You can’t make timely investment decisions without reliable stock market data. Yet, most stock market trackers delay data by at least 15 minutes, and public APIs often throttle when market volatility spikes or require paid plans.
This guide shows you how to bypass those limitations by automatically scraping stock data directly from Nasdaq using Python.
We’ll walk you through the full process - from setting up your project to deploying your scraper on the Apify platform, so your data collection runs on autopilot and stays accessible from anywhere.
Scraping Nasdaq stock market data in Python
In this tutorial, we'll focus on extracting stock market data for NVIDIA (NVDA) from the historical stock page on Nasdaq.com:
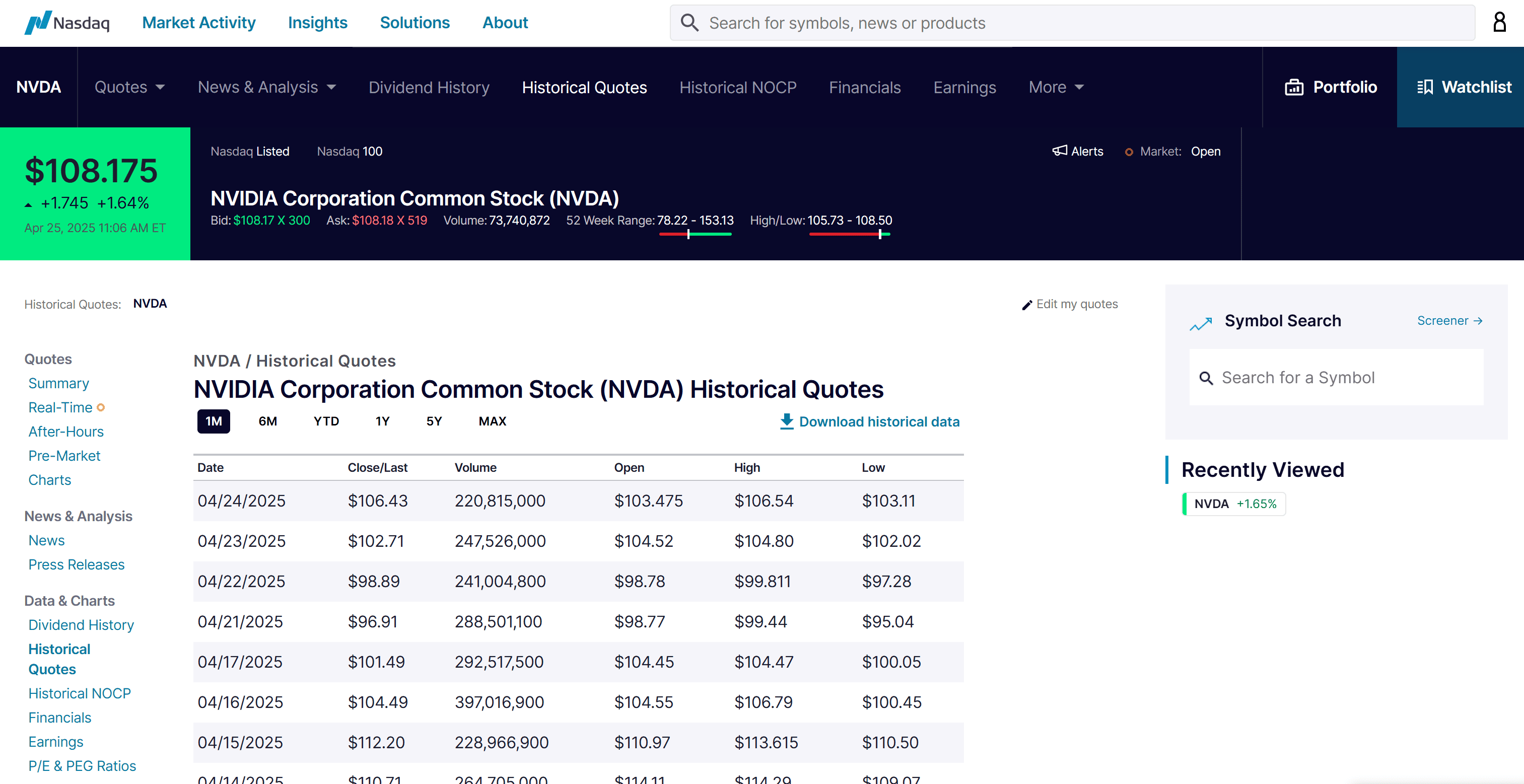
The scraping process will involve the following steps:
- Prerequisites and project setup
- Choose the scraping libraries
- Install the scraping library
- Connect to the target page
- Select the stock data rows from the table
- Extract stock data from the row cells
- Collect the scraped data
- Implement the pagination logic
- Export to CSV
- Complete code
- Deploy to Apify
1. Prerequisites and project setup
To follow along with this tutorial, make sure you meet the following prerequisites:
- A basic understanding of how the web works
- Familiarity with the DOM, HTML, and CSS selectors
- Knowledge of how JavaScript rendering and dynamic web pages work
- Understanding of AJAX and RESTful APIs
Since Python is the primary language used in this Nasdaq scraping guide, you'll also need:
- Python 3+ installed on your local machine
- A Python IDE, such as Visual Studio Code with the Python extension or PyCharm
- Basic knowledge of Python and asynchronous programming
To set up your Python project, begin by creating a new folder:
mkdir nasdaq-scraper
Then, navigate into it and initialize a virtual environment inside it:
cd nasdaq-scraper
python -m venv venv
Open the project in your IDE and create a file named scraper.py. That's where you'll write your scraping logic.
To activate the virtual environment on Windows, open the IDE's terminal and run the following:
venv\Scripts\activate
Equivalently, on Linux/macOS, execute:
source venv/bin/activate
2. Choose the scraping libraries
Before diving into coding, you need to get familiar with the Nasdaq stock data source you'll be working with. In this case, the target will be the official website of the Nasdaq stock exchange (nasdaq.com).
To analyze the website for Nasdaq stock market scraping:
- Open your browser in incognito mode (to ensure a fresh session) and navigate to the target webpage. In this example, visit the NVIDIA historical data page.
- Right-click anywhere on the page and select "Inspect" to open Chrome DevTools.
- Reload the page and go to the “Network” tab to observe the dynamic requests the page makes behind the scenes.
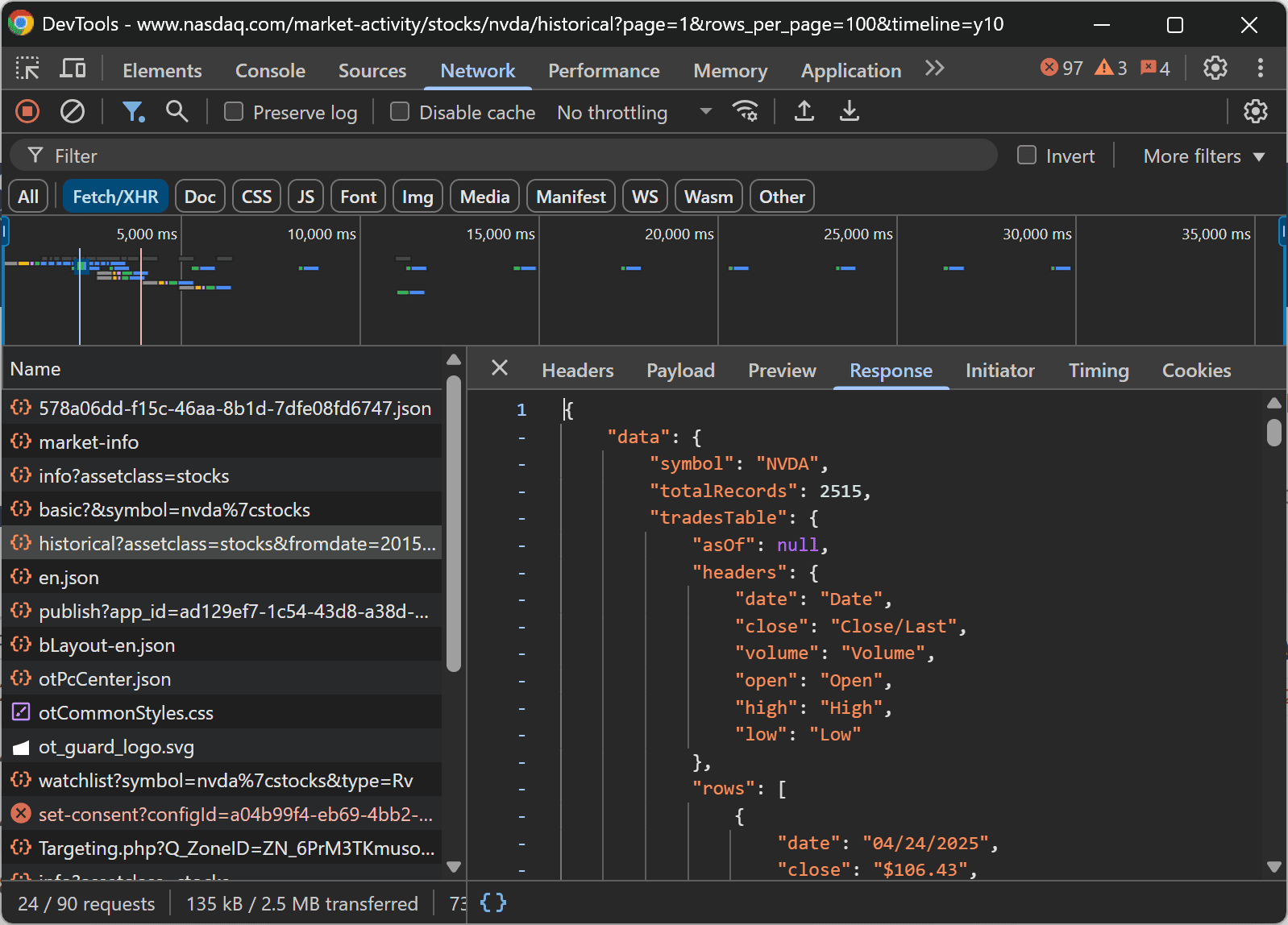
As you inspect the network activity, you'll notice that the stock data is loaded dynamically via AJAX. Specifically, the browser sends a GET request to the following endpoint:
https://api.nasdaq.com/api/quote/NVDA/historical?assetclass=stocks&fromdate=2015-04-25&limit=100&todate=2025-04-25
This discovery confirms that the target site is dynamic, meaning it loads data through JavaScript rather than serving it as static HTML. To scrape pages like that, you need a browser automation tool that can execute JavaScript—because only browsers can do that.
In this tutorial, we'll use Playwright as the automation tool but keep in mind that Selenium would also be a valid alternative.
3. Install the scraping library
As learned in the previous step, scraping the Nasdaq site requires a browser automation tool like Playwright.
Inside your activated virtual environment, install Playwright by running:
pip install playwright
After installing the library, make sure to download the necessary browser binaries and dependencies with:
python -m playwright install
This command sets up everything Playwright needs to launch and control browser sessions correctly.
4. Connect to the target page
Open your browser, go to Nasdaq.com, and search for the “NVDA” stock ticker. Then, click on the NVDA stock page:
From the top menu, select the "Historical Quotes" link:
The resulting page displays a table containing historical stock price data:
Assume that you are interested in scraping all available historical stock data. So, first set the time range to the “MAX” option. Also, change the number of rows displayed to “100” to load more entries at once:
Once the page loads, the browser’s address bar should show a URL similar to:
https://www.nasdaq.com/market-activity/stocks/nvda/historical?page=1&rows_per_page=100&timeline=y10
Copy the URL, as that it will be the target that your Nasdaq scraper visits.
As you can see, Nasdaq’s historical data URL follows this format:
https://www.nasdaq.com/market-activity/stocks//historical?page=&rows_per_page=&timeline=
Now, open your scraper.py file and add the following Playwright code:
import asyncio
from playwright.async_api import async_playwright
async def run():
async with async_playwright() as p:
# Initialize a new Playwright instance
browser = await p.chromium.launch(
headless=False # Set to True in production
)
context = await browser.new_context()
page = await context.new_page()
# The ticker of the stock to scrape data about
stock_ticker = "nvda"
# The URL of the Nasdaq stock page
url = f"https://www.nasdaq.com/market-activity/stocks/{stock_ticker.lower()}/historical?page=1&rows_per_page=100&timeline=y10"
# Navigate to the target Nasdaq page
await page.goto(url)
# Scraping logic...
# Close the browser and release its resources
await browser.close()
if __name__ == "__main__":
asyncio.run(run())
The above script uses Playwright’s asynchronous API to launch a Chromium browser, visit the Nasdaq historical data page for the NVDA stock, and close the browser cleanly.
headless=False forces the browser to run in headed mode. While that'sn't ideal for production (as it consumes more resources), it's necessary for Nasdaq.com. The site uses strict anti-bot measures that block most headless browsers. Running in headed mode helps bypass these restrictions.Next, place a breakpoint on browser.close() and run your script in a debugger. You should see something like this:
Playwright opens a Chromium browser and navigates to the Nasdaq NVDA historical data page.
5. Select the stock data rows from the table
Before diving into the scraping logic, you'll need a data structure to store the stock data extracted from the page. Since the historical quotes are listed in multiple rows, a list is a great fit:
stock_data = []
Place this line at the top of the run() function, outside the Playwright async block.
Next, inspect the HTML structure of the table to determine how to select the correct elements. On the Nasdaq page, right-click one of the table rows and select “Inspect” to open the browser’s DevTools:
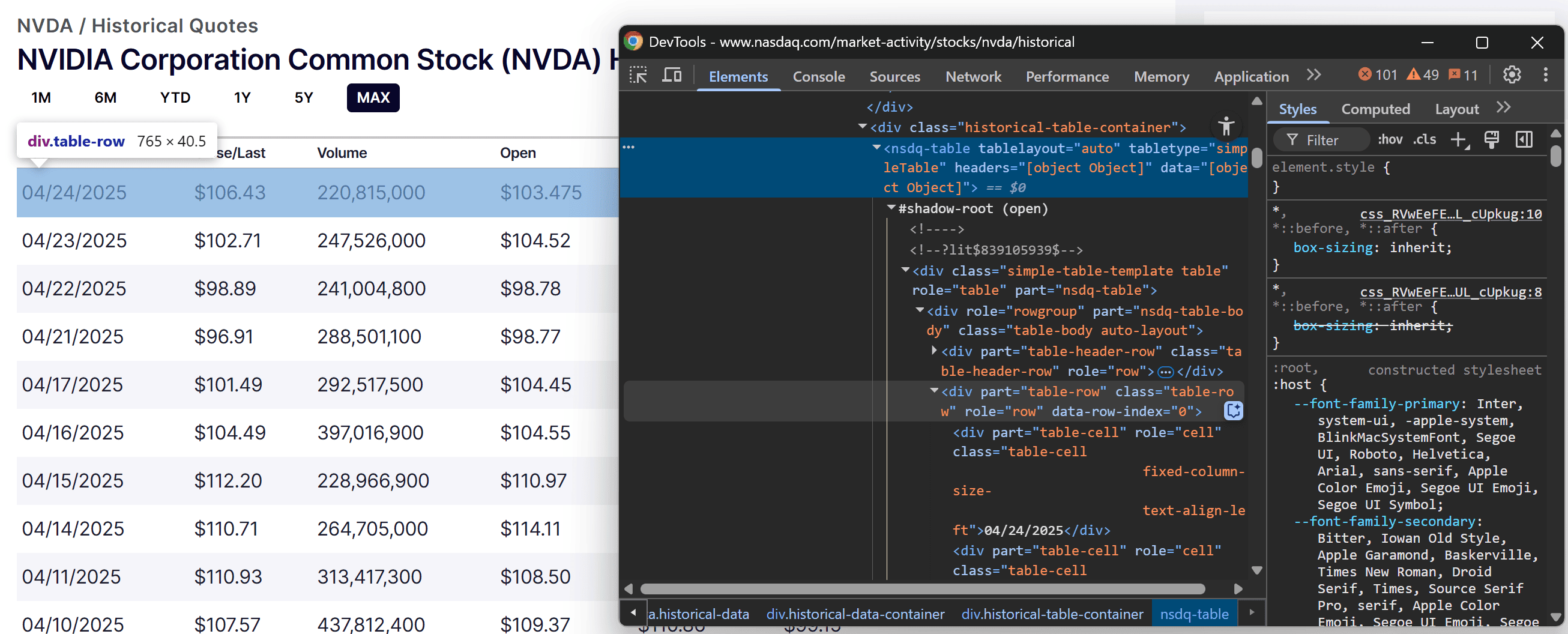
If you aren't familiar with this process, follow our guide on finding elements with DevTools.
As you examine the HTML, you'll notice that the table is rendered using a custom tag. Also, each row containing stock data has a role="row" attribute and a data-row-index attribute.
So, the CSS selector that targets the table rows is:
nsdq-table [role="row"][data-row-index]
Use the Playwright locator() method to apply that selector on the page:
table_row_elements = page.locator("nsdq-table [role=\"row\"][data-row-index]")
Because the stock data is loaded dynamically via AJAX, add a wait instruction to check that at least one row has become visible before proceeding:
await table_row_elements.first.wait_for(state="visible")
Once the rows are available, you can loop through them and begin extracting stock data:
for table_row_element in await table_row_elements.all():
# Scraping logic...
6. Extract stock data from the row cells
Start by inspecting the content of a single row in the table:
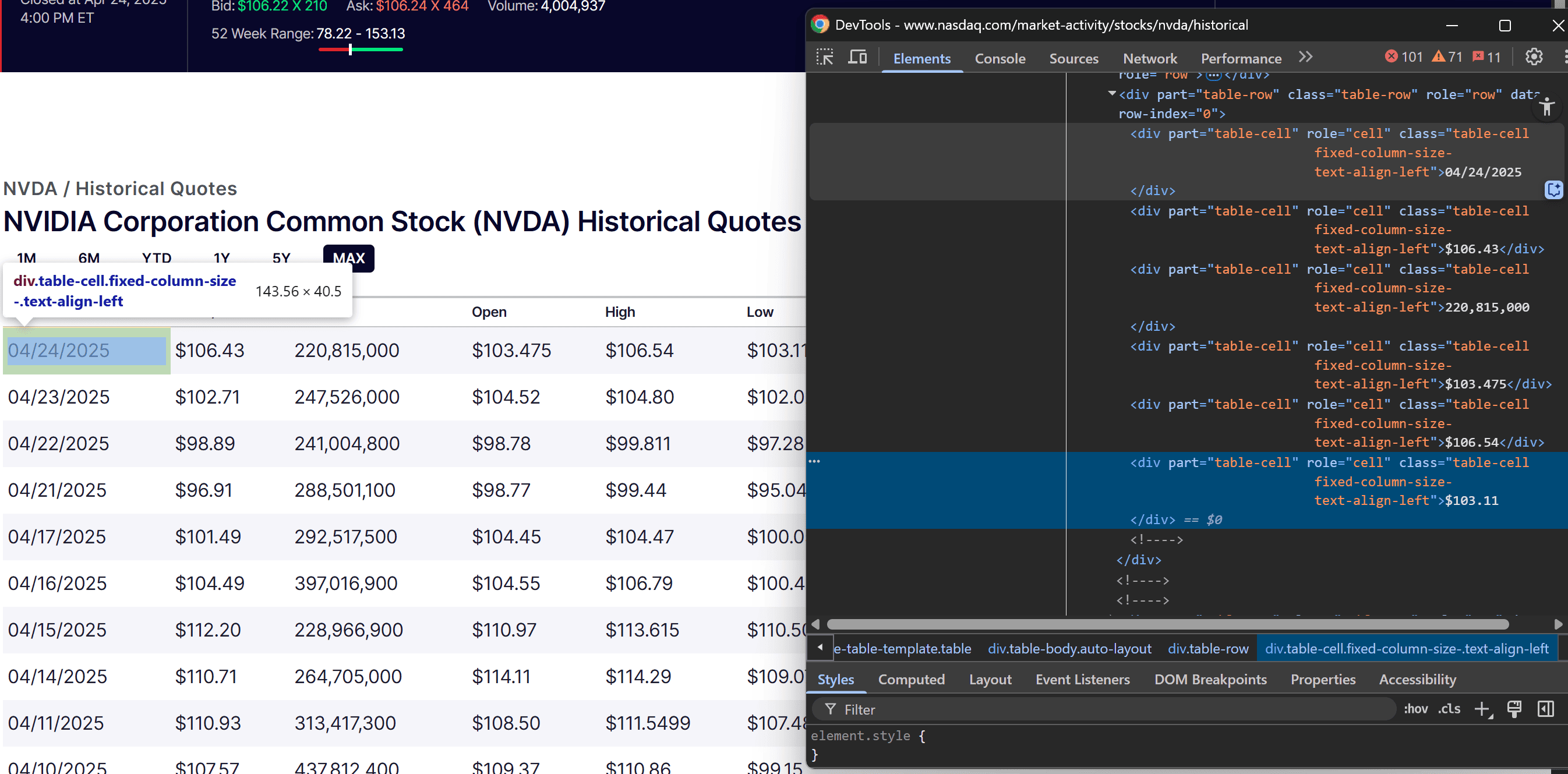
You'll see that each row contains several cells, represented by <div> elements with the role="cell" attribute. In particular, these cells hold the following data:
- Date
- Close price
- Stock volume
- Open price
- High price
- Low price
In other words, you can scrape each data point by targeting the corresponding cell index in the row (from 0 to 5, as Python uses 0-based indexing). Thus, to extract the data programmatically:
- Select all cell elements with the
[role="cell"]attribute. - Retrieve the cell content using an index that ranges from 0 to 5.
- Extract the text from each cell.
- Clean the text data.
Note that the Nasdaq stock market data appears in an easy-to-read format, but you are probably more interested in raw figures. To clean the data, create a specific function:
def clean_stock_data_string(string_value):
return string_value.strip().replace(",", "").replace("$", "")
This removes extra spaces, eliminates commas, and removes the dollar sign ($). That last step is important because all stock prices listed on the Nasdaq exchange are quoted in US dollars. So, it doesn’t make sense to repeat the currency symbol on each number.
Now, integrate the scraping logic within your for loop:
table_cell_elements = table_row_element.locator("[role=cell]")
# If the row contains the expected number of cells
if await table_cell_elements.count() >= 5:
date_cell_element = table_cell_elements.nth(0)
date = clean_stock_data_string(await date_cell_element.text_content())
close_cell_element = table_cell_elements.nth(1)
close = clean_stock_data_string(await close_cell_element.text_content())
volume_cell_element = table_cell_elements.nth(2)
volume = clean_stock_data_string(await volume_cell_element.text_content())
open_cell_element = table_cell_elements.nth(3)
open_value = clean_stock_data_string(await open_cell_element.text_content())
high_cell_element = table_cell_elements.nth(4)
high_value = clean_stock_data_string(await high_cell_element.text_content())
low_cell_element = table_cell_elements.nth(5)
low_value = clean_stock_data_string(await low_cell_element.text_content())
7. Collect the scraped data
Within the nested for loop, use the populate a new dictionary object with the scraped data:
stock_data_entry = {
"date": date,
"close": close,
"volume": volume,
"open": open_value,
"high": high_value,
"low": low_value
}
Next, append the dictionary to the stock_data list:
stock_data.append(stock_data_entry)
stock_data will now contain all the entries collected by your Nasdaq scraper from the table.
8. Implement the pagination logic
Do not forget that the table on the page only shows the first 100 rows. To scrape the remaining stock data entries, you need to implement custom pagination logic to navigate through the other pages of stock market data.
Try to click on page 2 in the pagination element below the table:
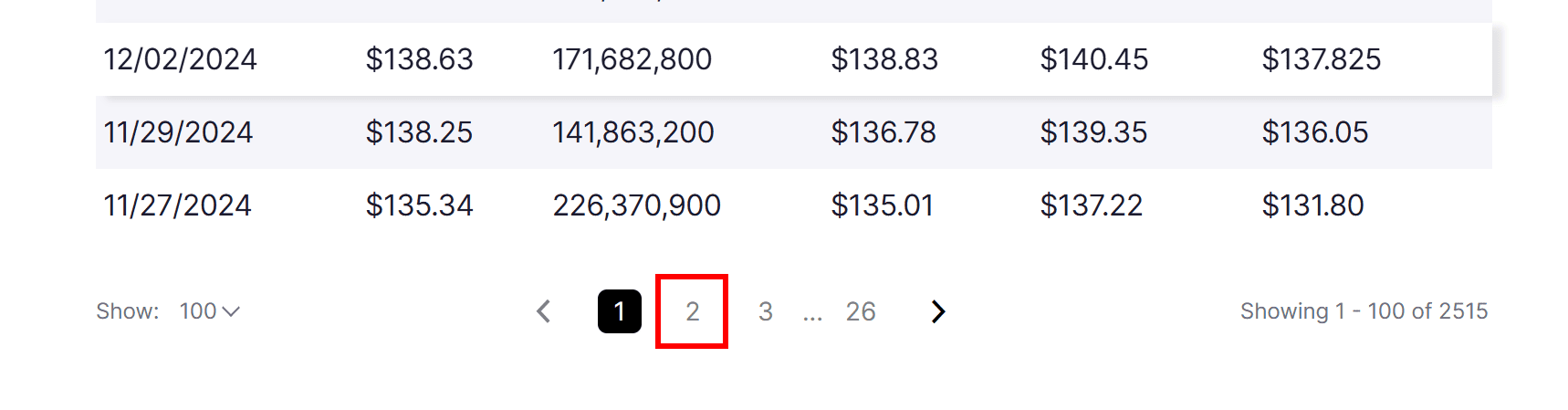
You’ll notice the URL changes to something like this:
https://www.nasdaq.com/market-activity/stocks/nvda/historical?page=2&rows_per_page=100&timeline=y10
In other words, the page query parameter contains the number of the current pagination page. That means you can programmatically build the pagination URL without having to simulate the click interaction on the pagination elements.
In detail, you can scrape data from all pages by:
- Initially connecting to the first pagination page
- Retrieving the last page number (if it has not been scraped already)
- Scraping data from the current page
- Incrementing the page number to move to the next page
To retrieve the last page number, inspect the pagination element:
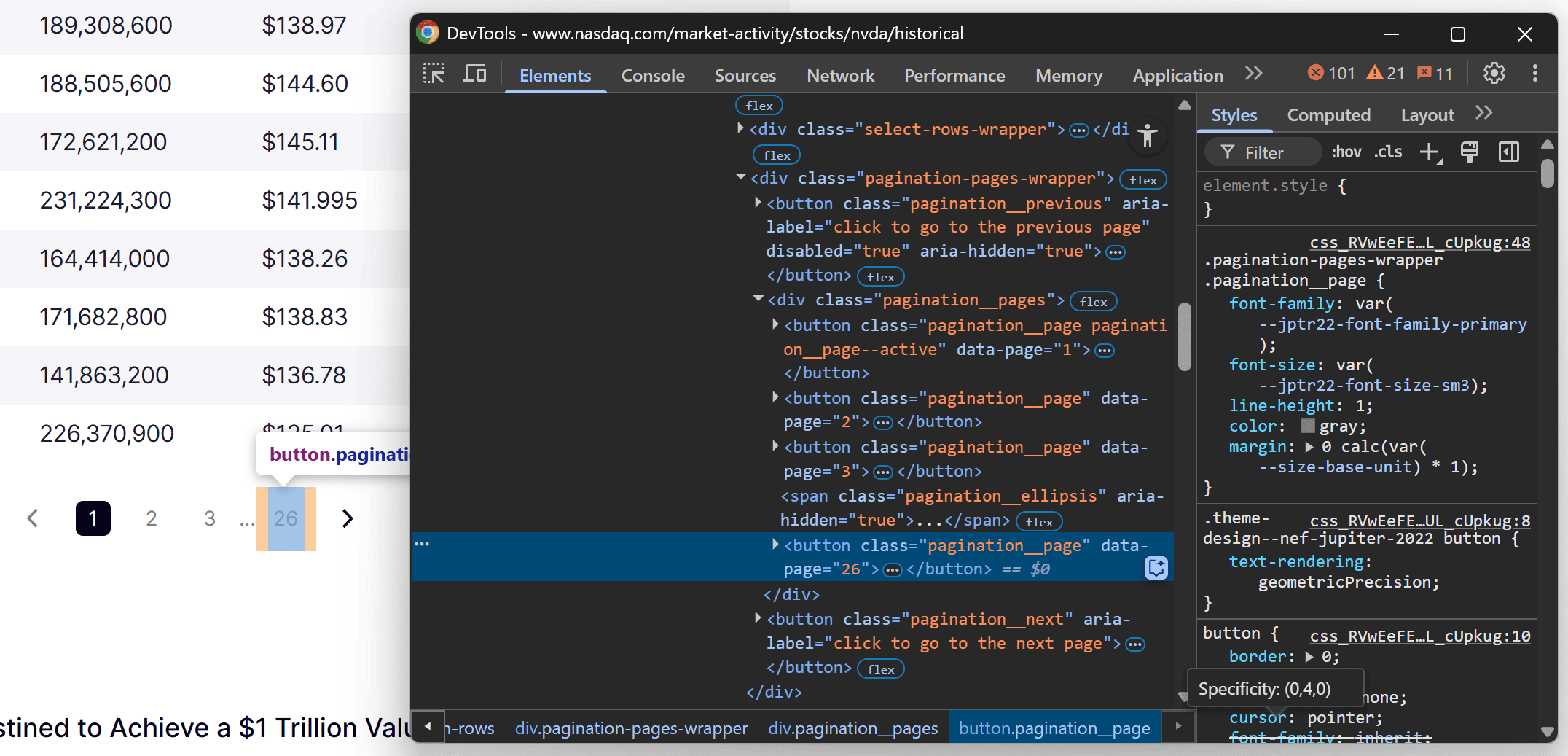
You can easily extract the last page number by targeting the content inside the data-page attribute of the last .pagination__pages [data-page] element:
pagination_last_page_element = page.locator(".pagination__pages [data-page]").last
last_page = int(await pagination_last_page_element.get_attribute("data-page"))
Now, integrate the crawling logic as follows:
# The index of the last pagination page
last_page = math.inf
# The maximum number of pages to scrape
max_pages = 5
# To keep track of the current page being scraped...
current_page = 1
# Iterate over no more than max_pages pages
while current_page <= min(last_page, max_pages):
# The URL of the Nasdaq stock page
url = f"https://www.nasdaq.com/market-activity/stocks/{stock_ticker.lower()}/historical?page={current_page}&rows_per_page=100&timeline=y10"
print(f"Scraping {url}...")
# Navigate to the target Nasdaq page
await page.goto(url)
# Update the value of the last pagination page
if last_page == math.inf:
# Retrieve the index of the last pagination page
pagination_last_page_element = page.locator(".pagination__pages [data-page]").last
last_page = int(await pagination_last_page_element.get_attribute("data-page"))
# Scraping logic from the previous steps...
# To scrape the next pagination page
current_page += 1
In this case, the maximum number of pages your Nasdaq scraper will go through is 5. This limitation helps avoid making too many requests to Nasdaq’s server.
Import math from the Python Standard Library to make the code above work:
import math
9. Export to CSV
After the while loop—and after the Playwright async block—use the Python built-in csv module to export the scraped stock data to CSV:
with open(f"{stock_ticker}.csv", mode="w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["date", "close", "volume", "open", "high", "low"])
writer.writeheader()
writer.writerows(stock_data)
In this case, this will create an nvda.csv file. Then, the code will add a header row to it, then populate it with the data from the stock_data list.
10. Complete code
Your scraper.py file should now contain:
import asyncio
from playwright.async_api import async_playwright
import math
import csv
# To clean the stock data strings scraped from the table
def clean_stock_data_string(string_value):
return string_value.strip().replace(",", "").replace("$", "")
async def run():
# Where to store the scraped data
stock_data = []
async with async_playwright() as p:
# Initialize a new Playwright instance
browser = await p.chromium.launch(
headless = False
)
context = await browser.new_context()
page = await context.new_page()
# The ticker of the stock to scrape data about
stock_ticker = "nvda"
# The index of the last pagination page
last_page = math.inf
# The maximum number of pages to scrape
max_pages = 5
# To keep track of the current page being scraped...
current_page = 1
# Iterate over no more than max_pages pages
while current_page <= min(last_page, max_pages):
# The URL of the Nasdaq stock page
url = f"https://www.nasdaq.com/market-activity/stocks/{stock_ticker.lower()}/historical?page={current_page}&rows_per_page=100&timeline=y10"
print(f"Scraping {url}...")
# Navigate to the target Nasdaq page
await page.goto(url)
# Update the value of the last pagination page
if last_page == math.inf:
# Retrieve the index of the last pagination page
pagination_last_page_element = page.locator(".pagination__pages [data-page]").last
last_page = int(await pagination_last_page_element.get_attribute("data-page"))
# Select the stock data HTML elements for the specific page
table_row_elements = page.locator("nsdq-table [role=\"row\"][data-row-index]")
# Wait for the first row to be rendered and visible on the page
await table_row_elements.first.wait_for(state="visible")
# Iterate over the rows and scrape data from each of them
for table_row_element in await table_row_elements.all():
# Scraping logic
# Get the number of cells in the row
table_cell_elements = table_row_element.locator("[role=cell]")
# If the row contains the expected number of cells
if await table_cell_elements.count() >= 5:
date_cell_element = table_cell_elements.nth(0)
date = clean_stock_data_string(await date_cell_element.text_content())
close_cell_element = table_cell_elements.nth(1)
close = clean_stock_data_string(await close_cell_element.text_content())
volume_cell_element = table_cell_elements.nth(2)
volume = clean_stock_data_string(await volume_cell_element.text_content())
open_cell_element = table_cell_elements.nth(3)
open_value = clean_stock_data_string(await open_cell_element.text_content())
high_cell_element = table_cell_elements.nth(4)
high_value = clean_stock_data_string(await high_cell_element.text_content())
low_cell_element = table_cell_elements.nth(5)
low_value = clean_stock_data_string(await low_cell_element.text_content())
# Populate a new object with the scraped data and append it to the list
stock_data_entry = {
"date": date,
"close": close,
"volume": volume,
"open": open_value,
"high": high_value,
"low": low_value
}
stock_data.append(stock_data_entry)
# To scrape the next pagination page
current_page += 1
# Close the browser and release its resources
await browser.close()
# Export the scraped stock data to CSV
with open(f"{stock_ticker}.csv", mode="w", newline="", encoding="utf-8") as f:
writer = csv.DictWriter(f, fieldnames=["date", "close", "volume", "open", "high", "low"])
writer.writeheader()
writer.writerows(stock_data)
if __name__ == "__main__":
asyncio.run(run())
As you can see, with just a few lines of Python code, you've built a simple Nasdaq scraper.
To test your script, run the following command in your terminal:
python scraper.py
It’ll produce output in the terminal like this:
Scraping https://www.nasdaq.com/market-activity/stocks/nvda/historical?page=1&rows_per_page=100&timeline=y10...
Scraping https://www.nasdaq.com/market-activity/stocks/nvda/historical?page=2&rows_per_page=100&timeline=y10...
Scraping https://www.nasdaq.com/market-activity/stocks/nvda/historical?page=3&rows_per_page=100&timeline=y10...
Scraping https://www.nasdaq.com/market-activity/stocks/nvda/historical?page=4&rows_per_page=100&timeline=y10...
Scraping https://www.nasdaq.com/market-activity/stocks/nvda/historical?page=5&rows_per_page=100&timeline=y10...
That’s just the logging output from the pagination logic.
When the script completes, a file named nvda.csv will appear in your project folder. Open that file, and you'll see the stock market data related to NVDA stock:
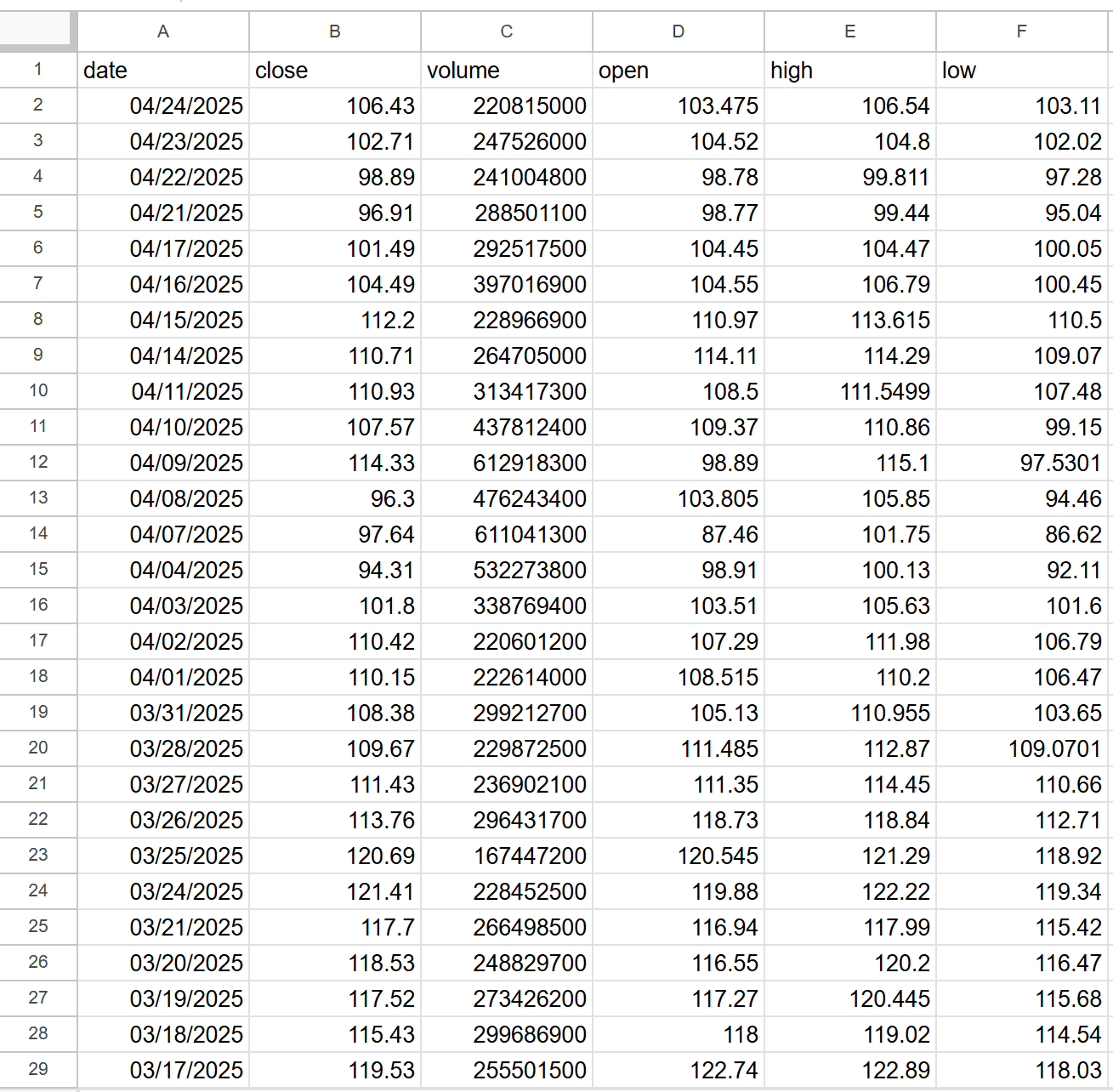
Wonderful! Your Python script to scrape Nasdaq stock market data is working perfectly.
11. Deploy to Apify
Suppose that you want to deploy your Nasdaq scraper to Apify and run it in the cloud. The prerequisites for using Apify are:
- An Apify account
- A basic understanding of how Apify works
To create a new project to scrape Nasdaq stock market data on Apify:
- Log in to your Apify account
- Go to Apify Console
- Under the "Actors" dropdown, select "Development," and then press the “Develop new” button:
Then, press the “View all templates” button to see all Apify templates:
In the Python section, choose the “Playwright + Chrome” template, as that's the setup we used in this tutorial:
Review the code of the starter project and click the “Use this template” button to create a copy of this template:
You'll be redirected to Apify’s built-in online IDE:
There, you can customize your Actor by writing your Nasdaq scraping logic directly in the cloud.
Thanks to the input/output configuration feature offered by Apify, you no longer need to hardcode the stock ticker directly into your code. Instead, you can configure your Actor to accept input arguments. This allows you to scrape data for different stocks by simply changing the stock ticker argument.
To configure the required input arguments in your Apify Actor, open input_schema.json in the Web IDE, write this JSON content:
{
"title": "Scrape stock market data from the Nasdaq site",
"type": "object",
"schemaVersion": 1,
"properties": {
"stock_ticker": {
"title": "Stock ticker",
"type": "string",
"description": "The ticker of the stock you want to scrape from the Nasdaq exchange",
"editor": "textfield",
"prefill": "NVDA"
},
"max_pages": {
"title": "Maximum number of pages",
"type": "integer",
"description": "The maximum number of pages of stock data the Nasdaq scraper should go through",
"editor": "number",
"prefill": 5
}
},
"required": ["stock_ticker"]
}
This defines two input arguments:
stock_ticker: The ticker symbol of the stock to scrape data about (e.g., NVDA).max_pages: The maximum number of pages of stock data to scrape.
In main.py, you can read the input arguments with:
actor_input = await Actor.get_input()
# ...
max_pages = actor_input.get("max_pages", 5)
# ...
stock_ticker = actor_input.get("stock_ticker")
Actor.get_input() retrieves the input arguments, which you can access by name using actor_input.get().
Inside main.py, you'll find some starter code that reads the target URLs from the Apify input arguments. The script then uses Playwright to launch a browser and navigate to the specified page.
After that, integrate the scraping logic you developed in steps 3 to 8 of this tutorial. Put everything together, and you'll have the following Apify Actor code:
from __future__ import annotations
from urllib.parse import urljoin
from apify import Actor, Request
from playwright.async_api import async_playwright
import math
# To clean the stock data strings scraped from the table
def clean_stock_data_string(string_value):
return string_value.strip().replace(",", "").replace("$", "")
async def main() -> None:
# Enter the context of the Actor.
async with Actor:
# Retrieve the Actor input, and use default values if not provided
actor_input = await Actor.get_input() or {}
# Launch Playwright and open a new browser context
async with async_playwright() as playwright:
# Configure the browser to launch in headless mode as per Actor configuration
browser = await playwright.chromium.launch(
headless=Actor.config.headless,
args=['--disable-gpu'],
)
context = await browser.new_context()
page = await context.new_page()
# The ticker of the stock to scrape data about
stock_ticker = actor_input.get("stock_ticker")
# The index of the last pagination page
last_page = math.inf
# The maximum number of pages to scrape
max_pages = actor_input.get("max_pages", math.inf)
# To keep track of the current page being scraped...
current_page = 1
# Iterate over no more than max_pages pages
while current_page <= min(last_page, max_pages):
# The URL of the Nasdaq stock page
url = f"https://www.nasdaq.com/market-activity/stocks/{stock_ticker.lower()}/historical?page={current_page}&rows_per_page=100&timeline=y10"
Actor.log.info(f"Scraping {url}...")
# Navigate to the target Nasdaq page
await page.goto(url)
# Update the value of the last pagination page
if last_page == math.inf:
# Retrieve the index of the last pagination page
pagination_last_page_element = page.locator(".pagination__pages [data-page]").last
last_page = int(await pagination_last_page_element.get_attribute("data-page"))
# Select the stock data HTML elements for the specific page
table_row_elements = page.locator("nsdq-table [role=\"row\"][data-row-index]")
# Wait for the the first row to be rendered and visible on the page
await table_row_elements.first.wait_for(state="visible")
# Iterate over the rows and scrape data from each of them
for table_row_element in await table_row_elements.all():
# Scraping logic
# Get the number of cells in the row
table_cell_elements = table_row_element.locator("[role=cell]")
# If the row contains the expected number of cells
if await table_cell_elements.count() >= 5:
date_cell_element = table_cell_elements.nth(0)
date = clean_stock_data_string(await date_cell_element.text_content())
close_cell_element = table_cell_elements.nth(1)
close = clean_stock_data_string(await close_cell_element.text_content())
volume_cell_element = table_cell_elements.nth(2)
volume = clean_stock_data_string(await volume_cell_element.text_content())
open_cell_element = table_cell_elements.nth(3)
open_value = clean_stock_data_string(await open_cell_element.text_content())
high_cell_element = table_cell_elements.nth(4)
high_value = clean_stock_data_string(await high_cell_element.text_content())
low_cell_element = table_cell_elements.nth(5)
low_value = clean_stock_data_string(await low_cell_element.text_content())
# Populate a new object with the scraped data and append it to the dataset
stock_data_entry = {
"date": date,
"close": close,
"volume": volume,
"open": open_value,
"high": high_value,
"low": low_value
}
await Actor.push_data(stock_data_entry)
# To scrape the next pagination page
current_page += 1
# Close the page in the browser
await page.close()
Note that you no longer need the CSV export logic, as that's handled by the push_data() method:
await Actor.push_data(stock_data_entry)
This method enables you to retrieve the scraped data via the API or export it in various formats directly from the Apify dashboard.
Next, press the “Save, Build & Start” button:
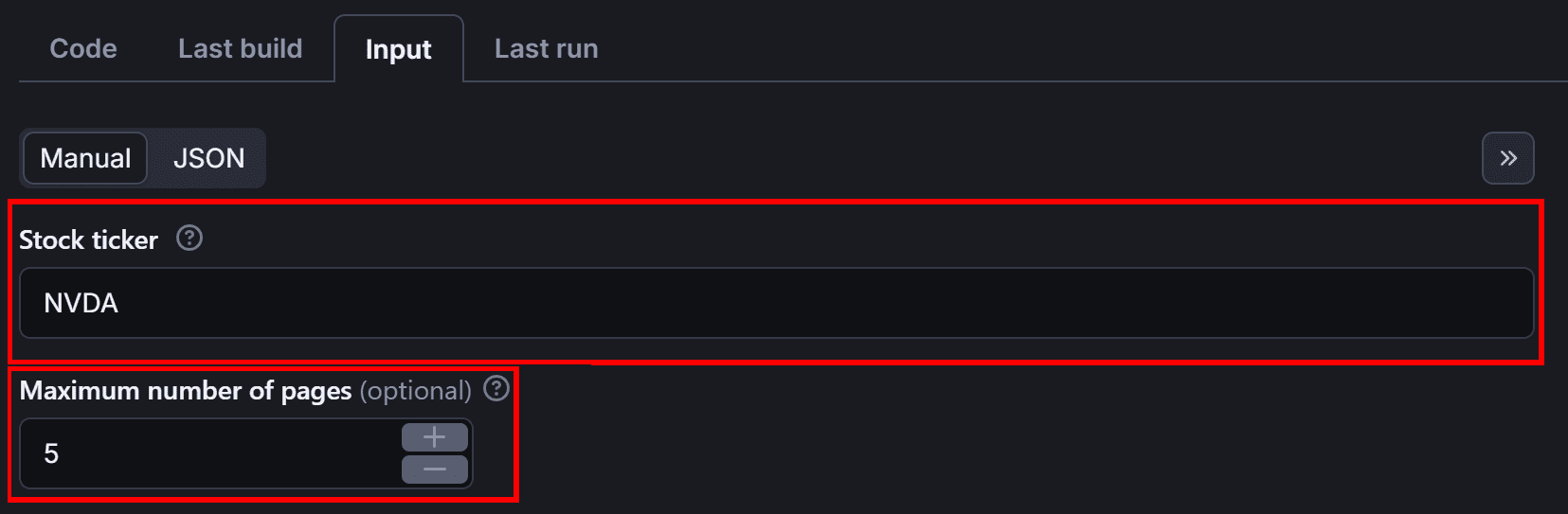
Go to the “Input” tab and enter the stock ticker and maximum number of pages manually:
Before running your Actor, remember that you need to execute your Nasdaq scraper in headless mode. So, move to the “Environment Variables” section in the “Code” tab and click “Add variable”:

Define the APIFY_HEADLESS environment variable and set it to 0:
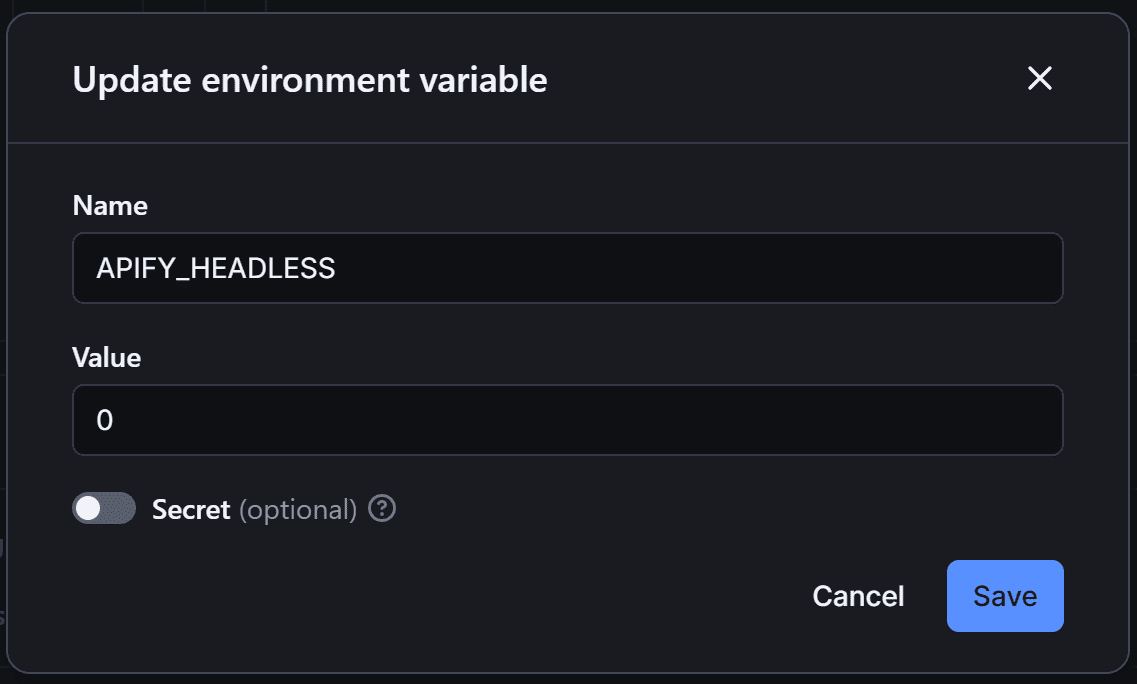
This will instruct Apify to run in headless mode.
Finally, press “Save, Build & Start” to run your Nasdaq scraper Actor. Once the run is complete, the results should appear as follows:
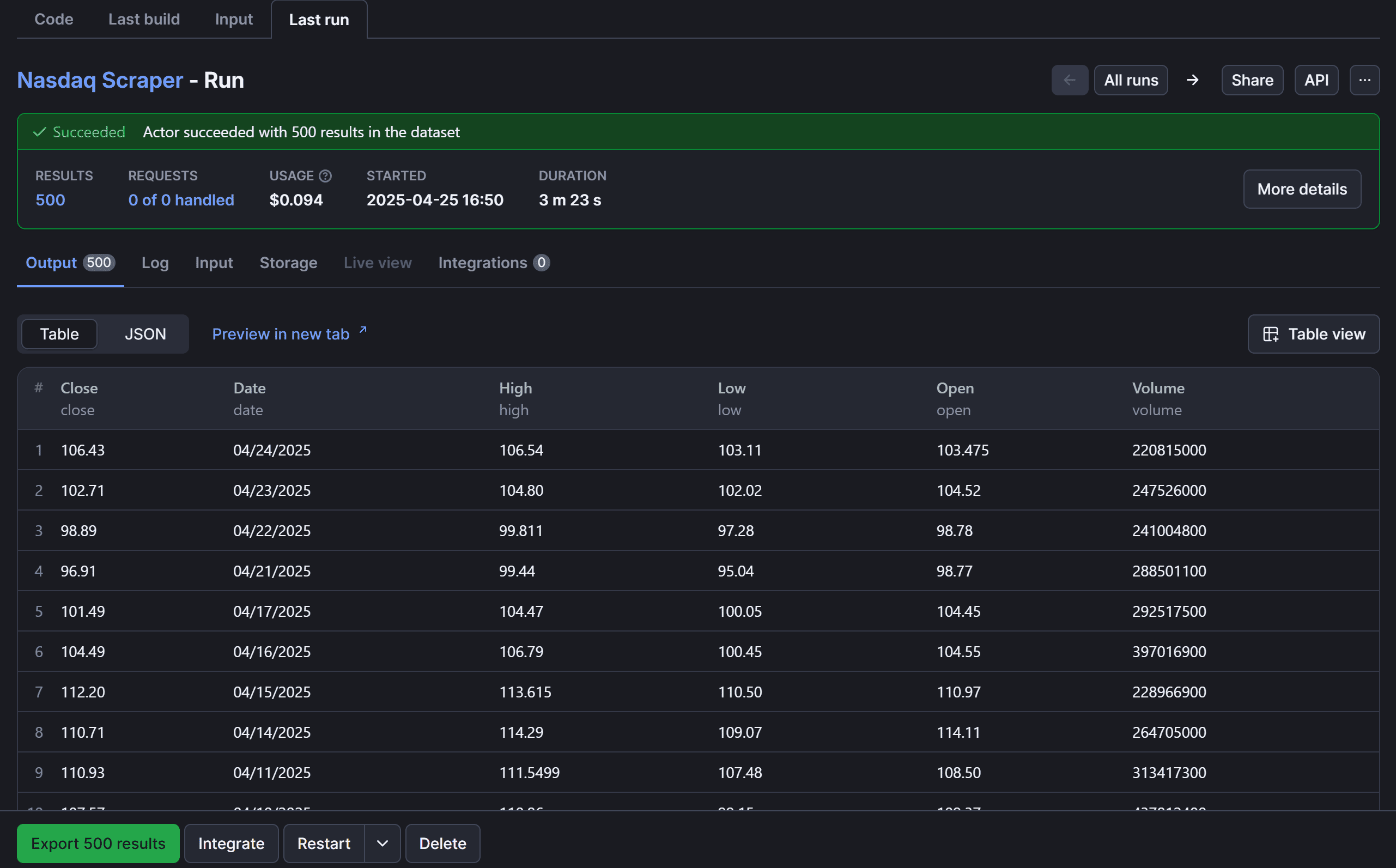
Switch to the “Storage” tab to export the scraped data:
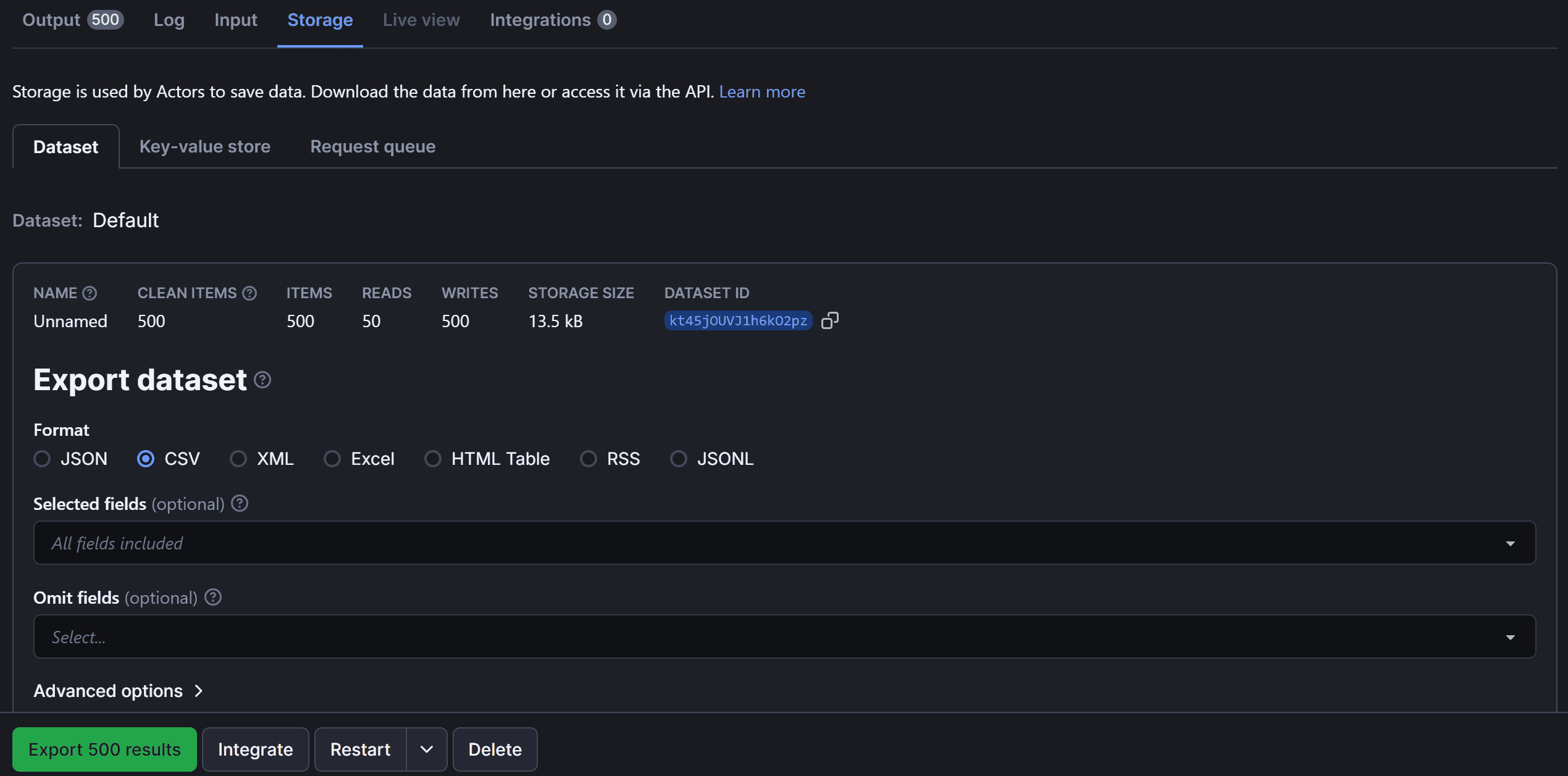
From here, you can export your scraped data in multiple formats—including JSON, CSV, XML, Excel, HTML Table, RSS, and JSONL.
And there you've it! You've successfully scraped Nasdaq stock market data on Apify.
Next steps
This tutorial has guided you through the basics of scraping stock market data from Nasdaq.com. To take your scraper to the next level, consider implementing these advanced techniques:
- Integrate other sources: Extend your Python web browser automation logic to consider other potential sources for Nasdaq stock market data, such as Yahoo Finance, for a more comprehensive dataset.
- Add more input arguments: You could add additional input arguments to control the start page, end page, or the timeline of the stock data you want to scrape.
- Proxy integration: Use proxy servers to rotate IP addresses and avoid rate limits or blocks. You can explore Apify's built-in proxy tools or integrate your own. For more details, check the official documentation.
Why scrape Nasdaq stock market data?
Scraping Nasdaq stock market data provides valuable insights for investors, analysts, and businesses looking to track market performance. In particular, below are the main reasons why you might want to scrape this data:
- Historical stock data: Analyze past performance to identify trends and study how stocks have reacted to certain events or market conditions over time. This helps you make better predictions for future investments.
- Real-time prices: Track live market movements and make quick decisions based on the latest price fluctuations, which is fundamental for day trading or responding to important news.
- Market trends: Identify overall market trends, such as the performance of different sectors, market indices, and stock groupings. That can give you an edge in market analysis.
- Investment research: Conduct thorough research for building models, testing investment strategies, and making data-driven decisions. The end goal is to improve your portfolio’s performance and risk management process.
Conclusion
In this tutorial, you used Playwright with Python to build a Nasdaq scraper that automates the extraction of stock market data from Nasdaq.com. You focused on scraping historical stock quotes for NVDA and successfully deployed the scraper to Apify.
This project demonstrated how Apify streamlines development by enabling scalable, cloud-based scraping with minimal setup. Feel free to explore other Actor templates and SDKs to expand your automation toolkit.
For quicker setups, consider using ready-made Apify Actors to efficiently collect stock data at scale.
Frequently asked questions
Can you scrape Nasdaq stock market data?
Yes, you can scrape Nasdaq stock market data using browser automation logic. By targeting the relevant pages, such as historical stock quotes, you can extract stock information using libraries like Playwright, Selenium, or Crawlee.
Is it legal to scrape Nasdaq stock market data?
Yes, it's legal to scrape Nasdaq stock market data since the data available on the Nasdaq site is public. At the same time, there may be limitations on unauthorized scraping, especially when the data is used for commercial purposes. So, it’s important to comply with Nasdaq's terms of service.
How to scrape Nasdaq stock market data?
To scrape Nasdaq stock market data, you can use a web scraping library like Playwright. Connect to the Nasdaq website with a controlled browser, navigate to the stock data page, wait for the page to load and render, and then extract the relevant data from the page’s table.