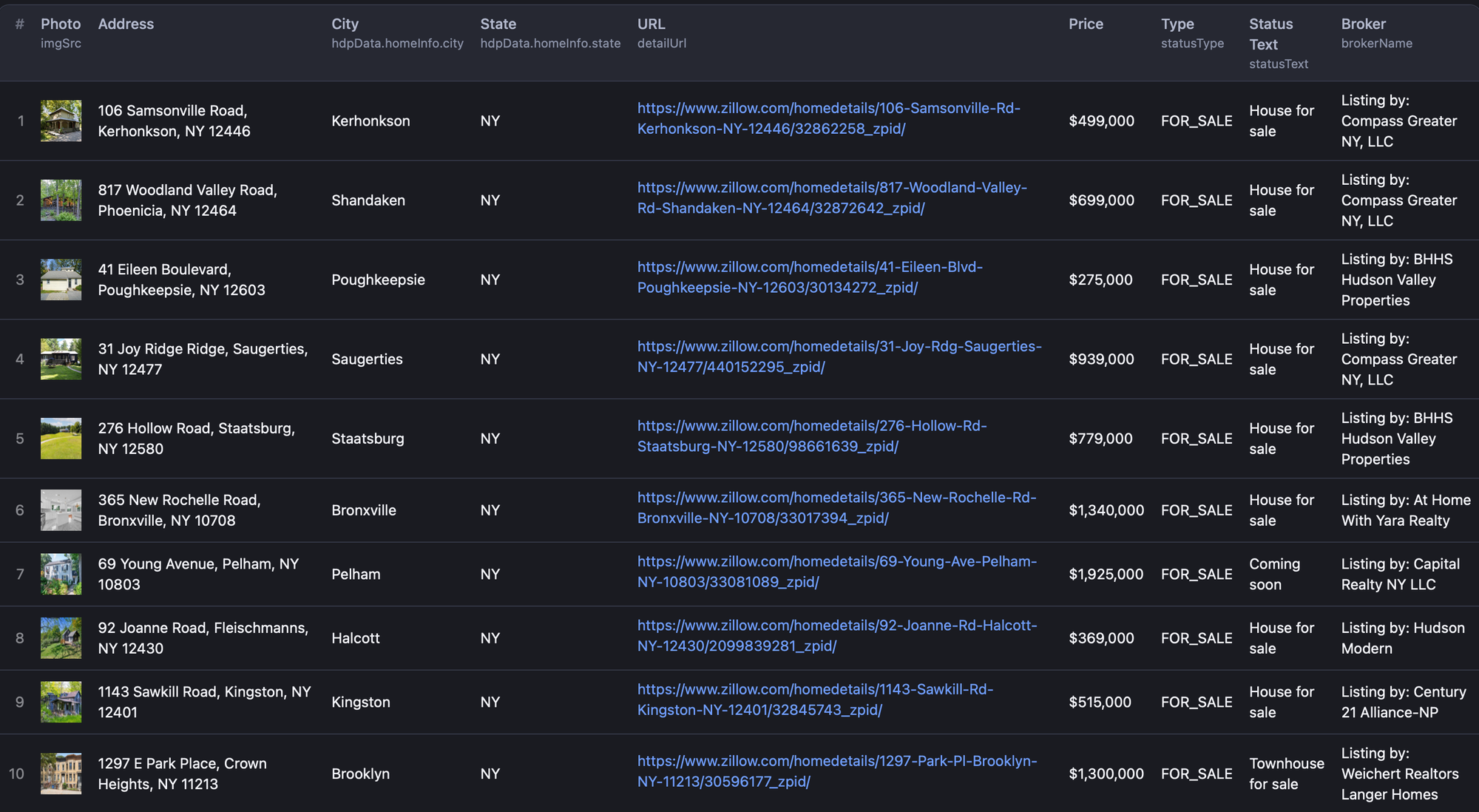
Conclusion
This tutorial guided you through scraping Zillow using 2 ways: a) Writing Python code from scratch, and b) Using an Apify Actor API. Either method lets you successfully scrape and store the extracted information easily and accurately.
Deploy your scraping code to the cloud
Headless browsers, infrastructure scaling, sophisticated blocking.
Meet Apify - the full-stack web scraping and browser automation platform that makes it all easy.
FAQs
Can you scrape Zillow in Python?
Yes, when the right tools and methods are used. You can write Python code to extract information like the price, number of bedrooms, square footage, and seller information from the Zillow website. Finally, you can create a script that navigates the Zillow website, finds information needed, and saves the data for later analysis.
Does Zillow have a Python API?
Zillow does provide a Python API, but it comes with some restrictions. Notable limitations of the Zillow API are rate limits, restrictions for commercial use, and outdated information. However, using a ready-made Apify Actor lets you scrape data easily, with no limitations on access or outdated information.