Learn how to build web scrapers with R in this beginner's guide. We'll cover R's capabilities, and its advantages and disadvantages. After completing this guide, you'll be able to create and modify your own web scraper. Don't worry if you're new to R - we've made the steps easy to follow.
Is R good for web scraping?
R is an excellent choice for web scraping due to its libraries specifically designed for data extraction, such as rvest and httr, which make collecting data from the web straightforward.
R has strong data manipulation and analysis tools, which make it great for processing and understanding your scraped data. However, R may have some limitations when dealing with complex or JavaScript-rendered websites compared to other options.
If you'd like to learn more about that, you can read our tutorial on using Selenium to scrape JavaScript-rendered pages or our guide to using Playwright to scrape dynamic websites.
Prerequisites
Firstly, you need to set up your R environment. To do so, execute the following commands:
# macos
brew install --cask r
# windows
Install using - https://cran.r-project.org/bin/windows/
# linux
Install using - https://cran.r-project.org/bin/linux/ubuntu/fullREADME.html
Next, you'll need to set up your IDE to support R. For this tutorial, let's stick to Visual Studio Code. Once you've installed VSCode, you can install the extension REditorSupport.
Then you can run the following command in your terminal:
R --version
If you've set up everything correctly, you should see the following output:
R version 4.4.0 (2024-04-24) -- "Puppy Cup"
Copyright (C) 2024 The R Foundation for Statistical Computing
Platform: aarch64-apple-darwin20
R is free software and comes with ABSOLUTELY NO WARRANTY.
You are welcome to redistribute it under the terms of the
GNU General Public License versions 2 or 3.
For more information about these matters see
https://www.gnu.org/licenses/.
Scraping a website with R
- Installing the required libraries
- Scraping a website
- Select elements
- Extract data from elements
- Scrape tables
- Handle forms
- Handle lists
- Download images
1. Installing the required libraries
First, you'll need packages. R offers a collection of libraries that let you scrape websites. Here are the libraries we'll be using:
rvest: Offers simple functions such asread_html(),html_nodes()that help read and parse HTML.httr: A package for sending and receiving HTTP requests in R. It allows you to interact with web APIs and access online data.dplyr: Allows easy data frame manipulation in R. It simplifies filtering, selecting, creating columns, summarizing, and rearranging data.
To install the libraries, add the following code:
# Install and load the necessary packages
install.packages("rvest")
install.packages("httr")
install.packages("dplyr")
library(rvest)
library(httr)
library(dplyr)
After executing the code, you should see the output:
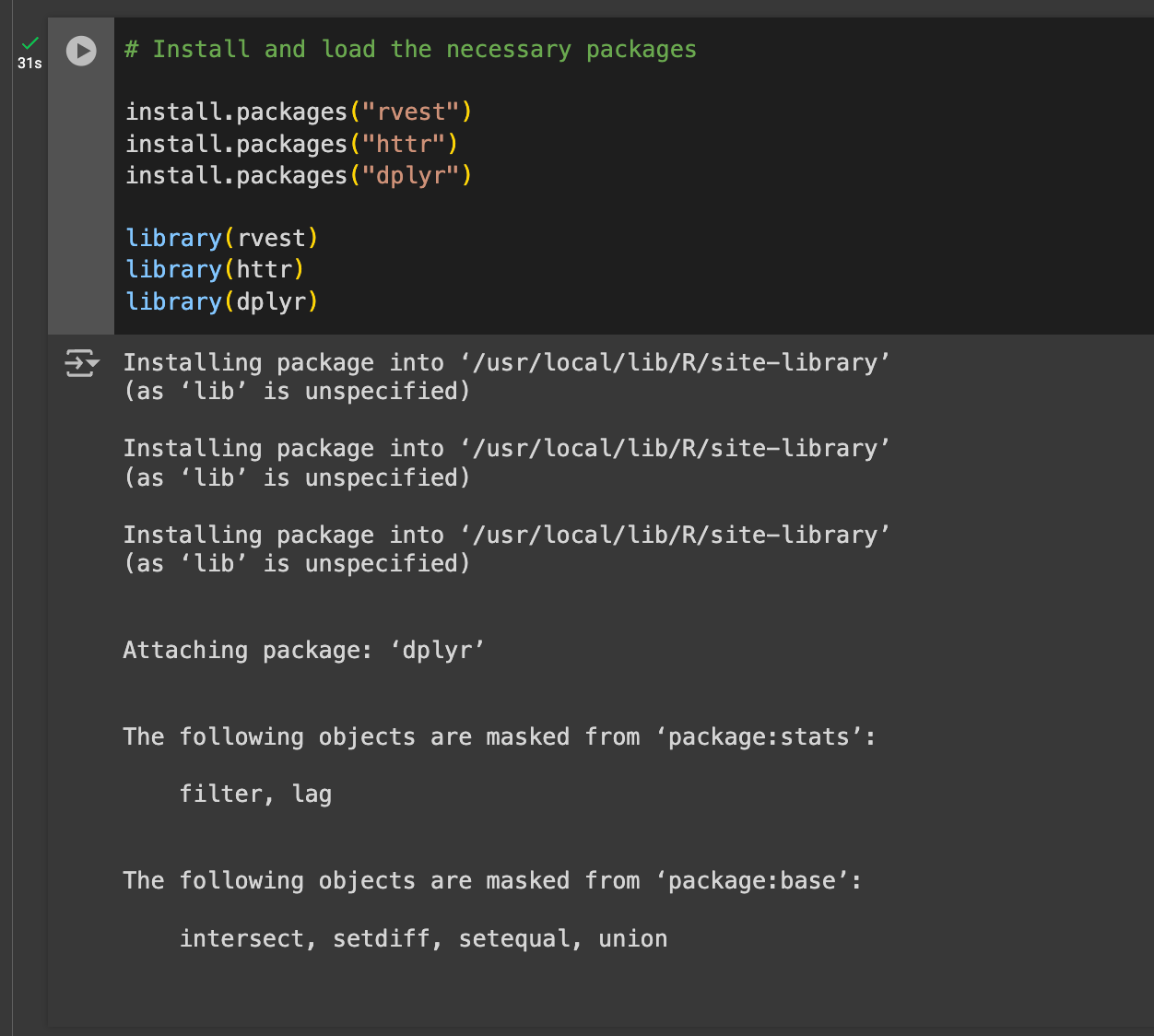
If you see this, you're on the right track.
2. Scraping a website
Now, you're ready to start scraping. Let's target this site: https://www.apify.com.
To begin, add the following code:
# Specify the URL of the Apify homepage
url <- "https://www.apify.com"
# Read the HTML content of the webpage
webpage <- read_html(url)
webpage
The snippet above will define a variable named url, hold the Apify URL, and read its HTML. This will generate the output:
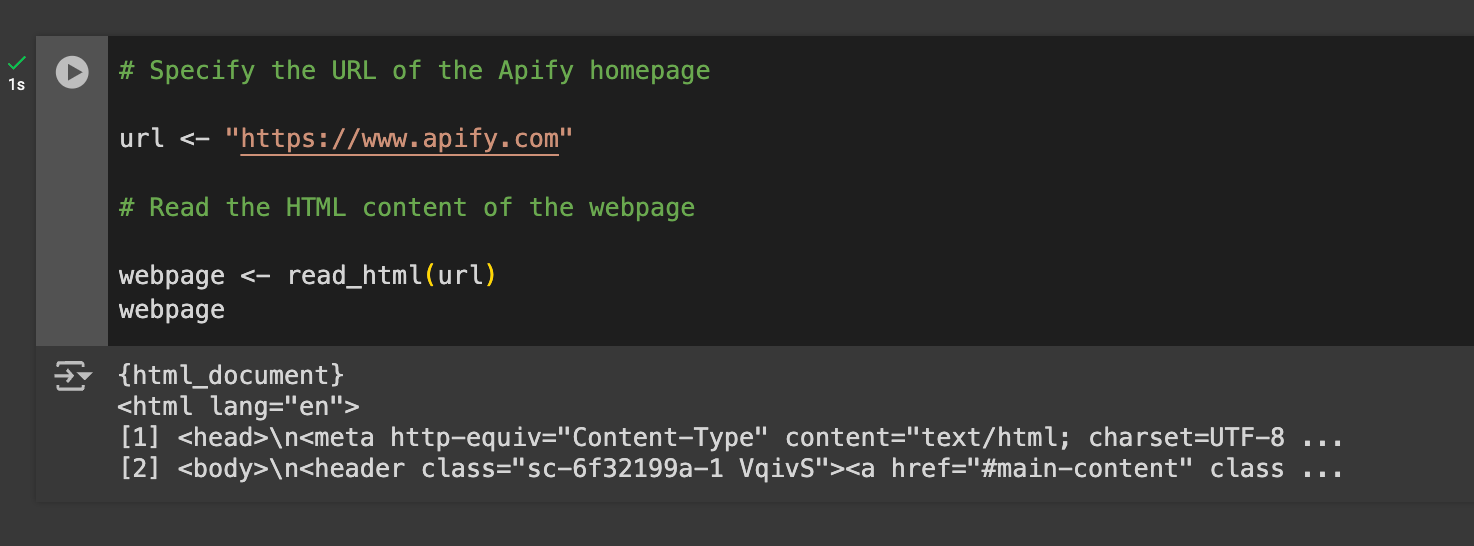
As you can see, you now have the entire HTML page of Apify.com. Now, you can do anything you wish with DOM queries. Let's explore what you can do.
3. Select elements
First, you can select the DOM elements of the site you've just scraped. This can be done using the following method:
elements <- webpage %>%
html_nodes(".class") %>%
html_text()
print("Elements:")
print(elements)
The function above selects elements through a given class name. In our example, Apify.com has elements with the class - sc-fcc5bc6f-0. This corresponds to the hero image, as shown below:
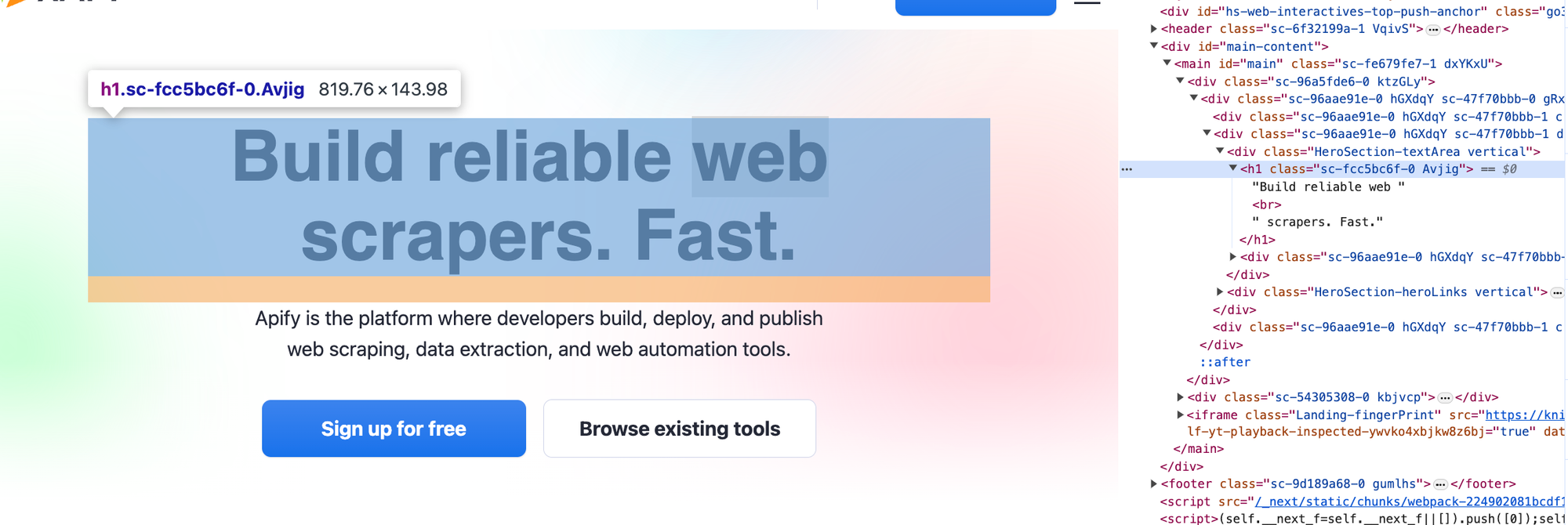
We can fetch such information using the function:
elements <- webpage %>%
html_nodes(".sc-fcc5bc6f-0") %>%
html_text()
print("Elements:")
print(elements)
This outputs the hero text:
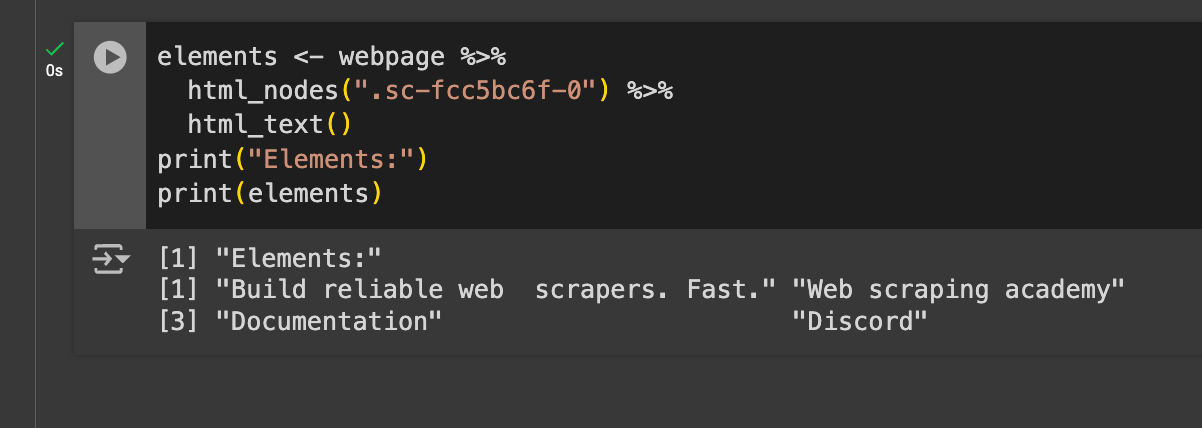
As you can see, it generated the hero text in the response and returned 3 more outputs. This means there are 4 elements in total that rely on this class.
4. Extract data from elements
Next, let's assume that you want to get data from DOM Elements. For instance, Apify.com has anchor tags that consist of links to different parts of their site, and you want to find out what these URLs are. To do this, use the command:
# Extract href attributes from links
links <- webpage %>%
html_nodes("a") %>%
html_attr("href")
print("Hyperlinks:")
print(links)
Replace "a" and "href" with any HTML tag and attribute what you wish to fetch data from. In this case, this would output:
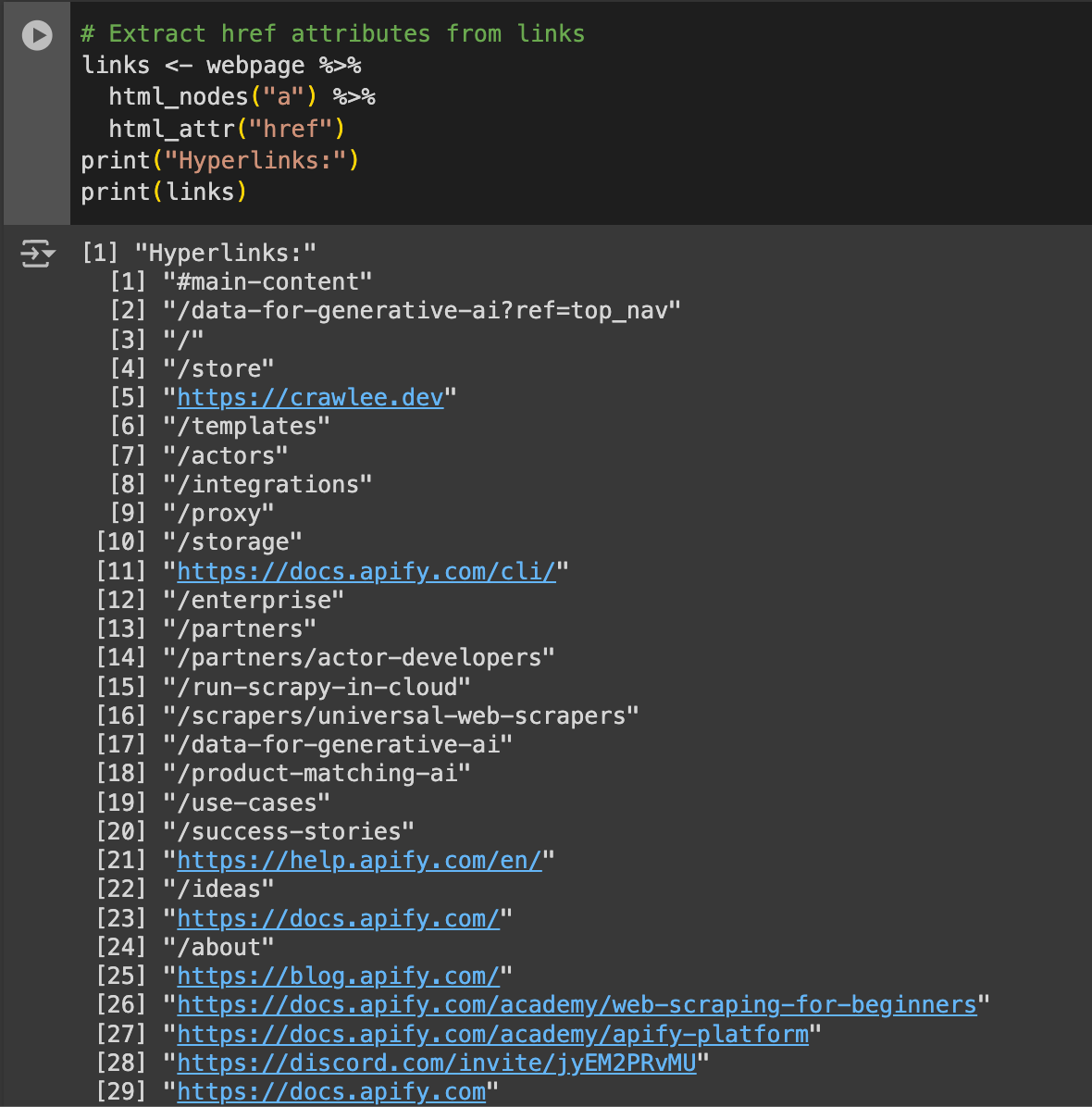
Here, you can analyze all the URLs Apify mentioned on their page. For instance, there's the /proxy page, which is an internal route. However, there are also external Discord and Docs links. For analysis, you can compile a list of URLs and store it in a different database.
5. Scrape tables
Next, let's understand all the HTML tables that Apify has on its site. To do so, run the command:
url <- "https://en.wikipedia.org/wiki/List_of_countries_by_GDP_(nominal)"
# Read the HTML content of the webpage
webpage <- read_html(url)
tables <- webpage %>%
html_table()
print("Tables:")
print(tables)
Apify.com doesn't have an HTML table we can scrape. So, let's scrape a site with tables for this next part. After scraping your tables, you'd have an output similar to this:
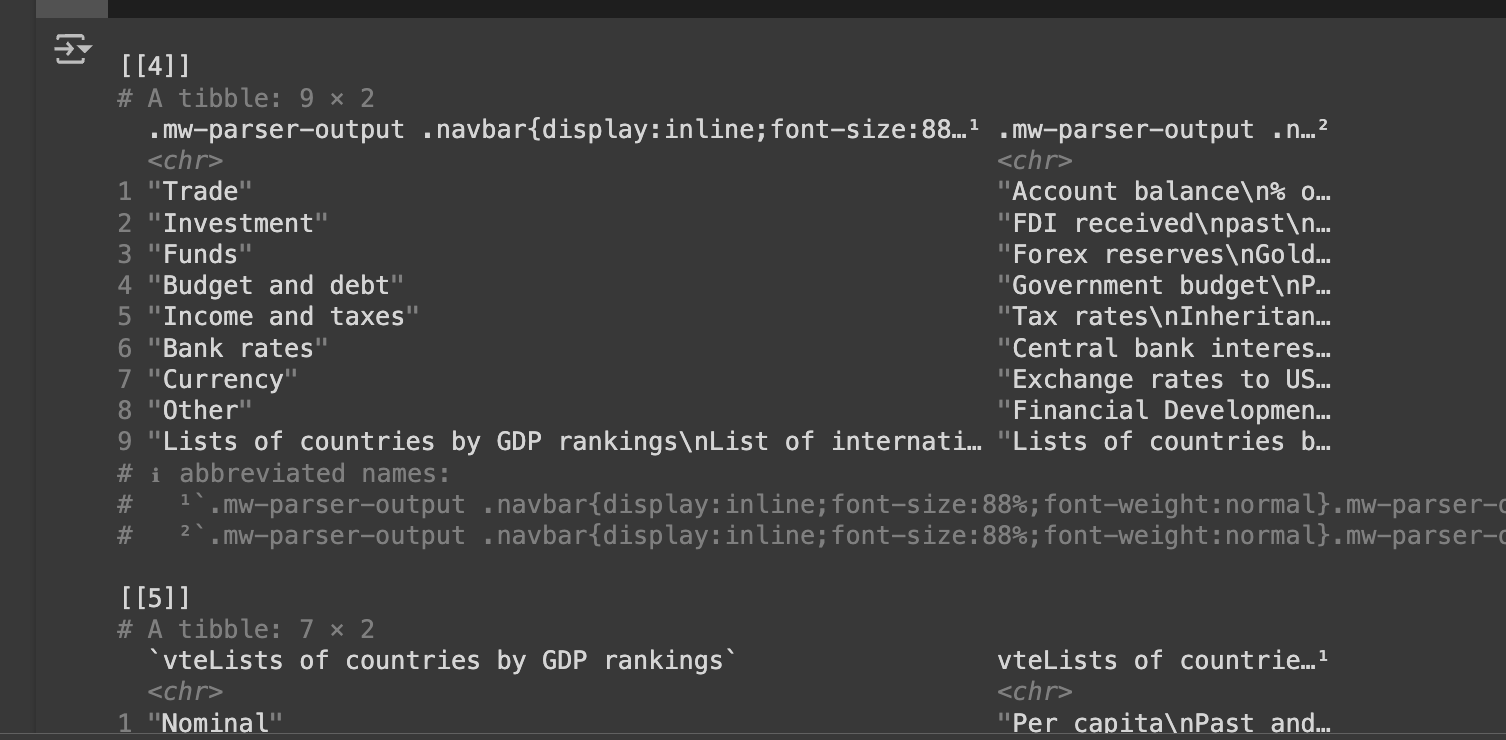
This URL gives us a list of countries with the highest GDP. So, on its own, this output isn't usable at all. You can format this table to get meaningful data for analysis using the following code:
# Extract tables from the webpage
tables <- webpage %>%
html_nodes("table") %>%
html_table(fill = TRUE)
gdp_table <- tables[[3]]
gdp_data <- gdp_table %>%
select(Country = Country/Territory )
# Print the processed data
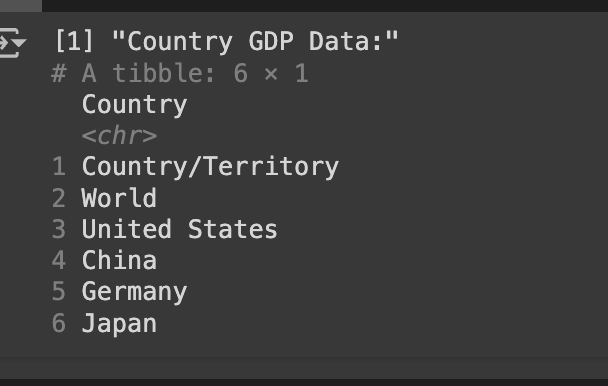
print("Country GDP Data:")
print(head(gdp_data))
The third table is important because it has the GDP information for each country. Next, we manipulate the data using R and create a new dataset with only the country list, which results in the following:
6. Handle forms
Next, we can input data and submit it onto a form. To do so, look at the following code:
form <- webpage %>%
html_form()
filled_form <- form %>%
set_values(input_name = "value")
submitted <- submit_form(session, filled_form)
print("Form Submitted and Response:")
print(submitted)
You can run this on your website with a form, submit data, and get responses using R.
7. Handle lists
Suppose we need to understand what list-based data the Apify website uses. This might be useful if we try curating items we want to show on our scraped list. For this, we can get a list of LI elements that apify.com has used. This can be done using the following code:
list_items <- webpage %>%
html_nodes("ul li") %>%
html_text()
print("List Items:")
print(list_items)
After execution, we should see the output:
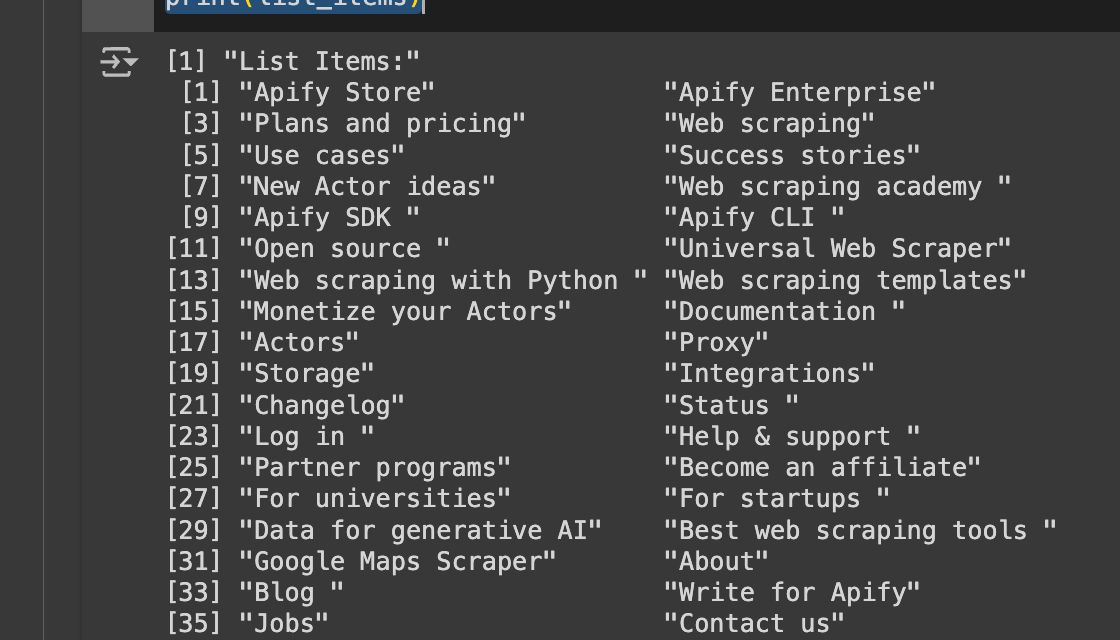
Lists have been used throughout the site, both across the document and in the navigation menu, to hold navigation items.
8. Download images
Finally, we can download static content, such as images, hosted on Apify.com by web scraping with R. To download images, run the command:
image_urls <- webpage %>%
html_nodes("img") %>%
html_attr("src")
print("Image URLs:")
print(image_urls)
This will first inspect all the images that are available on Apify.com. This will generate an output:
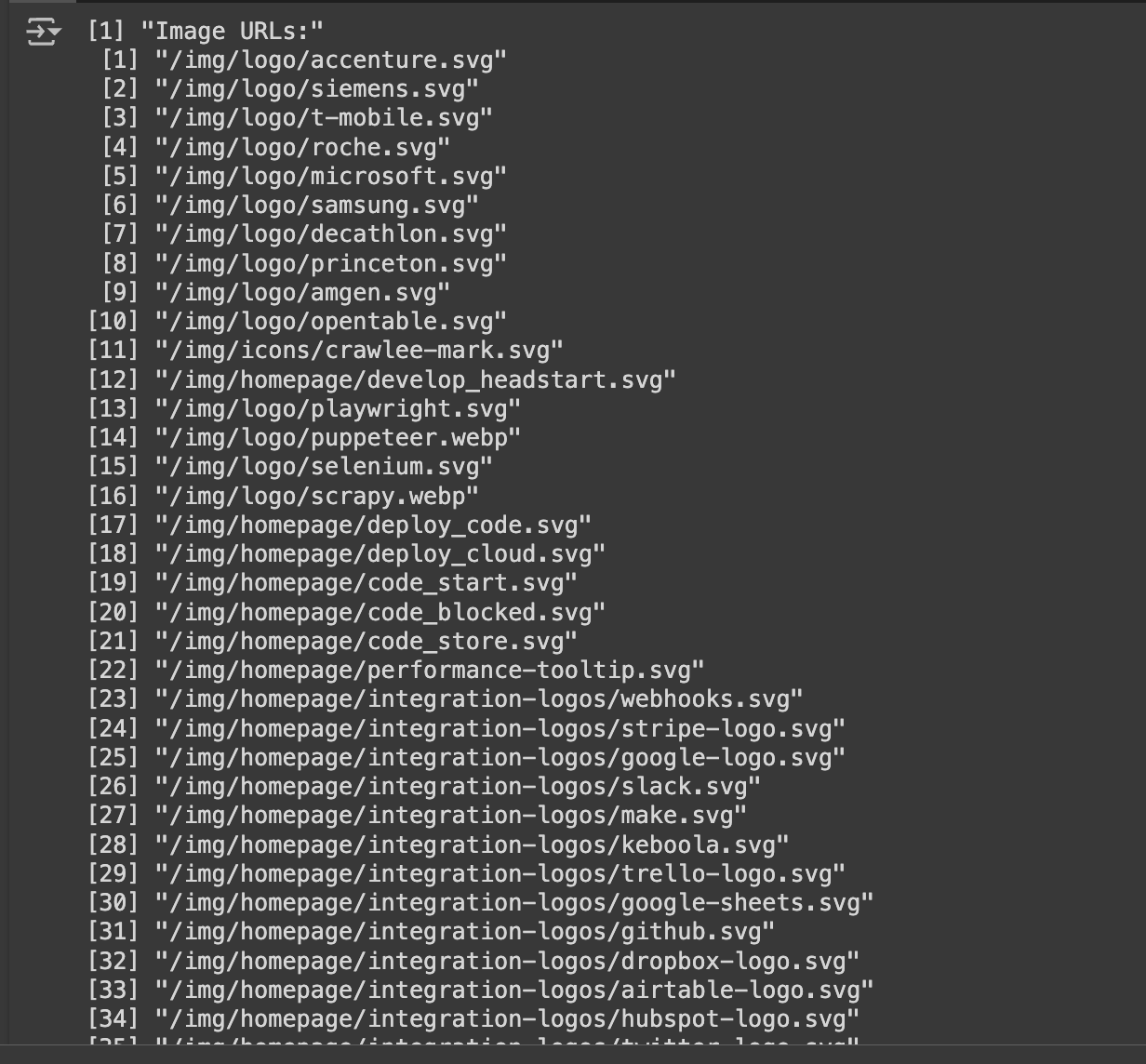
As you can see, the site has quite a few images. But it starts with "/". This means these assets are served with the https://apify.com appended to it, or they are served inside the domain. To download the image, the host must be appended. This can be done using:
# Download all images
for (i in seq_along(image_urls)) {
# Check if URL starts with "/"
if (startsWith(image_urls[i], "/")) {
# Attach "https://www.apify.com" as the host
image_urls[i] <- paste0("https://www.apify.com", image_urls[i])
}
# Create a file name based on the index
file_name <- paste0("image_", i, ".png")
# Download the image
download.file(image_urls[i], destfile = file_name, mode = "wb")
print(paste("Image", i, "downloaded as", file_name))
}
This script downloads all images from a webpage. It first checks if each image URL starts with a "/" (indicating it's a relative URL) and, if so, it adds https://www.apify.com to the beginning to form a complete URL.
It then creates a unique file name for each image based on its position in the list (e.g., image_1.png, image_2.png, etc.).
Finally, it downloads each image using download.file() and saves it with the generated file name, printing a confirmation message for each downloaded image.
After execution, we should see the output:
We can see the files in the directory as shown below:
Advantages of web scraping with R
R is a powerful tool for web scraping. Here's why:
- Analysis and visualization tools:
R has a wide range of packages for data manipulation (dplyr), visualization (ggplot2), and reporting (knitr). This makes it easy to scrape, clean, analyze, visualize, and present your data within the same environment. - Powerful web scraping packages:
R provides packages like,rvestandhttr. These simplify data extraction, handling HTTP requests, parsing HTML and XML content, and navigating the DOM. - Integrations:
R easily integrates data from various sources - websites, databases, APIs, and files. Combine scraped data with other datasets for deeper analysis. - Automated workflows:
R lets you automate web scraping with scripts. Set up workflows to regularly fetch data, update datasets, and generate reports. Perfect for monitoring sites and keeping your data fresh.
Disadvantages of web scraping with R
Like any tool, R web scraping has limitations. Here's what you should keep in mind:
- Performance issues:
R can be slower and less memory efficient than compiled languages. In this case, it's a good idea to learn how to web scrape with Java or C++ for complex tasks or pages. - Handling JavaScript:
R's primary web scraping packages, likervest, are not well-suited for scraping JavaScript-rendered websites. This often requires additional tools like RSelenium. - Dependency management:
Dependency management is tricky, as R relies on multiple packages. Script maintenance is ongoing, as package updates or website changes can break your code. This requires frequent adjustments to keep your scraping tools functional.
Should you use R for web scraping?
R is great for building complex datasets for analysis. However, it might not be the best choice for complex or dynamic, JavaScript-rendered pages. If you're dealing with that kind of scraping, consider using Python instead. If you'd like a simpler approach, look into tools like Apify that can help you quickly build and deploy web scraping solutions.