There are three possible reasons you’re reading this article:
👉 1. You’re actively seeking out a web ripper.
👉 2. Some geeky friends mentioned web rippers, and you were too embarrassed to confess your ignorance, so you googled it.
👉 3. You started going down one of those infamous rabbit holes on the internet, and by now, you don't remember how this web search started, where you live, or what your name is.
Whichever the reason you ended up here, we‘ll answer your questions about website rippers. So you'll either:
A. Find what you're looking for,
B. Feel able to talk to your friends about web rippers without looking like an idiot, or
C. Finally escape this rabbit hole and return to civilization.
What is a website ripper?
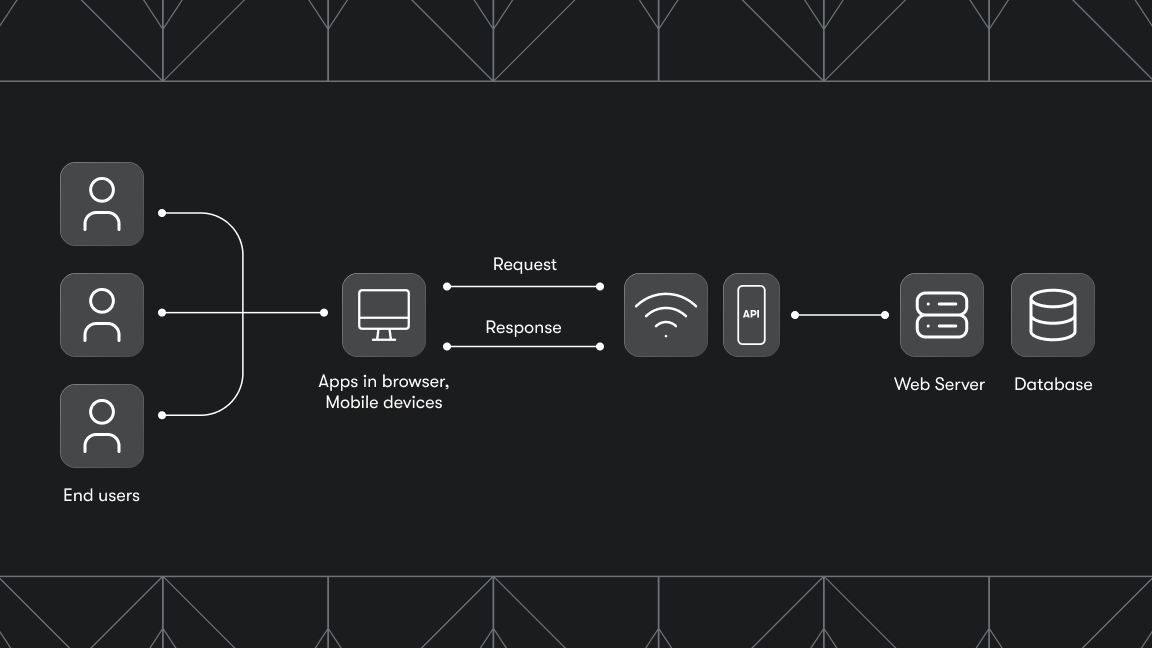
A website ripper, or site ripper, is a piece of software that copies an entire website or parts of a website so you can download it to read and analyze it offline. You can copy and extract data, images, files, and links and download that data to your computer. But why might someone need to do that? Here are four reasons to download a website:
- You can browse the site without an internet connection
- You can keep a downloaded copy of your website as a backup
- You can download source files and migrate your site to a new server
- You can use the web data for educational purposes, such as studying source code
As you can see, understanding how to rip website content can greatly benefit anyone needing reliable access to web resources. With advancements in technology, tools used for tasks like this often overlap with those utilized in Global Automation Testing, ensuring accuracy and efficiency in accessing and managing web data.
How do I rip a website?
That’s the what and the why out of the way, but how do you rip a website? To rip a website, you’ll need a reliable website copy tool to extract the data. There’s a handful of website ripper tools that can get the job done, but to help you choose the best website copier, we’ve narrowed down the list to five (there’s a nice surprise waiting for you in the fifth one) 😉
HTTrack
HTTrack is an effective website ripper copier that lets you download websites for offline viewing. Start from the Wizard 🧙♂️ and choose the number of connections needed and the items you want to extract. The tool will build the website directory with the server's HTML, files, and images and transfer it to your computer. When you open a page of the copied website, you’ll be able to browse it just as you would online.
Main weaknesses: Doesn’t allow you to download a single site page; takes time and effort to exclude unnecessary file types
SiteSucker
SiteSucker may sound like an insult, but in fact, it’s a highly useful web ripper. SiteSucker, a piece of website capture software designed exclusively for Mac users, simplifies the process of copying web content. SiteSucker copies individual web pages, style sheets, images, and PDFs and lets you download them to your local hard drive. All you need to do is enter the website’s URL and press enter. You can pause and restart downloads, and you also have a range of languages available: French, Spanish, German, Italian, and Portuguese.
Main weaknesses: It’s only for Macs
Cyotek WebCopy
Cyotek WebCopy is a free comprehensive website copier that can copy partial or entire websites to your local hard disk by scanning the specified site and downloading it to your computer. It remaps links to images, videos, and stylesheets to match the local paths. It has an intricate configuration that allows you to define which parts of the website should be copied.
Main weaknesses: Can’t handle sites that use JavaScript or dynamic functions; can only scrape what appears in the browser
Getleft
Getleft is a free downloading program for Windows. Getleft offers a straightforward approach as a clone website tool, allowing users to download complete websites simply by providing the URL. It supports 14 languages and edits original pages and links to external sites so you can emulate online browsing on your hard disk. You can also resume interrupted downloads and use filters to select which files should be downloaded.
Main weaknesses: Can process only HTML; can’t download files embedded in JavaScript
Universal web scrapers
Now it’s time to reveal that surprise we’ve been hiding! Our fifth entry is actually a list of web scraping tools. All web rippers utilize web crawling and data scraping, so these tools will come in very handy if you want to extract and download web data (have your own site grabber). The five web scrapers below are the most powerful tools on the Apify platform. With them, you can extract just about any kind of data (provided it’s legal) from any website at scale.
Use a universal web scraper
To get started with any of the following tools, you only need to tell the scraper which pages it should load and how to extract data from each page. The scrapers start by loading pages specified with URLs, and they can follow page links for recursive crawling of entire websites.
Web Scraper
Web Scraper is a generic easy-to-use tool for crawling web pages and extracting structured data from them with a few lines of JavaScript code. It loads web pages in the Chromium browser and renders dynamic content.
Cheerio Scraper
Cheerio Scraper is a ready-made solution for crawling websites using plain HTTP requests. A quick and lightweight alternative to Web Scraper, Cheerio web scraping is suitable for websites that don’t render content dynamically. It retrieves the HTML pages, parses them using the Cheerio Node.js library, and lets you quickly extract any data from them.
Vanilla JS Scraper
Vanilla JS Scraper is a non-jQuery alternative to Cheerio Scraper and is well-suited for scraping web pages that do not rely on client-side JavaScript to serve their content. It can be up to 20 times faster than a full-browser solution like Puppeteer.
Puppeteer Scraper
Puppeteer Scraper is a full-browser solution supporting website login, recursive crawling, and batches of URLs in Chrome. As the name suggests, this tool uses the Puppeteer library to control a headless Chrome browser programmatically, and it can make it do almost anything. Puppeteer is a Node.js library, so knowledge of Node.js and its paradigms is required to wield this powerful tool.
Playwright Scraper
The Playwright counterpart to Puppeteer Scraper, Playwright Scraper is highly suitable for building scraping and web automation solutions. It supports features beyond Chromium-based browsers, providing full programmatic control of Firefox and Safari. As with Puppeteer Scraper, this tool requires knowledge of Node.js.
A rabbit hole solution
If none of the above tools meet your requirements, or if they sound a little too tricky for you to handle, then rather than go off down another rabbit hole through the ever-expanding web universe for that elusive ideal solution, we have a better idea. Reach out to us at Apify and let us know what you need. We’ll be happy to discuss your case and develop a tool or solution just for you!
Note: This evaluation is based on our understanding of information available to us as of September 2022. Readers should conduct their own research for detailed comparisons. Product names, logos, and brands are used for identification only and remain the property of their respective owners. Their use does not imply affiliation or endorsement.