Selenium element location is a common challenge in web scraping and automation testing. Dynamic websites can make reliable element identification particularly complex, leading to script failures and data accuracy issues.
This guide covers Selenium's element location methods with Python code examples. While we use Python here, these principles apply across Selenium's supported languages.
findElement vs findElements in Selenium
Selenium provides two main methods for locating web elements: find_element and find_elements in Python.
findElement
The find_element() method in Selenium is used to locate a single element on a webpage. It returns the first element that matches the specified locator strategy. If no element is found, it raises a NoSuchElementException.
This method is useful when you need to interact with a specific element, such as logging into a website by locating the username and password fields or clicking buttons to submit forms.
Here’s the syntax:
element = driver.find_element(By.locator_strategy("locator_value"))
In this syntax, By.locator_strategy specifies the method for locating the element (such as ID, class name, or XPath). Selenium provides several built-in locator strategies, including:
- ID
- Name
- Class name
- Tag name
- Link text
- Partial link text
- XPath
Also, the locator strategy requires a locator value to uniquely identify the web element.
Now, if you want to use ID as the locator strategy to identify an element, you would write:
element = driver.find_element(By.ID, "elementId")
As you can see, ID is the locator strategy, and "elementId" is the locator value, which you can find by inspecting the HTML of the webpage and locating the id attribute of the target element. We'll discuss this in more detail in further sections.
findElements
The find_elements() method in Selenium is used to locate multiple elements on a webpage. It returns a list of all elements that match the specified locator strategy. If no matching elements are found, it returns an empty list instead of throwing an exception.
This method is useful when interacting with multiple elements, such as extracting a list of product names on an e-commerce site or collecting all links on a webpage.
Here’s the syntax:
elements = driver.find_elements(By.locator_strategy, "locator_value")
Just like find_element(), the find_elements() method also accepts a locator strategy and locator value, but it returns a list of WebElement objects instead of a single element.
Now that we've covered both find_element() and find_elements() in Python Selenium, let’s explore how to find elements using different locator strategies in detail. We will focus on the Python implementation, but keep in mind that the syntax in other languages like Java, JavaScript, and C# is slightly different, but the core functionality remains the same.
How to find elements in Selenium
Selenium offers multiple locator strategies for webpage elements, each suited to different scenarios. The following examples use Selenium Python's find_element and find_elements methods to demonstrate these strategies.
Important: Website structural changes may break element selectors. If your script fails, check whether the target website's layout has changed and update your selectors accordingly.
Find by ID
Finding elements by ID is a simple and effective method since IDs are unique on a webpage. However, if the IDs are dynamically generated (changing with each page load or session), this method may not be reliable. In such cases, alternative locator strategies are more useful, as we’ll see in the following sections. When the ID is static, this approach is ideal for identifying elements.
Let’s look at an example to understand how this works. Below is a screenshot of the Apple website. We want to extract all the text in the navigation bar, such as "Store," "Mac," "iPad," "iPhone," and more.
As you can see, all the navbar texts are stored inside an ul tag with ID globalnav-list. We’ll use this ID to extract all the available text.
Here's the code:
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
url = "https://www.apple.com/in/"
driver.get(url)
# find by ID
nav = driver.find_element(By.ID, "globalnav-list")
print(nav.text)
driver.quit()
Run the code, and you'll get the following output:
$ python main.py
Apple
Store
Mac
iPad
iPhone
Watch
AirPods
TV & Home
Entertainment
Accessories
Support
Nice! We successfully extracted all the desired text using the element’s ID.
Find by name
Similar to find by ID, the name attribute can be used to locate elements, especially in forms like input fields. For example, when logging into Hacker News, you can target fields such as username and password using the name attribute.
To target these fields, use the By.NAME locator strategy:
driver.find_element(By.NAME, "acct")
driver.find_element(By.NAME, "pw")
Here’s the complete code:
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
import time
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
url = "https://news.ycombinator.com/login"
driver.get(url)
username = "user" # Your Hacker News username
password = "pass" # Your Hacker News password
# find by Name
driver.find_element(By.NAME, "acct").send_keys(username)
driver.find_element(By.NAME, "pw").send_keys(password)
time.sleep(3)
driver.quit()
When you run the code, the username and password fields will be automatically filled with the input values you provide:
Find by XPath
XPath is a powerful way to locate and navigate elements in HTML and XML documents. Let's use XPath to extract all the news titles from the Hacker News homepage.
As you can see, the titles are stored within span tags with the class titleline. Here’s the XPath expression you can use with the By.XPATH method to extract the data.
element = driver.find_element(By.XPATH, "//span[contains(@class, 'titleline')]")
To extract the first news article, here’s a simple code snippet:
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
url = "https://news.ycombinator.com/"
driver.get(url)
# find by XPath
element = driver.find_element(By.XPATH, "//span[contains(@class, 'titleline')]")
print(element.text)
driver.quit()
The output will display the first news article title:
$ python main.py
How the iPhone 16's electrically-released adhesive works (ifixit.com)
Now, to extract all the news articles, simply use the find_elements() method instead of find_element(). Here’s the modified code:
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
url = "https://news.ycombinator.com/"
driver.get(url)
# find by XPath
elements = driver.find_elements(By.XPATH, "//span[contains(@class, 'titleline')]")
for element in elements:
print(element.text)
driver.quit()
The output will display all the news titles:
$ python main.py
How the iPhone 16's electrically-released adhesive works (ifixit.com)
GPU Puzzles (github.com/srush)
Low Cost C02 Sensors Comparison: Photo-Acoustic vs. NDIR (airgradient.com)
Qocker is a user-friendly Qt GUI application for managing Docker containers (github.com/xlmnxp)
Brainfuck Enterprise Solutions (github.com/bf-enterprise-solutions)
What's inside the QR code menu at this cafe? (peabee. substack.com)
Dot (YC S21) Is Hiring an Engineer to Automate Analytics (Remote) (ycombinator.com)
Court orders Google to uninstall pirate IPTV app sideloaded on Android devices (torrentfreak.com)
Ask HN: Good Sites for/with AI Enthusiasts?
The Palletrone is a robotic hovercart for moving stuff anywhere (ieee. org)
Rawdrawandroid - Build Android apps without any Java, in C and Make (github.com/cnlohr)
Show HN: Time Flies (koenvangilst.nl)
...
...
...
Awesome! We've successfully extracted all the news titles using XPath.
One of the main reasons for using XPath is when an element doesn’t have a suitable id or name attribute. XPath allows you to locate elements in such cases by either using an absolute path (though this is generally not recommended) or by finding the element relative to another element that has a suitable id or name attribute.
Find by link text
In Selenium, you can locate anchor elements (<a>) by their visible text. This approach is particularly useful when you need to click or interact with links using their displayed text. For example, let’s locate the anchor tag with the visible text "jobs" on the Hacker News website.
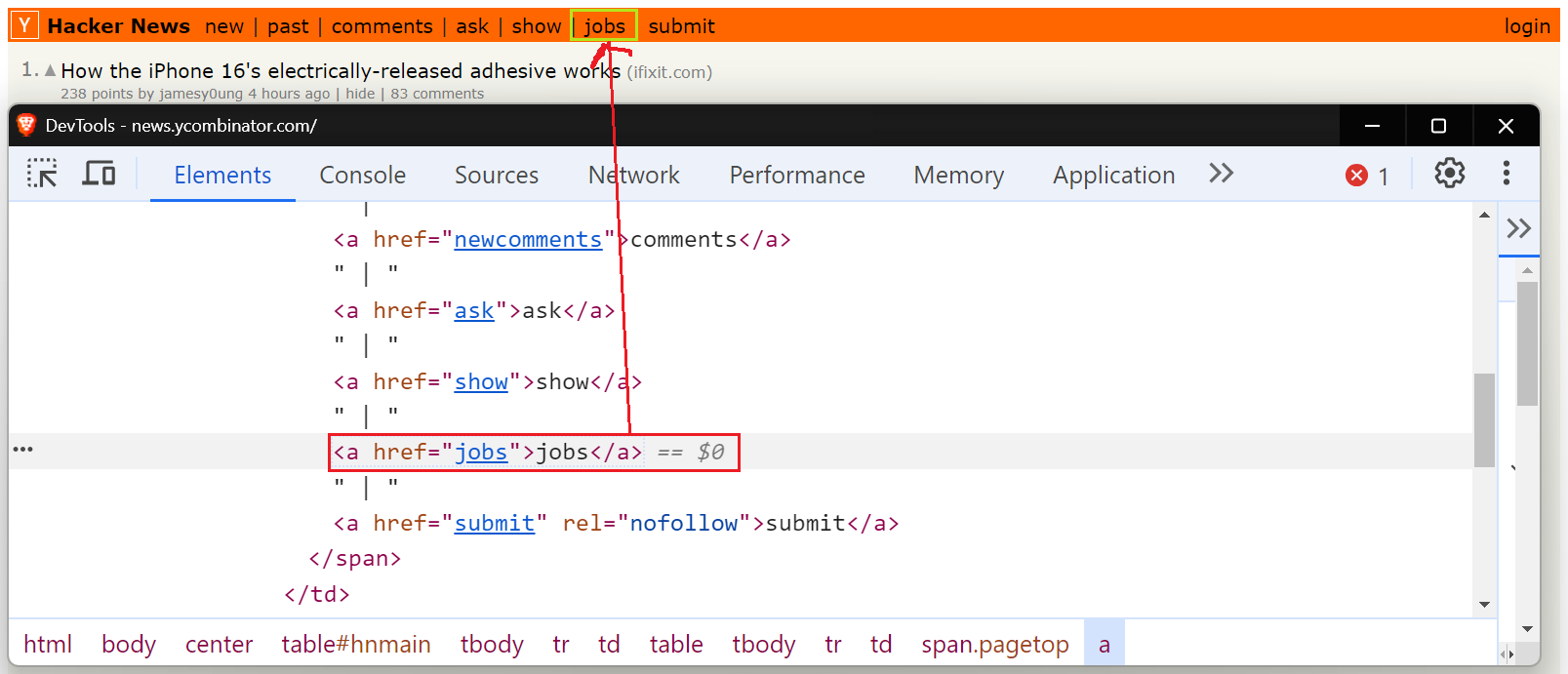
Selenium provides two ways to find links by text:
By.LINK_TEXT: Locates a link using its exact visible text.By.PARTIAL_LINK_TEXT: Locates a link using a portion of its visible text. Only the first one will be returned if multiple links match the partial text.
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
url = "https://news.ycombinator.com/"
driver.get(url)
# find by Link Text
jobs_link = driver.find_element(By.LINK_TEXT, "jobs")
# OR
jobs_link2 = driver.find_element(By.PARTIAL_LINK_TEXT, "jo")
print(jobs_link.text)
print(jobs_link.get_attribute("href"))
print(jobs_link2.get_attribute("href"))
driver.quit()
The result is:
$ python main.py
jobs
https://news.ycombinator.com/jobs
https://news.ycombinator.com/jobs
Find by tag name
Finding elements by their tag name is useful when you need to interact with elements of a particular type, such as <div>, <button>, <a>, headings, or <input>. Let’s find all the <h2> headers from a Wikipedia page using the By.TAG_NAME method.
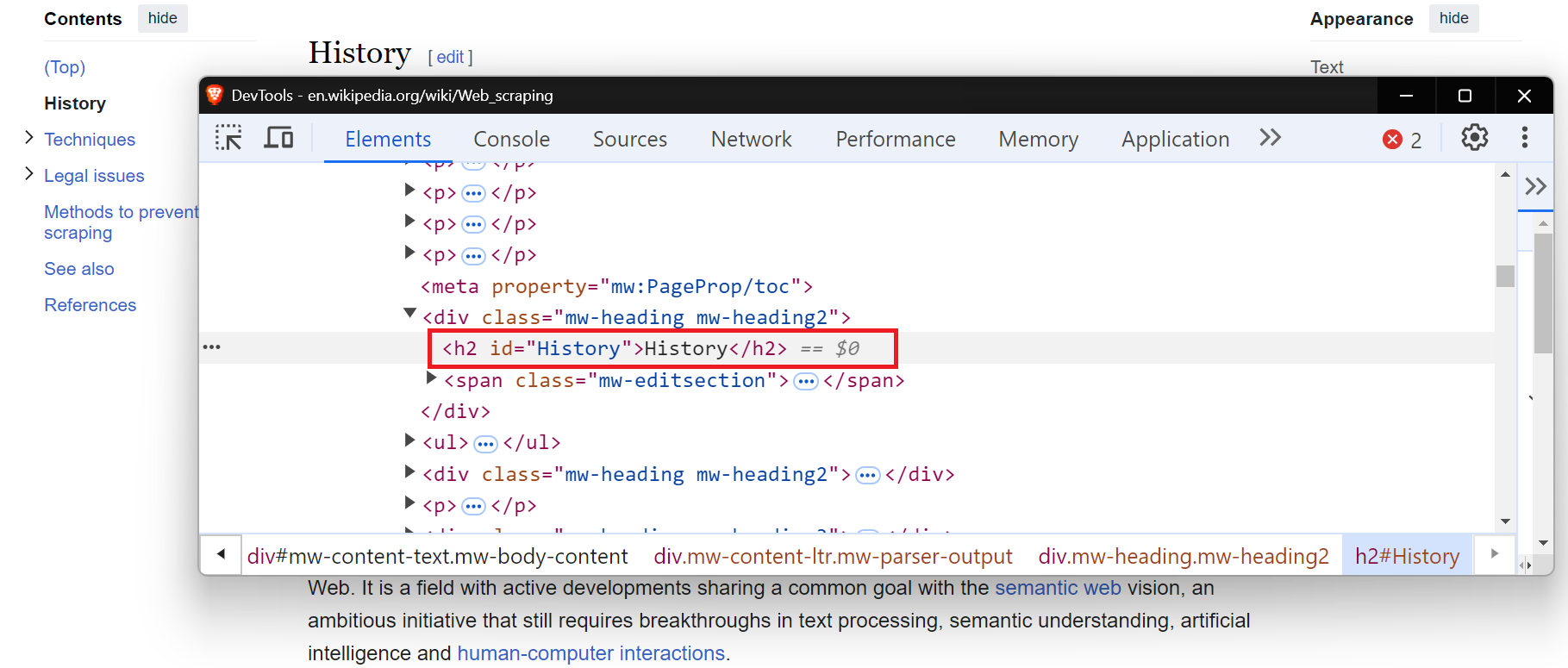
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
url = "https://en.wikipedia.org/wiki/Web_scraping"
driver.get(url)
# Find by Tag Name
h2_elements = driver.find_elements(By.TAG_NAME, "h2")
for h2 in h2_elements:
print(h2.text)
driver.quit()
The result will display all the <h2> elements from the page:
$ python main.py
History
Techniques
Legal issues
Methods to prevent web scraping
See also
References
Find by class name
The By.CLASS_NAME is used to locate elements that match a specific class attribute value. You’ve to pass the value of the class attribute as the locator.
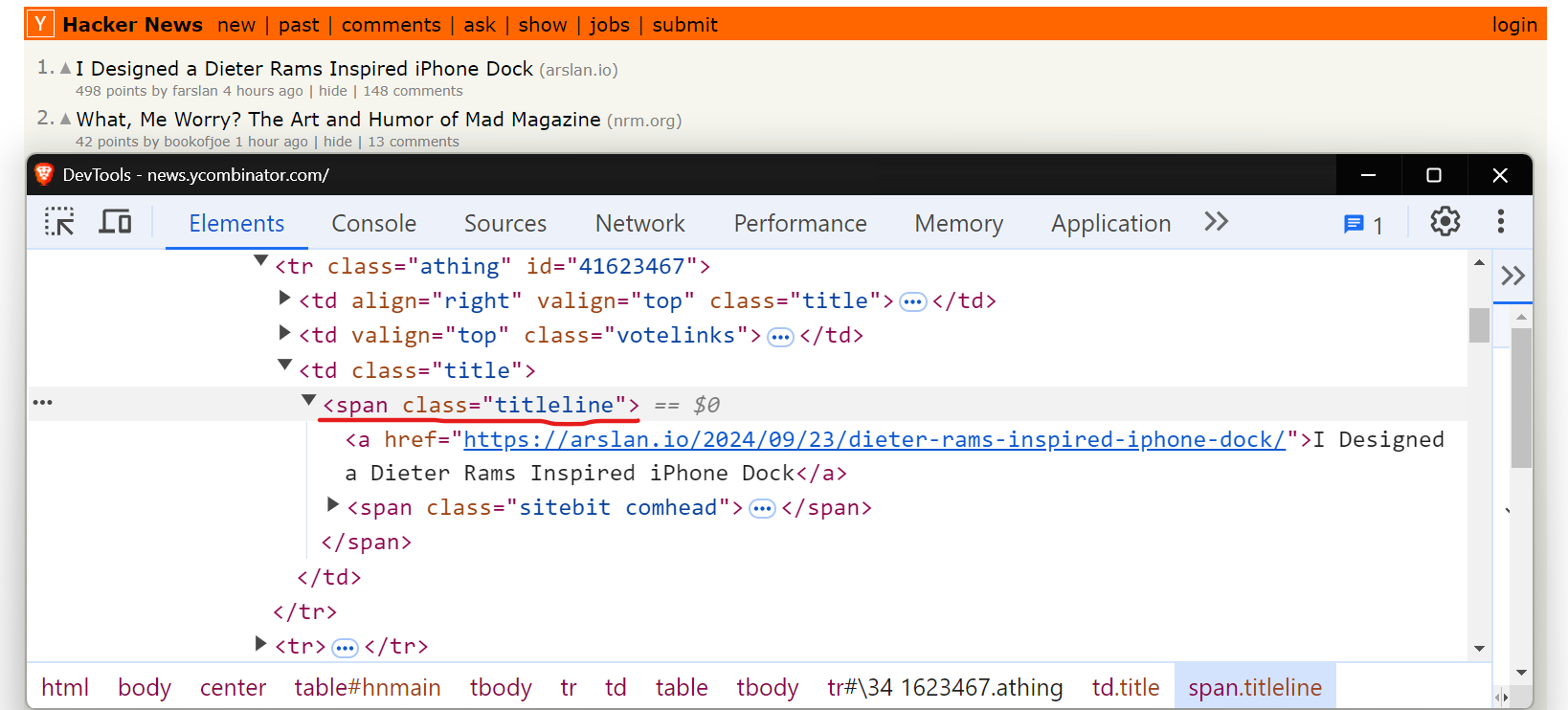
Here’s the code extracting all titles with the titleline class:
from selenium import webdriver
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
url = "https://news.ycombinator.com/"
driver.get(url)
# find by Class Name
titles = driver.find_elements(By.CLASS_NAME, "titleline")
for title in titles:
print(title.text)
driver.quit()
The result will display all the titles:
$ python main.py
I designed a Dieter Rams-inspired iPhone dock (arslan.io)
In 1870, Lord Rayleigh used oil and water to calculate the size of molecules (atomsonly.news)
iPhone 16 Pro Storage Expansion 128GB to 1TB [video] (youtube.com)
Show HN: I Wrote a Book on Java
We fine-tuned Llama 405B on AMD GPUs (publish. obsidian.md)
Inside a Ferroelectric RAM Chip (righto.com)
A brief look at the new Kamal Proxy (strzibny. name)
What, Me Worry? The Art and Humor of Mad Magazine (nrm. org)
Free-form floor plan design using differentiable Voronoi diagram (github. com/nobuyuki83)
Launch HN: Panora (YC S24) - Data Integration API for LLMs (github. com/panoratech)
GPU Puzzles (github. com/srush)
Picking Glibc Versions at Runtime (blogsystem5. substack.com)
...
...
...
Find by CSS selectors
CSS selectors are a powerful way to locate elements by combining tag names, classes, IDs, and attributes. For example, if you want to extract the price of a product from Amazon, you can use the CSS selector div[data-cy='price-recipe'] span.a-offscreen. This selector accurately targets the price.
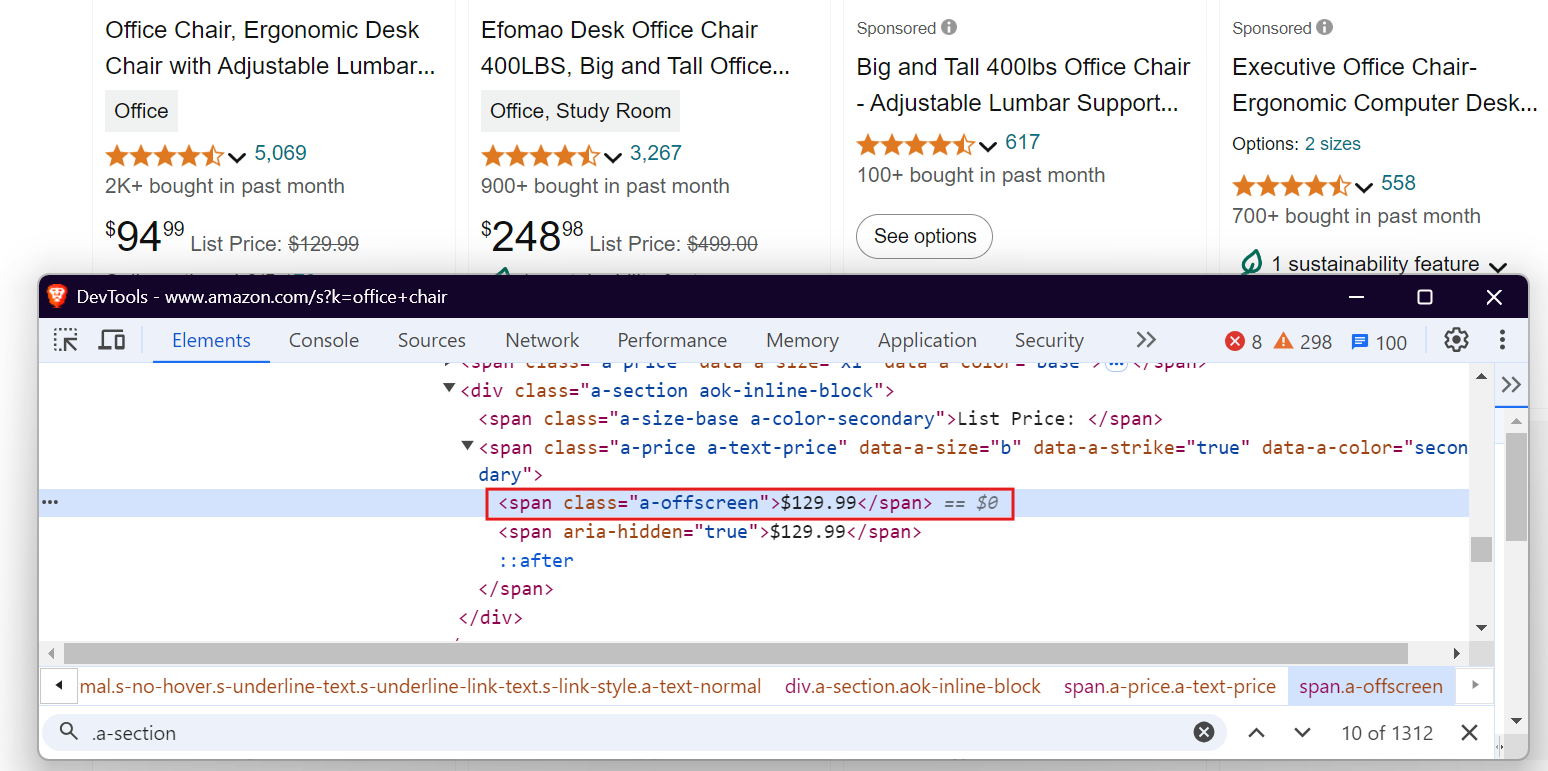
Here’s the code:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManager
service = Service(ChromeDriverManager().install())
driver = webdriver.Chrome(service=service)
driver.get("https://www.amazon.com/s?k=office+chair")
price_element = driver.find_element(
By.CSS_SELECTOR, "div[data-cy='price-recipe'] span.a-offscreen"
)
price = price_element.text
print(f"Price: {price}")
driver.quit()
The result shows the price of a flight:
$ python main.py
Price: $69.49
Wrapping up
This guide covered Selenium's findElement and findElements methods and their associated locator strategies. While our examples use Python, these element location principles apply across Selenium's language implementations.
Effective element location starts with analyzing your target website's DOM tree to select appropriate locators. This approach helps create maintainable scripts that adapt to website structure changes.
Templates for Requests, Beautiful Soup, Scrapy, Playwright, Selenium