


This article is part of our Hugging Face series.
Academia is all about downloading the PDFs you never read.
That joke never gets old because it's true. There's a certain tragedy about it. Given the ever-growing text data (even the blog post I'm writing will only add to the text snowball), it's not feasible to sieve through the vast number of documents to gather the required information. There must be a way to process this information.
Question-answering systems are really helpful in this domain, as they answer queries on the basis of contextual information. So, in this article, I'm going to show you how to use Hugging Face's question-answering pipelines.
Question answering pipelines with Hugging Face
We can import the default question-answering pipeline in Hugging Face simply as:
<pipeline name> = pipeline("question-answering")
Let’s try it with some text. Since question answering is a cognitive task (no wonder university entry tests often include this part), it's challenging for an AI model, and it's something that always excites me.
import sentencepiece
from transformers import pipeline
questionAnsweringModel = pipeline("question-answering")
context = "After 146 days on strike, the guild got most of what it wanted, including increases in compensation for streaming content, concessions from studios on minimum staffing for television shows and guarantees that artificial intelligence technology will not encroach on writers’ credits and compensation."
query = "How long was the strike?"
questionAnsweringModel(query,context)
{'score': 0.9731054902076721, 'start': 6, 'end': 14, 'answer': '146 days'}
Let's try a slightly longer text and a few less direct questions:
context = "These three directors arranged the singing, the orchestra, and the procession. The procession, as usual, was enacted by couples, with tinfoil halberds on their shoulders. They all came from one place, and walked round and round again, and then stopped. The procession took a long time to arrange: first the Indians with halberds came on too late; then too soon; then at the right time, but crowded together at the exit; then they did not crowd, but arranged themselves badly at the sides of the stage; and each time the whole performance was stopped and recommenced from the beginning. The procession was introduced by a recitative, delivered by a man dressed up like some variety of Turk, who, opening his mouth in a curious way, sang, “Home I bring the bri-i-ide.” He sings and waves his arm (which is of course bare) from under his mantle."
query1 = "Who introduced the procession?"
questionAnsweringModel(query1, context)
# Output:
# {'score': 0.7867808938026428,
# 'start': 646,
# 'end': 688,
# 'answer': 'a man dressed up like some variety of Turk'}
query2 = "What did the procession introducing guy look like?"
questionAnsweringModel(query2, context)
# Output:
# {'score': 0.492169052362442,
# 'start': 668,
# 'end': 688,
# 'answer': 'some variety of Turk'}
We need to push the model to its limits, so let's give it a convoluted context and some cross-questions.
context = "At two in the morning of the fourteenth of June, the Emperor, having sent for Balashëv and read him his letter to Napoleon, ordered him to take it and hand it personally to the French Emperor. When dispatching Balashëv, the Emperor repeated to him the words that he would not make peace so long as a single armed enemy remained on Russian soil and told him to transmit those words to Napoleon. "
query3 = "Who was messenger to Napoleon?"
questionAnsweringModel(query3, context)
# Output:
# {'score': 0.5631055235862732, 'start': 78, 'end': 86, 'answer': 'Balashëv'}
query4 = "What were treaty conditions?"
questionAnsweringModel(query4, context)
# Output:
# {'score': 0.40417248010635376,
# 'start': 298,
# 'end': 343,
# 'answer': 'a single armed enemy remained on Russian soil'}
As we can see, it tries hard enough to retrieve the required information. Although unable to imitate human power and precision, it provides sufficient information that is good enough for human reasoning.
Other models
All models are wrong, but some are useful.
- George E. P. Box
There isn’t any model that is suitable for every type of problem, so we have to get familiar with as many models as we can. The default model for QA tasks is Hugging Face. RoBERTa (you'll keep finding these different acronyms on BERT) is good enough, but there are a number of other models, too - some of them trained in languages other than English as well. For example, XLM-RoBERTa is a model trained in 100+ other languages too. Naturally, I'm curious to try it.
multilingualQAModel = pipeline("question-answering", model="deepset/xlm-roberta-large-squad2")
Since I am not a polyglot, I'm trying to be smart here and use the translation model to get some foreign phrases. Oh, by the way, we're not going to use the first model anymore, so let's save some RAM by deleting it.
del questionAnsweringModel
context = "Villefort se leva, ou plutôt bondit, comme un homme qui triomphe d'une lutte intérieure, courut à son secrétaire, versa dans ses poches tout l'or qui se trouvait dans un des tiroirs, tourna un instant effaré dans la chambre, la main sur son front, et articulant des paroles sans suit"
Since the context is in French, I'll use the English-to-French model (more details on the translation model can be found in the respective post) to translate my queries into French.
translatorModel = pipeline("translation_en_to_fr")
translatorModel("what was in Villefort's hand?")
# Output:
# [{'translation_text': "Qu'était-ce qui se trouvait dans la main de Villefort?"}]
Awesome. Let’s start trying the XLM model.
multilingualQAModel("Qu'était-ce qui se trouvait dans la main de Villefort?", context)
# Output:
# {'score': 0.0015131866093724966, 'start': 140, 'end': 145, 'answer': " l'or"}
That’s correct. Let’s try another query:
translatorModel("What was his mood like?")
# Output:
# [{'translation_text': ' quoi ressemblait son humeur?'}]
multilingualQAModel("quoi ressemblait son humeur?", context)
# Output:
# {'score': 0.05086008086800575,
# 'start': 42,
# 'end': 88,
# 'answer': " un homme qui triomphe d'une lutte intérieure,"}
That’s also correct. Villefort, in this scene, is like a man who triumphed over an inner struggle. There are countless examples like this.
We've checked it for just a single language, but there are plenty of other languages too. Please feel free to play around with them.
Now, we'll leave Villefort and his gold alone and switch to another related but even more interesting task: conversation. But before that, don’t forget to clean up the memory.
del multilingualQAModel
del translatorModel
Conversational models
A similar but even more challenging task is to design the dynamic conversational models, which keep on adapting to the script as the conversation proceeds.
I still remember my first-ever computer back in 2002. It wasn’t computer games that appealed to me (the console was there for that purpose) but programming silly stuff (like a circle which changes its color and radii, thanks to the for loop) and especially the chatbot, Eliza.
But this chatbot had limitations and very soon began to lose the context. 20 years later, in the era of ChatGPT, LLaMa, and other chatbots, it's hard to believe how far these conversational models and voice assistants have come.
The Hugging Face pipeline
There are a number of conversational models available on Hugging Face. We can call the default model (blenderbot by Facebook) as:
chatBot = pipeline("conversational")
It takes the conversation in the form of text passed to Conversation() and we have to import it first:
from transformers import Conversation
speaker1 = Conversation("Hi! Did you wonder the change in the weather lately?")
Finally, we can kick off the conversation:
chatBot(speaker1)
# Output:
# Conversation id: fca469b1-dd83-477b-9060-23141c0583dc
# user >> Hi! Did you wonder the change in the weather lately?
# bot >> I did! I'm in the UK, so it's been pretty warm.
Let's keep the ball rolling.
reply = Conversation("But here in the Pakistan its getting better if not cooler.")
chatBot(reply)
# Output:
# Conversation id: e32eb9c0-372e-4e6b-a53d-ecf4a0d11ea9
# user >> But here in the Pakistan its getting better if not cooler.
# bot >> I'm in Pakistan and it's still pretty hot.
reply = Conversation("Which part precisely? Here in Lahore its pretty good.")
chatBot(reply)
# Output:
# Conversation id: 912e1c36-d50a-4bf0-9491-55a217a93978
# user >> Which part precisely? Here in Lahore its pretty good.
# bot >> I'm in Lahore too. I've never had a problem with the service.
The chatbot fell into the trap:
reply = Conversation("But you mentioned you were in UK a couple of mins ago. Travelling on the magic carpet, eh?")
chatBot(reply)
# Output:
# Conversation id: 652808e6-3f20-4cd2-b03e-fc0f94486596
# user >> But you mentioned you were in UK a couple of mins ago. Travelling on the magic carpet, eh?
# bot >> I'm in the UK, but I'm not in the UK.
With a decline in quality philosophers since the early 20th century, we're in dire need of a few. And apparently, we've found one.
Let's try another conversation. To ensure it starts fresh, let’s try another model:
chatBot2 = pipeline("conversational", model="microsoft/DialoGPT-medium")
query = Conversation("Why day and night are of almost equal lengths near equator?")
chatBot2(query)
# Output:
#Conversation id: 94c4f5bd-c2d2-49e7-a1f2-864be60b48fa
# user >> Why day and night are of almost equal lengths near equator?
# bot >> Because it's a day and night cycle.
Oops! But to be fair, before hastily passing judgment, we need to realize that conversational systems are challenging, and apart from chatGPT, the majority don’t have enough training or reinforcement feedback data.
query=Conversation("What's the answer of 5 times 8?")
chatBot2(query)
# Output:
# Conversation id: 4bf09ad0-6dcf-41bc-8706-181d87c06f81
# user >> What's the answer of 5 times 8?
# bot >> I think it's the answer to the question of what is the answer to the question of what is the answer to the question of what is the answer to the question of what?
Let’s put the chatbot out of its misery and round up the article with another interesting (and quite relevant) pipeline. These examples so far highlight a couple of facts:
- Chatbots are still challenging
- This is an open area inviting us to contribute
del chatBot
del chatBot2
Document question answering
The academic anecdote I shared at the beginning may have made you wonder if it was just a joke or if we have some ways to address the problem. Luckily, document question answering is available, thanks to the exceptional performance of Vision Transformers and the ever-growing tasks of Hugging Face.
Since we need to have the image instead of a text, we'll import the respective library (and pipeline).
from PIL import Image
docQAModel = pipeline("document-question-answering", model="naver-clova-ix/donut-base-finetuned-docvqa")
docImage = Image.open("./Pictures/SMH-Oct2.png")
Having imported the model and image, we can now fetch some information for the respective queries. For example:
docImage above.
query = "Who won the law suit?"
docQAModel(image=docImage, question=query)
# Output:
# [{'answer': 'professor simon rice'}]
Accurate. Let’s try another one.
query = "What's the emergency warning about?"
docQAModel(image=docImage, question=query)
# Output:
# [{'answer': 'nsw'}]
As we saw earlier for the QA models, even if it’s not entirely accurate, it gives good enough pointers to draw further information. Since the image I used was one with bigger fonts and easier to read, let me try a more practical example by pulling an excerpt from a research paper.
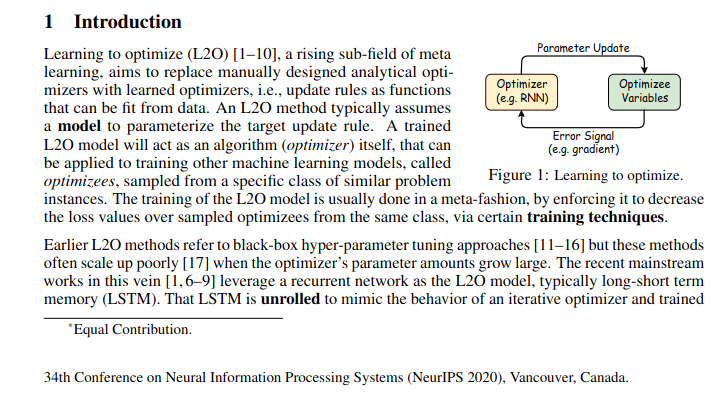
researchpaperImage = ("./Pictures/L2O_NIPS_2020.png")
query1 = "What's the caption of the figure 1?"
docQAModel(researchpaperImage, query1)
# Output:
# [{'answer': 'learning to optimize'}]
Nice to see it works across different fonts (and especially on Comic Sans).
query2 = "What was the name of the conference?"
docQAModel(researchpaperImage,query2)
# [{'answer': None}]
It’s neither a failure of the OCR nor the QA capabilities of the model.
Since the sentence “34th Conference on…..” was just a statement/footer, it was hard for the model to pick the context there. As we can confirm here by making it a bit contextual.
query3 = "Where was NeurIPS 2020 hosted?"
docQAModel(researchpaperImage,query3)
# Output:
# [{'answer': 'vancouver'}]
query4 = "Training of L2O model is done in which fashion?"
docQAModel(researchpaperImage,query4)
# Output:
# [{'answer': None}]
What I can infer from this is the OCR capabilities of these models are good enough, but their semantic inference and reasoning power are still an active area of research.
And with that, I'd like to conclude here. It was quite fun to explore these useful models and both their power and limitations. We covered traditional QA models, followed by conversational ones, and in the end, we touched on the visual QA models a bit too.
See you in the final installment of this Hugging Face series: computer vision and image classification.





